A. O. Bello1, F. A. Oguntolu1, O. M. Adetutu1, Nyor Ngutor1, J. P. Ojedokun2
1Departent of Mathematics and Statistics, Federal University of Technology, Minna, Nigeria
2Department of Statistics, University of Ibadan, Nigeria
Correspondence to: A. O. Bello, Departent of Mathematics and Statistics, Federal University of Technology, Minna, Nigeria.
| Email: |  |
Copyright © 2015 Scientific & Academic Publishing. All Rights Reserved.
Abstract
This research reports on the relationship and significance of social-economic factors (age, gender, employment status) and modes of HIV/AIDS transmission to the HIV/AIDS spread. Logistic regression model, a form of probabilistic function for binary response was used to relate social-economic factors (age, sex, employment status) to HIV/AIDS spread. The statistical predictive model was used to project the likelihood response of HIV/AIDS spread with a larger population using 10,000 Bootstrap re-sampled observations.
Keywords:
HIV, Category data, Large-Sample inference, Multiple Split Sample Procedure logistic regression and probability plots
Cite this paper: A. O. Bello, F. A. Oguntolu, O. M. Adetutu, Nyor Ngutor, J. P. Ojedokun, Application of Bootstrap Re-Sampling Method to a Categorical Data of HIV/AIDS Spread across Different Social-Economic Classes, International Journal of Statistics and Applications, Vol. 5 No. 4, 2015, pp. 157-168. doi: 10.5923/j.statistics.20150504.04.
1. Introduction
A virus has been draining the resources of the world for the past three decades and the virus is called HIV, which stands for Human Immunodeficiency Virus. The virus damages the immune system after a period of time, and this causes a variety of symptoms known as AIDS (Acquired immune deficiency syndrome). According to UNAIDS/HIV [13] “the pandemic of HIV and AIDS has continued to constitute serious health and socio economic challenges globally, for more than three decades. In the underdeveloped and developing countries which includes Nigeria, HIV/AIDS has reversed many of the health and developmental gains over the past three decades as reflected by indices such as life expectancy at birth and infant mortality rate among others”.The interest of this work is to model the relationship pattern that describes the way at which HIV infection varies across gender, economic status and age-groups. Also, to determine the notable factor(s) that play major role in transmitting the virus among people of different social and economic classes per given population, and out of the various possible mode of transmission (PMOT), age-group, gender and economic status; we want to determine if there is (are) any existence of individual or collective variability effect(s) of these variables to HIV infection or otherwise. We shall verify the stability of our predictive model in order to obtain a prototype models that will adequately describe the pattern of the spread and also predict the trends of HIV infection among person(s) of different socio-economic classes in Oyo state. This will help the state government and other relevant non-governmental bodies to know the age group(s) or socio-economic class that required urgent or long term plan interventions.
1.1. Epidemiology of HIV and AIDS
HIV infects cells in the immune system and the central nervous system. The main type of cell that HIV infects is the T helper lymphocyte; these cells play a crucial role in the immune system by coordinating the actions of other immune system cells. A large reduction in the number of T helper cells seriously weakens the immune system as HIV infects the T helper cell through the protein CD4 on its surface. HIV produces new copies of itself, which can then go on to infect many other cells. This process usually takes several years See [2] for details.HIV virus is a communicable infection, for this work we classified all possible mode of transmission (PMOT) of HIV under the following medically confirmed activities: Sexual intercourse/ heterosexual contact, Pregnancy (mother-child transmission), Sharp objects and Blood transfusion. Also, the social status is classified as Employed, and Unemployed.According to Open Dictionary[10] Employment is work that you are paid regularly to do for a person or company while Unemployed is define according to International Labour Organization[4] as the proportion of the economic active people who are without jobs.
2. Literature Review
The logistic regression model is one of the popular statistical models for the analysis of binary data with applications in physical, biomedical, behavioural sciences, and many others. Logistic regression analysis was implemented to determine the significant contributory factors influencing the subject of study [9]. The cases having the response variable as categorical, often called binary of (yes/no; present/absent; etc) and possible explanatory variables which can either be categorical variables, numerical variables or both are numerous in the biometry, psychometric, and epidemiology researches.In a longitudinal study of coronary heart disease as a function of age, gender, smoking history, cholesterol level, percentage of ideal body weight, and blood pressure, the response variable yi was defined to have the two possible outcomes: person developed heart disease during the study; person did not develop heart disease during the study were modelled using the logistic regression model (See [9] p555-556). L.M Raposo and et al [7] used the logistic regression model to predict resistance to HIV protease Inhibitor, the model obtained was said to be useful in decision making regarding the best therapy for HIV positive individuals. Also, Jinma Ren and et al [6] “Risk of Using logistic Regression to illustrate exposure-response relationship of infectious diseases”, the work was suspicious of the suitability of ordinary, categorical exposures, and logarithm transformation functions presented in logistic regression model to assess if the likelihood of infectious diseases is risk or as a result of exposure using simulated data, the work adjudged the logarithmic transformation function as better than the other two. However, the risk of using logistic regression is no risk at all if large sample size is used or procedure of large sample technique such as bootstrap re sampling method is used. This will reduce the bias in our estimates. “The odd function is the most suitable function for interpretation of binary predictive problems” [1].
2.1. Data Description and Limitation
The data used in this study can be classified as secondary data because they were not generated by the investigator. Secondary data is a data collected initially for a particular purpose and it may not always provide detailed information, which a researcher needs. The implication of this kind of problem is that the researcher will generally resort to certain assumptions so as to fill the missing information. This reduces the scope, quality and amount of information required for the research.Information on different variables of interests was collected from the records of Central Blood Transfusion Service Unit Oyo State, Nigeria. Information collected is sub topic into the followings data variables:Gender (Qualitative Variable): Male/ Female, Age (Quantitative Variable), Possible Mode of Transmission (PMOT), Employment Status (Emp): Employed / Unemployed. 400 observations of people that randomly visit the centre for HIV test for the purpose of medical diagnosis or for the purpose of blood donation were extracted out of the record that covers five years, 2009-2014. The dataset includes the Age of people that took the HIV test, so it is possible to calculate age in single years or age-groups. Presence of HIV (HIV+) and Absent of HIV (HIV-) is measured as a simple dichotomy coded one and zero respectively. The fact that we treat all predictors as discrete factors allows us to summarize the data in terms of the numbers of HIV+ and HIV- in each of the five different age-groups. The reference classes of explanatory variables (the male and the employed population) are coded 0, because they are traditionally believed to be less susceptible to HIV infection. We cross tabulate the variable PMOT (sexual intercourse, sharp object, mother-to-child and Blood transfusion) against age-group (0-15, 16-39, 40-54, 55-69, 70 and above in years), this will be treated as a qusi-experimental data.
3. Methodology
Considering the case where our response 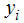 is a dichotomous response, when possible response is either yes or no, death or alive, present or absent and as the case at hand in this work is either HIV negative or HIV positive.
is a dichotomous response, when possible response is either yes or no, death or alive, present or absent and as the case at hand in this work is either HIV negative or HIV positive.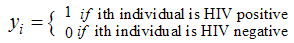 We coded the present or absent of subject of study as 1 and 0 respectively. The distribution of
We coded the present or absent of subject of study as 1 and 0 respectively. The distribution of 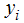 is binomial of a single trial or basically Bernoulli distribution as used by some text. The binary indicator variable outcome can only be 1 or 0 as the probability is bound between 0 and 1; this gives a sigmodial shape approaching 0 and 1 asymptotically. This is a nonlinear problem. The logistic function relating
is binomial of a single trial or basically Bernoulli distribution as used by some text. The binary indicator variable outcome can only be 1 or 0 as the probability is bound between 0 and 1; this gives a sigmodial shape approaching 0 and 1 asymptotically. This is a nonlinear problem. The logistic function relating 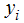 to predictors which can be qualitative, quantitative or both is a very flexible model which makes it vital to solving many epidemiology and social indicators related problems. The logistic line can also be of form;
to predictors which can be qualitative, quantitative or both is a very flexible model which makes it vital to solving many epidemiology and social indicators related problems. The logistic line can also be of form;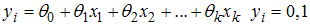 | (1) |
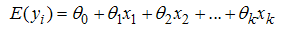 | (2) |
Probabilities; given 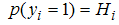 and
and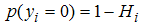 , Therefore,
, Therefore,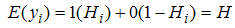 | (3) |
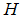 is the probability of our subject of interest in study taking place and
is the probability of our subject of interest in study taking place and 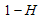 is the probability of subject of interest not occurring. The subject of interest informs our choice of coding 1 or 0.Equation (3) gives the probability
is the probability of subject of interest not occurring. The subject of interest informs our choice of coding 1 or 0.Equation (3) gives the probability 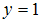 given that level of parameter variable is
given that level of parameter variable is 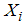 . Logistic regression model is a special case of general linear model. The special problems associated with model having binary response variable is the problem of having our error terms not normally distributed and heteroskadastic in nature due to the distribution of our response variable bonded between 0 and 1.
. Logistic regression model is a special case of general linear model. The special problems associated with model having binary response variable is the problem of having our error terms not normally distributed and heteroskadastic in nature due to the distribution of our response variable bonded between 0 and 1. 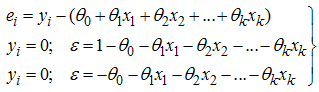 | (3.1) |
From equation (3.1) 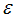 is not normally distributed. Other problem associated with the logistic model is the constraint condition on response function (See [9] for details).The function form in equation (3) has its left hand-side to take value ranging between 0 and 1, while the right hand-side is not in a form that can return values between 0 and 1 asymptotically. Therefore, we require a link function to properly link the left hand-side to the right hand-side. Link function such as identity function will not be appropriate for the nonlinear problem at hand. However, out of several possible link functions, we shall use the logit function, for easier understanding and interpretations of our results. The model is initially best put in the form;
is not normally distributed. Other problem associated with the logistic model is the constraint condition on response function (See [9] for details).The function form in equation (3) has its left hand-side to take value ranging between 0 and 1, while the right hand-side is not in a form that can return values between 0 and 1 asymptotically. Therefore, we require a link function to properly link the left hand-side to the right hand-side. Link function such as identity function will not be appropriate for the nonlinear problem at hand. However, out of several possible link functions, we shall use the logit function, for easier understanding and interpretations of our results. The model is initially best put in the form; 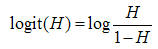 | (4) |
Also written as;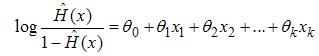 | (5) |
The interpretation of 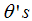 is not straightforward because the increase in unit of X varies for the logistic regression model according to the location of the starting point of the X scale [9]. The logit function is the natural logarithm (ln) of odds of
is not straightforward because the increase in unit of X varies for the logistic regression model according to the location of the starting point of the X scale [9]. The logit function is the natural logarithm (ln) of odds of 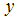 and taking exponential of the log of odd function gives us the most appreciable odd function that is vital in our interpretation of result. The odd function will simplify our interpretation problem.
and taking exponential of the log of odd function gives us the most appreciable odd function that is vital in our interpretation of result. The odd function will simplify our interpretation problem.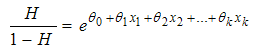 | (6) |
Explicitly; | (7) |
The inverse of the logit function is the logistic function.Hence; 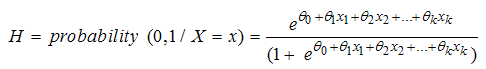 | (8) |
The logistic function form in equation (7) and (8) will return the right hand-side to be property value ranging from 0 and 1. The function increases monotonically if the gradient 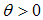 and decreases monotonically if
and decreases monotonically if 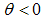 .Algebraically, the equation 7 or 8 can also be written in another form as shown in equation (9) below;
.Algebraically, the equation 7 or 8 can also be written in another form as shown in equation (9) below;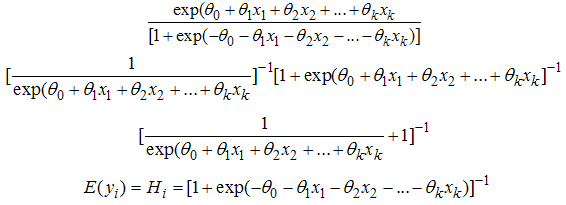 | (9) |
3.1. Method of Estimation
The variability of the error terms variances differs at different level of X, as shown in equation (3.1). This makes Ordinary Least square estimation ineffective in estimation of logistic function. The maximum likelihood is a better method for estimating logistic function since logistic function predicts probabilities, and not just classes, it can fit the probabilities for each class of our data-point, either for the class 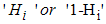 . We must also note that the error term is not usually considered in logistic problems.
. We must also note that the error term is not usually considered in logistic problems.
3.2. Maximum Likelihood Estimation
The maximum likelihood estimate is that value of the parameter that makes the observed data most likely [12]. The values of 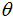 s that maximize
s that maximize 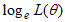 , that is, the value of
, that is, the value of 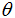 that assign the highest possible probability to the sample that was actually obtained. The method of likelihood in estimating a logistic function usually requires numerical procedures, and Fisher scoring or Newton-Raphson often work best. Most statistical packages have the logit numerical search procedure. In this work, R-programming language package for obtaining the maximum likelihood estimates of a logistic regression is used.Let
that assign the highest possible probability to the sample that was actually obtained. The method of likelihood in estimating a logistic function usually requires numerical procedures, and Fisher scoring or Newton-Raphson often work best. Most statistical packages have the logit numerical search procedure. In this work, R-programming language package for obtaining the maximum likelihood estimates of a logistic regression is used.Let 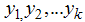 be n independent random variables (r.v.’s) with probability density functions
be n independent random variables (r.v.’s) with probability density functions 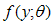 that depends on parameter
that depends on parameter 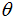 . The likelihood of the joint density function of k independent observations is
. The likelihood of the joint density function of k independent observations is 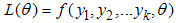 Then;
Then; 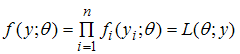 | (10) |
The root of the equation is obtained by equating the first derivative of equation (10) to zero and solved for each parameter. The maximum likelihood estimate (MLE) hold only when the second derivative is negative.The probability distribution function of our 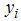 follows the Bernoulli distribution,
follows the Bernoulli distribution, 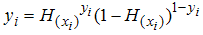 with
with 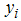 taking zero or one. The likelihood function is;
taking zero or one. The likelihood function is;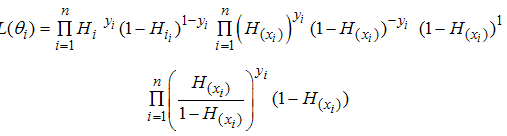 | (11) |
Recall equation (7), H is substituted into equation (11)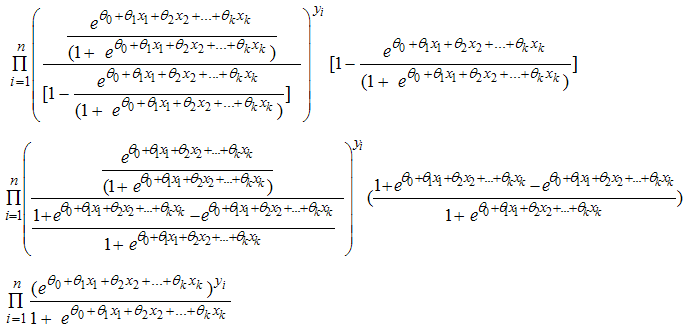 | (12) |
Taking the natural logarithm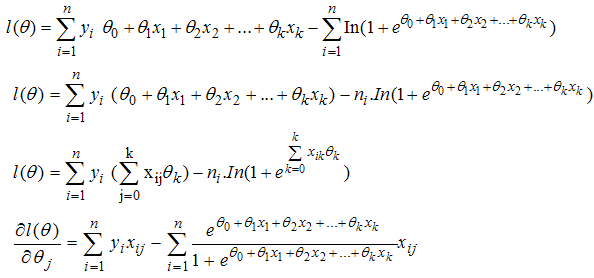 | (13) |
Recall equation (7) and substitute for 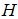 ; the probability of subject of interest under study occurring
; the probability of subject of interest under study occurring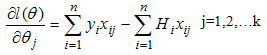 | (14) |
The differentiation of the log likelihood function in equation (13) with respect to each parameter 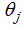 will not analytical give us the maximum likelihood estimates by setting each of the k equations in equation( 13) equal to zero. It is a system of k nonlinear equations. The solution to the K unknown variables is a nonlinear problem cannot be solved analytically but through numerical estimation using an iterative process. The Newton-Raphson method is popularly used for a logistic nonlinear function. However, problem of multicollinarity may arise which is visible when there are large estimated parameters and large standard error values. Also, convergence problem in numerical search procedure can be associated with multicollinearity problem which can be overcome by reducing the number of parameter variables for easy and quick convergence. For details see [8] and [9].
will not analytical give us the maximum likelihood estimates by setting each of the k equations in equation( 13) equal to zero. It is a system of k nonlinear equations. The solution to the K unknown variables is a nonlinear problem cannot be solved analytically but through numerical estimation using an iterative process. The Newton-Raphson method is popularly used for a logistic nonlinear function. However, problem of multicollinarity may arise which is visible when there are large estimated parameters and large standard error values. Also, convergence problem in numerical search procedure can be associated with multicollinearity problem which can be overcome by reducing the number of parameter variables for easy and quick convergence. For details see [8] and [9].
3.3. Variance Estimation of a Logistic Function Using the Bootstrap Method
The general linear model rely on asymptotic approximations in estimating the coefficient standard errors and this may not be reliable, just as measures such as R-square based, residual errors are not very informative and can be misleading. Therefore, using the method of bootstrap (a re-sampling technique) will either confirm or dispel our doubts about the sufficiency of our sample to estimate unbiased and robust estimates for the population parameters. For our models to adequately capture the reality of HIV/AIDS spread across different socio-economical classes in Oyo state population as likely as possible. We shall Generate 10,000 Bootstrap samples from the original sample to estimate our models’ parameter values and their confidence intervals. In addition to the bootstrap method we shall also consider the multiple split sample procedure. These will help us in selecting robust parameter values for our models. Bootstrapping technique has being identified to be effective in dealing with non-linear data with extremely non-normal distribution. See [3].
3.4. The Odd Function
J. M Bland and Douglas G [5] mentioned that there are mainly three reasons to use the odds ratio. “Firstly, they provide an estimate (with confidence interval) for the relationship between two binary variables. Secondly, they enable us to examine the effects of other variables on that relationship, using logistic regression. Thirdly, they have a special and very convenient interpretation.” The odds are nonnegative, with odds 1.0 when a success is more likely than a failure. According to Pedhazur [11] Odds are determined from probabilities and range between 0 and infinity. Odds are defined as the ratio of the probability of success and the probability of failure. The odds of success given as 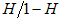 and the odds of failure would be odds (failure) given as
and the odds of failure would be odds (failure) given as 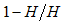 . The odds of success and the odds of failure are just reciprocals of one another. Probability and odds both measure how likely it is that our subject of interest will occur. Notably, the sign of the log-odds ratio indicates the direction of its relationship, the distinction regarding a positive or negative relationship in that of the odds ratios is given by which side of 1 the odd values fall on. Odd value 1 indicates no relationship, less than one indicates a negative relationship and greater than one indicates a positive relationship. However, in order to get an intuitive sense of how much things are changing, we need to get the exponential of the log-odds ratio, which gives us the odds ratio itself [1]. The odd ratio of the odd for x=1 to the odd of x=0 is
. The odds of success and the odds of failure are just reciprocals of one another. Probability and odds both measure how likely it is that our subject of interest will occur. Notably, the sign of the log-odds ratio indicates the direction of its relationship, the distinction regarding a positive or negative relationship in that of the odds ratios is given by which side of 1 the odd values fall on. Odd value 1 indicates no relationship, less than one indicates a negative relationship and greater than one indicates a positive relationship. However, in order to get an intuitive sense of how much things are changing, we need to get the exponential of the log-odds ratio, which gives us the odds ratio itself [1]. The odd ratio of the odd for x=1 to the odd of x=0 is 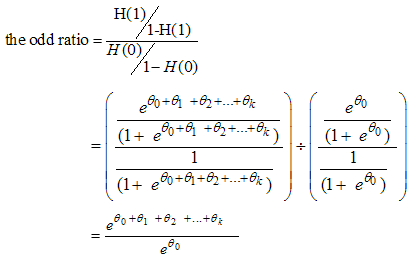 | (14.1) |
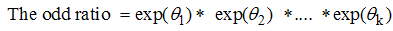 | (15) |
This result obtained is the relationship between the odds ratio and an independent dichotomous. The result tells that the odds on the event that y equals 1, increases (or decreases) by the factor 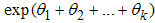 among those with x = 1 than among those x = 0. One major condition to note when interpreting for multiple logistic regression is that the estimated odds ratio for predictor variable x assumes that all other predictor variables are held constant.
among those with x = 1 than among those x = 0. One major condition to note when interpreting for multiple logistic regression is that the estimated odds ratio for predictor variable x assumes that all other predictor variables are held constant.
3.5. Results and Discussions
A lowess nonparametric response curve was fitted for the data (see Figure 1 and 2), the plots show a sigmoidal S-shaped response function, and the lowess fit S-shape supported our choice of fitting a logistic regression model to the data. | Figure 1 & Figure 2. Exploratory Data Analysis for Our Data |
3.6. The Large-Sample Inference Procedure Results
I. Bootstrap Re sampling TechniqueThe numerical search converges after four iterations with a very small standard error for each parameter shown in table 1. The residuals plotted against the predicted probability (See figure 3), shows the lowess smooth approximates a line having zero slope and intercept, and we can conclude that model inadequacy is not apparent. 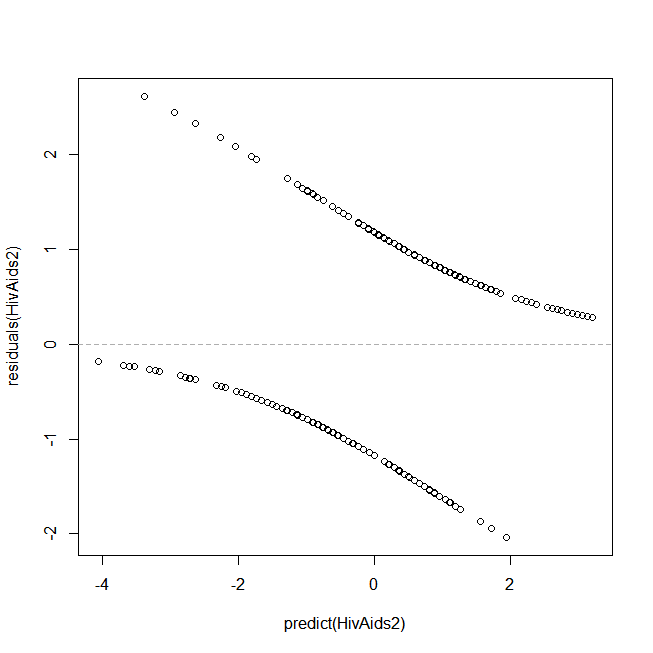 | Figure 3. Residual Plot |
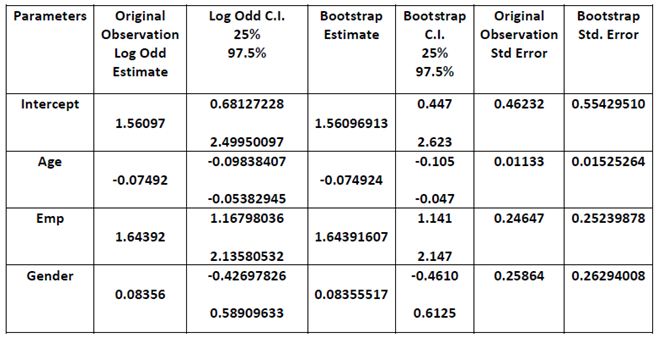
Table 1. Bootstrap Results and the Original Observation Results
 |
| |
|
The original sample confidence intervals constructed for the coefficient estimates and that of the bootstrap confidence intervals coincide at almost the same intervals; they agree quite well and these demonstrate the precision of the model coefficient estimates. The parameter estimates from the original observation and the 10,000 bootstrap samples were asymptotically the same, thus, we can conclude within approximately 95 percent confidence that our sample size is as sufficient as using any other larger sample size, all of our coefficient estimate are between 2.5% and 97.5% respectively. (See table 1). Statistically, our sample size is a good representation of the entire population and sufficient to inferring the population characteristics.Also, from table 1 above, the coefficient of factors Age and Emp shows great statistical significance at 0.05 level of significance with a very small standard error values of 0.01133 and 0.246 respectively. Gender is significant but not at 95% level of significant; however, because of the prior importance of this natural factor to HIV infections in area of sexual intercourse, and also its significance at interaction level with Employment status (Emp.), we shall retain the Age coefficient in our model. The odds ratio of HIV infection for the employed as our reference class in Emp. variable and that of the male as reference class in variable Gender is exp (1.56097). The male gender has almost five times lesser odd of contracting HIV compared to the female.Moreover, value 1.56097 is the log odds ratio of male with employment of a given age contracting HIV; the employed male population in Oyo State odd ratio can also be translated to their probabilities of contracting HIV, given by exp 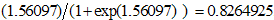 .The negative coefficient value of Age parameter suggests a negative relationship between age and HIV infection, which imply that the probability of contracting HIV decreases as Age of person(s) increases. The odds of contracting HIV given age cannot be given a direct interpretation based on the question ‘what unit of age is appropriate and applicable to show the change in odds ratio?’ The odds is best described by exp(c*Age), given c is a difference of units of ages under comparison. For the difference of unit between age 39 and 54years, the odds of contracting HIV between age 39 and 54years is exp
.The negative coefficient value of Age parameter suggests a negative relationship between age and HIV infection, which imply that the probability of contracting HIV decreases as Age of person(s) increases. The odds of contracting HIV given age cannot be given a direct interpretation based on the question ‘what unit of age is appropriate and applicable to show the change in odds ratio?’ The odds is best described by exp(c*Age), given c is a difference of units of ages under comparison. For the difference of unit between age 39 and 54years, the odds of contracting HIV between age 39 and 54years is exp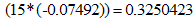 . For this we can now say the odd of contracting HIV decreases by 33% with each additional 15 years increase in age. The inverse relationship between age and Probability of HIV infection suggests that the younger generation below 55years should be of first priority in all the agenda towards eradicating HIV/AIDS spread. Also we could say that the result indicates a possibility that 33% of the infected persons in Oyo state never survived the AIDS beyond 15years. This might be as a result of inadequate medical supports, psychological stigma and discrimination that is still associated with HIV/AIDS infection in Africa, Oyo state inclusive. This call for the attention of all relevant organisations to increase their support for HIV/AIDS victims, intensify campaigns against stigmatization and discrimination of HIV/AIDS patient and also give supports such as free or subsidize antiretroviral drugs.Also, from the table 1 above, the odds of a unemployed person(s) in Oyo state contracting HIV are five times more likely than that of their employed counterpart and the generally probability of unemployed population of a given age contracting HIV is exp(1.56097+1.64392)/ (1+exp(1.56097+1.64392))=0.9610179. This result shows that the unemployed are more susceptible to HIV. The difference in the odds ratio of HIV infection between the female and the male individuals in the population is 1.087145(8.7%). This result implies that the odds the females in the population contracting HIV are 8. 9% than that of the males in the population, for given age and employment status. The positive coefficient of the gender and employment status (Emp.) variables imply that the female population in Oyo state are more likely to be HIV infected than the male counterpart and the unemployed population more likely that the employed respectively.Recall
. For this we can now say the odd of contracting HIV decreases by 33% with each additional 15 years increase in age. The inverse relationship between age and Probability of HIV infection suggests that the younger generation below 55years should be of first priority in all the agenda towards eradicating HIV/AIDS spread. Also we could say that the result indicates a possibility that 33% of the infected persons in Oyo state never survived the AIDS beyond 15years. This might be as a result of inadequate medical supports, psychological stigma and discrimination that is still associated with HIV/AIDS infection in Africa, Oyo state inclusive. This call for the attention of all relevant organisations to increase their support for HIV/AIDS victims, intensify campaigns against stigmatization and discrimination of HIV/AIDS patient and also give supports such as free or subsidize antiretroviral drugs.Also, from the table 1 above, the odds of a unemployed person(s) in Oyo state contracting HIV are five times more likely than that of their employed counterpart and the generally probability of unemployed population of a given age contracting HIV is exp(1.56097+1.64392)/ (1+exp(1.56097+1.64392))=0.9610179. This result shows that the unemployed are more susceptible to HIV. The difference in the odds ratio of HIV infection between the female and the male individuals in the population is 1.087145(8.7%). This result implies that the odds the females in the population contracting HIV are 8. 9% than that of the males in the population, for given age and employment status. The positive coefficient of the gender and employment status (Emp.) variables imply that the female population in Oyo state are more likely to be HIV infected than the male counterpart and the unemployed population more likely that the employed respectively.Recall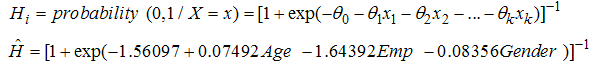 | (16) |
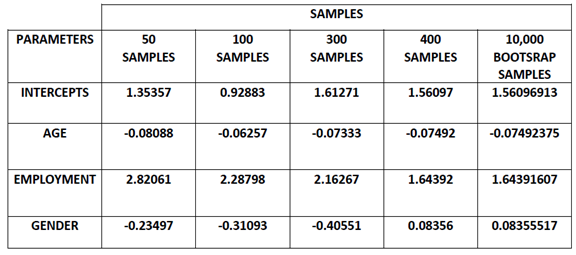
II. Multiple Split Sample Procedure Resultglm(formula = HIV ~ Age + Emp + Gender, family= binomial(link = "logit"), data = HivAids.dat2) Table 2. Multiple Sample Parameters Estimates
 |
| |
|
 | (17) |
The equation (16) is from the 400 samples. Equation (17) was fitted from different samples of 50, 100, 200 and 300 data points respectively, their probability plots across different age is shown by fig 3; As the sample sizes increase the closer the probabilities tends asymptotically to a sure prediction. This confirmed the central limit theorem showing that as our sample size increases the closer we get to the true value of the unknown population parameter’s estimates and the closer to the true probability. Therefore using the parameter estimates obtained from the larger 10,000 bootstrap samples is not a bad idea.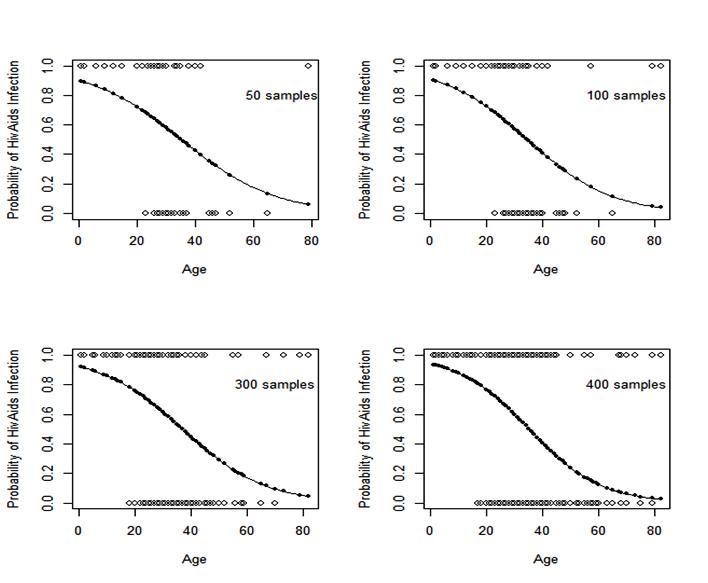 | Figure 4. Plots of Split Sample Models |
III. Model validation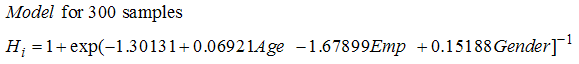 | (18) |
The model prediction from the equation (18) above was obtained from the first 300 observations. We now used equation (18) to predict Hi with i=301 to 400, within our observations, using predictor variables within our observation from data point 301 to 400. We compared the predicted result with the original observation of HIV from data point 301 to 400. The model gave correct prediction of 92 out of the 100 data points predicted. These imply that the fitted model is more than 91% stable with less than 8 percents variations compared with the original data. Our model has not done badly. We can now at this confidence predict the likelihood of HIV spread in Oyo State among different gender, economic classes across all possible age.a) The predictive model for Male-Employed individuals in; 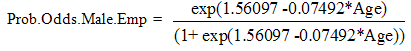 | (19) |
b)The predictive model for Male-Unemployed individuals;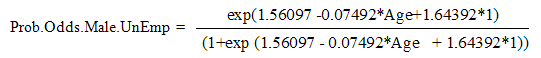 | (20) |
c)The predictive model for Female-Employed individuals;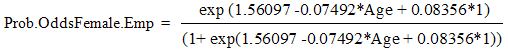 | (21) |
d)The predictive model for Male-Unemployed individuals;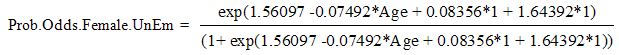 | (22) |
The predicted probability plot for equation (19), (20), (21) and (22) is as below;The probability plot predicts all most likely of HIV contraction for female-unemployed population aging below 39 years in Oyo state population as the fit is asymptotically approaching one. The model for the male-employed takes second position with the highest probability of HIV contraction across a randomly generated population ageing from 0 to 120 years using R sequential function (See Fig 5 for the plots).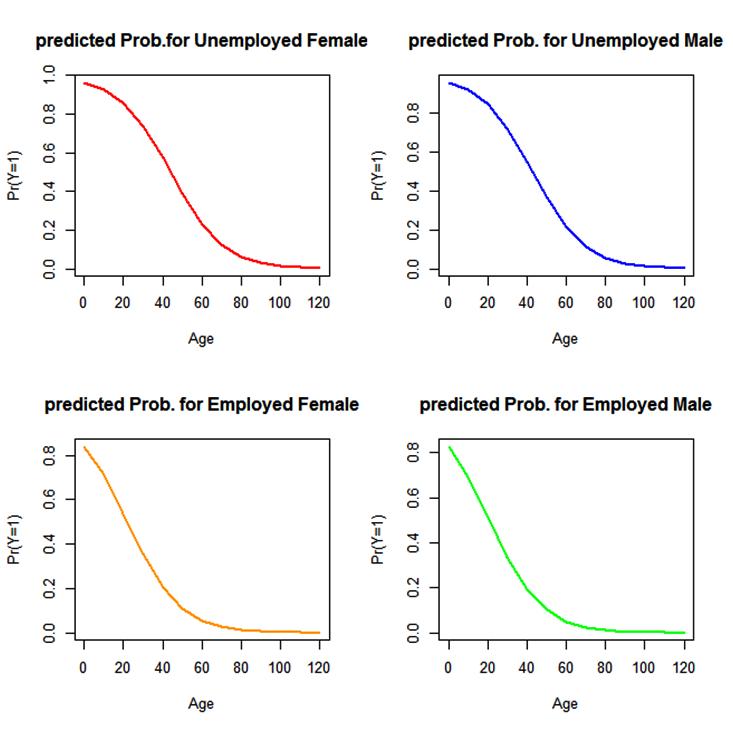 | Figure 5. |
For the predicted probabilities of HIV infection for females that are employed compared with females unemployed, the plot shows a increasing trend of infection with the unemployed population both in male and female gender in Oyo state, it is notably that the plot predicted the highest trend of most likelihood of infection with the unemployed females (see figure 6 and 7). 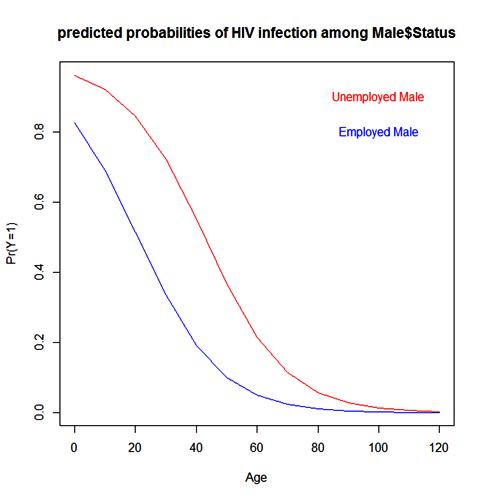 | Figure 6. |
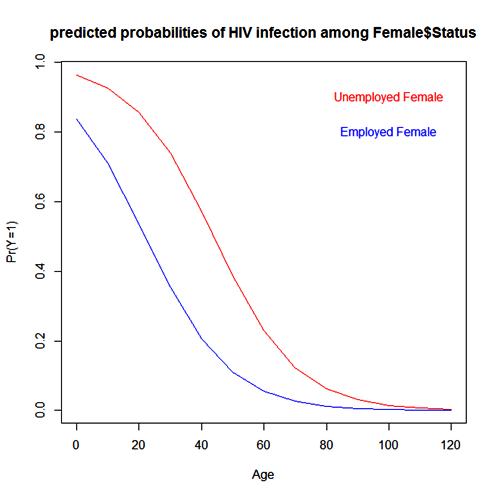 | Figure 7. |
4. Conclusions
The age group as block effect shows adequate significant level to HIV infection with F-value 6.496 and significant level 0.004(p<0.05). The age group 16-39 seems to be the age block that is most infected in the population, this age group is the reproductive age and the most sexually active stage of any population which suggests that any additional to the uncontrolled activities of sexual intercourse and pregnancy without proper medical supports will increase the cases of mother-to- chid infection in particular. An individual will not contract HIV because he/she belongs to a particular gender; contraction is majorly as result of activities or exposure. We recommend increment in employment level especially for the female gender in Oyo state as a vital control measure to mitigate the spread of HIV/AIDS coupled with increase in public awareness, abstinence, and a more comprehensive approach to preventing mother-to-child infection.
References
| [1] | Aaron (2005), Logistic Regressionhttp://pages.uoregon.edu/aarong/teaching/G4075_outlines/node16.html, 2005-12-21. |
| [2] | AIDS Centre@2002-2010;http://aids.md/aids/index.php?cmd=item&id=280&lang=ru |
| [3] | Bello, Oyedele Adeshina; Bamiduro, Timothy Adebayo; Chuwkwu, Unna Angela & Osowole, Oyedeji Isola (2015) “Bootstrap Nonlinear Regression Application in a Design of an Experiment Data for Fewer Sample Size” international journal of research (ijr) E-ISSN: 2348-6848, p- ISSN: 2348-795x volume 2, issue 2, feb. 2015 http://internationaljournalofresearch.org |
| [4] | ILO(www.ilo.org/wcmsp5/groups/public/---.../wcms_343153.pdf. |
| [5] | J. Martin Bland; Altman, Douglas G. British Medical Journal, International edition 320.7247 320.7247 (May 27, 2000): 1468. (May 27, 2000): 1468. |
| [6] | Jinma Ren, Zhen Ning, Carmen S. Kirkness, Carl V. Asche and Huaping Wang(2014) “Risk of Using logistic Regression to illustrate exposure-response relationship of infectious diseases”. BMC infectious diseases BioMed Centre Springer Science; http//www.biomedcentral.com/1471-2334/14/504# |
| [7] | L.M. Roposo, M.B. Arruda, R.M Brindeiro, F.F. Nobre; Logistic Regression Model for Predicting Resistance to HIV Protease Inhibitor Nelfinerir, XIII Mediterranean Conference on medical and Biological Engineering and Computing 2013,IFMBE proceedings volume 41, 2014,pp 1237-1240. Springer, http://link.spriger.com/chapter/10.1007%2F978-3-319-2_306# |
| [8] | Scott A. Czepiel, Maximum Likelihood Estimation of Logistic Regression Models: Theory and Implementation, http://czep.net/contact.html and. |
| [9] | Michael H. Kutner, Christopher J. Nachtsheim, William li; Applied Linear Statistical Models Fifth Edition, EmORY University of Minnesota John Neter University of Georgia University of Minnesota, pp 555-581. |
| [10] | Open Dictionary;synonyms/Macmillandictionary.com/dictionary/British/employment Publisher Limited (2005), www.macmillandictionary.com. |
| [11] | Pedhazur, E. (1997). Multiple Regression in behavioural research. New York, Harcourt Brace College Publishers: 714-765. |
| [12] | Richard Williams, Maximum Likelihood Estimation University of Notre Dame, http://www3.nd.edu/~rwilliam/ Last revised February 21, 2015. |
| [13] | UNAIDS, 2010. UNAIDS Report on the global AIDS epidemic 2010. www.unaids.org/documents/20101123_GlobalReport_em.pdf. |
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTML