-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Statistics and Applications
p-ISSN: 2168-5193 e-ISSN: 2168-5215
2018; 8(2): 72-78
doi:10.5923/j.statistics.20180802.06

Ridge Parameter in Quantile Regression Models. An Application in Biostatistics
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLAli Sadig Mohommed Bager
Department of Statistics and Econometrics, The Bucharest University of Economic Studies, Muthanna University, Iraq
Correspondence to: Ali Sadig Mohommed Bager, Department of Statistics and Econometrics, The Bucharest University of Economic Studies, Muthanna University, Iraq.
| Email: |  |
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

In quantile regression, usually the explanatory variables in medical data are highly correlated with each other. Thus, the influence of one variable can't be differentiated from the others. Also, multicollinearity generates unstable regression coefficients with undesirable large variances. It is possible that the estimated coefficients may have the incorrect signs and present problems in the interpretation. In this paper ridge regression is applied to solve the problem of multicollinearity. An optimum ridge coefficient for the ridge regression parameter can be estimated through Bayesian approach. The Bayesian approach is a method to stabilize the ridge parameter. The quantile regression is the best method to predict an extreme value. This study discusses the use of ridge regression in quantile regression with a parameter ridge. Variance inflation factor (VIF) is used to determine the best ridge coefficient. The results show that the quantile regression with ridge regression was suitable for the study of the causes of genetic anemia (Thalassemia) in children.
Keywords: Quantile regression, Ridge regression, Bayesian approach, Genetic blood diseases (Thalassemia)
Cite this paper: Ali Sadig Mohommed Bager, Ridge Parameter in Quantile Regression Models. An Application in Biostatistics, International Journal of Statistics and Applications, Vol. 8 No. 2, 2018, pp. 72-78. doi: 10.5923/j.statistics.20180802.06.
Article Outline
1. Introduction
- Thalassemia is an inherited disease that is transmitted from parents to children across genes and affects the ability to produce hemoglobin in the human body, leading to severe anemia. The most common type is found among children with anemia in all parts of world. This disease is caused by genetic acquired factors. Iron deficiency anemia affects a large number of children, and significantly more than other types of anemia in poor and developing countries, where there is an increased incidence of some infections [1]. The World Health Organization has calculated that about 7% of the world’s population carry a hemoglobinopathy gene [2]. In the Mediterranean area, there are 15 to 25 million of healthy carriers [3]. Iraq is one of the countries with health, environmental and economic difficulties [4]. The statistics announced by government agencies on blood diseases confirmed high rates of patients with Thalassemia in the last few years, especially among children. The increase in the incidence of infection is due to several reasons, including the remnants of war and its impact on generations as well as the genetic factor and lack of health awareness among people.Statistics show that the of Thalassemia patients has increased significantly in recent years. After the 2003 war that the rates of this genetic blood diseases in children in Iraq has risen to 22 cases per 100 thousands children compared with 2002, when it only appeared in 4 children out of 100,000 children. This number is much higher compared to neighboring countries. Children with Thalassemia need a life-long treatment of regular blood transfusion and iron chelation. Thalassemia has negative impact on many aspects of the life for children.Thus, it is necessary to acknowledge the causes of the disease and the variables that cause infection with the disease. In this case, the Quantile regression models help define the relationship between a set of proposed predictor variables and the specific quantiles of the response variables analogous to a linear regression, which investigate the mean value of the response variables for a given set of predictor variables [5]. Quantile regression leads to a more comprehensive analysis by estimating the changes in specific quantiles of the response variables with respect to predictor variables, providing relationship at different points in the conditional distribution of the response variable. Since the pioneering research of Koenker and Bassett [6], quantile regression models have been the topic of major theoretical interest as well as many practical applications in many different areas such as: economics, survival analysis, microarray study, growth chart, finance, biomedical studies. A comprehensive account of these recent applications can be found in Koenker [7], and Cade and Barry [8]. The ridge parameter in quantile regression is employed to address the most important challenges that may arise with medical data, such as multicollinearity [9]. This problem arises because of the high correlation between the independent variables that lead to weak estimates. It is important to note the fact that in analysis of factors affecting the incidence of Thalassemia, the variables in the phenomenon under study are linked to each other in one way or another, either directly or indirectly. The existence of these relationships have several effects on the results of the analysis obtained. Nevertheless, existing literature shows that this issue is not adequately addressed. Many researchers have pursued different aspects and ways of solving multicollinearity. In 1975, Hoerl and Kennard developed a new method by adding a positive value (k) to the elements of the information matrix, the so called ridge parameter [10].The ridge estimator is used to solve the identification problem that can be viewed from a Bayesian perspective (Congdon, [11]). In this paper we will use Bayesian methods to choose the ridge parameter.In 2013, Cule, E. and De Iorio, M. identified numerous genetic associated with diverse phenotypic traits. However, the identified associations generally explain only a small proportion of trait heritability and the predictive power of models incorporating only known-associated variants has been small, considering the joint effect of many genetic variants simultaneously. The study found ridge regression, a penalized regression approach that has been shown to offer good performance in multivariate prediction problems [12].The variance is higher in the OLS method if in the multiple regression model, the linear correlation between explanatory variables is high [13]. The results of this study were obtained by using ridge regression study. Also, the authors showed that the best results are achieved with the ridge regression method of Hoerl and Kennard’s. Bager et al. (2017) aimed to determine the most important macroeconomic factors which affect the unemployment rate in Iraq by using a ridge regression method, one of the most widely used methods for solving the multicollinearity problem [14].This paper aims to use the ridge parameter in the quantile regression to address important challenges, such as the multicollinearity problem. A Bayesian method is used for estimation of the ridge parameter in quantile regression. Because this technique could provide an important research tool, it may help to find the most appropriate value for the parameter. The paper would also contribute to develop a robust statistical model to identify the most important factors affecting patients with thalassemia across various quantile ratios. The model helps rank the relevant factors affecting patients. The findings of the study can be potentially useful for the identification of the causes of the disease in order to reduce its incidence.The paper structure is the following: section two provides ridge regression method, section three includes the ridge and quantile regression models, section four covers the test of the multicollinearity problems, section five is the application to the case study and section six includes the conclusions.
2. Ridge Regression Method
- The history of multicollinearity dates back at least to the paper of Frisch (1934) who introduced the concept in order to describe a situation where the variables dealt with are subject to two or more relations. One way to approach this problem is called the ridge regression, first introduced by Horel and Kennard [15] who suggested an alternative method to the standard method of ordinary least squares (OLS). The ordinary ridge regression method (ORR) has become one of the most applied solutions for addressing the problem of semi-multicollinearity.The method implies adding a small positive constant (K) to the main diagonal elements of the information matrix (XTX). This positive value, known as the ridge parameter, decodes the links between the explanatory variables. The ORR method can be written as follows:
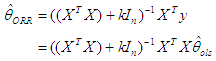 | (1) |
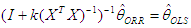 | (2) |
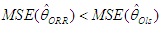 | (3) |
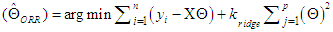 | (4) |
3. Ridge and Quantile Regression Models
- In quantile regression there should be no multicollinearity in predictor variables. We will address this problem by using the ridge regression which can overcome the multicollinearity problem. An optimum ridge coefficient can be estimated through many methods. The quantile regression model has the following form [7]:
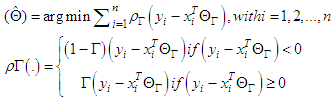 | (5) |
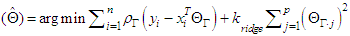 | (6) |
3.1. Estimator Parameter (k)
- The multiple linear regression model can be expressed as:
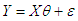 | (7) |
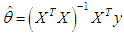 | (8) |
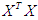 has the orthogonal conversion p; it results that
has the orthogonal conversion p; it results that 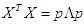 and the matrices p and Λ are matrices eigenvalue and eigenvector for matrix
and the matrices p and Λ are matrices eigenvalue and eigenvector for matrix 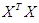 .
. 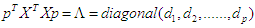 where di is the eigenvalue of number j of the matrix
where di is the eigenvalue of number j of the matrix 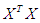 and
and 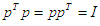 . The orthogonal (canonical form) version of the multiple regression model (7) is [19] [20]:
. The orthogonal (canonical form) version of the multiple regression model (7) is [19] [20]: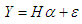 | (9) |
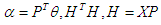 | (10) |
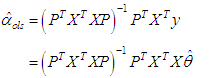 | (11) |
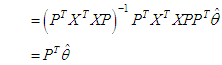 | (12) |
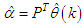 .From equation (8) we can write:
.From equation (8) we can write: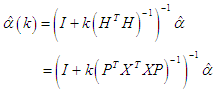 where:
where: 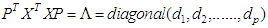 .The equation above simplified:
.The equation above simplified: 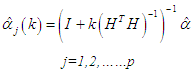 | (13) |
3.2. Bayesian Approach to Estimator Parameter (k)
- Ridge regression has a close connection to Bayesian linear regression. The first review of the Bayesian derivation and interpretation of the ridge estimator along the line was provided by Loesgen [22]. The ridge estimator proposed to solve the identification problem can be viewed from a Bayesian perspective [8]. To the estimate ridge parameter, we depend on the result. Lindely and Smith [19] express the formula into Bayesian for estimating the linear regression model through an appreciation multi stages and use multivariate normal prior distribution when the parameter is unknown at every stage of the analysis. In this case, the prior is considered to be marginal distribution:
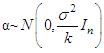 .The posterior distribution can be rewritten to depend on Bayesian estimator k as follows [1], [23]:
.The posterior distribution can be rewritten to depend on Bayesian estimator k as follows [1], [23]: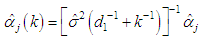 | (14) |
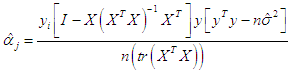 | (15) |
4. Test Multicollinearity Problems (Farrar & Glauber Test)
- This test is based on a Chi square test (x2) to determine whether or not there is a multicollinearity problem in the estimated model.The test formula is:
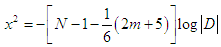 | (16) |
5. The Sample and Data Analysis
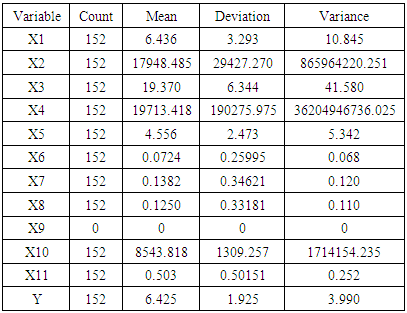
- The inasmuch prevalence of genetic blood diseases (Thalassemia) varies among areas of Iraq with the highest incidence of infections in the middle Al-Forat region and southern Iraq, according to the Iraqi Ministry of Health (National Cancer Council). This study was conducted to determine the factors affecting the children infected with some genetic anemia (Thalassemia). The sample was taken for 152 patients from centers for the treatment of blood diseases in that areas during 2016. This paper used the quantile regression model at four quantile levels (0.25, 0.50, 0.75, 0.95) respectively, because quantile regression has attractive properties. The variables that are thought to affect the disease were selected after the consultation of doctors specialists and practitioners in genetic anemia (Thalassemia). The following table (Table 1) describes the variables:
|
|
5.1. Testing the Multicollinearity Problems
- We calculated the Chi square test (x2). To apply this test, these steps were followed:a. test hypothesis:H0=XJ nonexistence multicollinearity problemH1=XJ existence multicollinearity problemb. calculate the Chi- square test (x2):
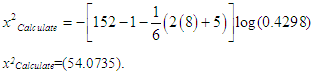 | (17) |
5.2. Determine the Causative Variables of the Multicollinearity Problems
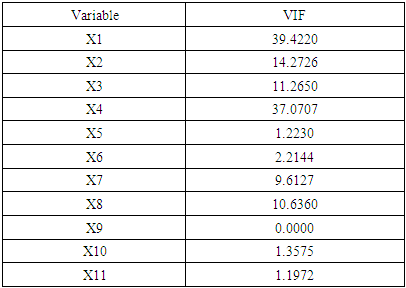
- In order to determine the variables causing the problem of linear multiplicity the Variance Inflation Factor (VIF) will be used, which measures the inflation of the parameter estimates for all explanatory variables in the model. These indicators were computed for the regression parameters of all the explanatory variables of the model. The multicollinearity between the explanatory variables was determined with the following results:
|
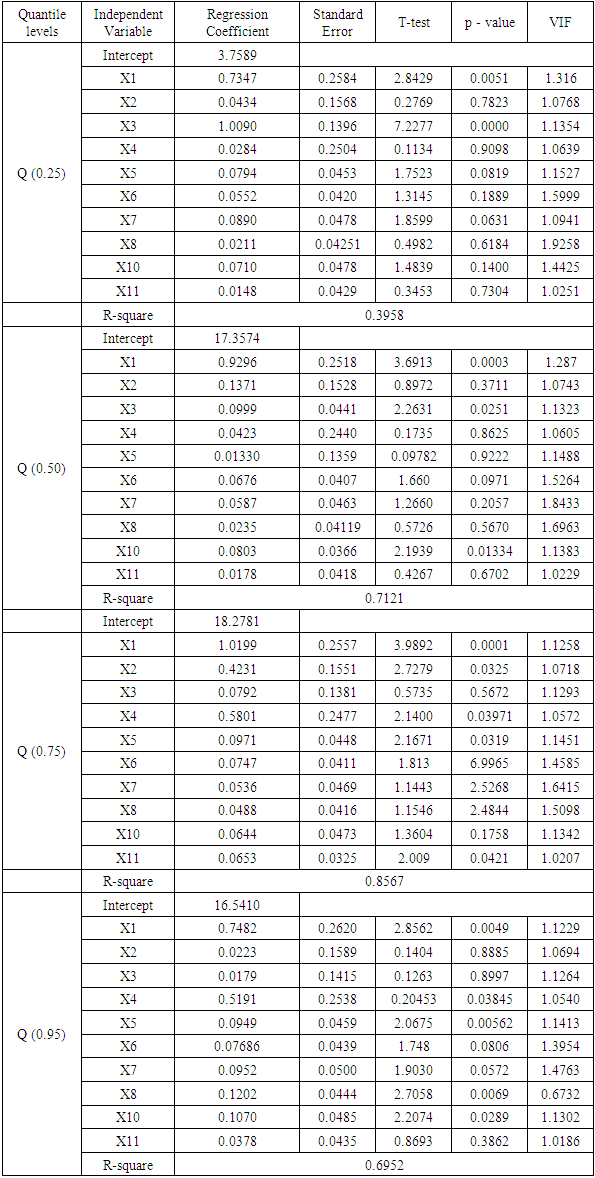
5.3. Ridge Quantile Regression Analysis
- This method allows the estimation of the quantile regression models established by ridge coefficients. These coefficients are selected based on the Bayesian method for parameter (k) estimation. This method was used to find the best value of the ridge parameter in accordance with formula (15). Using R package the following result was reached: 𝑘 = 0.02578. Table 4 shows the results for each quantile coefficients.The results presented in Table 4. for the coefficient estimation at the quantile levels 0.25, 0.50, 0.75 and 0.95 show the following: a. At the quantile level (0.25): the variables X1 and X3 have a significant effect on the dependent variable according to p-value and R-square (0.3958); this means the independent variables can explain 39.5% of the variation in the dependent variable. This quantile level is weak in interpreting the data of the phenomenon under study. The VIF values for X1 and X3 are 1.1316 and 1.1354, respectively. That is an indicator that the multicollinearity problem is solved.b. The results were quantile level 0.50 showed that the variables X1, X3, X10 have a significant effect on the dependent variable. The R-square value (0.7121) indicates that the independent variables can explain 71.2% of the variation in the dependent variable. This level is also weak in interpreting the data of the phenomenon under study. The VIF values for X1, X3, X10 are 1.2870, 1.1323 and 1.1383, respectively. This is an indicator that the multicollinearity problem is solved.c. The results at the quantile level 0.75, indicate that the variables X1, X2, X4, X5 and X11 have a significant effect on the dependent variable (Incidence of anemia in children, Thalassemia). The R-square (0.8567) shows that the independent variables, can explain 85.6% of the variation in the dependent variable. This quantile level is strong and the variables have a direct correlation with the response variable except three variables (X3, X6, X7, X8 and X10). These variables have weak effect according to this measure, all the results are logical by the medical side. The VIF values for X1, X2, X4, X5 and X8 are 1.1258, 1.0718, 1.057, 1.1451, and 1.0207. This indicates that the multicollinearity problem is solved.d. At quantile level 0.95, the variables X1, X5, X8 and X10 have a significant effect on the adopted variable. The value of R-square (0.6952) shows that the independent variables can explain 69.5% of the variation in the independent variable. This ratio is small and can't be used to interpret the results.Finally, the last step of our analysis is to compare the performance of the quantile levels in ridge quantile regression. This comparison would help to better select the best quantile level. Through comparison we found that the quantile level at 0.75 is the best as it has a high R-square (0.8567) according to the interpretation of the data regarding the phenomenon under study.
|
6. Conclusions
- In this paper, the multicollinearity issues in quantile regression models were the subject under research, in an attempt to find practical solutions to deal with the violation issue of a regression model assumption. The solution adopted in our research is the ridge regression and for estimating the parameter of the ridge we use the Bayesian approach. We tested this approach for identifying the factors affecting anemia in children (Thalassemia) across various quantile ratios.The study showed that the use of the ridge quantile regression method in the cases when the independent variables are affected by multicollinearity is one of the successful ways to solve this issue. Therefore, applying the ridge quantile regression method in other studies is recommended, since it provides better estimators than the ordinary regression methods when the independent variables are related, without omitting any of the independent variables.By applying the ridge regression method at quantile level 0.75, we found that there were five variables with a significant impact on the anemia in children (Thalassemia) in Iraq at the statistically significant level less for 0.05%: real age, complete blood count, platelet count, size of spleen, the relatives between father and mother, where was the p-value as (0.0001, 0.0325, 0.03971, 0.0319, 0.0421) respectively. As for the rest of the variables (mean corpuscular volume, Blood type, white blood cell) the study shows that they are weak and have no significant statistical effect.The results are explained by the fact that Iraq is one of developing countries still facing health, environmental and economic difficulties.
ACKNOWLEDGEMENTS
- The author wishes to acknowledge the contribution of all the physicians that helped collecting and analysing the data for this study.