-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Statistics and Applications
p-ISSN: 2168-5193 e-ISSN: 2168-5215
2020; 10(5): 113-117
doi:10.5923/j.statistics.20201005.01
Received: Jul. 15, 2020; Accepted: Aug. 23, 2020; Published: Sep. 26, 2020

A Comparison of Two Hybrid Approaches for Improving Neural Network “Simulation Study”
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLMohammed Abou Elfettouh Ghazal1, Asaad Ahmed Gad Elrab2, Wafa Hamed Abd Allah1
1Mathematical Statistics, Faculty of Science, Damietta University, Damietta, Egypt
2Mathematics Department, Faculty of Science, Al-Azhar University, Cairo, Egypt
Correspondence to: Wafa Hamed Abd Allah, Mathematical Statistics, Faculty of Science, Damietta University, Damietta, Egypt.
| Email: |  |
Copyright © 2020 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Traditional statistical models work on the assumption of linearity and stationary of time series. Machine learning models such as Artificial Neural Network (ANN) and Support Vector Regression (SVR) suffer the problem of over-fitting and are sensitive to parameter selection, respectively. This paper propose two models that integrates Statistical Empirical Mode Decomposition (SEMD) and ANN and Ensample Empirical Mode Decomposition and ANN for improve the weakness of ANN. SEMD and EEMD are an adaptive technique that shifts the non-stationary and non-linear time series data till it becomes stationary. In first stage, the data is decomposed into a smaller set of Intrinsic Mode Functions (IMFs) and residuals using EEMD and SEMD. In the next stage, IMFs and residue are taken as the inputs for the ANN model. The methodology was compared with EEMD-ANN and SEMD-ANN models. The results suggest that the SEMD-ANN is better than EEMD-ANN.
Keywords: Empirical mode decomposition, Statistical empirical mode decomposition, Ensample empirical mode decomposition, Artificial neural network, Support vector regression, Discrete wavelet transform, Intrinsic mode functions
Cite this paper: Mohammed Abou Elfettouh Ghazal, Asaad Ahmed Gad Elrab, Wafa Hamed Abd Allah, A Comparison of Two Hybrid Approaches for Improving Neural Network “Simulation Study”, International Journal of Statistics and Applications, Vol. 10 No. 5, 2020, pp. 113-117. doi: 10.5923/j.statistics.20201005.01.
Article Outline
1. Introduction
- Machine learning models such as Artificial Neural Network (ANN) and Support Vector Regression (SVR) suffer the problem of over-fitting and are sensitive to parameter selection, respectively [1], [2]. Hence, a slightest improvement in the prediction accuracy attracts researchers. Recently, several signal processing techniques like Discrete Wavelet Transform (DWT) and Empirical Mode Decomposition (EMD) have been used for decomposing the series in time-frequency domain and time domain, respectively [5], [6]. The process of decomposition can be considered as a data pre-processing technique for machine learning models. EMD, proposed by [4], and its extensions SEMD and EEMD decomposes a signal into a set of adaptive basis functions called Intrinsic Mode Functions (IMFs). It uses Huang-Hilbert Transform (HHT) to decompose the non-stationary and non-linear time series. Unlike DWT, it does not require the a priori information about the series, i.e, the scale of decomposition. Though DWT can handle non stationary data, it still requires linear generating process and suffers from leakage between the scales [3]. In any model building process, especially machine learning process, selection of appropriate features is considered to be an important step. There are two types of features: (1) feature vector approach, (2) scale-based approach. Time series analysis traditionally seek out for appropriate model to fit the data; this is difficult by the fact that the data is typically non-stationary, with non-linear relationships between past and future values and conduct occurring instantaneously at diverse time scales. Adaptive data analysis methods or signal analysis methods such as Empirical Mode decomposition (EMD).Review: Statistical Empirical Mode DecompositionStatistical Empirical Mode Decomposition are a techniques designed to decompose a signal into its intrinsic modes [9], with each mode constrained to a limited frequency band and has seen extensive practice in the part of financial analysis. What makes EMD, SEMD, and EEMD attractive in financial analysis is that it is an empirically based method that is a posteriori and adaptive, permitting the data to speak for itself. No a priori assumptions are requisite, as is the case with traditional time-frequency methods such as Fourier or wavelet analyses. The time-frequency components obtained from above mentioned tools can simplify this task by allowing one to examine the series for one intrinsic mode function (IMF) at a time and over time horizons that are ideal for the particular IMFs. While adaptive data analysis tools are traditionally used to analyses the individual modes of a time series, usage of the method as a filter has also been recognized [4], [8]. An advantage of EMD, SEMD and EEMD-filtering are that the data still retains its nonlinearity and non-stationary, which is not the case when using conventional filtering techniques.This article proposes an ANN model applied to data filtered with a novel adaptive data tools-filtering technique for multi-stage prediction. The SEMD and EEMD-filtered ANN model will be tested and will be compared with an EMD-ANN applied to unfiltered data as well as to a random walk model in terms of accuracy of predictions and simulated returns on an investment.In former, the IMFs at a particular time point are taken as a feature vector, while in the latter, the IMFs are predicted independently at each level and the results are combined [7]. The paper compared hybrid SEMD-ANN and EEMD-ANN techniques signal is first decomposed to different sub-series (IMFs) using SEMD and EEMD. Then, these sub-series are independently using ANN. In brief, scale-based approach has been used. The hybrid SEMD-ANN model integrates the benefits of both EEMD-ANN.Section 2 will summarize hybrid SEMD-ANN and EEMD-ANN. Section 3 will introduce the EEMD method, illustrate more details of the drawbacks associated with mode mixing, present concepts of noise-assisted data analysis and of noise-assisted signal extraction, and introduce the EEMD in detail and statistical empirical mode decomposition SEMD. Section 4 will display the usefulness and capability of the EEMD-ANN and SEMD-ANN through simulation study. A summary and conclusion will be presented in the final section.
2. Hybrid SEMD-ANN, EEMD-ANN and EMD-ANN Framework
- The flow chart of the SEMD-ANN and EEMD model is shown in figure 1. The detailed steps are enumerated below:1. The original series is decomposed into a set of different sub-series using Statistical Empirical Mode Decomposition and Ensample Empirical Mode Decomposition.2. Each sub-series is combined separately using ANN.3. Calculate the Mean Square Error (MSE) to compare between the results.
 | Figure 1. Flow Chart of Hybrid SEMD-ANN and EEMD-ANN Approach |
2.1. Steps of ANN
- Network structure, input data format and training algorithm play an important role in the performance of the neural network. Network structure: Here, based on previous studies [5], [6], a three-layer resilient feed forward neural network consisting of input layer, hidden layer and output layer, is considered to predict the non-linear time series. Input data format: Each decomposed series should be predicted individually using ANN model. Training Algorithm: In this study, Resilient Back Propagation (RBP) is used for training the neural network. compared to commonly used Back Propagation algorithm, RBP helps to achieve superior performance [6].
3. Methodology
3.1. Ensample Empirical Mode Decomposition
- To mitigate the scale part-ion difficulty without presenting a subjective intermittence test, a new noise-assisted data analysis techniques is invented, the Ensemble EMD (EEMD), which outlines the true IMF components as the mean of an ensemble of trials, each containing of the signal plus a white noise of finite amplitude. With this ensemble methodology, we can undoubtedly separate the scale certainly without any a priori subjective criterion selection. This new method is based on the insight gleaned from recent studies of the statistical properties of white noise (Flandrin, et al., 2004, and Wu and Huang, 2004), which indicated that the EMD is excellently an adaptive dyadic filter bank 1 when applied to white noise. More critically, the new approach is encouraged by the noise added analyses initiated by Flandrin et al. (2005) and Gledhill (2003). Their results established that noise could support data analysis in the EMD. The main idea of the EEMD is simple: the added white noise would populate the whole time-frequency space uniformly with the constituting components of different scales separated by the filter bank. When signal is added to this uniformly distributed white background, the bits of signal of different scales are mechanically projected onto proper scales of reference recognized by the white noise in the background. Of course, each single may create very noisy outcomes, for each of the noise-added decompositions consists of the signal and the added white noise. Since the noise in each trial is changed in separate trials, it is canceled out in the ensemble mean of enough trails. The ensemble mean is treated as the true answer, for, in the end, the only persistent part is the signal as more and more trials are added in the ensemble.The critical theory advanced here is based on the following observations: 1. A collection of white noise cancels each other out in a time space ensemble mean; therefore, only the signal can survive and persist in the final noise-added signal ensemble mean. 2. Finite, not infinitesimal, amplitude white noise is necessary to force the ensemble to exhaust all possible solutions; the finite magnitude noise makes the different scale signals reside in the corresponding IMF, dictated by the dyadic filter banks, and render the resulting ensemble mean more meaningful.3. The true and physically meaningful answer of the EMD is not the one without noise; it is designated to be the ensemble mean of a large number of trials consisting of the noise-added signal. This EEMD anticipated here has employed all these important statistical characteristics of noise. We will proof that the EEMD utilizes the scale separation principle of the EMD, and enables the EMD method to be a truly dyadic filter bank for any data. By adding finite noise, the EEMD removes mode mixing in all cases mechanically. Therefore, the EEMD represents a major improvement of the EMD method.
3.2. Statistical Empirical Mode Decomposition
- New approach called (Statistical Empirical Mode Decomposition) discovered in 2012 by (Donghoh Kim, Kyungmee O Kim and Hee-Seok Oh), [10] as an extension of EMD. The suggested algorithm is intended for considering noisy signals that are used in the area of statistics. Thus, we call the proposed algorithm statistical EMD (SEMD). Officially, the SEMD procedure can be specified as follows: 1. ((Modified sifting) Take a signal x to be decomposed, and extract the first mode h1,O by using a smoothing technique. (A-1) Classify the local maxima (minima) Z of the signal
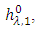 where
where 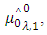 is the original signals ×.(A-2) Build an upper envelop
is the original signals ×.(A-2) Build an upper envelop 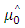 ((lower envelope
((lower envelope 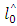 ) by applying a smoothing technique with a smoothing parameter
) by applying a smoothing technique with a smoothing parameter 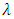 to the maxima (minima) z.(A-3) Calculate the local mean
to the maxima (minima) z.(A-3) Calculate the local mean 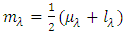 by the average of both the envelopes, and then get a candidate intrinsic mode
by the average of both the envelopes, and then get a candidate intrinsic mode 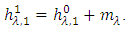 (A-4) Replicate steps (A-1)–(A-3) for the signal
(A-4) Replicate steps (A-1)–(A-3) for the signal 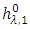 until the signal
until the signal 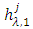 at the jth iteration satisfies the IMF conditions.(A-5) Decompose the signal
at the jth iteration satisfies the IMF conditions.(A-5) Decompose the signal 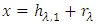 where
where 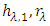 is defined as the limite of
is defined as the limite of 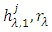 is the remaining signal.2. If the remaining signal
is the remaining signal.2. If the remaining signal 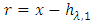 has an intrinsic oscillation mode, then or can be further decomposed by conventional sifting.
has an intrinsic oscillation mode, then or can be further decomposed by conventional sifting.4. Simulation Study
- In this simulation, the software package R was employed to evaluate classical ANN, and the proposed combined method, SEMD-ANN. The following conditions were set at Table 1. (1) Four different test functions.(2) Two different samples size (50, and 100).
|
 | Figure 2. Presents the observations of each test function from Table 1. such as discontinuities or sharp bumps |
5. Results and Discussion
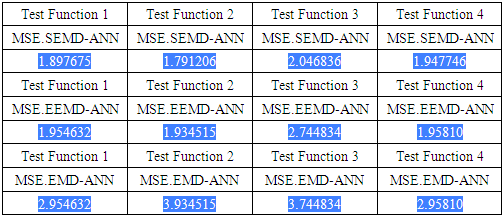
- Table 2 below shows that the suggested method performs better in terms of noise structures and test functions, under different samples size and 4k-fold cross validation. It is therefore understood that SEMD-ANN is highly recommended in handling non-linear and non-stationary signals.
|
6. Conclusions
- This paper submitted a two-stage method to minimize issues in conventional ANN. Coupling SEMD at early stages followed by conventional ANN combination is the crucial design of the proposed method. A simulation was carried out to test the empirical performance of the technique through simulation experiments. Findings from this study showed that SEMD can be improved and resolve issues of non-linear and non-stationary signals, and enhance MSE values.
Availability of Data and Materials
- All data generated and analyzed during this study are included within this article.
ACKNOWLEDGEMENTS
- This work of AbdAllah.W.H was supported by the Mathematical Statistics-Faculty of science- Damietta University of Egypt funded by the Arab Republic of Egypt Government (AREG). This research of Ghazal.M.A. was supported by Damietta University, Faculty of Science at the Mathematical Department funded by the by the Arab Republic of Egypt Government (AREG).
List of Abbreviations
- ANN: Artificial Neural NetworkDWT: Discrete Wavelet TransformEMD: Empirical Mode DecompositionEEMD: Ensample Empirical Mode DecompositionEEMD-ANN: Ensample Empirical Mode Decomposition of Artificial Neural NetworkHHT: Huang-Hilbert TransformIMF: Intrinsic Mode FunctionIMFs: Intrinsic Mode FunctionsMSE: Mean Square ErrorSVR: Support Vector RegressionSEMD: Statistical Empirical Mode DecompositionSEMD-ANN: Statistical Empirical Mode Decomposition of Artificial Neural Network