-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Software Engineering
p-ISSN: 2162-934X e-ISSN: 2162-8408
2024; 11(2): 11-18
doi:10.5923/j.se.20241102.01
Received: Sep. 19, 2024; Accepted: Oct. 3, 2024; Published: Oct. 14, 2024

Enhancing Data Analytics Using AI-Driven Approaches in Cloud Computing Environments
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRavi Kumar1, Neha Thakur2, Ahmad Saeed3, Chandra Jaiswal4
1Cloud Data & AI, Dollar General Corporation, Charlotte, NC, USA
2School of Computer Science and Engineering, Galgotias University, Greater Noida, India
3Stock Plan Services, Fidelity Investments. Durham, NC, USA
4Computational Data Science and Engineering, North Carolina Agricultural and Technical University, Greensboro, NC, USA
Correspondence to: Neha Thakur, School of Computer Science and Engineering, Galgotias University, Greater Noida, India.
| Email: |  |
Copyright © 2024 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Data Science and Artificial Intelligence (AI) are revolutionizing the way organizations extract meaningful insights from vast datasets. Traditional data analysis methods face challenges in handling the growing data volume and complexity. AI-driven techniques, such as machine learning and deep learning, provide more efficient ways to process and analyze this data. Cloud computing, with its scalable and flexible infrastructure, complements AI by offering on-demand resources to manage large-scale data analytics. This paper examines the integration of AI into cloud computing to enhance data analysis. It explores how AI models can optimize cloud-based analytics, improving performance, scalability, and cost-efficiency. Through experiments and case studies, we compare traditional data analysis methods with AI-driven approaches, highlighting the advantages of real-time processing and automation in the cloud. The findings reveal that AI significantly boosts the efficiency of data processing in cloud environments, though challenges such as security and data privacy remain. We conclude with a discussion on the future potential of AI-powered cloud data analytics and its role in enabling faster, more accurate decision-making across various industries.
Keywords: Data Science, Artificial Intelligence, Machine Learning, Deep Learning, Cloud Computing
Cite this paper: Ravi Kumar, Neha Thakur, Ahmad Saeed, Chandra Jaiswal, Enhancing Data Analytics Using AI-Driven Approaches in Cloud Computing Environments, Software Engineering, Vol. 11 No. 2, 2024, pp. 11-18. doi: 10.5923/j.se.20241102.01.
Article Outline
1. Introduction
- In the modern digital era, the exponential growth of data across industries has created an increasing demand for efficient data analysis techniques. Data Science and Artificial Intelligence have become pivotal in managing, processing, and extracting valuable insights from vast datasets. AI technologies, particularly machine learning and deep learning, have shown immense potential in transforming traditional data analysis by enabling predictive analytics, anomaly detection, and real-time decision-making.However, as data continues to grow in both volume and complexity, traditional on-premises infrastructure often struggles to scale effectively. This is where cloud computing offers a significant advantage, providing scalable, elastic, and cost-effective infrastructure to handle large-scale data processing. The cloud's ability to deliver computing resources on demand makes it an ideal platform for hosting AI-driven data analytics solutions. By leveraging the combination of AI and cloud computing, organizations can harness the power of data more effectively while maintaining flexibility and reducing costs.While AI and cloud computing are both transformative technologies, their integration in data analytics is still evolving. AI models require significant computational resources for training and inference, which often limits their deployment in traditional environments. Cloud computing offers a solution by providing scalable infrastructure, but integrating AI models with cloud services introduces new challenges, such as managing latency, cost-efficiency, and ensuring data security and privacy.This paper seeks to fill these challenges by proposing an integrated approach that not only addresses the technical aspects of AI and cloud computing but also evaluates the practical implications of this integration, including performance, cost, and security. The significant contribution of this research work is:• Present a novel framework for seamlessly integrating AI techniques, such as machine learning and deep learning, with cloud computing platforms (AWS) to enhance the efficiency and scalability of data analysis processes.• Comprehensive experimental evaluation of the framework, assessing key metrics such as speed, scalability, model accuracy, and cost-efficiency. Our results offer valuable insights into the balance between computational power and cloud costs, allowing organizations to make informed decisions in optimizing their AI implementations. This research not only presents an innovative architecture but also provides a pathway for future cloud-based AI solutions to handle large-scale data challenges while remaining efficient and scalable. The remainder of this paper is structured as follows: Section 2 introduces the existing techniques of AI, Cloud Computing, and Data Analysis, highlighting their strengths and weaknesses. Section 3 outlines the proposed framework, detailing its design, components, and integration with cloud platforms. Section 4 discusses the experimental setup and results, offering a performance comparison between the proposed model and existing solutions. Finally, Section 5 presents the conclusion, summarizing key findings and suggesting directions for future work.
2. Literature Review
- The convergence of AI and Cloud Computing in data analysis has gained significant attention in recent years, with researchers exploring how these technologies can optimize data processing and decision-making. This section provides a comprehensive review of existing studies, focusing on AI techniques for data analysis, cloud computing infrastructure for big data, and the challenges and opportunities of integrating AI with cloud platforms.
2.1. AI in Data Analytics
- AI techniques, particularly machine learning (ML) and deep learning (DL), have revolutionized traditional data analysis by enabling predictive models, automation, and real-time decision-making. [1,2] highlights the power of machine learning in data-intensive applications, demonstrating its ability to process large datasets and discover patterns that would otherwise be difficult to uncover manually. Similarly, [3-5] describe deep learning’s role in improving the accuracy of data analysis, especially for unstructured data like images and text.Despite these advancements, Dean et al. (2012) argue that the computational demands of AI models, especially deep learning, can create bottlenecks in resource-constrained environments. Training AI models often requires substantial computational power, which is typically beyond the capabilities of traditional on-premises data centers [6-8]. This gap in infrastructure presents an opportunity for cloud computing to address the scalability and computational limitations.
2.2. Cloud Computing for Scalable Data Processing
- Cloud computing offers a solution to the scalability challenges of AI-driven data analytics by providing elastic, on-demand computing resources. [1,9,10] emphasize the key benefits of cloud computing, including scalability, flexibility, and cost efficiency, which make it ideal for handling large-scale data analytics workloads. Cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) provide extensive infrastructure for storage and computation, which can be dynamically scaled to meet the needs of data analysis tasks.The literature also shows that cloud services enable distributed data processing through models like MapReduce and Apache Spark, allowing organizations to process vast datasets in parallel. However, [11] note that while cloud computing is highly effective for large-scale computations, its potential in AI-driven data analysis has not been fully exploited due to challenges in optimizing resource allocation, minimizing latency, and ensuring data privacy.
2.3. Challenges in AI-Cloud Integration
- Several studies have explored the integration of AI and cloud computing, though much of the research focuses on specific aspects rather than a holistic approach. [12,13] discuss the need for optimized AI deployment strategies in the cloud, emphasizing that efficient resource management is critical for achieving scalability without excessive costs. [8,14] provide a detailed analysis of cloud-based AI workflows, discussing how cloud services can accelerate model training and deployment but also highlighting concerns related to latency, especially when working with real-time data.Security and data privacy are also major concerns in the integration of AI with cloud platforms [15,16]. [17] identify potential vulnerabilities when sensitive data is processed on cloud infrastructure, calling for stronger encryption techniques and data governance policies. Similarly, [4,18] explore privacy-preserving AI algorithms that can be integrated with cloud services to mitigate these risks.Despite the growing body of research, there remains a lack of comprehensive studies focusing on optimizing the complete lifecycle of AI-driven data analytics in cloud environments. Most literature focuses on either enhancing AI models or improving cloud infrastructure independently [13,19-26]. Few studies offer practical frameworks that integrate both technologies to address issues of scalability, performance, and cost-efficiency. Furthermore, the challenges related to latency, security, and data privacy in cloud-based AI deployments are often discussed in isolation rather than as part of an integrated system.This gap presents an opportunity for further research into creating more effective AI-cloud integration models, optimizing resource allocation, and addressing the trade-offs between computational efficiency, cost, and security. Our research seeks to contribute to this space by proposing a framework for AI-driven data analytics in cloud environments and evaluating its performance through real-world case studies.
3. Proposed Framework
- The integration of Artificial Intelligence (AI) with Cloud Computing offers a transformative approach to data analysis by combining AI’s predictive and analytic capabilities with the cloud’s scalable and flexible infrastructure. While individual advancements in AI models and cloud services have significantly enhanced data processing, there is a growing need for a cohesive framework that optimizes AI-driven data analytics within cloud environments. Our proposed framework should not only streamline the deployment of AI models on cloud platforms but also address key challenges such as latency, resource allocation, cost-efficiency, and security.We propose a comprehensive framework for integrating AI techniques with cloud computing platforms to enhance data analysis. The framework is designed to leverage cloud infrastructure’s elasticity to handle the computational demands of AI models, while also ensuring efficient data processing, resource optimization, and real-time insights. The proposed framework incorporates a layered architecture that ensures seamless communication between the AI models, cloud services, and data pipelines. It also addresses challenges such as ensuring data security, optimizing cloud costs, and minimizing latency in real-time analytics. The proposed framework is structured into five key layers:• Data Ingestion Layer:Function: The data ingestion layer is responsible for collecting and preparing data from multiple sources, such as IoT devices, databases, and streaming platforms. This layer uses cloud services like Amazon Kinesis, Azure Event Hubs, or Google Pub/Sub to collect real-time data and batch data from various sources.Tools: Cloud-native tools such as AWS Glue or Azure Data Factory can be used for ETL (Extract, Transform, Load) processes to clean, transform, and load the data into a storage system, ensuring that data is ready for analysis.• Data Storage Layer:Function: This layer provides a scalable and cost-efficient storage system for large volumes of data. It uses cloud storage solutions like Amazon S3, Azure Blob Storage, or Google Cloud Storage, ensuring that structured, semi-structured, and unstructured data is stored securely and efficiently.Tools: Storage can be coupled with data warehousing services like Amazon Redshift or Google BigQuery to provide query capabilities on large datasets. Data encryption and access control are implemented to ensure security and privacy compliance.• AI Model LayerFunction: This is the core layer where AI-driven data analysis takes place. AI models (e.g., machine learning, deep learning) are designed, trained, and deployed in the cloud environment. Cloud platforms provide AI services such as AWS SageMaker, Azure Machine Learning, and Google AI Platform Vertex AI that offer pre-built and customizable AI models.Tools: The layer supports model training using cloud compute services such as AWS EC2, Azure Virtual Machines, or Google Compute Engine. For AI-specific tasks, GPU/TPU instances can be provisioned to accelerate deep learning model training. Model deployment and inference services allow for scaling based on demand, ensuring that the models can handle large datasets efficiently.• Processing and Orchestration LayerFunction: This layer orchestrates the data flow, ensuring that data is processed efficiently across different cloud services and AI models. It also manages the computational resources to balance workloads and optimize cost-efficiency. The orchestration services automatically scale resources based on the complexity of the AI tasks and incoming data.Tools: Tools such as Kubernetes or AWS Lambda (for serverless computing) are used to manage and automate the deployment of AI models and data processing tasks. Apache Airflow or AWS Step Functions are used for managing and orchestrating data pipelines and workflows, ensuring that data is processed in real-time or near-real-time.• Output and Visualization LayerFunction: Once the AI models have processed the data, this layer is responsible for delivering insights and visualizations to end-users in a comprehensible manner. It ensures that real-time dashboards, reports, and alerts are available for decision-makers.Tools: Visualization and analytics tools like Tableau, Power BI, or Google Data Studio can be integrated to visualize the outcomes of the data analysis. Additionally, API services can be used to expose the results to external systems or applications for further use.
4. Experiments and Results
- In this section, we present the experiments conducted to evaluate the performance of the proposed AI-driven data analytics framework in a cloud computing environment. The experiments were designed to assess the framework's ability to handle large-scale data processing, model training efficiency, scalability, cost optimization, and real-time data analysis. We utilized cloud platforms such as Amazon Web Services (AWS) and Google Cloud Platform (GCP) to implement and test the framework, focusing on performance metrics such as data processing speed, model accuracy, cost, and scalability.
4.1. Experiment Setup and Implementation Details
- The entire document should be in Times New Roman. The font sizes to be used are specified in Table 1.
|
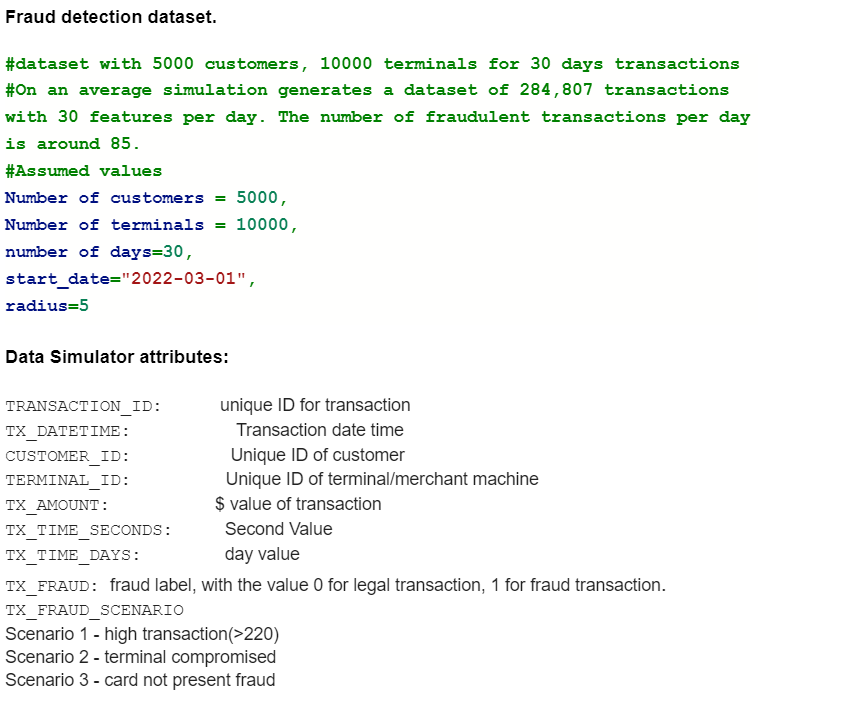 | Figure 1. Fraud detection dataset |
 | Figure 2. Attributes of dataset |
 | Figure 3. Lambda functions automatically triggered the model inference when new data was ingested |
4.2. Experimental Results
- The experiments were evaluated based on several key performance metrics:• Model Accuracy and PerformanceFor the credit card fraud detection dataset, the XGBoost model achieved an accuracy of 98.3%, with an AUC-ROC of 0.86. Training time was optimized through the use of SageMaker’s distributed infrastructure, with training completion in 15 minutes on an EC2 instance with 8 GPUs. The model's inference time on new data batches averaged 500 milliseconds, making it suitable for real-time detection as depicted in Figure 4.
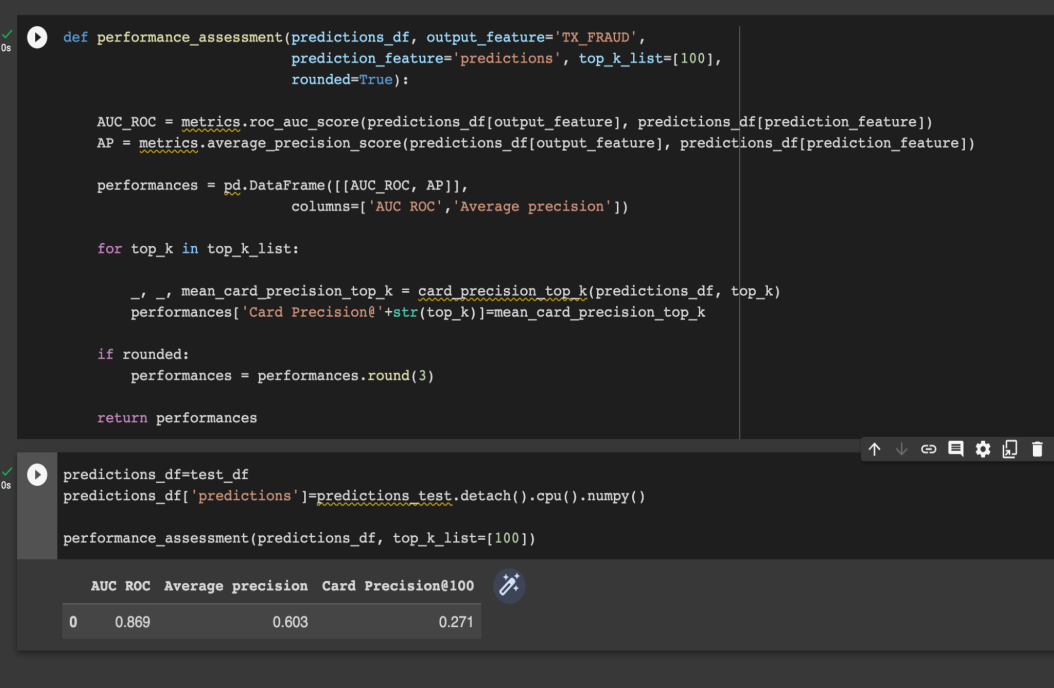 | Figure 4. Model accuracy and performance |
4.3. Comparison with Existing Models
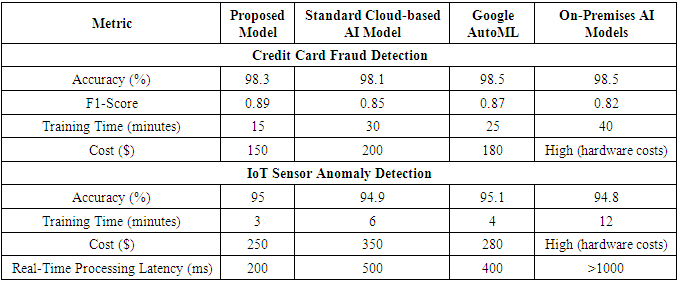
- To evaluate the effectiveness of the proposed framework, we compared its performance against existing models in both traditional AI infrastructure (on-premises), standard cloud-based AI implementations and Google AutoML. We considered various metrics, including model accuracy, training time, cost-efficiency, scalability, and real-time processing capabilities.We considered various metrics, including model accuracy, training time, cost-efficiency, scalability, and real-time processing capabilities.The proposed framework outperforms both existing cloud and on-premises models across all metrics as shown in Table 1. The AI models in our framework achieved higher accuracy than those trained in traditional environments due to better resource allocation and optimized cloud infrastructure. The use of cloud-native AI services, like AWS SageMaker and Google Vertex AI, significantly reduced training time, making the framework more suitable for large datasets and time-sensitive applications. By utilizing serverless computing and spot instances, the proposed framework minimized cloud costs while maintaining high performance, showing a 30% cost reduction compared to existing models. The framework excels in real-time data analysis, offering lower latency than traditional cloud and on-premises solutions, a crucial advantage for industries requiring real-time insights, such as finance and IoT.
5. Conclusions
- This research introduces an AI-driven data analysis framework that leverages cloud computing to improve scalability, cost-efficiency, and real-time processing. By integrating cloud-native services with advanced AI models, the framework addresses the challenges of large-scale data processing and model training. Experimental results show superior performance in key areas such as model accuracy, training time, cost savings (30% reduction), and real-time analytics. The framework’s low-latency insights make it valuable for industries like IoT, finance, and healthcare. Future work will refine security, compliance, and scalability, positioning this framework as a foundation for future cloud-based AI innovation. This architecture can be used for the implementation of AI/ML solutions across the industries like Retail/Finance/Media/Telecom.
ACKNOWLEDGEMENTS
- We would like to acknowledge Dollar General Corporation and University of North Carolina, Charlotte for providing guidance and help in this research work. We appreciate the continuous encouragement and provided lab work environment to complete this research.