-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Science and Technology
p-ISSN: 2163-2669 e-ISSN: 2163-2677
2018; 8(1): 1-10
doi:10.5923/j.scit.20180801.01

Data Migration
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLSimanta Shekhar Sarmah
Business Intelligence Architect, Alpha Clinical Systems, USA
Correspondence to: Simanta Shekhar Sarmah, Business Intelligence Architect, Alpha Clinical Systems, USA.
| Email: |  |
Copyright © 2018 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

This document gives the overview of all the process involved in Data Migration. Data Migration is a multi-step process that begins with an analysis of the legacy data and culminates in the loading and reconciliation of data into new applications. With the rapid growth of data, organizations are in constant need of data migration. The document focuses on the importance of data migration and various phases of it. Data migration can be a complex process where testing must be conducted to ensure the quality of the data. Testing scenarios on data migration, risk involved with it are also being discussed in this article. Migration can be very expensive if the best practices are not followed and the hidden costs are not identified at the early stage. The paper outlines the hidden costs and also provides strategies for roll back in case of any adversity.
Keywords: Data Migration, Phases, ETL, Testing, Data Migration Risks and Best Practices
Cite this paper: Simanta Shekhar Sarmah, Data Migration, Science and Technology, Vol. 8 No. 1, 2018, pp. 1-10. doi: 10.5923/j.scit.20180801.01.
Article Outline
1. Introduction
- Migration is a process of moving data from one platform/format to another platform/format. It involves migrating data from a legacy system to the new system without impacting active applications and finally redirecting all input/output activity to the new device. In simple words, it is a process of bringing data from various source systems into a single target system. Data migration is a multi-step process that begins with an analysis of legacy data and culminates in the loading and reconciliation of data into the new applications. This process involves scrubbing the legacy data, mapping data from the legacy system to the new system, designing the conversion programs, building and testing the conversion programs conducting the conversion, and reconciling the converted.
2. Need for Data Migration
- In today’s world, migrations of data for business reasons are becoming common. While the replacement for the old legacy system is the common reason, some other factors also play a significant role in deciding to migrate the data into a new environment. Some of them areŸ Databases continue to grow exponentially that requires additional storage capacityŸ Companies are switching to high-end serversŸ To minimize cost and reduce complexity by migrating to consumable and steady systemŸ Data needs to be transportable from physical and virtual environments for concepts such as virtualizationŸ To avail clean and accurate data for consumptionData migration strategy should be designed in an effective way such that it will enable us to ensure that tomorrow’s purchasing decisions fully meet both present and future business and the business returns maximum return on investment.
3. Data Migration Strategy
- A well-defined data migration strategy should address the challenges of identifying source data, interacting with continuously changing targets, meeting data quality requirements, creating appropriate project methodologies, and developing general migration expertise.The key considerations and inputs for defining data migration strategy are given below:Ÿ Strategy to ensure the accuracy and completeness of the migrated data post migrationŸ Agile principles that let the logical group of data to be migrated iterativelyŸ Plans to address the source data quality challenges faced currently as well as data quality expectations of the target systemsŸ Design an integrate migration environment with proper checkpoints, controls and audits in place to allow fallout accounts/errors are identified/reported/resolved and fixedŸ Solution to ensure appropriate reconciliation at different checkpoints ensuring the completeness of migrationŸ Solution to selection of correct tools and technologies to cater for the complex nature of migrationŸ Should be able to handle large volume data during migrationŸ Migration development/testing activities should be separated from legacy and target applicationsIn brief, the Data Migration strategy will involve the following key steps during end-to-end data migration:Ÿ Identify the Legacy/source data to be migratedŸ Identification any specific configuration data required from Legacy applicationsŸ Classify the process of migration whether Manual or AutomatedŸ Profile the legacy data in detailŸ Identify data cleansing areasŸ Map attributes between Legacy and Target systemsŸ Identify and map data to be migrated to the historical data store solution (archive)Ÿ Gather and prepare transformation rulesŸ Conduct Pre Migration Cleansing where applicable.Ÿ Extract the dataŸ Transform the data along with limited cleansing or standardization.Ÿ Load the dataŸ Reconcile the data
4. SDLC Phases for Data Migration
- The Migration process steps will be achieved through the following SDLC phases.
4.1. Requirement Phase
- Requirement phase is the beginning phase of a migration project; requirement phase states that the number and a summarized description of systems from where data will be migrated, what kind of data available in those systems, the overall quality of data, to which system the data should be migrated. Business requirements for the data help determine what data to migrate. These requirements can be derived from agreements, objectives, and scope of the migration. It contains the in scope of the project along with stakeholders. Proper analysis gives a better understanding of scope to begin, and will not be completed until tested against clearly identified project constraints. During this Phase, listed below activities is performed:Ÿ Legacy system understanding to baseline the migration scopeŸ Migration Acceptance Criteria and sign-offŸ Legacy data extraction format discussion and finalizationŸ Understanding target data structureŸ Legacy data analysis & Profiling to find the data gaps and anomaliesŸ Firming up Migration Deliverables and Ownership
4.2. Design Phase
- During design phase i.e. after Analysis phase, High-level Approach and Low-level design for Migration components are created. Following are the contents of the design phase. Ÿ Approach for end to end MigrationŸ Master and transactional data handling approachŸ Approach for historical data handlingŸ Approach for data cleansingŸ Data Reconciliation and Error handling approachŸ Target Load and validation approachŸ Cut-over approachŸ Software and Hardware requirements for E2E MigrationŸ Data model changes between Legacy and target. For example – Change in Account structure, Change in Package and Component structureŸ Data type changes between Legacy and targetŸ Missing/Unavailable values for target mandatory columnsŸ Business Process specific changes or implementing some Business RulesŸ Changes in List of Values between Legacy and targetŸ Target attribute that needs to be derived from more than one columns of LegacyŸ Target Specific unique identifier requirementThe detailed design phase comprises of the following key activities:Ÿ Data Profiling - It is a process where data is examined from the available source and collection of statistics and other important information about data. Data profiling improves quality of data, increase the understanding of data and its accessibility to the users and also reduce the length of implementation cycle of projects. Source to Target attribute mappingŸ Staging area designŸ Technical designŸ Audit, Rejection and Error handling
4.3. Development Phase
- After completing the Design phase, Migration team works on building Migration components as listed below:Ÿ ETL mappings for Cleansing and TransformationŸ Building Fallout FrameworkŸ Building Reconciliation ScriptsŸ All these components are Unit Tested before Dry Runs.Actual coding and unit testing will be done in the construction phase. During the development phase, the structures which are similar to target system should be created. Data from different legacy systems will be extracted from a staging area & source data will be consolidated in the staging area. The Construction and Unit Testing (CUT) phase include the development of mappings in ETL tool depend on Source to Target Mapping sheet. Transformation Rules will be applied to required mappings and loaded the data into target structures. Reconciliation programs will also be developed during this phase. Unit test cases (UTC) to be written for validating source systems, source definitions, target definitions and to check the connection strings, validation of data types and ports, etc.
4.4. Testing Phase
- The objectives of the data migration testing areŸ All required data elements have been fetched/moved.Ÿ Data has been fetched/moved for specified time periods as per the requirement specification document.Ÿ Data has originated from the correct source tables.Ÿ Verify if the target tables are populated with accurate data.Ÿ Performance of migration programs and custom scripts.Ÿ There has been no data loss during data migration, and even if there is any loss, they are explained properly.Ÿ Data integrity is maintained.The Migrated data will be tested by reconciliation process. The reconciliation scripts will be developed to check the count between the source system and staging area where the data extracted from the source, to check the count between source staging area, target staging area, and rejection tables. For example: Count of source records = Count of target records + count of rejected records in rejection table.All functional check validations will be verified depends on the business rules through functional scripts. The various ways to do the reconciliation and functional checks, it can be a manual process or automated process. Automation Process includes creating one procedure to check reconciliation which returns the records in the error table if any of the scripts fail and creating one procedure to check the functionality which returns the records in the error table if any of the functionality fails or creating macro to execute the reconciliation and functional scripts in one shot.
4.5. Delivery
- The migrated data will be moved to QA environment to check the quality of data. During this phase, the cutover activities will be performed, and migrations from the legacy systems into Target Systems will be carried out. After the data is loaded, reconciliation of the loaded records will be verified. Reconciliation identifies the count of records which are successfully converted. It identifies those records that failed during the process of conversion and migration. Failed records are analysed to identify the root cause of the failures and they are fixed in order to load them into the target database. The cutover phase includes conversion and testing of data, changeover to the new system, and also user training. This phase is the final phase of the volume move.In the cutover phase, synchronization of source volume data and the destination volume data takes place. From the project perspective, the final preparation for cutover phase includes:Ÿ Critical issue resolution (and document it in the upgrade script).Ÿ Creation of the cutover plan, based on the results and experiences of the tests.Ÿ Based on the cutover plan, an optional dress rehearsal test can be performed.Cutover phase requires intense coordination and effort among various teams such as database administrator, system administrator, application owners and project management team. All these team must coordinate the effort closely on every step of the process. Acknowledgement of accomplishment of each step must be communicated to the all the teams so that all are on the same page during the phase.
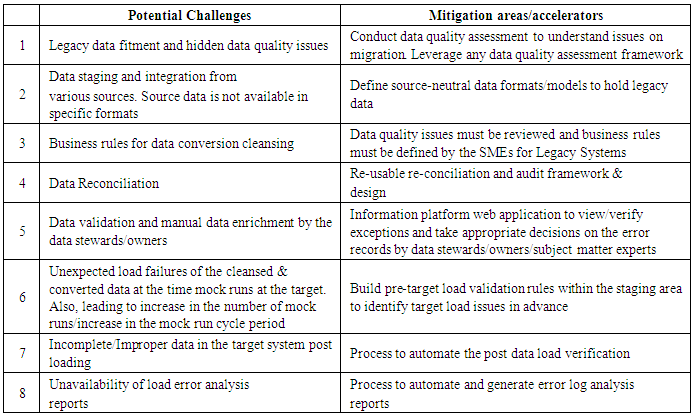
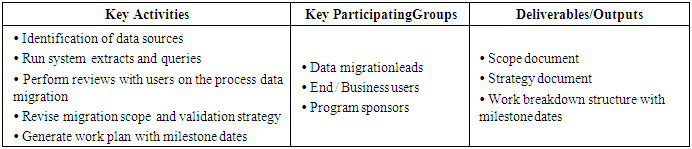
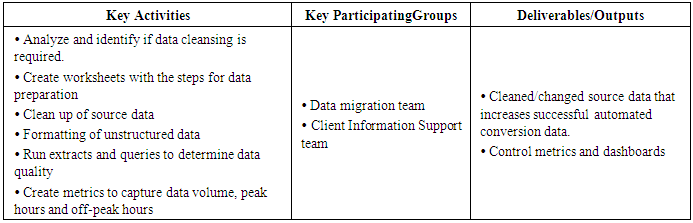
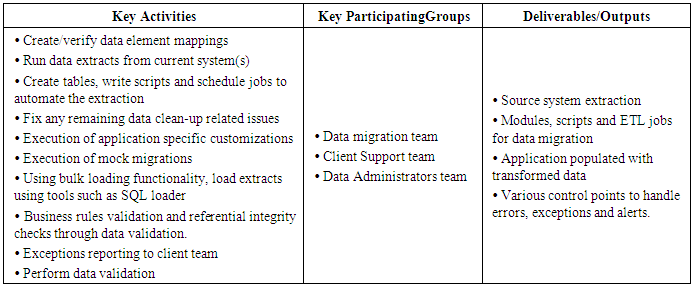
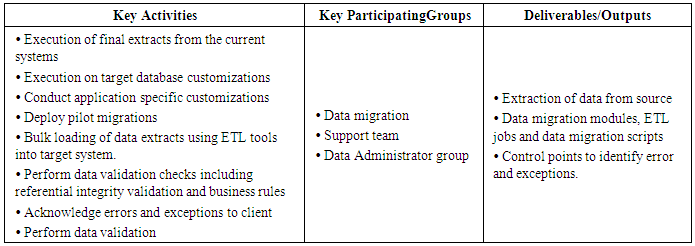
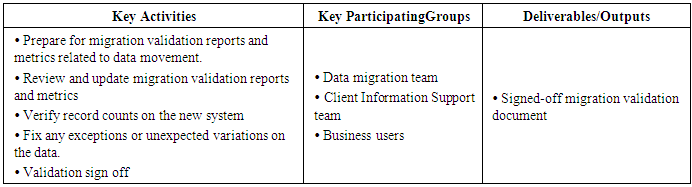
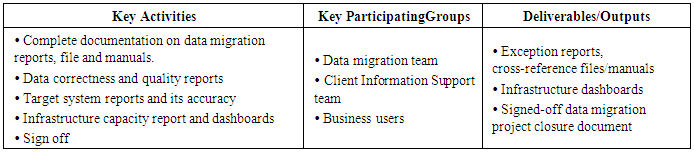
5. Phases of Data Migration
- Following tables describes the different phases of the data migration along with the participating groups and also the deliverables and output associated with each of the phases.
|
|
|
|
|
|
6. Approach for Test Runs
- Following are some of the best practices followed as test approach for mock runs/test runs to test the data migration activities before the crucial conversion to the production environment. Before entering the mock conversion phase following criteria’s must be metŸ Tested the developed data conversion, cleansing and data validation programsŸ Data Cleansed & transformed the legacy data for mock runsŸ Developed & tested target system’s load scripts/componentsŸ Target system technical experts, subject matter experts’ availability for Mock runs data loads into the target system & verification/validationŸ Availability of the target system environment – similar to target production systemEach mock run data load will be followed by validation and sign off by respective stakeholders for confirmation of validation and acceptance.
6.1. Mock Run 1/ Test Run 1
- Ÿ Cleansed & converted representative legacy sample data (~40%) for mock runŸ Execution, reconciliation and load errors reportsŸ Conversion findings report & validation report for mock run 1Ÿ Data & business SMEs verification & certification
6.2. Mock Run 2 / Test Run 2
- Ÿ Fixes to the code / revise conversion approach from mock run1 observationsŸ Cleansed &converted representative legacy sample data loading (~80%) for mock runŸ Execution, conversion reconciliation and load error reportsŸ Conversion findings report & validation report for mock run 2Ÿ SIT will be conducted as part of this test run. Data & business SMEs verification & certification
6.3. Mock Run 3 / Test Run 3
- Ÿ Fixes to the code / revise conversion approach from mock run two observationsŸ Cleansed & converted complete legacy data loading for mock run 3 (similar to production run)Ÿ Execution, conversion reconciliation and load error reportsŸ Conversion findings report & validation report for mock run 3Ÿ UAT will be conducted as part this test run, data & business SMEs verification & certification Following methods shall be utilized for validation of mock runsŸ Visual check of data in the target system based on samples (comparison of legacy data and data loaded in target systemŸ Testing of end to end processes with migrated data & system responseŸ Run target system specific standard reports/Queries for some of the transactional dataŸ Verification of load reconciliation reports and error reports
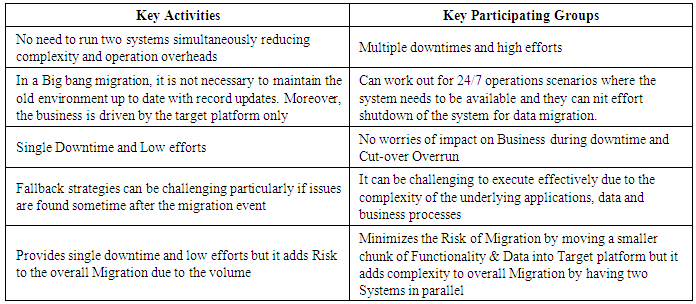
7. Migration Approach
- Data Migration which is a subset of overall Migration can be achieved either using either Big-Bang approach or Phased Approach. Comparison of Big-Bang vs. Phased Migration is listed below:
|
8. Common Scenarios of Testing
- Below are the common scenarios which we can test during Data migration activities.
8.1. Record Count Check
- Data in the staging will be populated from different source systems in general scenarios. One of the important scenarios to be tested after populating data in the staging is Record count check. Record count checks is divided into two sub-scenarios namelyŸ Record count for Inserted Records: The number of records identified from source system using requirement document should completely match with the target system. i.e., Data populated after running the jobs.Ÿ Record count for updated records: The number of records which are updated in the target tables in the staging using data from source tables must match the record count identified from the source tables using requirement document.For example, SELCT count(*) from table would give us the number of number of records at the target which is a quick and effective way to validate the record count.
8.2. Target Tables and Columns
- If the jobs have to populate the data in a new table, check that required target table exists in the staging. Check that required columns are available in the target table according to the specification document.
8.3. Data Check
- Data checking can be further classified as follows.Ÿ Data validation for updated records: With the help of requirement specification document, we can identify the records from the source tables where data from these records will be updated in the target table in the staging. Now take one or more updated records from the target table, compare the data available in these records with the records identified from source tables. Check that, for updated records in the target table; transformation has happened according to the requirement specification using source table data.Ÿ Data validation for inserted records: With the help of requirement specification document, we can identify the records from the source tables, which will be inserted in the target table available in the staging. Now take one or more inserted records from the target table, compare the data available in these records with the records identified from source tables. Check that, for populating data in the target table transformation is happened according to the specification using source table data.Ÿ Duplicate records check: If the specification document specifies that target table should not contain duplicate data, check that after running the required jobs, target table should not contain any duplicate records. To test this, you may need to prepare SQL query using specification document.For instance, following simple piece of SQL can identify the duplicates in a tableSELECT column1, COUNT (column2) FROM tableGROUP BY column2HAVING COUNT (column2) > 1Ÿ Checking the Data for specific columns: If the specification specifies that particular column in the target table should have only specific values or if the column is a date field, then it should have the data for specific data ranges. Check that data available for those columns meeting the requirement.Ÿ Checking for Distinct values: Check for distinct values available in the target table for any columns, if the specification document says that a column in the target table should have distinct columns. You can use a SQL query like “SELECT DISTINCT