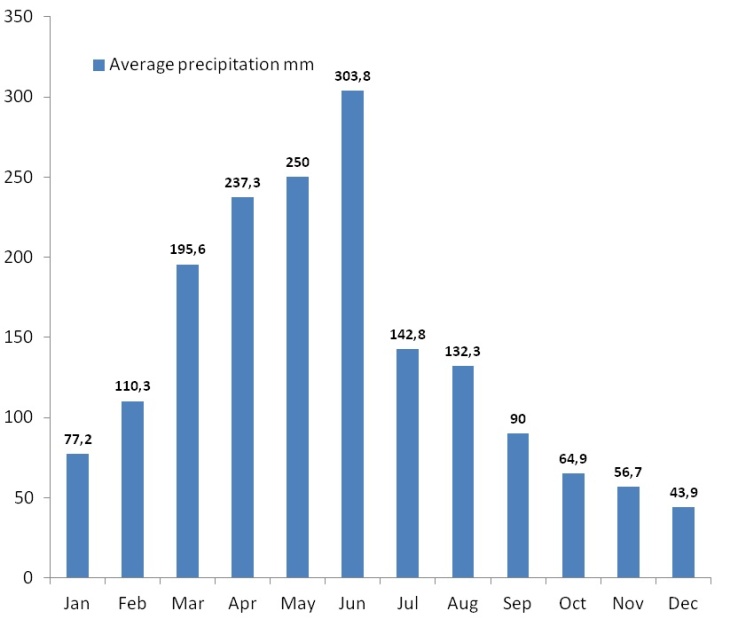
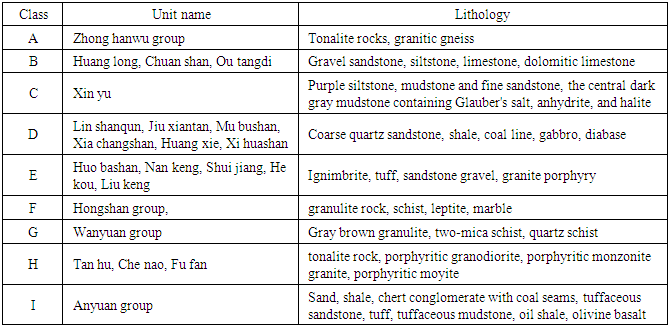
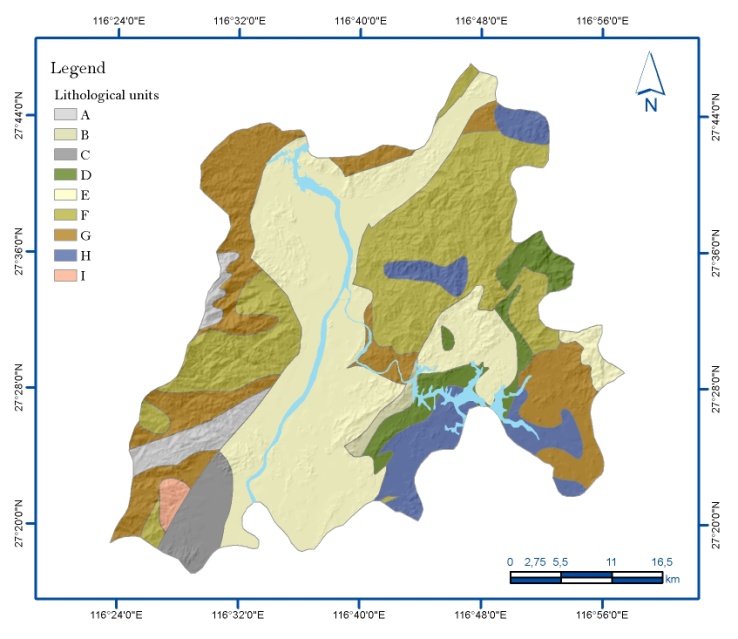
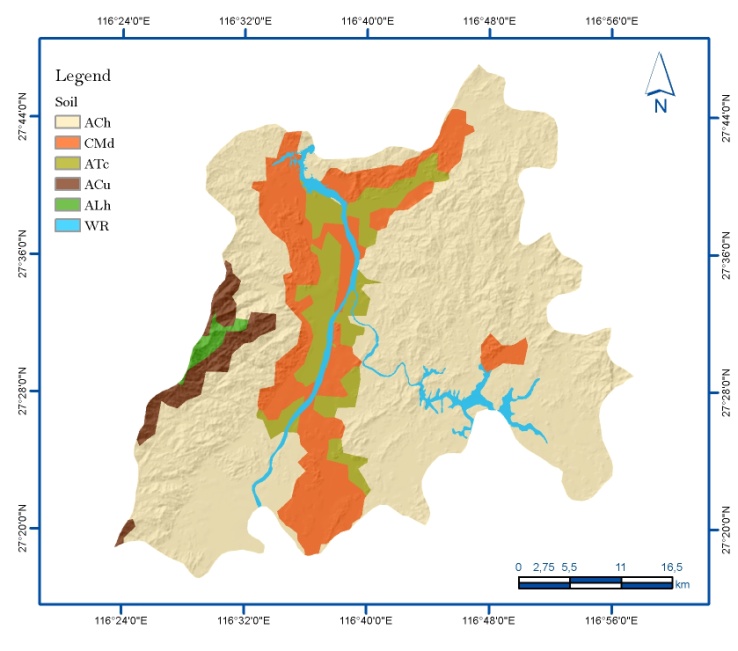
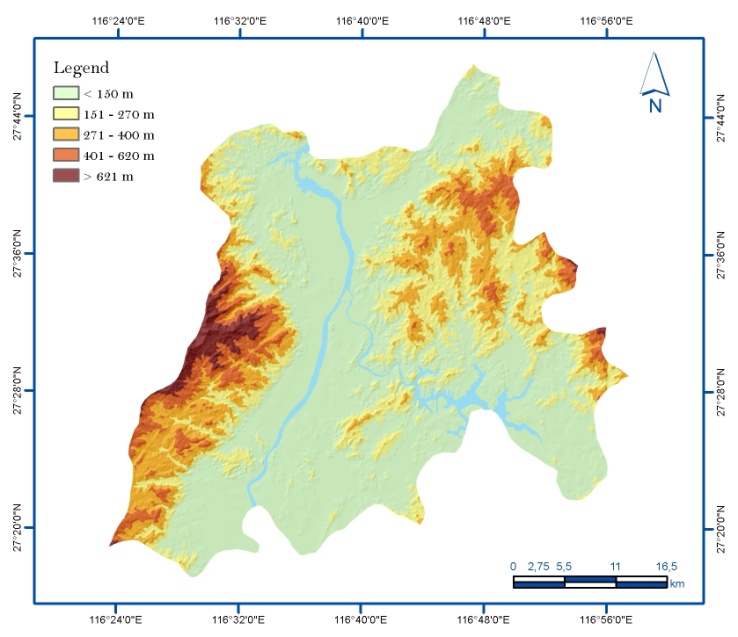
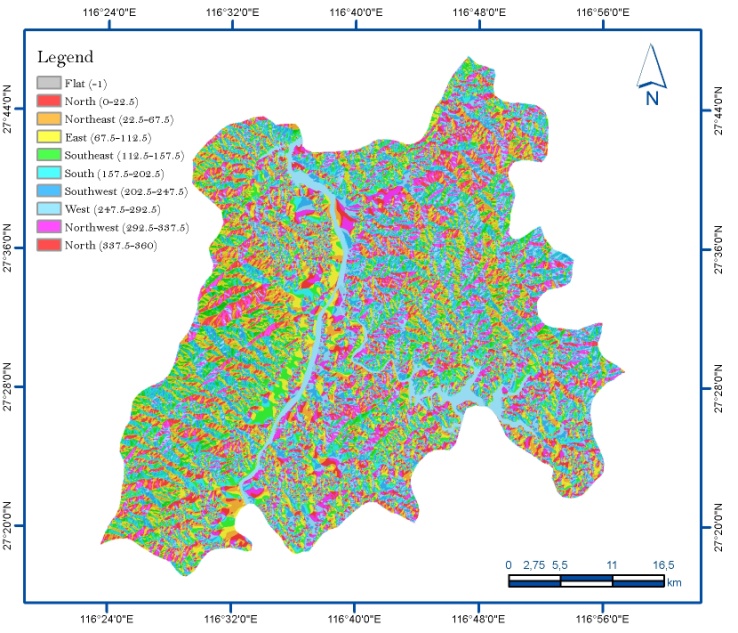
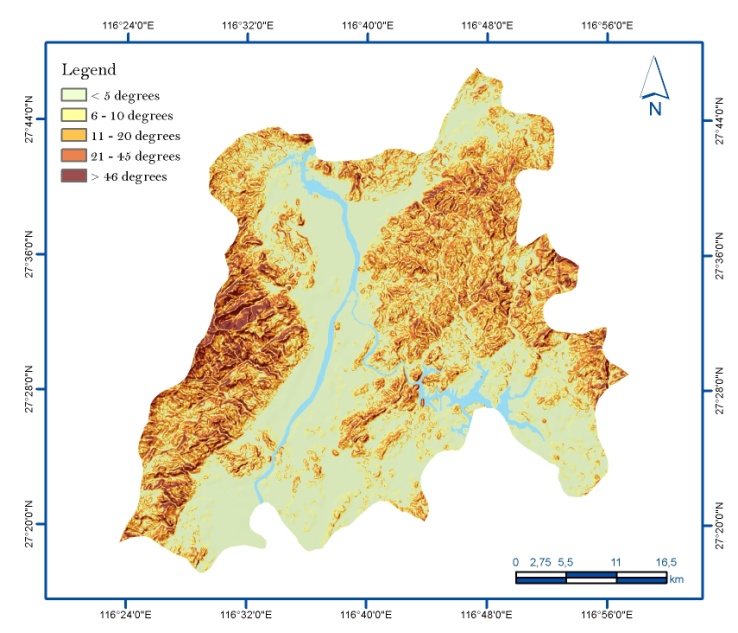
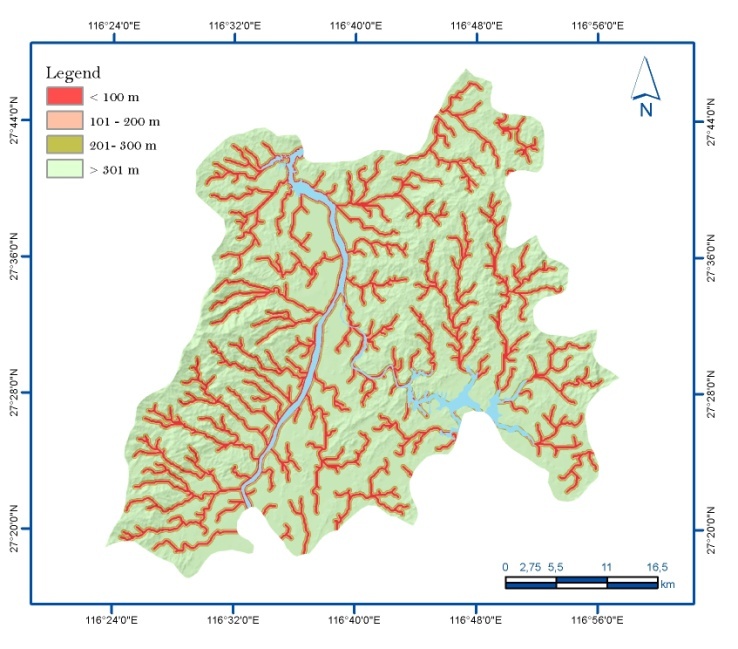
| [1] | Xie, QM,, Bian, X,, Xia, YY., 2005. Systematic analysis of risk evaluation of landslide hazard (in Chinese). Rock Soil Mech 26(1):71–74. |
| [2] | Xu, C., Dai, F., Xu, X., Yuan, HL., 2012. GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang river watershed, china. Geomorphology. 145–146:70–80. |
| [3] | Feizizadeh, B., Blaschke, T., Roodposhti, MS., 2013. Integrating GIS based fuzzy set theory in multicriteria evaluation methods for landslide susceptibility mapping. Int. J. Geoinf., 9 (3), 49–57. |
| [4] | Chen, W., Chai, H., Zhao, Z., Wang, Q., Hong, H., 2016. Landslide susceptibility mapping based on GIS and support vector machine models for the Qianyang County, China. Environ Earth Sci. 75:1–13. |
| [5] | Zhu, A-X., Wang, R., Qiao J., Qin, C-Z. Chen, Y., Liu, J., Du, F., Lin, Y., Zhu, T., 2014. An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 214:128–138. |
| [6] | Peng, L., Niu, R., Huang, B., Wu, X., Zhao, Y., Ye, R., 2014. Landslide susceptibility mapping based on rough set theory and support vector machines: a case of the three gorges area, China. Geomorphology. 204:287–301. |
| [7] | Hong, H., Pradhan, B., Jebur, MN., Tien Bui, D., Xu, C., Akgun, A., 2016. Spatial prediction of landslide hazard at the Luxi area (China) using support vector machines. Environ Earth Sci. 75:1–14. |
| [8] | Pourghasemi, HR., Pradhan, B., Gokceoglu, C., 2012b. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat Hazards 63(2):965–996. |
| [9] | Wang, LJ., Sawada, K., Moriguchi, S., 2013. Landslide susceptibility analysis with logistic regression model based on FCM sampling strategy. Computers & Geosciences, 57, 81–92. |
| [10] | Pourghasemi, HR., Jirandeh, AG., Pradhan, B., Xu, C, Gokceoglu, C. 2013. Landslide susceptibility mapping using support vector machine and GIS at the Golestan province, Iran. J Earth Syst Sci. 122:349–369. |
| [11] | Vahidnia, MH., Alesheikh, AA., Alimohammadi, A., Hosseinali, F., 2010. A GIS-based neuro-fuzzy procedure for integrating knowledgeand data in landslide susceptibility mapping. Computers & Geosciences, 36(29), 1101–1114. |
| [12] | Sdao F., Lioi, DS., Pascale, S., Caniani, D., Mancini, IM., 2013. Landslide susceptibility assessment by using a neuro-fuzzy model: a case study in the Rupestrian heritage rich area of Matera. Nat. Hazards Earth Syst. Sci., 13, 395–407. |
| [13] | Pourghasemi, HR., Kerle, N., 2016. Random forests and evidential belief function-based landslide susceptibility assessment in Western Mazandaran Province, Iran. Environ Earth Sci (2016) 75:185 |
| [14] | Mohammady, M., Pourghasemi, HR., Pradhan, B., 2012. Landslide susceptibility mapping at Golestan Province, Iran: a comparison between frequency ratio, Dempster-Shafer, and weights-of-evidence models. J Asian Earth Sci 61:221–236 |
| [15] | Saito, H., Nakayama, D., Matsuyama, H., 2009. Comparison of landslide susceptibility based on a decision-tree model and actual landslide occurrence: the Akaishi mountains, Japan. Geomorphology, 109(3–4), 108–121. |
| [16] | Yeon, YK., Han, JG., Ryu, KH., 2010. Landslide susceptibility mapping in Injae, Korea, using a decision tree. Engineering Geology, 16(3–4), 274–283. |
| [17] | Catani F, Lagomarsino D, Segoni S, Tofani V (2013) Landslide susceptibility estimation by random forests technique: sensitivity and scaling issues. Nat Hazards Earth Syst Sci 13:2815–2831. |
| [18] | Youssef, AM., Pourghasemi, HR., Pourtaghi, ZS., Al-Katheeri, MM., 2015. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah basin, Asir Region, Saudi Arabia. Landslides. DOI: 10.1007/s10346-015-0614-1. |
| [19] | Tsangaratos, P., Ilia, I., Hong, H., Chen, W., Xu, C., 2016. Applying Information Theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng County, China. Landslides, DOI: 10.1007/s10346-016-0769-4. |
| [20] | Zare, M., Pourghasemi, H., Vafakhah, M., Pradhan, B., 2013. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: a comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arabian Journal of Geosciences, 6(8), 2873-2888. |
| [21] | Conforti, M., Aucelli, PP., Robustelli, G., Scarciglia, F. 2011. Geomorphology and GIS analysis for mapping gully erosion susceptibility in the Turbolo stream catchment (Northern Calabria, Italy). Nat Hazards 56(3):881–898. |
| [22] | Ozdemir, A., Altural, T., 2013. A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J Asian Earth Sci 64:180–197. |
| [23] | Ilia, I., Tsangaratos, P., 2016. Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides 13(2):379-397. |
| [24] | Devkota, KC., Regmi, AD., Pourghasemi, HR., Yoshida, K., Pradhan, B., Ryu, CI., Dhital, MR., Althuwaynee, OF., 2012. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Natural Hazards (65):135-165. |
| [25] | Jaafari, A., Najafi, A., Pourghasemi, HR., Rezaeian, J., Sattarian, A., 2014. GIS-based frequency ratio and index of entropy models for landslide susceptibility assessment in the Caspian forest, northern Iran. Int J Environ Sci Technol 11:909–926. |
| [26] | Youssef, AM., Al-Kathery, M., Pradhan, B., 2015. Landslide susceptibility mapping at Al-Hasher area, Jizan (Saudi Arabia) using GIS-based frequency ratio and index of entropy models. Geosci J 19:113–134. |
| [27] | Guzzetti, F., Carrara, A., Cardinali, M., Reichenbach, P., 1999. Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology, 31, 181–216. |
| [28] | Feizizadeh, B., Roodposhti, MS., Jankowski, P., Blaschke, T., 2014. A GIS-based extended fuzzy multi-criteria evaluation for landslide susceptibility mapping. Computers & Geosciences, 73, 208–221. |
| [29] | Ballabio, C., Sterlacchini, S., 2012. Support Vector Machines for Landslide Susceptibility Mapping: The Staffora River Basin Case Study, Italy. Mathematical Geosciences, 44(1), 47-70. |
| [30] | Demsar, J., Curk, T., Erjavec, A., Gorup, C., Hocevar, T., Milutinovic, M., Mozina, M., Polajnar, M., Toplak, M., Staric, A., Stajdohar, M., Umek, L., Zagar, L., Zbontar, J., Zitnik, M., Zupan, B., 2013. Orange: Data Mining Toolbox in Python. Journal of Machine Learning Research 14(Aug):2349−2353. |
| [31] | Cortes, C., Vapnik, V., 1995. Support-Vector Networks. Machine Learning, 20(3):273–297. |
| [32] | Cheeseman, P., Stutz, J., 1996. Bayesian classification (AutoClass): Theory and results. In Advances in knowledge discovery and data mining, 153–180. Menlo Park, CA: AAAI Press. |
| [33] | Soria, D., Garibaldi, JM., Ambrogi, F., Biganzoli, EM., Ellis, IO., 2011. A “non-parametric” version of the naive Bayes classifier. Knowledge-Based Systems, 24(6), 775–784. |
| [34] | Pham, BT., Pradhan, B., Tien Bui, D., Prakash, I., Dholakia, MB., 2016. A comparative study of different machine learning methods for landslide susceptibility assessment: a case study of Uttarakhand area (India). Environ Modell Softw. 84:240–250. |
| [35] | Can, T., Nefeslioglu, HA., Gokceoglu, C., Sonmez, H., Duman, TY., 2005. Susceptibility assessments of shallow earthlows triggered by heavy rainfall at three catchments by logistic regression analysis. Geomorphology 72(1–4): 250–271. |
| [36] | Pradhan, B., Lee, S., 2010. Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environmental Earth Sciences, 60, 1037–1054. |
| [37] | Tien Bui, D., Pradhan, B., Lofman, O., Revhaug, I., 2012. Landslide susceptibility assessment in Vietnam using support vector machines, decision tree, and Naive Bayes models. Math Probl Eng. 2012:1–27. |

 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTML