-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Statistics and Applications
p-ISSN: 2168-5193 e-ISSN: 2168-5215
2021; 11(4): 79-83
doi:10.5923/j.statistics.20211104.01
Received: Aug. 4, 2021; Accepted: Sep. 6, 2021; Published: Nov. 15, 2021

Adversarial Risk Analysis Structural Equation Model Estimators of Big Data
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLBoakye Agyemang1, 2, Bashiru I. I. Saeed3, Albert Luguterah2, Samuel Baffoe1, Daniel Mbima1
1Department of Applied Mathematics, Koforidua Technical University, Faculty of Applied Sciences and Technology, Koforidua, Ghana
2University for Development Studies, Faculty of Mathematical Sciences, Department of Statistics, Navrongo, Ghana
3Tamale Technical University, Faculty of Applied Sciences and Technology, Tamale, Ghana
Correspondence to: Boakye Agyemang, Department of Applied Mathematics, Koforidua Technical University, Faculty of Applied Sciences and Technology, Koforidua, Ghana.
| Email: |  |
Copyright © 2021 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

This paper seeks to discover the estimators to support decisions in relation to adversarial risk analysis structural equation models of big data using the concept of adversarial risk analysis structural equation modelling (ARA-SEM). A comparative literature examination of hundred (100) related articles published between 2007 and 2020 was employed in the study for the analysis. The results reveal twenty-four (24) eminent estimators discovered to be used in the modelling process. The study concludes that these estimators must be assessed with regard to their properties of statistical significance, unbiasedness, consistency and as well as efficiency in the modeling process of the model.
Keywords: Estimates, Estimators, Adversarial Risk Analysis (ARA), Structural Equation Model (SEM), and Adversarial Risk Analysis-Structural Equation Model (ARA-SEM)
Cite this paper: Boakye Agyemang, Bashiru I. I. Saeed, Albert Luguterah, Samuel Baffoe, Daniel Mbima, Adversarial Risk Analysis Structural Equation Model Estimators of Big Data, International Journal of Statistics and Applications, Vol. 11 No. 4, 2021, pp. 79-83. doi: 10.5923/j.statistics.20211104.01.
Article Outline
1. Introduction
- According to ISO (31000:20095) risk refers to the “effect of uncertainty on defined objectives” using probability of occurrence of event as the measurement framework. The assessment and analysis of statistical risk is very crucial and critical in making informed and intelligent decisions particularly for optimum decision science (Boakye et al, 2021). This is the surest way of avoiding overly ambitious or skyrocketing forecasting or otherwise as far as the application of decision science is concerned. Big data as the non-conventional strategies and innovative technologies applied by businesses and organizations to capture, manage, process, and make sense of huge amount of data requires special or new inductive approach in dealing with such data (Reed, 2017). This is as a result of the big characteristics big data which introduces statistical risks and adversaries known as intelligent opponents whose main aims are to intentionally pose threats to systems in an intelligent manner that is very difficult to detect (Zhaohao, 2018; IBM, 2015). The ISF (2016) corroborates through specifying several adversarial threats within its catalogue which has attracted the attention of researchers such as Rios et al (2009), Banks et al (2015), Ibrahim et al (2015) Kantarcioglu and Xi (2016), among others delving into adversarial risk analysis. The approaches used by the above-mentioned researchers deals widely with adversarial risk analysis (ARA) to model the intentions and strategic behaviour of adversaries in the cybersecurity domain in particular and as a two-player game in ordinary data rather than big data. Furthermore, Ibrahim et al (2015) reveal that big data analysis requires a combination of analytical techniques and technologies that include new applications to derive benefit or insights from such data. The aim of this paper therefore is to develop methods to support decisions in relation to adversarial risk analysis of big data by particularly determining some adversarial risk estimators to be derived from big data analysis using adversarial risk analysis structural equation modelling. This would be achieved through the development and application of new a inductive statistical concept to infer laws regarding the determination of the estimators, the models and as well as their fit indices regarding adversarial risks in big data (Billings, 2013).
2. Methodology
- The main methodology adopted in this study is the exploratory literature survey of related works particularly with respect to adversarial risk and structural equations models. This is as a result of the fact that the modelling approach combines risk analysis in statistics, the theory of games, and structural equation models to derive interactional adversarial risk problem formulations, and also to provide a model that will extend existing risk analysis models. A total of hundred (100) related works published between 2007 and 2020 were reviewed in the determination of the estimators coupled with some proposed assumptions as listed below. The approach has been utilized by Amado, A., Cortez, P., Paulo, R. and Sérgio, M. (2017) in their work on research trends on big data in marketing, a text mining and topic modeling based literature analysis. The following conditions therefore must be set out to perform adversarial risk assessment:i. there exist disruptive events or actions or decisions e1, e2, ..., e∞;ii. events and decisions are assumed to be independent;iii. these actions or decisions are interactive in nature;iv. the probabilities of occurrence exist, and may be uncertain, i.e
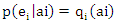 .v. the costs (ci’s) are conditioned on the occurrence of ei’s and decision which are also typically random and the assessment may be a distribution.vi. there is the presence of adversaries which changes the risk analysis probabilities from being conditioned on one event to being conditioned on two or more events.vii. the distribution of the adversarial risk estimates must be normally distributed.
.v. the costs (ci’s) are conditioned on the occurrence of ei’s and decision which are also typically random and the assessment may be a distribution.vi. there is the presence of adversaries which changes the risk analysis probabilities from being conditioned on one event to being conditioned on two or more events.vii. the distribution of the adversarial risk estimates must be normally distributed.3. Results, Discussions and Findings
3.1. Estimators in Adversarial Risk Analysis Modelling of Big Data
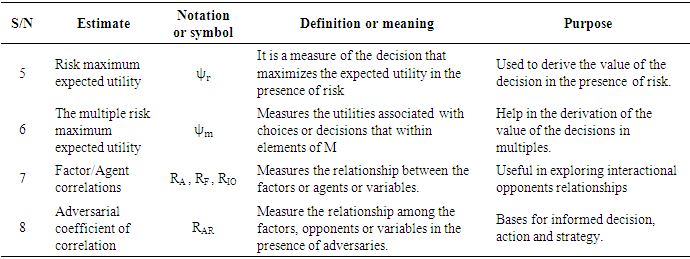
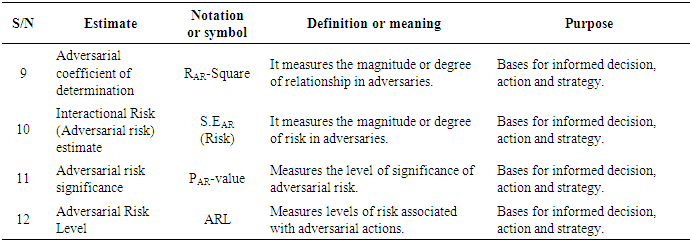
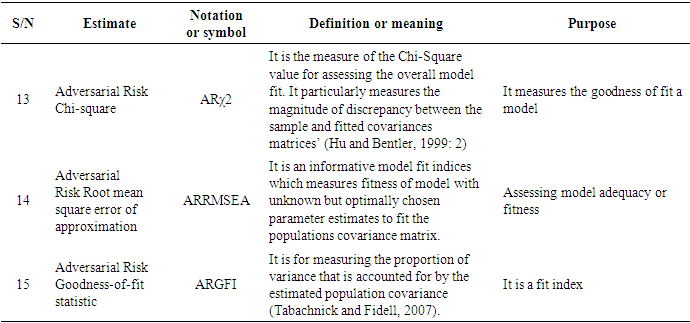
- Since the adversarial risk analysis combined with structural equation modelling is a virtually new concept which is being proposed by this very research, it was intended to explore some possible estimates that could spur the debate and the research in this area as already indicated in the methodology.The following estimates have therefore been identified, denoted and defined as summarised in Tables 1a to h.
|

|
|
|
|

|

|

|

3.2. Discussions and Findings
- Twenty-four (24) estimates of adversarial risk analysis structural equation modelling have been deduced from existing literature, the modelling process and as well as the model assumptions giving rise to entirely new discovery propounding approach to propel adversarial risk analysis modelling especially in big data. From literature, fourteen (14) of the estimators were obtained from Schreiber et al (2010) and remaining ten (10) also based on the assumptions and the modelling process of the ARA-SEM model. This result is consistent with Schreiber et al (2010) particularly on the fit indices, however, it gives an enhancement to the outcome and recommendation of Schreiber, et al (2010) in their work on reporting structural equation modelling and confirmatory factor analysis results primarily due to the addition of the adversarial estimators. The results further imply that since the estimators are consistent with previous studies, they are therefore adopted in the analysis of adversarial risk analysis structural equation models and other related models as well.
4. Conclusions and Recommendations
- The study concludes first and foremost that since the estimates are consistent with previous studies, they are therefore adopted in the analysis of adversarial risk analysis structural equation models and other related models as well. Finally, the paper recommends based on the conclusion that the estimators of the discovered estimates should be explored in order to provide the path for their use in the proposed modelling approach including their statistical properties of significance, unbiasedness, consistency and as well as efficiency in this modeling process of the ARA-SEM model. This recommendation is supported by Adepoju (2007) that properties of estimators should be of interest to researchers after they have deduced them for the typical samples.