-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Software Engineering
p-ISSN: 2162-934X e-ISSN: 2162-8408
2012; 2(4): 124-128
doi: 10.5923/j.se.20120204.05
Verification of Web Sites with Fixed Cost
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLDoru Anastasiu Popescu , Dragos Nicolae
Department of Computer Science, National College "Radu Greceanu", Slatina, Olt, Romania
Correspondence to: Doru Anastasiu Popescu , Department of Computer Science, National College "Radu Greceanu", Slatina, Olt, Romania.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In this paper, we will introduce the notion of cost associated to web sites, from the point of view of verification. We will determine, using an algorithm, some web pages in order to maximize the number of verified web pages so that the verification has a total cost less than or equal to a fixed cost. In order to do this, we use the notion of sink web pages which are determined using a relation between the web pages.
Keywords: Relation, Tag, HTML, Sink Web Page
Cite this paper: Doru Anastasiu Popescu , Dragos Nicolae , "Verification of Web Sites with Fixed Cost", Software Engineering, Vol. 2 No. 4, 2012, pp. 124-128. doi: 10.5923/j.se.20120204.05.
Article Outline
1. Introduction
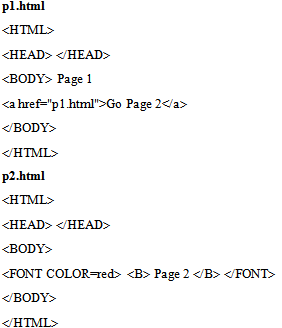
- This paper presents a notion introduced by the authors in [8] and [15] together with a new application. The web sites used in this paper consist of web pages which contain only HTML tags.We will define the verification cost associated to a tag with attributes, respectively associated to a web page and to a web site. A detailed example is presented in section 2, in order to understand the definition of the relation RTG and the method used to calculate the verification costs. Then, we will define the notion of sink web page, notion used as well in [8], [12] and [15] for different applications.The relation used in section 2 is used through different methods in [6], [9], [11] and [13] and is dependent on a set of tags TG, chosen based on the web site, in order to have a larger or a smaller number of sink web pages.In section 3, a method of selecting some web pages is being presented so that by verifying those web pages, others are being implicitly verified. Taking into consideration that a web site can contain a large number of web pages and that the process of verifying them is complex and expensive from the point of view of time, two aspects have been considered: maximizing the number of web pages which are being implicitly verified by the selected web pages and the cost of verifying those selected web pages that should not be higher than a fixed threshold. A web page p is implicitly verified by a web page q if all the tags in p, which are not members of a fixed set TG, can be found in q in the same order.The algorithm presented in section 3 determines the sink web pages necessary for verification, with the mentioned restrictions.The effective verification of the web pages is not the target of this paper, taking into consideration the fact that several descriptions of this process have been presented in [2], [3], [4] and [8].The novelty of this paper consists in the method of defining the cost for verifying a web site and selecting the sink web pages which are necessary in this process.
2. Sink Web Pages
- Next, we will consider a web site with the set of web pagesP={p1, p2, ... , pn} and a set TG of tags.In [12] is defined a relation between two web pages, allowing us to say about a web page if its content can be found in the structure of another web page. Using this relation, we can select from a set P of web pages, some of them that contain all the building tags of the web site. Those web pages are called sink web pages ([8], [12], [15]). Next, we briefly introduce these notions with an example that will be useful in section 3.For any web page pi from P, we write Ti the sequence of tags, without their arguments, from pi, which are not members of TG.Definition 1Let TG be a set of tags, pi and pj two web pages from P.We say that Ti=(Ti1, Ti2, ..., Tia) is in relation ≤TG with Tj=(Tj1, Tj2, ..., Tjb) and we write Ti ≤TG Tj, if a ≤ b and there is an index set w={w[1], w[2], ..., w[a]}, with:1 ≤ w[1] < w[2] < ... < w[a] ≤ b;Tjw[1] = Ti1, Tjw[2] = Ti2, ..., Tjw[a] = Tia.Definition 2Let TG be a set of tags, pi and pj two web pages from P. We say that pi is in relation RTG with pj and we write pi RTG pj, if:i) Ti ≤TG Tj;ii) For any tag

 According to previous definitions, we obtain the following pairs of pages which are in relation RTG one with each other:p1 RTG p7;p2 RTG p3; p2 RTG p4 ;p5 RTG p4; p5 RTG p6 ;p6 RTG p4.Definition 3The web page pi is called sink web page, if the following property is fulfilled:There does not exist pj in P, with i ≠ j and pi RTG pj.Using the relation RTG, we can construct for the web site an oriented graph G=(X,U) as below:X={1, 2, ..., n} is the set of nodes. Each web page pi from P, where 1 ≤ i ≤ n, has one and only one node in X, associated to it. The relation between a node in X and its corresponding web page from P is the following: the web page pi has associated the node i.U = { (i, j) | pi RTG pj, i ≠ j, 1 ≤ i, j ≤ n } is the set of edges.For any set A we denote by |A| the number of elements of the set A.Writing d+(i) = |{(i,j) | (i,j) U}| as being the exterior degree of the graph G, we obtain:Proposition 1If i, 1 ≤ i ≤ n is a node in the oriented graph G previously defined, with d+(i) = 0, then pi is a sink web page.The proof is immediate, taking into consideration the definition of the sink web page.
According to previous definitions, we obtain the following pairs of pages which are in relation RTG one with each other:p1 RTG p7;p2 RTG p3; p2 RTG p4 ;p5 RTG p4; p5 RTG p6 ;p6 RTG p4.Definition 3The web page pi is called sink web page, if the following property is fulfilled:There does not exist pj in P, with i ≠ j and pi RTG pj.Using the relation RTG, we can construct for the web site an oriented graph G=(X,U) as below:X={1, 2, ..., n} is the set of nodes. Each web page pi from P, where 1 ≤ i ≤ n, has one and only one node in X, associated to it. The relation between a node in X and its corresponding web page from P is the following: the web page pi has associated the node i.U = { (i, j) | pi RTG pj, i ≠ j, 1 ≤ i, j ≤ n } is the set of edges.For any set A we denote by |A| the number of elements of the set A.Writing d+(i) = |{(i,j) | (i,j) U}| as being the exterior degree of the graph G, we obtain:Proposition 1If i, 1 ≤ i ≤ n is a node in the oriented graph G previously defined, with d+(i) = 0, then pi is a sink web page.The proof is immediate, taking into consideration the definition of the sink web page.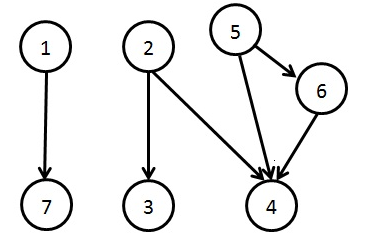 | Figure 1. The oriented graph G for a web site with 7 web pages and the relation RTG given by the edges |
3. Defining the Cost of Verifying a Web Page
- Similarly to previous sections, we will take a fixed set of tags TG. We will consider p being a web page which contains only HTML tags, with the sequence of tags that are not in TG, T, defined in section 2. For p, we will define the verification cost, C(p), as a function which depends on the cost of verifying the tags.Let tg be an HTML tag. For tg, we write Atg as being the set of attributes of tg.Definition 4Let the verification cost of tg be c(tg)=1+|Atg|.Definition 5Let the verification cost of a web page p as a function of TG be:
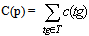 Definition 6Let the verification cost of a web site WA, with the set of web pages P = {p1, p2, ..., pn}, as a function of TG be:
Definition 6Let the verification cost of a web site WA, with the set of web pages P = {p1, p2, ..., pn}, as a function of TG be: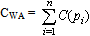 For the example 1 from section 2, we have:C(p1) = 2+1 = 3;C(p2) = 2+1+1+1 = 5;C(p3) = 2+1+1+1+1+3+1 = 10;C(p4) = 2+1+1+1+4+1+1+1+4 = 16;C(p5) = 2;C(p6) = 4+1+1+2 = 8;C(p7) = 4+1+2+1 = 8;Considering those costs, we obtain CWA = 3+5+10+16+2+8+8 = 52.The cost of verifying a web site can be diminished, if we use for verification only the sink web pages.Definition 7Let the cost of implicit verification of the web site WA, with the set of sink web pages S = {s1, s2, ..., sk}, be:
For the example 1 from section 2, we have:C(p1) = 2+1 = 3;C(p2) = 2+1+1+1 = 5;C(p3) = 2+1+1+1+1+3+1 = 10;C(p4) = 2+1+1+1+4+1+1+1+4 = 16;C(p5) = 2;C(p6) = 4+1+1+2 = 8;C(p7) = 4+1+2+1 = 8;Considering those costs, we obtain CWA = 3+5+10+16+2+8+8 = 52.The cost of verifying a web site can be diminished, if we use for verification only the sink web pages.Definition 7Let the cost of implicit verification of the web site WA, with the set of sink web pages S = {s1, s2, ..., sk}, be: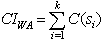 For the above previous, we obtain: CIWA = C(p3) + C(p4) + C(p7) = 10 + 16 + 8 = 34.Definition 8Let the cost of implicit verification of the web site WA, with the subset of sink web pages US, where S={s1, s2, ..., sk} is the set of sink web pages, be:
For the above previous, we obtain: CIWA = C(p3) + C(p4) + C(p7) = 10 + 16 + 8 = 34.Definition 8Let the cost of implicit verification of the web site WA, with the subset of sink web pages US, where S={s1, s2, ..., sk} is the set of sink web pages, be: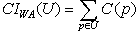 Remarks1.
Remarks1. 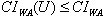 , for any
, for any 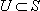 ;2.
;2. 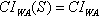 .
.4. Algorithm of Determining the Sink Web Pages for Verifying a Web Site with a Fixed Cost
- We will consider a web site with the set web pages P = {p1, p2, ..., pn}, a set of tags TG and a fixed cost k, which is a natural number. Our target is to determine those web pages that maximize the number of implicitly verified web pages with the total cost of verification less than or equal to k.In order to diminish the total cost of verification, certain web pages will be implicitly verified, through other web pages. A considerable improvement is obtained if we use the sink web pages.For the example in section 2, if we fix k=25, choosing the web pages 4 and 7, there can be verified directly or implicitly the web pages number 1, 2, 4, 5, 6, 7 with a cost equal to 24 ≤ 25.The proposed algorithm has the following input data:- the path of the folder with the web site to be verified- the path of a text file which contains the TG set- the fixed maximum cost kThe algorithm will return the following output data:- the total number of web pages that can be verified within the fixed cost (directly or implicitly)- the cost of verification- the web pages that can be directly or implicitly verified with a cost less or equal than kThe algorithm consists of three parts:- Using the previously defined relation (RTG), the graph G associated to the web site is determined. It is memorized in an array (aij)1≤i,j≤n, with aij=1 if pi RTG pj and aij=0 otherwise.- The array s=(s1, s2, ..., sn) is determined. For each i, 1 ≤ i ≤ n, si=0 if pi is a sink web pages or si=j if pi is not a sink web page and pj is a sink web page which fulfils the condition pi RTG pj.- Using dynamic programming (the knapsack problem), some sink web pages are selected so that their verification cost is less than or equal to k and the number of directly and implicitly verified web pages is maximum.read the input dataread the tags from TG setread the tags from each web page from the web site// cost[i]= verification cost for web page i, i=1,nfor i=1,n docost[i]=0;while (exist tag Tg in web page i) and (not(Tg in TG)) docost[i]=cost[i]+ (1+ number of attributes from tag Tg)read Tg from web page iendwhileendfor//create the graphfor i=1,n dofor j=1,n doa[i][j]=0if i!=j thenif pi is in relation RTG with pj thena[i][j]=1endifendifendforendfor//s=(s[1],...,s[n]) with the meaning from the above descriptionfor i=1,n dos[i]=0endforfor i=1,n dofor j=1,n doif s[j]=0 and a[i][j]=1 thens[i]=jendifendforendforsw=1while sw=1 dosw=0for i=1,n dot=s[i]u=s[t]v=s[u]if t!=0 and u!=0 and v=0 thens[i]=usw=1endifendforendwhile//p[1]-first sink web page, p[2]-second sink web page, ...//nrp[i] the number of web pages verified through pifor i=1,n donrp[i]=1endfornrsink=0for i=1,n doif s[i]=0 thennrsink=nrsink+1p[nrsink]=ielsenrp[s[i]]=nrp[s[i]]+1endifendfor//dynamic programming methodct[0]=0for i=1,k doct[i]=-1endforfor i=1,k dofor j=1,nrsink doif cost[p[j]]<=i thenif ct[i-cost[p[j]]]!=-1 and use[i-cost[p[j]]][j]=0 thenif ct[i]
 We wrote nWS the number of web pages, respectively cWS the provided cost which does not exceed k as output data to Java program.
We wrote nWS the number of web pages, respectively cWS the provided cost which does not exceed k as output data to Java program.5. Conclusions
- The algorithm described in section 3 has provided good results with the tested examples. Next, the authors intend to build a more complex application, which should use the notions and the presented algorithm, and test it on a larger set of web sites. Meanwhile, it is considered that the method of calculating the verification cost for a web page can be improved, by considering the possible values that the tag attributes can have, as well as the method of selecting web pages within the algorithm.
References
| [1] | Cormen T.H., Leiserson C.E., Rivest R.L., Stein C., “Introduction to Algorithms”, second edition, MIT Press, (1990). |
| [2] | Ricca F, Tonella P. “Web Site Analysis: Structure and Evolution”, Proceedings of the International Conference on Software Maintenance; pg. 76-86, (2000). |
| [3] | Andrews A.A., Offutt J., Alexander R.T., “Testing Web applications by modeling with FSMs”, Software and System Modeling; 4(3): pg. 326-345, (2005). |
| [4] | Mao Cheng-ying, Lu Yan-sheng, “A Method for Measuring the Structure Complexity of Web Application”, Wuhan University Journal of Natural Sciences, vol. 11, No. 1, (2006). |
| [5] | Manar H. Alalfi, James R. Cordy, Thomas R. Dean, “Modeling Methods for Web Application Verification and Testing: State of Art”, JohnWiley and Sons, Ltd, (2008). |
| [6] | Catrinel Maria Danauta, Doru Anastasiu Popescu, “Method of Reduction of the Web Pages to Be Verified when Validating a Web Site”, Buletin Stiintific, Universitatea din Pitesti, Seria Matematica si Informatica, Nr. 15, pg 19-24, (2009). |
| [7] | Doru Anastasiu Popescu, Catrinel Maria Danauta, Zoltan Szabo, “A Method of Measuring the Complexity of a Web Application from the Point of View of Cloning”, The 5th International Conference on Virtual Learning, Section Models and Methodologies, October 29 - October 31, Proceedings, pg. 186-181, (2010). |
| [8] | Doru Anastasiu Popescu, Zoltan Szabo, “Sink Web Pages of Web Application”, The 5th International Conference on Virtual Learning, Section Software Solutions, October 29 - October 31, Proceedings, pg. 375-380, (2010). |
| [9] | Doru Anastasiu Popescu, “Reducing the Navigation Graph Associated to a Web Application”, Buletin Stiintifc - Universitatea din Pitesti, Seria Matematica si Informatica, Nr. 16, pg. 125-130 (2010). |
| [10] | G. Sreedhar, A.A. Chari, V.V. Ramana, “Measuring Qualitz of Web Site Navigation”, Journal of Theoretical and Applied Information Technology, Vol. 14, Nr. 2, (2010). |
| [11] | Doru Anastasiu Popescu, “A Relation between Web Pages”, CKS 2011 Challenges of the Knowledge Society "Nicolae Titulescu" University and "Complutense" University, Bucharest, April, 15-16, CKS Proceedings pg. 2026-2033, (2011). |
| [12] | Doru Anastasiu Popescu, Catrinel Maria Danauta, “Similarity Measurement of Web Sites Using Sink Web Pages”, 34th International Conference on Telecommunications and Signal Processing, TSP 2011, August 18-20, 2011, Budapest, Hungary, Indexed By IEEE Xplore, pag.24-26, (2011). |
| [13] | Doru Anastasiu Popescu, Catrinel Maria Danauta “Validation of a Web Application by Using a Limited Number of Web Pages”, BRAIN, Broad Research in Artificial Intelligence and Neuroscience, Volume 3, Issue 1, February, pg. 19-23 (2012). |
| [14] | Doru Anastasiu Popescu, Dragos Nicolae, “Degree of Similarity of Web Applications”, Second International Symposium on Communicability, Computer Graphics and Innovative Design for Interactive Systems (CCGIDIS 2012), July 5 – 6, Valle d'Aosta, Italy, (2012). |
| [15] | Doru Anastasiu Popescu, “Sink Web Pages in Web Application”, IAPR TC3 Workshop on Partially Supervised Learning (PSL2011), September 15-16, 2011, University of Ulm, Germany, Proceedings Lecture Notes in Computer Science 7081 Springer, pg. 154-158 (2012). |