-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Science and Technology
p-ISSN: 2163-2669 e-ISSN: 2163-2677
2013; 3(2A): 41-47
doi:10.5923/s.scit.201301.07
The Mechanism Analysis of Natural Language Texts in Order to Construct A Model of the Full-text Document
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLA.S. Lebedev
Computer Engineering Dept., Zaporozhye Institute of Economics and Information Technologies, Zaporozhye, 69041, Ukraine
Correspondence to: A.S. Lebedev, Computer Engineering Dept., Zaporozhye Institute of Economics and Information Technologies, Zaporozhye, 69041, Ukraine.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
The article describes the main methods of analyzing natural language. Isolated linguistic text analysis method and the basic steps of text analysis. Detailed itemized mechanisms of morphological and syntactic analysis. Considered the stages of the formation of a semantic network. Created a software system which produces a semantic network of the source text in natural language.
Keywords: InformatiСS, Knowledge Base, Antiplagiat System
Cite this paper: A.S. Lebedev, The Mechanism Analysis of Natural Language Texts in Order to Construct A Model of the Full-text Document, Science and Technology, Vol. 3 No. 2A, 2013, pp. 41-47. doi: 10.5923/s.scit.201301.07.
Article Outline
1. Introduction
- In modern society the important role played by information technology. Over time, their importance is continuously increasing. But the development of information technology is very uneven: if the current level of computing and communication is amazing, in the field of semantic information processing is much more modest success. These successes are dependent primarily on advances in the study of the processes of human thought processes of verbal communication between people and the ability to model these processes on a computer.When it comes to creating advanced information technology, the problem of automatic processing of textual information presented in natural languages, come to the fore. It is determined that the person's thinking is closely linked with his language. Furthermore, natural language is a tool of thought. He is also a universal means of communication between people - a means of perception, storing, processing and transmitting information.To address the objectives necessary to move to a new level of processing and presenting information. Specifically, the processing of natural language is necessary to build a structure that will, to some extent formalized document in natural language, to build its model. Using these approaches, receiving document model, we can achieve universal search queries or to create a universal and unique knowledge base.Note, however, that neither the one nor the other is not an end in itself, it is more of the components of more complex problems or support mechanisms for software systems with a very different purpose.For example, when using the considered approach, you can create a search engine of new generation, which will search for information is not a keyword, and within the meaning of the required information.You can design a system for automatic text generation, which will generate a sample of data from a vast array of knowledge in a short text, and it is possible to set not only the subject and scope, and complexity of the method and level of generated text.Actual development of the interpretation of texts. If a model is developed showing the meaning of the text, that meaning can be projected to any natural language. That is, the system is able to produce a translation of the text on the same level at which it would have made a professional translator with the subject matter and level of difficulty of the text.Relevant for today and the so-called antiplagiat system. These are programs that allow you to compare some text to a pre-knowledge base, and determine the percentage of plagiarism in the text. Moreover, such systems need to compare the basic semantic relations, and not perform a comparison on mutual entry into documents and phrases.To address the problem of processing and presentation of the text has been developed further described system. In order to more applied work, then, in this article, the system development will be considered in the spectrum antiplagiat systems. In addition, given that the system is designed for the CIS, the examples discussed in the article are, in Russian. However, the principles of this system are applicable to any language
2. Development Tools
- Given the wide range of applications of the idea, the fundamental difference in the development tools were not. However, given that the spectrum atiplagiat systems more appropriate site is to write the whole system was set up as an independent Internet page.As the existence of the original base was chosen package DenverThe contents of the basic package of Denver:Apache - is HTTP-server. That is the basis of the Apache package.• SSL - is a secure protocol that allows you to communicate important information in a safe manner. These protocols are often common, when used on the page is very important operations (for example, WebMoney).• SSI - a language that lets you create and work with pages shtml.• PHP5 c different modules (mod_rewrite, mod_php).• MySQL - a relational DBMS. All new sites have long been all of the content stored in the database.• PhpMyAdmin - this is a common web-based application that is responsible for the administration of MySQL.• SendMail - emulator SMTP-server, it is possible to write a feedback form and test the results by sending an email.Pros and Cons:•[+] The small size and portability.•[+ / -] The absence of unnecessary modules.•[+] Autonomy. That is the registry, system folders intact. You can run from a flash drive. Not needed deistallyator.•[-] No external access, that is, your friends can not come and see your work.•[-] SecurityDenver - it's a simple local server main tasks - checking of scripts, work with MySQL, work with the emulator SMTP.As the development environment was used ZendStudio 7.2.0. Zend - professional environment for developing and debugging web projects. A distinctive feature of the program is the ability to do remote debugging and profiling. Note that for remote debugging is required to install ZendStudioServer, which is a server module. The composition ZendStudio as an option package included PHP with an extensive list of pre-compiled extensions. If you already have pre-configured version of PHP, ZendStudio product easy to integrate with it. Also in the package environment is ZendOptimizer, a server module to run encoded using ZendEncoder ZendSafeGuardSuite and scripts as well as some of their speeding. The seventh version ZendStudio adds support PHP 5.3, integration with ZendFramework and ZendServer, improved editing of source code and various performance improvements program.The main features of the development environment is:• Integratsiy as ZendiZendServerFramework• Analysis of the code and a quick fix• Quickly create a new file• Support for PHP 4.x and 5.x• SyntaxColoring• Using code templates (PHP, PHPDoc, New File)• Detection of errors in real time• Using Book marks• Internal Browser• Commenting on the PHP code• Search for text and elements of PHP code• Search and replace text in files• Integrated TODO mechanism• Support for HTML and CSS• Debugging PHP code• Using toolbars in IE and Firefox
3. The structure of the Developed System
- Schematic diagram of the system is simple at first glance, but in fact close to the structure of programming languages, compilers, thus increasing the accuracy and quality of the analysis.The algorithm of the method can be divided into four main sections:• Thedivision of the text• Analysis of the words• Review of the proposal• Merge to form a semantic network.At the stage of the construction of a semantic network was offered a special mechanism to handle synonyms and homonyms, the replacement of set phrases and phraseology. Because the system considers the entire text as a collection of some of the identifier, such as synonyms, even in the dictionary have been the same identifier. In the case of the result of a disconnected graph suggested checking for associative relationships. It is possible to create connection "it is" between words that have no direct correspondence. Proceed to a detailed description of each block (Fig. 1).The division of the text:Since any natural language in terms of a computer is a consistent set of characters, for text analysis, you must first share the suggestions and make words in sentences.To perform this task, the simplest, and so, and fast, the method is the use of regular expressions. Clearly, any proposal ends with a special character from which there can be either the following sentence, or the end of the text. A prior proposal or beginning of the text, or a special symbol of the end of previous proposals. Consequently, we can say that all is between the beginning of the text or special characters and other special characters have a suggestion.In the same way the word should be considered all that lies between the beginning of the text, or space, and special characters or spaces. However, it should immediately distinguish different word sentences, that did not happen in the future confusion.[1]Analysis of the words:For this process, the key factors are speed and accuracy, however, given the rising trend of hardware capacity, as the key factor was chosen precisely characterize speech. Therefore, as the primary method for determining the chosen vocabulary methods.At the same time, given the number of words in the Russian language and the amount of space on the media that these words would have taken, had to abandon the store words in the whole form. In the sense that the words with all possible endings, suffixes, prefixes, and so on can produce in large numbers, and to find in a dictionary search word is difficult and long. Instead, a mechanism that allows you to store media on only parts of speech, with fully determine all the necessary characteristics of speech.[2]
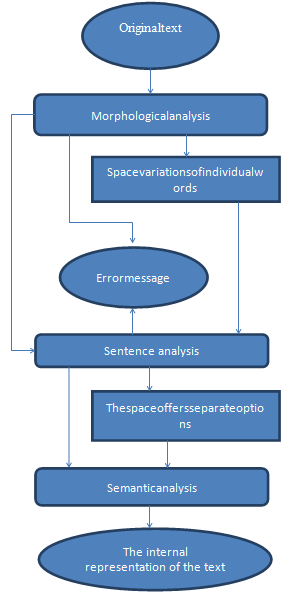 | Figure 1. Outline of a draft |
4. The System
- The simplest version of a semantic network - Display meaning of one sentence. In the simplest case consists of subject and predicate, they are usually applied at least one slave word. For example:«Веникстоитвуглу.»In this case, the semantic network contains subordinate word "углу" associated with the preposition "в". In the semantic network prepositions and conjunctions are removed as insignificant.For an easier perception, this article IDs words are replaced by their text counterparts. A connection of any type are displayed as arrows.Consequently, the semantic web will be as follows:
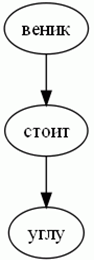 | Figure 2. example of a simple semantic network with one word slave |
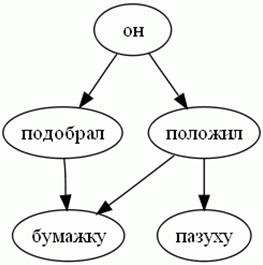 | Figure 3. An example of a semantic network composite offers |
|
5. Discussion of Results
- In the course of the work was the comparative analysis of modern approaches to building semantic models of test documents. The analysis phase identified the strengths and weaknesses approaches examined.Considered such systems as:• System SnePSThe basis for this method was the idea in the text representation of objects as instances of the class. All knowledge about individual objects, classes of objects, their properties, abstraction, action, propositions, rules and meta-rules is represented as a network of nodes and directed named relations.Node in the network belongs to one of four types: basic, alternating, and a molecular model - and a unique identifier. The base unit for the element is conceptually different from any other node. Variables nodes correspond to arbitrary elements of the network and can be identified with some of the basic unit. Of base and variable components of the arc can not go, their properties are defined by arcs belonging to them.Molecular nodes correspond to propositions, models - functional term with free variables and are used to search the network.[3] The system is widely used as a means of developing pilot applications using natural language, as it includes the basic mechanism for representation and automatic construction of semantic networks with minimal structure and inference on these networks.The close connection of this system to the tasks of natural language processing due to the fact that its architecture is focused not on manually creating a semantic network, and in its construction as a result of extraction of knowledge from various sources, mostly natural language text.• System SNOOPSNOOP system uses a mechanism that integrates network representation with object-oriented programming and production rules.Network nodes and the relationship between them belong to the class described by a separate network of inheritance, in which a class is determined by a set of possible fields and properties associated with the object corresponding to the class.Classes describe the properties of objects by means of groups of production rules, each of which consists of a pattern, you can navigate through the network, the terms of the nodes found pattern, and action to change the internal structure of the nodes and network changes.[3]There are two kinds of relationships inherit a more general class of communication actantial Communications, and pronoun class inherits from the noun. Rectangles and directed arrows indicate nodes and relationships in the network.Another specific feature of this formalism is the mechanism of the modularization of production rules, separated on the properties that are associated with the objects of the corresponding classes and consists of a set of production rules. This formalism was used for analysis of texts in a narrow domain.• Linguistic Processor LP Krisin for complex information systemsСо стороны своей внутренней структуры данная система представляет собой многоуровневый преобразователь. В нем различаются три уровня разного представления текста:- Morphological- Syntax- Semantic.Each of the sub-levels served by one of the components of the model, by arrays of rules, a dictionary or dictionaries. At each level is formed formally called morphological, syntactic and semantic structure, respectively. Thus, we can talk about the rigid structure of technology.Morphological structure is a set of words, their parts of speech and basic characteristics.The syntax is, in fact, a tree proposal, which reflects the structure of hard sentences.The semantic structure of a graph that reflects the meaning of the text, its structure is combined with the proposals.This mechanism reflects the structure of the text in the form of a set of objects. These objects, in general, are presented as a set of attributes describing it - a statement about the object and the identifier of the object may be a serial number or a combination of statements, the so-called "core" characteristics that distinguish it from many of the other objects.Serial number of statements represents a concatenation of all features of the object, and it can be seen as the links between them. All these objects are stored in a table. The table rows - the links between features, columns - name tag, and their intersection - the value attribute. Then each row corresponds to a statement about a single object.It should be noted that, in this view the structure, the number of fields in the records may be constant or vary from record to record, which causes some difficulties in the further analysis. Namely, in the records of the functional role of a permanent format of concepts expressed by positional means (through the establishment of a specific point in each field), and in the records of variable format - using special code combinations (keywords, indexes role, etc.).It should also be noted that this mechanism involves the use of the analogy. This method, in turn, does not guarantee a correct analysis, but can be used if other methods of analysis for success.[4]According to the results of the analysis as a basis for further research was chosen approach in the language processor LP Krysin.A characteristic feature of the method proposed by the author is the mechanism analysis of the word.Suggest my own dictionary structure and methods of work with him.Identified specific mechanisms of construction of a semantic network, avoiding ambiguity and solve possible disconnected graph semantic network.For comparison site antiplagiat.ru were loaded two texts:• AdobeFlash (MacromediaFlash), или просто Flash— мультимедийная платформа компании Adobeиспользуется для создания веб-приложений или мультимедийных презентаций. Широко используется для создания рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей. (19% of original)• AdobeFlash (MacromediaFlash), или просто Flash— мультимедийная основа компании Adobeиспользуется для разработки веб-приложений или мультимедийных показов. Широко используется для разработки рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей. (100% оригинальности)The reason for this variation is that the site does not take into account the presence of synonyms.As mentioned previously developed system stores the words synonymous with the same codes. As a consequence, both the text will be identified as identical in meaning. A kind blagodaryaraznogo rules for proposals permutation will not help hide the authorship of the text
6. Conclusions
- The system which is described has a complex architecture. However, this system has several advantages for the analysis of natural language texts:• Dedicated stages of text analysis are clear limits of that allow you to distinguish the stages of the system and reduce errors• Morphological analysis is a series of tests, each of which is based on the previous one, which ensures the absence of ring bonds• Parsing involves not just the establishment of the fact that what we offer is a particular structure, but allows us to analyze all possible options for the analysis of words and sentences• Semantic analysis has a number of tools able to deal with the problem of substitutes words, phraseology, and other things.