-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Statistics and Applications
p-ISSN: 2168-5193 e-ISSN: 2168-5215
2013; 3(5): 141-154
doi:10.5923/j.statistics.20130305.01
Semi-Parametric Analysis of Children Nutritional Status in Ethiopia
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLKasahun Takele
Haramaya University, Department of Statistics, Ethiopia
Correspondence to: Kasahun Takele, Haramaya University, Department of Statistics, Ethiopia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Malnutrition among children under age five is the major public health problem in the developing world particularly in Ethiopia. The aim of this study was then to determine statistically the determinants of children malnutrition, using 2011 DHS data. The overall prevalence of underweight among children in Ethiopia was 36.4%. Bayesian Semi-parametric regression model was used to flexibly model the effects of selected socioeconomic, demographic, health and environmental covariates. Inference was made using Bayesian approach with Markov chain Monte Carlo (MCMC) techniques. It was found that the covariates sex of child, preceding birth interval, birth order of child, place of residence, mother’s education level, toilet facility, number of household members, household economic status, cough, diarrhea and fever were the most important determinants of children nutritional status in Ethiopia. The effect of child Age, mother’s age at child birth, and mother’s body mass index were also explored non-parametrically as determinants of children nutritional status. It is suggested that for reducing childhood malnutrition, due emphasis should be given in improving the knowledge and practice of parents on appropriate young child feeding practice and frequent growth monitoring together with appropriate and timely interventions.
Keywords: Undernutrition, Underweight, Semi-Parametric Regression Model, MCMC
Cite this paper: Kasahun Takele, Semi-Parametric Analysis of Children Nutritional Status in Ethiopia, International Journal of Statistics and Applications, Vol. 3 No. 5, 2013, pp. 141-154. doi: 10.5923/j.statistics.20130305.01.
Article Outline
1. Introduction
- The importance of nutrition on early-childhood development outcomes has gained international awareness. Strong evidence shows that nutritional failure during pregnancy and in the first two years of life lead to lower human capital endowments, negatively affecting physical strength and cognitive ability in adults. This contributes directly reduced earnings potential of individuals and damages national economic growth and competitiveness potential in a globalized world[1].Undernutrition of children is among the most serious health issues facing developing countries. Malnutrition is particularly prevalent in developing countries, where it affects one out of every three pre-school age children. It is an intrinsic indicator of well-being, but is also associated with morbidity, mortality, impaired childhood development, and reduced labor productivity[2]. Reducing malnutrition rates by half is one of the central development goals adopted by the international community at the Millennium Summit[3]. Malnutrition is an underlying factor in many diseases in both children and adults, and it contributes greatly to the disability - adjusted life years worldwide. Nutrition and health are important dimensions of human well-being. Undernutrition may be defined as insufficient intake of energy and nutrients to meet an individual’s needs to maintain good health. Additionally, it may indicate insufficient absorption of nutrients due to ill health. The term “malnutrition” is sometimes also used synonymously for Undernutrition. However, strictly speaking, malnutrition includes both Undernutrition as well as over-nutrition. Over nutrition simply refers to excess intake of macronutrients and micronutrients[4]. In the developing world, it is the Undernutrition which is of greater concern because it is alleged to be one of the leading causes of morbidity in children and contributes to more than half of child deaths[5]. Nutritional deprivation in early life can have long lasting effects on growth, educational attainment and productivity. Usually, the under-nutrition in children (under age five) is used as a measure for determining the extent of this particular public health problem in a population[6, 7].The development of Undernutrition typically follows a pattern that is closely related to the age of the child. While some children are already born undernourished due to growth retardation in utero, the anthropometric status of children worsens considerably only after 4-6 months, when children are weaned and solid foods are introduced 6,8]. Initially, the worsening anthropometric status shows up as acute under-nutrition. But then stunting develops and worsens until about age 2-3. At that time, the body has, through reduced growth, adjusted to reduced nutritional intake and now needs fewer nutrients to maintain this smaller[6,9]. Nutritional status during childhood has consequences in childhood until adulthood. Deficiencies in nutrients or imbalances between them can have dire long-term effects for the individual[10]. Thus, measuring the child’s nutritional status is important because of both the long-term and short-term effects on the health, educational and the cognitive abilities of the child. There are also severe consequences and effects to the child’s ability to function as a healthy, productive and self-supporting community member in the long-term, which is another reason for concern, and as such the study further wishes to add to an understanding on how to contribute to the betterment of society.Measures of child malnutrition are based on height-for-age, weight-for-age, and weight-for-height. Each of these indices provides somewhat different information about the nutritional status of child. The height-for-age index measures linear growth retardation among children, primarily reflecting chronic malnutrition. The weight – for - height index measures body mass in relation to body height, primarily reflecting acute malnutrition. Weight-for-age reflects both chronic and acute malnutrition[6, 4]. According to the 2009, special report of the Crop and Food Security Assessment Mission to Ethiopia[11], 7.5 million persons are still chronically food insecure and are under the productive safety net programme (PSNP); an additional 4.9 million people are facing acute food insecurity as of January to June 2009. Malnutrition in Ethiopia is the underlying cause of 57% of child deaths and thus failing to address this problem will also hold back progress towards reaching MDG 4 to reduce child mortality[12].Woldemariam and Timotiows (2002) performed a comparative study for urban, rural and combined urban and rural children. They identified region of residence, education of mother, economic status of the household and age of the child as determinants of malnutrition and health problems among urban children. For rural children, the analyses showed that region of residence, education of mother, education of partner, age, birth order and preceding birth interval of a child as important predictors of nutrition status. The combined urban and rural (national) sample results indicated that region of residence, education of mother, education of father, economic status of the household, age, birth order and birth interval of the child were important determinants of child nutrition and health status.[13]Nutritional status of children in Ethiopia is among the worst in the world. For example, chronic malnutrition in Ethiopia is worst than other SSA countries: about one in two children (51 percent) are moderately to severely stunted, of which slightly more than one in four children (26 percent) are severely stunted . Thus, high malnutrition rates in Ethiopia pose a significant obstacle to achieve better child health outcomes[12]. The implication of this high prevalence of child malnutrition is that a good knowledge regarding the major factors that contribute to the problem is essential in order to avoid its adverse consequences. The causes and determinants of child malnutrition are complex, interrelated, and multidimensional. In the literature, since mothers are the main providers of primary care to their children, understanding the contribution of maternal characteristics on child nutrition has been identified as a key towards addressing the problem of child malnutrition. In Ethiopia reason behind malnutrition is still to be known from recent data available.Weight-for-age was chosen as the index of child nutritional status for this analysis because it is the most widely used in developing countries, allowing for the inclusion of the largest number of studies. Although it does not distinguish between wasting and stunting, low weight-for-age (underweight) represents a combination of both aspects and has a high positive predictive value as an indicator for child malnutrition in developing countries[6].While there are numerous studies on childhood malnutrition in Ethiopia and other countries, majority of these studies have looked at the contributions of individual ‐ level (socioeconomic and family planning) characteristics. A growing body of literature considers the importance of understanding of determinants of childhood malnutrition through an integrated analysis that considers linkages between demographic, household, and community structures. Thus, the contextual aspect of child malnutrition needs to be explored to understand the process of malnourishment as a whole. The study was to model the various possible factors and their contribution for the current high prevalence of malnutrition problems using the Bayesian semi-parametric regression model. To expand our understanding of the most common and consistent factors on the risk of childhood malnutrition, it is necessary to consider expected determinants for malnutrition using Bayesian approach. Therefore, the purpose of this paper has been to develop and test a model for childhood nutritional status.
2. Data and Methodology
2.1. Data
- This research used the 2011 Ethiopian Demographic and Health Survey. The survey drew a representative sample of women of reproductive age, by administering a questionnaire and making an anthropometric assessment of women and their children that were born within the previous five years.For the 2011 EDHS, a representative sample of approximately 17,817 households from 624 clusters was selected. In the first stage, 624 clusters, 187 urban and 437 rural were selected from the list of enumeration areas based on sampling frame. In the second stage, a complete listing of households was carried out in each selected cluster. The analysis presented in this study on nutritional status was based on the 8200 children aged less than 60 months with complete anthropometric measurements.In this study, height and weight measurements of the children, taking age and sex into consideration, were converted into Z‐scores based on new growth standards published by the World Health Organization (WHO) in 2006. Thus, those below (-2) standard deviations of the WHO median reference for height‐for‐age, weight‐for‐age and weight‐for‐height were defined as stunted, underweight, and wasted, respectively. In this study, underweight was considered as an indicator of both linear growth retardation and acute malnutrition. Children with weight‐for‐age z‐scores below two standard deviations from the median of the reference population were considered as underweight. Furthermore, children with z‐scores below (-3) standard deviations from the median of the reference population were considered to be severely underweight, while children with z‐scores between three and two standard deviations were considered to be moderately underweight; these all three indicators are used to describe the level of child malnutrition and the relationship between maternal and child nutritional status. Moreover, underweight measures linear growth retardation, cumulative growth deficit and acute malnutrition and indicates the effect of chronic and acute nutritional status in the life of the child. Therefore, an in‐depth analysis was performed on underweight by focusing on factors affecting chronic and acute malnutrition. Undernutrition among children is usually determined by assessing the anthropometric status of a child relative to a reference standard. In this study, under-nutrition was considered as measured by underweight or insufficient weight‐for‐age, indicating chronic and acute under-nutrition. Weight‐for‐age score for a child i is determined using a Z‐score which is defined as
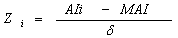 where AI refers to the child`s anthropometric indicator (weight at a certain age in our case), MAI refers to the median of the reference population and σ refers to the standard deviation of the reference population. Weight‐for‐age z‐score is an indicator of the nutritional status of a child. Here the main interest is in modelling the dependence of nutritional status on covariates including the age of the child, the body mass index of the child`s mother, the district the child lives in, mother education, mother working status, sex of child, birth order and birth interval, household economic status, and health and environmental conditions.
where AI refers to the child`s anthropometric indicator (weight at a certain age in our case), MAI refers to the median of the reference population and σ refers to the standard deviation of the reference population. Weight‐for‐age z‐score is an indicator of the nutritional status of a child. Here the main interest is in modelling the dependence of nutritional status on covariates including the age of the child, the body mass index of the child`s mother, the district the child lives in, mother education, mother working status, sex of child, birth order and birth interval, household economic status, and health and environmental conditions.2.2. Variables in the Study
- As verified in the literature review, socio-economic, demographic, health and environmental characteristics are considered as the most important determinants of child nutritional status.
2.2.1. Response Variable
- In our application on children nutritional status, underweight is used which is the response variable. Z-score (in a standardized form) was used as a continuous variable to maximize the amount of information available in the data set.
2.2.2. Explanatory Variables
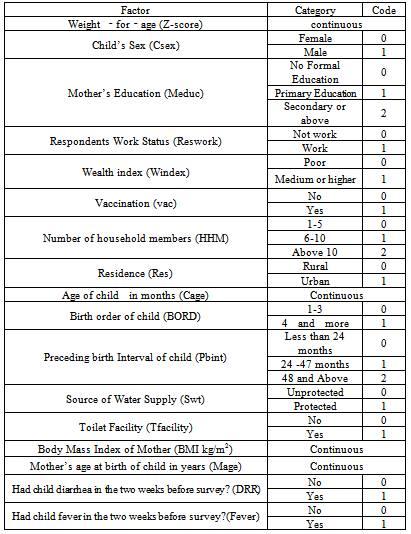
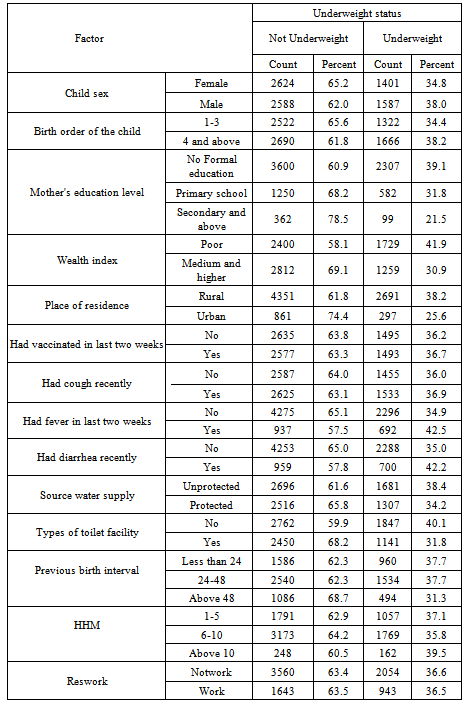
- The explanatory variables which might determine nutritional status of child were socio-economic, demographic, health and environmental factors. These factors include the sex of child, age of child, preceding birth interval, birth order of child, mother’s age at child birth, place of residence, mother’s education level, mother’s work status, number of household members, household economic status, mothers body mass index, diarrhea, fever, vaccination, cough, water supply and toilet facility (Table 1).
|
2.3. Methods of Statistical Analysis
- Bayesian methods have become popular in modern statistical analysis and are being applied to a broad spectrum of scientific fields and research areas. Bayesian data analysis involves inferences from data using probability models for quantities we observe and for quantities about which we wish to learn or in other words analyzing statistical models with the incorporation of prior knowledge about the model or model parameters.There has been much recent interest in Bayesian inference for generalized additive and related models. The increasing popularity of Bayesian methods for these and other model classes is mainly caused by the introduction of Markov chain Monte Carlo (MCMC) simulation techniques which allow realistic modeling of complex problems.Thus, the Bayesian approach offers the viable and rigorous solution, though there is also the added benefit of providing much‐needed uncertainty and probability assessments in nonlinear and non‐Gaussian situations in a valid and rigorous way.The statistical analysis in this research is based on Bayesian approaches which allow a flexible framework for realistically complex models. These approaches allow us to analyze usual linear effects of categorical covariates and nonlinear effects of continuous covariates within a unified semi‐parametric Bayesian framework for modeling and inference. In this work, firstly, we analyze the effects of the different types of covariates on the response variable “nutritional status” by using weight‐for‐age z‐score as continuous response variable with the assumption that each of the covariates has a linear effect on the response variable. In this case, a Bayesian Additive regression model was employed. In the first case, it assumes each covariate has a linear effect; the approach we follow in this step is Bayesian linear regression parametric approach. Secondly, since some studies suggest that body mass index and age of child as having nonlinear effect, which modify the first case, the Bayesian additive Gaussian regression parametric approach, to accommodate some transformation of these two covariates. Thirdly, to analyze the nutritional status of children we employ the same Bayesian approach, but in this case, since the three continuous covariates BMI (body mass index of the mother), Cage (age of the child), and Mage (Mother age at birth) are assumed to have a possibly nonlinear effect on the z‐score and, therefore these are modeled non-parametrically (as cubic P‐splines with second order random walk prior). Finally, it has been done by employing the Deviance Information Criteria to compare the three models. In this study, the study proposed generalized additive models can simultaneously incorporate the usual linear effects as well as nonlinear effects of continuous covariates within a semi-parametric Bayesian approach. The inference we make is fully Bayesian and uses recent Markov Chain Monte Carlo (MCMC) simulation techniques for drawing random samples from the posterior.
2.3.1. Bayesian Structured Additive Regression Models
2.3.1.1. Generalized Additive Regression Models
- Generalized Additive Models are methods and techniques developed and popularized ([14]. The study examines the generalized additive model as an alternative to the common linear model in the context of analyzing childhood nutritional status in Ethiopia. Most applications are still based on generalized linear models, assuming that covariate effects can be modeled by a parametric linear predictor. In this study, however, the data contain detailed information on continuous covariates like body mass index of the mother, mother age at child birth and child age. Their effects are often highly nonlinear, and are difficult to assess with conventional parametric models.The generalized additive model generalizes the linear model by modeling the expected value of Y as
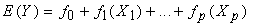 | (1) |
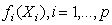 are smooth functions. These functions are not given a parametric form but instead are estimated by nonparametric methods.While Gaussian models can be used in many statistical applications, there are types of problems for which they are not appropriate. For example, the normal distribution may not be adequate for modeling discrete responses such as counts, or bounded responses such as proportions. Thus, generalized additive models can be applied to a much wider range of data analysis problems. Generalized additive models consist of a random component, an additive component, and a link function relating these two components. Generalized additive models[14] assume that, the response Y, the random component, has density in the exponential family. That is, conditional on covariates xi, the responses yi are independent and the distribution of yi belongs to a simple exponential family, which is expressed as:
are smooth functions. These functions are not given a parametric form but instead are estimated by nonparametric methods.While Gaussian models can be used in many statistical applications, there are types of problems for which they are not appropriate. For example, the normal distribution may not be adequate for modeling discrete responses such as counts, or bounded responses such as proportions. Thus, generalized additive models can be applied to a much wider range of data analysis problems. Generalized additive models consist of a random component, an additive component, and a link function relating these two components. Generalized additive models[14] assume that, the response Y, the random component, has density in the exponential family. That is, conditional on covariates xi, the responses yi are independent and the distribution of yi belongs to a simple exponential family, which is expressed as: 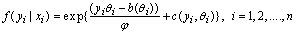 | (2) |
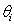 is the natural parameter of the exponential family,
is the natural parameter of the exponential family, 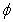 is a scale or dispersion parameter common to all observations, and b (.) and c (.) are functions depending on the specific exponential family.Moreover, the conditional expectation
is a scale or dispersion parameter common to all observations, and b (.) and c (.) are functions depending on the specific exponential family.Moreover, the conditional expectation 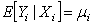 and with link function g (.) we have
and with link function g (.) we have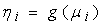 | (3) |
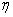 in the Generalized Additive models can be expressed as
in the Generalized Additive models can be expressed as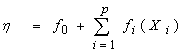 | (4) |
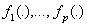 are smooth functions that define the additive component. Finally, the relationship between the mean μ of the response variable and
are smooth functions that define the additive component. Finally, the relationship between the mean μ of the response variable and 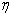 is defined by a link function.A generalized additive regression model is a special case of the generalized linear models, but they serve different analytic purposes. Generalized linear models emphasize estimation and inference for the parameters of the model, while generalized additive models focus on exploring data non-parametrically.
is defined by a link function.A generalized additive regression model is a special case of the generalized linear models, but they serve different analytic purposes. Generalized linear models emphasize estimation and inference for the parameters of the model, while generalized additive models focus on exploring data non-parametrically. 2.3.2. Bayesian Semi-Parametric Regression Models
- The assumption of a parametric linear predictor for assessing the influence of covariate effects on responses seems to be rigid and restrictive in practical application situation and also in many real statistically complex situation since their forms cannot be predetermined a priori. In this application to childhood under-nutrition and in many other regression situations, we are facing the problem for the continuous covariates in the data set; the assumption of a strictly linear effect on the response Y may not be appropriate as suggested in[15, 16, 17].Traditionally, the effect of the covariates on the response is modelled by a linear predictor as:
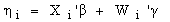 | (5) |
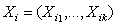 is a vector of continuous covariates,
is a vector of continuous covariates,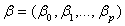 is a vector of regression coefficients for the continuous covariates.
is a vector of regression coefficients for the continuous covariates. 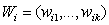 is a vector of categorical covariates.
is a vector of categorical covariates. 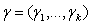 is a vector of regression coefficients for the categorical covariates. In the Bayesian parametric regression model, the parameter vectors β and γ one routinely assume diffuse priors
is a vector of regression coefficients for the categorical covariates. In the Bayesian parametric regression model, the parameter vectors β and γ one routinely assume diffuse priors 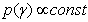 and
and 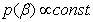 A possible alternative would be to work with a multivariate Gaussian distribution γ~ N (γ0, Σγ0) and β ~ N (β0, Σ β0). However, since in most cases a non‐informative prior is desired, it is sufficient to work with diffuse priors. In this study, the continuous covariates child’s age (Cage), the mother’s age at birth (Mage), and the mother’s Body Mass Index (BMI kg/m2) are assumed to have non-linear effects on child nutritional status. Hence, it is necessary to seek for a more flexible approach for estimating the continuous covariates by relaxing the parametric linear assumptions, by considering their true functional forms. This can be done using an approach referred to as non-parametric regression model. Non-parametric regression analysis is regression without an assumption of linearity. The scope of non-parametric regression is very broad, ranging from "smoothing" the relationship between two variables in a scatter plot to multiple-regression analysis and generalized regression models (for example, logistic non-parametric regression for a binary response variable). To specify a non-parametric regression model, an appropriate function that contains the unknown regression function needs to be chosen. This choice is usually motivated by smoothness properties, which the regression function can be assumed to possess. The semi-parametric regression model is obtained by extending model (5) as follows:
A possible alternative would be to work with a multivariate Gaussian distribution γ~ N (γ0, Σγ0) and β ~ N (β0, Σ β0). However, since in most cases a non‐informative prior is desired, it is sufficient to work with diffuse priors. In this study, the continuous covariates child’s age (Cage), the mother’s age at birth (Mage), and the mother’s Body Mass Index (BMI kg/m2) are assumed to have non-linear effects on child nutritional status. Hence, it is necessary to seek for a more flexible approach for estimating the continuous covariates by relaxing the parametric linear assumptions, by considering their true functional forms. This can be done using an approach referred to as non-parametric regression model. Non-parametric regression analysis is regression without an assumption of linearity. The scope of non-parametric regression is very broad, ranging from "smoothing" the relationship between two variables in a scatter plot to multiple-regression analysis and generalized regression models (for example, logistic non-parametric regression for a binary response variable). To specify a non-parametric regression model, an appropriate function that contains the unknown regression function needs to be chosen. This choice is usually motivated by smoothness properties, which the regression function can be assumed to possess. The semi-parametric regression model is obtained by extending model (5) as follows: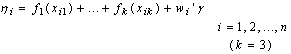 | (6) |
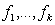 are smooth functions of the continuous covariates.
are smooth functions of the continuous covariates.2.3.3. Prior Distributions
- Existing evidence about the parameters of interest may be available from earlier studies or from experts’ opinions and can be formalized into what is called prior distribution of the parameter of interest. A prior distribution can be non-informative, informative, or very informative. Non informative prior distributions are used in cases in which no extra-sample information is available on the value of the parameters of interest[18, 19]. In statistical terms, this lack of knowledge is represented with a distribution that attributes, approximately, the same probability to each possible parameter value.In model (6), the parameters of interest
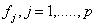 and parameters
and parameters 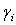 as well as the variance parameter (τ2) are considered as random variables and have to be supplemented with appropriate prior assumptions. In the absence of any prior knowledge we assume independent diffuse priors
as well as the variance parameter (τ2) are considered as random variables and have to be supplemented with appropriate prior assumptions. In the absence of any prior knowledge we assume independent diffuse priors 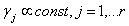 for the parameters of fixed effects. Another common choice is highly dispersed Gaussian priors. Several alternatives are available as smoothness priors for the unknown functions
for the parameters of fixed effects. Another common choice is highly dispersed Gaussian priors. Several alternatives are available as smoothness priors for the unknown functions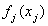 . Among the others, random walk priors[20], Bayesian Penalized-Splines[21], Bayesian smoothing splines (Hastie and Tibshirani, 2000)[22] are the most commonly used. In this study, the Bayesian smoothing spline was used by taking cubic P‐spline with second order random walk priors[23, 16].Suppose that
. Among the others, random walk priors[20], Bayesian Penalized-Splines[21], Bayesian smoothing splines (Hastie and Tibshirani, 2000)[22] are the most commonly used. In this study, the Bayesian smoothing spline was used by taking cubic P‐spline with second order random walk priors[23, 16].Suppose that 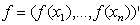 is the vector of corresponding function evaluations at observed values of X. Then, the prior for f is
is the vector of corresponding function evaluations at observed values of X. Then, the prior for f is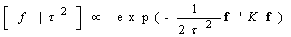 | (8) |
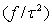 follows a partially improper Gaussian prior
follows a partially improper Gaussian prior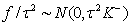 where
where 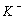 is a generalized inverse of a band‐diagonal precision or penalty matrix K. it is possible to express the vector of function evaluations
is a generalized inverse of a band‐diagonal precision or penalty matrix K. it is possible to express the vector of function evaluations 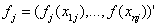 of a nonlinear effect as the matrix product of a design matrix Xj and a vector of regression coefficients βj,
of a nonlinear effect as the matrix product of a design matrix Xj and a vector of regression coefficients βj, 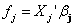 Brezger and Lang (2006)[24] also suggest a general structure of the priors for βj as:
Brezger and Lang (2006)[24] also suggest a general structure of the priors for βj as: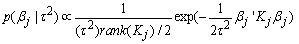 | (9) |
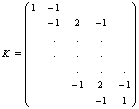 For full Bayesian inference, the unknown variance parameters τ2 are also considered as random and estimated simultaneously with the unknown regression parameters. Therefore, hyperpriors are assigned to the variances τ2 in a further stage of the hierarchy by highly dispersed (but proper) inverse Gamma priors
For full Bayesian inference, the unknown variance parameters τ2 are also considered as random and estimated simultaneously with the unknown regression parameters. Therefore, hyperpriors are assigned to the variances τ2 in a further stage of the hierarchy by highly dispersed (but proper) inverse Gamma priors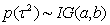 .
.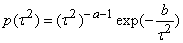 | (10) |
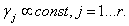 Another choice would be to work with a multivariate Gaussian distribution
Another choice would be to work with a multivariate Gaussian distribution 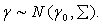 In this study, diffuse priors was used for the fixed effects parameter γ. Bayesian P-splineAny smoother depends heavily on the choice of smoothing parameters for p-spline in a mixed (fixed and continuous) framework. A closely related approach for continuous covariates is based on the P‐splines approach introduced by[25].This approach assumes that an unknown smooth function fj of a covariate Xj can be approximated by a polynomial spline of degree l defined on a set of equally spaced knots
In this study, diffuse priors was used for the fixed effects parameter γ. Bayesian P-splineAny smoother depends heavily on the choice of smoothing parameters for p-spline in a mixed (fixed and continuous) framework. A closely related approach for continuous covariates is based on the P‐splines approach introduced by[25].This approach assumes that an unknown smooth function fj of a covariate Xj can be approximated by a polynomial spline of degree l defined on a set of equally spaced knots 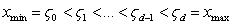 within the domain of Xj. The domain from xmin to xmax can be divided into n’ equal intervals by d’+1 knots, Each interval will be covered by l+1 P-splines of degree l, The total number of knots for construction of the P-spline will be d’+2l+1. The number of P-splines in the regression is d’+1. It is well known that such a spline can be written in terms of a linear combination of Mj = d + l P-spline basis functions Bm, i.e.,
within the domain of Xj. The domain from xmin to xmax can be divided into n’ equal intervals by d’+1 knots, Each interval will be covered by l+1 P-splines of degree l, The total number of knots for construction of the P-spline will be d’+2l+1. The number of P-splines in the regression is d’+1. It is well known that such a spline can be written in terms of a linear combination of Mj = d + l P-spline basis functions Bm, i.e.,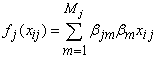 | (11) |
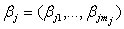 corresponds to the vector of unknown regression coefficients. The n*mj design matrix
corresponds to the vector of unknown regression coefficients. The n*mj design matrix 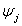 consists of the basic functions evaluated at the observations
consists of the basic functions evaluated at the observations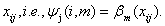 The crucial choice is the number of knots: for a small number of knots, the resulting spline may not be flexible enough to capture the variability of the data; for a large number of knots, estimated curves tend to over fit the data and, as a result, too rough functions are obtained. As a remedy,[25] suggest a moderately large number of equally spaced knots (usually between 20 and 40) to ensure enough flexibility, and to define a roughness penalty based on first or second order differences of adjacent P-Spline coefficients to guarantee sufficient smoothness of the fitted curves. In our analysis, we will typically choose P‐splines of degree 3 and 20 intervals, and second order random walk priors on the P‐splines regression coefficients. Hence, it is used to flexibly capture the variability of the data.First and second order random walk priorsLet us consider the case of a continuous covariate X with equally spaced observations
The crucial choice is the number of knots: for a small number of knots, the resulting spline may not be flexible enough to capture the variability of the data; for a large number of knots, estimated curves tend to over fit the data and, as a result, too rough functions are obtained. As a remedy,[25] suggest a moderately large number of equally spaced knots (usually between 20 and 40) to ensure enough flexibility, and to define a roughness penalty based on first or second order differences of adjacent P-Spline coefficients to guarantee sufficient smoothness of the fitted curves. In our analysis, we will typically choose P‐splines of degree 3 and 20 intervals, and second order random walk priors on the P‐splines regression coefficients. Hence, it is used to flexibly capture the variability of the data.First and second order random walk priorsLet us consider the case of a continuous covariate X with equally spaced observations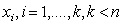 . Suppose that
. Suppose that 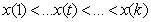 defines the ordered sequence of distinct covariate values. Here n denotes the number of different observations for x in the data set. A common approach in dynamic or state space models is to estimate one parameter
defines the ordered sequence of distinct covariate values. Here n denotes the number of different observations for x in the data set. A common approach in dynamic or state space models is to estimate one parameter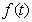 for each distinct
for each distinct 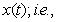 Define
Define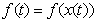 and let
and let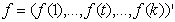 denote the vector of function evaluations. Then a first order random walk prior for f is defined by:
denote the vector of function evaluations. Then a first order random walk prior for f is defined by: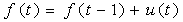 | (12) |
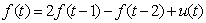 | (13) |
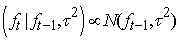 | (14) |
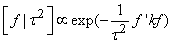 | (15) |
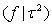 follows a partially improper Gaussian prior
follows a partially improper Gaussian prior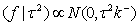 Where,
Where, 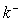 is a generalized inverse of the penalty matrix K.For the case of non-equally spaced observations random walk priors must be modified to account for non-equal distances
is a generalized inverse of the penalty matrix K.For the case of non-equally spaced observations random walk priors must be modified to account for non-equal distances 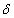 t = x (t)-x (t-1) between observations. Random walks of first order are now specified by f(t) = f(t - 1) + u(t); u(t)~ N(0;
t = x (t)-x (t-1) between observations. Random walks of first order are now specified by f(t) = f(t - 1) + u(t); u(t)~ N(0; 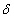 t τ 2); i. e. by adjusting error variances from τ 2to
t τ 2); i. e. by adjusting error variances from τ 2to 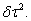 Random walks of second order are defined by
Random walks of second order are defined by 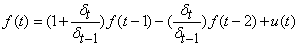 | (16) |
2.3.4. Posterior Probability Distribution
- Bayesian inference is based on the entire posterior distribution derived by multiplying the prior distribution
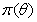 of all parameters and the full likelihood function
of all parameters and the full likelihood function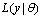 . For this case, let
. For this case, let 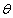 be the vector of all unknown parameters, then the posterior distribution is given by:
be the vector of all unknown parameters, then the posterior distribution is given by: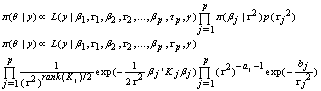 | (17) |
3. Results and Discusions
3.1. Descriptive Analysis
- The main purpose of this study was to determine statistically the correlates of child malnutrition in Ethiopia. The data were obtained from 2011 DHS[28]. In this study a total of 8200 children under age five were considered for the analysis. Among these, 2988 (36.4%) were found to be underweight, with weight-for-age Z-score less than -2.0. This shows that underweight prevalence is high in the country. The result displayed on Table 2 shows the percentages and counts of underweight status of children with respect to the categorical explanatory variables. As one can see from Table 2, among the 8200 cases examined in this study 38.0 % of male children were underweight and 34.8 % of female children were underweight.In this study, birth order is recorded into two categories: first to third birth and above. As one can see from the descriptive output in most of the household the number of children ever born is greater than three. In addition to this one can easily see from Table 2 as the birth order number increase it seems that children’s nutritional status decrease.As can be seen from Table 2, the highest prevalence of child malnutrition was observed among children whose preceding birth interval was less than 24 months (37.7%) unlike to the lowest prevalence of child malnutrition which was recorded from children whose preceding birth interval is 48 and above (31.3 %). The proportion of underweight children, as can be seen in Table 2, differs by type of place of residence: urban and rural. Accordingly, higher numbers of underweight children (38.2%)) reside in rural areas, and relatively small numbers of underweight children (25.6%) reside in urban centers. In this study, mother’s educational level is recorded into three categories: no formal education, primary education and secondary education and above. From Table 2, nutritional status of a child varies by educational level of mother. The highest prevalence of malnutrition was observed from children whose mothers had no formal education (39.1%) as opposed to the lowest prevalence of child malnutrition which was recorded from children whose mothers have secondary and above educational level (21.5%). It seems that a mother with higher educational level had a child with better nutritional status.Table 2 also shows that the nutritional status of children varies by the households’ economic status. The highest probability of underweight was observed among children from poor households (41.9 %) and the lowest was noticed for children cared by non-poor household.Households with more than 10 or more children had the highest percentage of underweight children (39.5 %) unlike to households with less than five children (37.1%).The evidence given in Table 2 shows that the percentage nutritional statuses of children who had diarrhea recently seem to be high probability of underweight than those children which had no diarrhea recently. Likewise, one can observe that the percentages nutritional status of children who had fever recently seemed high probability of underweight than those children who have no fever recent (42.2%, 42.5 %, respectively). The evidence given in Table 2 shows that the percentages nutritional status of children in households who had unprotected water seemed to be more severe of underweight than those children in households which used water from protected source.
3.1.1. Continuous Covariates
- In this study, it seems reasonable to assume that the Z-score is (at least approximately) Gaussian distributed and, thus, model (6) could in principle be applied. Figure 1 shows a histogram estimate of the distribution of the Z‐scores of weight-for-age variable. The plots suggest that the Z-score can be reasonably approximated by a Gaussian distribution. The plot of weight‐for‐age Z-scores versus child age is given in Appendix, Figure 2. The exact shape of the influences is unknown and, hence, no simple model can be established to link the nutritional status scores to the age of the child. This effect would be explored by a nonparametric method. The plot of weight-for-age scores versus mother’s age at child birth is given in Figure 3. The plot of weight-for-age Z-score versus BMI is given in Figure 4. There is no definite pattern of relationship that can be observed from the scatter plot of body mass index (BMI) versus mean weight‐for‐age (z-score) presented in Figure 4 and this relationship can be explored by a nonparametric method.
|
3.2. Results of Bayesian Semi-parametric Analysis
- The whole analysis has been implemented using software BayesX (Belitz Andreas Brezger, 2009)[23]. The fitted model was:Z-score=
 +f1(MBI)+f2(Mage)+f3(Cage)+Csexγ1+Resγ2+BORDγ3+pint1γ4+Pbint2γ5 +HHM1γ6+HHM2γ7+Medu1γ8+Medu2γ9+tfacilitγ10+Vacγ11+Coughγ12+Drrhγ13+feverγ14+windexγ15
+f1(MBI)+f2(Mage)+f3(Cage)+Csexγ1+Resγ2+BORDγ3+pint1γ4+Pbint2γ5 +HHM1γ6+HHM2γ7+Medu1γ8+Medu2γ9+tfacilitγ10+Vacγ11+Coughγ12+Drrhγ13+feverγ14+windexγ15 3.2.1. Linear Fixed Effects
- Table 3 gives results for the fixed effects (categorical covariates) on the nutritional status of children under age five in Ethiopia. The output gives posterior means, posterior median along with their standard deviations and 90% credible intervals. Since the 90% confidence interval do not include zero, Sex of child, birth order of child, birth interval, place of residence, cough, respondent’s current work status, mothers education level, toilet facility, household members, household economic status, diarrhea status of child and fever status of child were found statistically significant at 5% significance level. But, source of drinking water and vaccination were found statistically insignificant. From Table 3, one can observe that having an educated mother (at least primary education) contributes to better nourishment for children under five age which has also been found in other studies[16,15]. In this study, the relative chance to be underweight for the children was found to decrease with the increase of mother’s educational level. The children of illiterate mothers and those with incomplete primary education were more likely to be malnourished as compared to mothers with secondary education and higher. The findings support the statement that educated mothers were more conscious about their children’s health[14]. Literate mothers can easily introduce new feeding practices scientifically, which helps to improve the nutritional status of children. And also the analysis shows that female children are better nourished than male children. On the other hand, one can observe that underweight is higher for children of higher birth order (other than first born), larger household’s members, and for child residents in the rural areas. Also we observe that larger household is not conducive for better nourishment of children. However, one may interpret that while larger households provide more care to children (mostly by elder members of the household in a joint or extended family setting), there seemed to be a simultaneous competition for resources within the same larger household size. This competition for limited resources may be responsible for worsening of nutritional status for the children of a larger household size. Household factors are strong indicators of children’s underweight status. Children in households having higher income have better nutritional status than that of lower income households. The results indicate that the risk of children being underweight decreased with the increase of household wealth index. The children of households having the lowest wealth index were more likely to be underweighted than those of household with the highest wealth index. Working status of mothers which might increase economic status of household had significant effect on child nutritional status. The prior birth interval matters for the nutritional status of the child. The analysis showed that children born after a long birth interval were better off than other children. This statement is in agreement with[26] which found that, children with a birth interval of 2 or more years were less likely to be underweight. This may be due to the fact that the parents can take better care of fewer numbers of children and could provide adequate breast milk due to recovery of nutritional status between births. The results also indicate that source of water had no significant effect on child stunting status.
3.2.2. Non-linear Effects under Generalized Additive Linear Regression Models
- Nonlinear effects represented by smoothed functions, are commonly interpreted graphically. Figure 5 shows the smooth function of the children age versus weight‐for‐age z-score. The posterior means together with 80% and 95% point wise credible intervals are shown. One can observe that the influence of a child’s age on its nutritional status is considerably high in the age range between the ages of 0-27 months with decreasing trend; and then stabilizes. As suggested by the nutritional literature, one can able to distinguish the continuous worsening of the nutritional status up until about 27 months of age. This deterioration set in right after birth and continues, more or less linearly, until 27 months. After 27 months the effect of age on underweight stabilizes at a low level. Through reduced growth and the waning impact of infections, children were apparently able to reach a low‐level equilibrium that allows their nutritional status to stabilize[21, 14, 23, 21].Figure 6 displays nonlinear effects of mother’s age at birth in years. It shows the posterior means together with 80 % and 95% point-wise credible intervals. It is evident from the analysis that increasing age of mother at birth reduces underweight status of children. That is younger mothers tend to have more underweighted children than older mothers. Mother age at birth shows significant effect on underweight status of children under age of five years old. The effect of mother’s age on her child’s underweight status (other constant) negatively increase as her age increase up to 25 years and then after the effect of mothers age on her child’s underweight status positively increase.
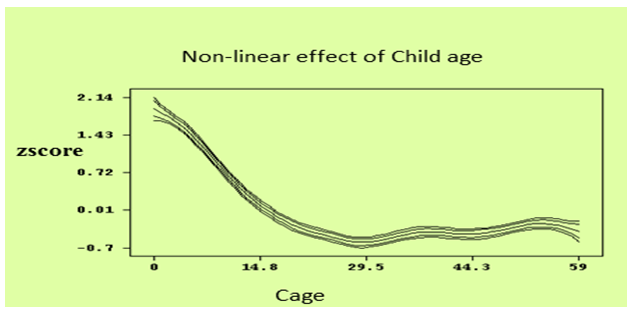 | Figure 5. Non-linear Effects of Child’s Age in months on Nutritional Status of a Child |
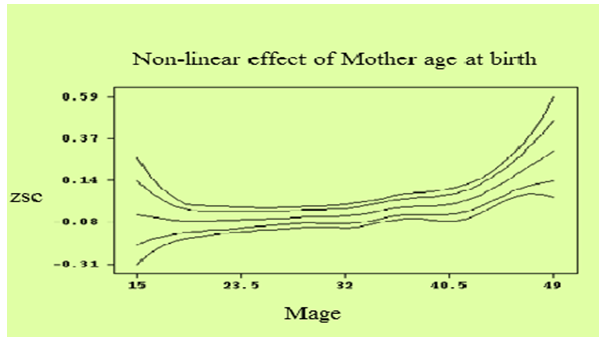 | Figure 6. Non-linear Effects of Mother’s Age in years on Nutritional Status of a Child |
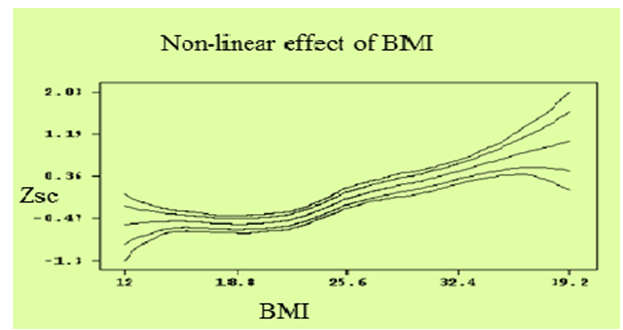 | Figure 7. Non-linear Effects of Mother’s Body Mass Index (kg/m2) on Nutritional Status of a Child |
3.3. Discussion
- This study was intended to identify the determinants of the underweight status of children under five years old in Ethiopia based on EDHS 2011 data. The nutritional status was measured by the weight-for-age. Accordingly, Bayesian semi-parametric regression analysis on underweight was employed to identify flexibly the effect of covariates on nutritional status of the children. In this study, underweight was analyzed based on the modified anthropometric measurement indicators of the nutritional status of children calculated using new growth standards published by the World Health Organization in 2006. The results obtained are discussed as follows. The total number of children covered in the present study was 8200, among which 36.4 % were underweight. The Bayesian semi-parametric analysis revealed that the covariates: sex of child, birth order of child, place of residence, cough, previous birth interval, mothers education level, toilet facility, household members, household economic status, diarrhea and fever were found statistically significant. But, source of drinking water and vaccination were found statistically insignificant (though not expected).Preceding birth interval is an important demographic variable that affects nutritional status of children. As the preceding birth interval increases, the nutritional status of a child increases. This finding is confirmed by most of previous studies[19, 21, 13]. The significant and higher risk of underweight among children of lower preceding birth interval could be due to uninterrupted pregnancy and breastfeeding, since this drains women’s nutritional resources. Close‐spacing may also have a health effect on the previous child who may be prematurely weaned if the mother becomes pregnant too early again.The fact that mother education level was significant is in agreement with different reports under taken on the same problem. According[28], with an increase in mothers’ educational level, incidence of malnutrition among young children decreases. And this factor is then directly associated to the women’s own nutritional status and quality of care they receive[39]. The educated mothers are more conscious about their children’s health. Literate mothers can easily introduce new feeding practices scientifically, which help to improve their children nutritional status[26].Household economic status is also an important socio - economic variable that affects nutritional status of children in Ethiopia. Children in poor households were found to be at a higher risk of malnutrition problem than children from rich households. This finding is consistent with other studies[19, 11]. The study indicated that better off households had better access to food and higher cash incomes than poor households, allowing them a quality diet, better access to medical care and more money to spend on essential non-food items such as schooling, clothing and hygiene products.As the study has revealed that, household size is an important variable that affects nutritional status of children. The prevalence of underweight increased with increasing household size. Households with more than 10 and above child had a higher percentage of underweight children (39.5%) compared with households with less than five children (37.1 %). Large household size is not conducive for better nourishment of children. However, we may interpret that while larger households provide more care to children (mostly by elder members of the household in a joint or extended family setting), there seemed to be a simultaneous competition for resources within the same larger household size. This competition for limited resources may be responsible for worsening of nutritional status for the children of a larger household size. This result is in agreement with a study under taken by[31] which stated that children living in a household with only one child have a lower risk of nutrition than children who live in households with more than one child. The total number of children within a household influences the resources available to each child, in terms of financial, time and attention. In a crowded household, exposure of an individual child to infection is also increased[32].As shown in the analysis, urban children were less likely to be malnourished than their rural counterparts because the quality of health environment and sanitation is better in urban areas, whereas, the living condition in rural areas were associated with poor health condition, and lack of personal hygiene, which were the risk factors in determining malnutrition. This is consistent with some studies, where mothers’ place of residence has a statistical significant effect on children nutritional status[27, 11]. The findings of this study also showed that children who had diarrhea two weeks before date of survey are vulnerable to malnutrition problem than those who had not. This finding is consistent with other studies[13, 33, 34]. This may be due to the fact that diarrhea accelerates the onset of malnutrition by reducing food intake and increasing catabolic reactions in the organism. Diarrhea also affects both dietary intake and utilization, which may have a negative effect in child nutritional status. The type of toilet used by a household is an indicator of household wealth and a determinant of environmental sanitation. This means that poor households were less likely to have sanitary toilet facilities. In consequence, these results increased risk of childhood diseases, which contribute to malnutrition.It is evident that increasing age of mother’s at birth reduces underweight and shown that children whose mothers are older age group were better in their underweight status as compare to children whose mothers are in the younger age group. The mother’s age at birth of the index child was found to be a statistically significant predictor of children’s underweight status in a number of previous studies, where it was found that children born to mothers between the ages of 20 and 29 years were more likely to have children that suffered from negative nutritional outcomes than those children born to older mothers[35]. Children whose mothers are older than 30 years of age are better in their stunting status as compare to children whose mothers are in the younger age group[14].In the study, the effect of the age of the child is obviously nonlinear and decreasing between birth and an age of about 20 months and then stabilizes. That means the underweight of children increases until 24 months. This continuous worsening of the nutritional status may be caused by the fact that most of the children obtain liquids other than breast milk already shortly after birth. After 24 months a relatively stable, low level is reached. However, it reaches its minimum level between ages 24-30 months, then rises again and stabilizes thereafter at a middle level with a bump till 5 years. Previous studies also confirm this[27, 13, 14]. Mother’s body mass index is defined as her weight in kilo‐grams divided by her square of her height in meters. Mothers with low BMI value are themselves malnourished and are therefore likely to have undernourished children. The same finding is also found in a number of studies. Mothers with low BMI on average giving birth to babies of low birth weight[14].
4. Conclusions
- The main objective of this study was to identify the most important predictors of under five years old children underweight status in Ethiopia using Bayesian Semiparametric regression model. The study revealed that socio-economic, demographic and health and environmental variables have significant effect on the underweight status of children in Ethiopia. Using Bayesian Semiparametric regression model, the predictors, sex of child, birth order of child, preceding birth interval, place of residence, cough, mother’s education level, toilet facility, household members, household economic status, diarrhea and fever are the most important determinants of child underweight status in the country. The study showed that children from uneducated mother, lower preceding birth interval (less than 24 months), higher birth order, economically poor household, large household size are more vulnerable to underweight problem in Ethiopia. The findings of this study also showed that children who had diarrhea and fever for two weeks before the date of survey are significantly vulnerable to underweight problem than those who had not. Male children are more vulnerable to underweight problem than female children. The study analyzed how the continuous covariates: child's age, mother's age at birth and mother's BMI affect underweight status of the child. The underweight status of a child improves as mother’s body mass index increases. And children are at high risk of underweight problem during the first 0‐24 months of their life and then stabilize moderately with bump. The study also revealed that children whose mothers are in the older age group are better in their nutritional status as compare to children whose mothers are in the younger age group.
Appendixes
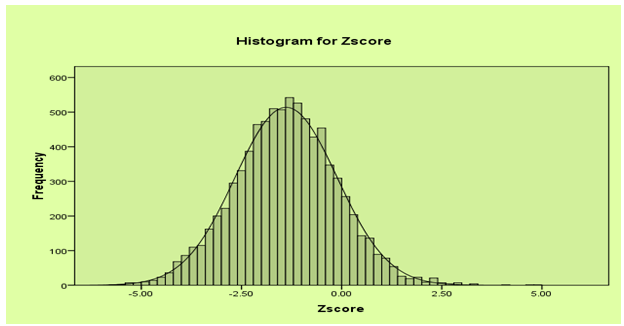 | Figure 1. Histogram for Zscore |
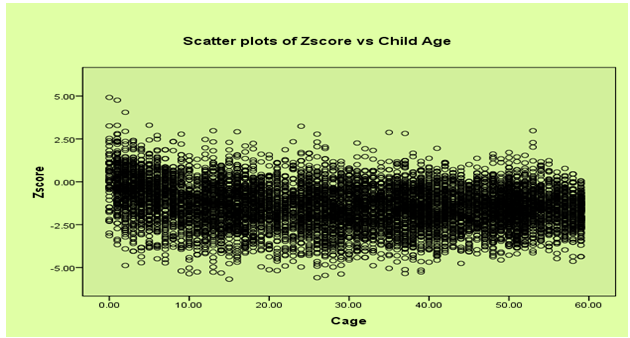 | Figure 2. Scatter plots of Zscore vs Child Age in months |
 | Figure 3. Scatter plots of Zscore vs mother age at child birth in years |
 | Figure 4. Scatter plots of Zscore vs Mother’s Body Mass Index (kg/m2) |
References
| [1] | World Bank (2007). Nutritional Failure in Ecuador: Causes, Consequences, and Solutions. The World Bank: Washington, DC. |
| [2] | UNICEF (2009). Tracking Progress on Child and Maternal Nutrition, a Survival and Development Priority. |
| [3] | Maleta, K. (2006). Epidemiology of Undernutrition in Malawi, Chapter 8 in The Epidemiology of Malawi, Edited by Eveline Geubbles and Cameron Bowie. |
| [4] | HKI (2001). Reduction in diarrheal diseases in children in rural Bangladesh by environmental and behavioral modifications. Transactions of the Royal Society of Tropical Medicine and Hygiene |
| [5] | WHO (1995). Physical Status: The Use and Interpretation of Anthropometry. WHO Technical Report Series No. 854. Geneva. |
| [6] | Kandala, NB; Fahrmeir L; Klasen S; Priebe J (2009). Geo-additive Models of Childhood Undernutrition in Three Sub-Saharan African Countries. Population, Space and Place. |
| [7] | Klasen, S. and Moradi, A. (2000). The Nutritional Status of Elites in India, Kenya and Zambia: An Appropriate Guide for Developing Reference Standards for Undernutrition? Sonderforschungsbereich 386: Discussion Paper no. 217. Deutsche Forschungsge- meinschaft. |
| [8] | Kibel ,M.; Saloojee; H. & Westwood, T. (2007). Child Health for All. (4th Edition). Oxford University Press: Cape Town (South Africa). |
| [9] | FAO/WFP (2009). Special Report on Crop and Food Security Assessment Mission to Ethiopia: Integrating the Crop and Food Supply and the Emergency Food Security Assessments. Rome, Italy. |
| [10] | NNS (2009). Ethiopia National Nutrition Strategy Review and Analysis of Progress and Gaps: One Year On May 2009. |
| [11] | Woldemariam Girma and Timotiows Genebo (2002). Determinants of Nutritional Status of Women and Children in Ethiopia |
| [12] | Hastie, T. and Tibshirani, R. (1990). Generalized Additive Models. Chapman and Hall, London. |
| [13] | Khaled, K. (2007). Child Malnutrition in Egypt Using Geoadditive Gaussian and Latent Variable Models. |
| [14] | Mohammad, A. (2008). Gender Differentials in Mortality and Undernutrition in Pakistan: Peshawar (Pakistan). |
| [15] | Mila, A.L.; Yang, X.B. and Carriquiry, A.L. (2003). Bayesian Logistic Regression of Clinical Epidemiology for Uncertainty in Parameter Estimation. Basic Science for Clinical Medicine: Little, Brown and Company, Boston. |
| [16] | Fahrmeir, L. and Lang, S. (2001). Bayesian Inference for Generalized Additive Mixed Models Based on Markov Random Field Priors. Applied Statistics (JRSS C), Vol 50, P. 201‐220. |
| [17] | Fahrmeir, L. and Lang, S. (2004). Bayesian Semiparametric Regression Analysis of Multicategorical Time-Space Data. To appear in Ann. Inst. Statist. Math. |
| [18] | Hastie, T. and Tibshirani, R. (2004). Bayesian Back Fitting. (To Appear in Statistical Science). |
| [19] | Kandala, NB.; Fahrmeir, L and Klasen, S. (2010). Geo-additive Models of Childhood Undernutrition in Three Sub-Saharan African Countries. Sonderfor |
| [20] | Brezger, A. and Lang S. (2006). Generalized Structured Additive Regression based on Bayesian P-Splines. Computational Statistics and Data Analysis, Vol 50,P. 967-991. |
| [21] | Khaled, K. (2010). Child Malnutrition in Egypt Using Geoadditive Gaussian and Latent Variable Models. |
| [22] | Spiegelhalter, DJ (2002). Bayesian measures of model complexity and fit. |
| [23] | Belitz, C.; Brezger A., Kneib T.; Stefan L. (2009). BayesX Software for Bayesian Inference in Structured Additive Regression. Department of Statistics, Ludwig Maximilians University Munich. Version, 2.0.1. |
| [24] | CSA (2011). Ethiopian Demographic and Health Survey. Addis Ababa |
| [25] | Olivier, Francois (May, 2011). Deviance Information Criteria for Model Selection in Approximate Bayesian Computation. Institute Pasteur, Human Evolutionary Genetics, Paris, France. |
| [26] | Das , S., Hossain; M.Z., & Islam, M.A. (2008). Predictors of Child Chronic Malnutrition in Bangladesh. Proc.Pakistan Acad. Sci. 45(3): P.137-155. |
| [27] | Kandala ,NB; S. Lang; S. Klasen, and L. Fahrmeir (2006). Semiparametric Analysis of the Socio-Demographic Determinants of Undernutrition in Two African Countries. Research in Official Statistics, EUROSTAT, Vol. 4 No.1:P. 81-100. |
| [28] | Sasha, F. (2009). An Analysis of Under-Five Nutritional Status in Lesotho: The Role of Parity Order and Other Socio-Demographic Characteristics. |
| [29] | Smith, L. C. and Haddad L. (1999). Explaining Child Malnutrition in Developing countries: a Cross Country Analysis. International Food Policy Research Institute, FCND Discussion paper, USA. |
| [30] | Semba, R. D.; de Pee, S., Sun, K.; Sari, M.; Akhter, N., & Bloem, M.W. (2008). Effect of Parental Formal Education on Risk of Child Stunting in Indonesia and Bangladesh: A Cross Sectional Study. Lancet 371(9609):P.322-328. |
| [31] | Rahman, A. & Chowdhury, S. (2007). Determinants of Chronic Malnutrition Among Preschool Children in Bangladesh. Journal of Biosocial Science 39(2):P.161-173. |
| [32] | Sereebutra, P.; Solomons, N.; Aliyu, M.H., & Jolly, P.E. (2006). Socio-Demographic and Environmental Predictors of Childhood Stunting in Rural Guatemala. Nutrition Research. |
| [33] | WHO (2011). World Health Statistics, (The Millennium Development Goals Report), United Nations 2011. |
| [34] | Birhan Fetene (2010). Determinants of Nutrition and Health Status of Children in Ethiopia: A Multivariate Multilevel Linear Regression Analysis. Addis Ababa University |
| [35] | Som, S.; Pal M.; Bhattacharya; B. Bharati, S. & Bharati, P. (2006). Socio-Economic Differentials in Nutritional Status of Children in the States of West Bengal and Assam, India. Journal of Biosocial Sciences. Vol.38: P.625-642 |