-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Library Science
2012; 1(2): 23-27
doi: 10.5923/j.library.20120102.02
Library Automation the Ingredients for Systems Hardware and Software Interoperability
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLAlex Ozoemelem Obuh1, Aruerhe Ogheneme2
1Department of Library & Information Science, Delta State University, Abraka, Delta State, Nigeria
2University Library, Western Delta University, Oghara, Delta State, Nigeria
Correspondence to: Alex Ozoemelem Obuh, Department of Library & Information Science, Delta State University, Abraka, Delta State, Nigeria.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
The paper provides an overview of some elements that are necessary for ensuring hardware and software interoperability in library and information systems. It specifically proffers meaning to the term system interoperability and identified the need for interoperability alongside some globally accepted standards and mechanisms that will guarantee system interoperability. Based on this, the paper examined library automation standards such as DCMES, MARC-21, OAI-PMH and Z39.50 standards. Bottlenecks in ensuring operability through standardization were highlighted, the way forward in achieving interoperability among libraries in a library system were also itemized and recommendations were put forward.
Keywords: Library Automation, System Interoperability, MARC, OAI-PMH, Z39.50, DCMES
Article Outline
1. Introduction
- Managing information has become challenging for many organizations. The more information and people, the harder and more complex is the control of information management processes and initiatives. It is true that, effective management of knowledge is now playing a key role in wealth creation. Strong economies of the 21st century are giving no more emphasis on industrial production but rather becoming powerhouses of knowledge, which has resulted in “information explosion”[11]. The exponential growth of literature and ever increasing cost of published materials have put great financial constraint that has resulted in shrinking collections in the library and information centres. That notwithstanding, user demands are increasing and librarians are at their wits end to satisfy the needs of users[14]. According to[10], the only viable solution to meet users’ demands is to make optimum use of available literature. This is being done through automation which ensures pooling and sharing of resources. Sharing of resources is also not an easy task; the technological changes and development of new systems create compatibility issues in different hardware and software platforms.Interoperability is a property referring to the ability of diverse systems and organizations to work together. Interoperability includes the exchange of data, records, and messages between computer systems across different hardware, operating systems, and networks.Interoperability is sought to be achieved by establishing standards that different vendors of software and hardware can adopt so that they can share data and information. In case of software the term interoperability is used to describe the capability of different programs to exchange data via a common set of exchange formats, to read and write the same file formats, and to use the same protocols[4].The lack of interoperability can be a consequence of a lack of attention to standardization during the design of a program. During the last couple of decades, communications world has witnessed several new developments, two of which are the Open Access (OA) and Open Archives Initiatives (OAI) whose main objectives are to improve transfer and exchange of research output. The OA model allows for the widest dissemination of research output, and maximum visibility, while, at the same time, reducing barriers common to traditional diffusion methods of scientific literature. The OAI develops and promotes interoperability solutions that aim to facilitate the efficient dissemination of content. The initiative is built on the principle that interoperability will federate the distributed open archives, thus encouraging the development of value-added services such as portals, subject gateways, and specialized search engines, with the overall benefit of increasing visibility[12]. The ultimate objective is to overcome existing barriers to interoperability by using OA for all digital materials.
2. Standards and Mechanisms for Achieving Interoperability
- Some internationally adopted standards and mechanisms for achieving system interoperability in library and information systems include:
2.1. Dublin Core Metadata Element Set (DCMES)
- Dublin Core is the result of an international cross-disciplinary consensus achieved through the ongoing efforts of the Dublin Core Metadata Initiative (DCMI), aimed at providing a foundation for standardized bibliographic description of information resources available via the Internet. In 2007, the Dublin Core Metadata Element Set (DCMES) was published by the International Organization for Standardization. The DCMES is a set of 15 interoperable metadata elements designed to facilitate the description and recovery of document-like resources in a networked environment. The descriptive elements are[3]: ·Title (name given to the resource) ·Creator (entity primarily responsible for making the content of the resource) ·Subject (topic of the content of the resource, typically expressed as keywords, key phrases, or classification codes) ·Description (abstract, table of contents, free-text account of the content, etc.) ·Publisher (entity responsible for making the resource available) ·Contributor (entity responsible for making contributions to the content of the resource) ·Date (typically associated with the creation or availability of the resource) ·Type (nature or genre of the content of the resource) ·Format (physical or digital manifestation of the resource) ·Identifier (an unambiguous reference to the resource within a given context, such as the URL, ISBN, ISSN, etc.) ·Source (reference to a resource from which the present resource is derived) ·Language (the language of the intellectual content of the resource) ·Relation (reference to a related resource) ·Coverage (extent or scope of the content of the resource) ·Rights (information about rights held in and over the resource)
2.2. Machine-Readable Cataloguing
- Machine-Readable Cataloguing (MARC) is an international standard digital format for the description of bibliographic items, developed at the Library of Congress to facilitate the creation and dissemination of computerized cataloguing from one library to another and between countries. The MARC record is divided into fields, each containing one or more related elements of bibliographic description. A field is identified by a three-digit tag designating the nature of its content. Tags are organized as follows in hundreds, indicating a group of tags, with XX in the range of 00-99[7]0XX fields - Control information, numbers, codes 1XX fields - Main entry 2XX fields - Titles, edition, imprint 3XX fields - Physical description, etc. 4XX fields - Series statements (as shown in item) 5XX fields - Notes 6XX fields - Subject added entries 7XX fields - Added entries other than subject or series 8XX fields - Series added entries (other authoritative forms)Widespread use of the MARC standard has helped libraries acquire predictable and reliable cataloguing data, make use of commercially available library automation systems, share bibliographic resources, avoid duplication of effort, and ensure that bibliographic data will be compatible when one automation system is replaced by another.
2.3. Open Archives Initiatives–for Metadata Harvesting (OAI-PMH)
- The Open Archives Initiatives–for Metadata Harvesting (OAI-PMH) is one of the mechanisms used to achieve the interoperability between digital repositories. It provides a system to facilitate the harvesting, sharing and discovery of distributed resources. This allows materials within repositories to be accessed by a greater number of users via external services[13]. Usually, a search tool would ideally allow the user to search or navigate across all material, providing the most useful matches first. The ability to search across all of the harvested content and retrieve data from sources into a central, aggregated service is facilitated through the OAI-PMH. It enables ease of use and accessibility across board over a disparate set of repositories[1]. The OAI-PMH is based on the Hypertext Transport Protocol (HTTP) and Extensible Markup Language (XML) open standards. XML is designed for data exchange and unlike HTML which is designed for a specific application to convey information to humans through a web browser, XML has no specific application; it is designed for whatever use that need it for. And XML document can be created and information retrieved from the document by any XML parser. HTML and XML are so popular, for information display and exchange, because they are standards. Anyone following these standards is sure of developing solutions that will be able to interoperate. XML is platform and language independent, in fact, when it is necessary to communicate between the different systems, XML is a potential fit for the exchange format[5].
2.4. Z39.50
- Z39.50 is the American National Standard Information Retrieval Application Service Definition and Protocol Specification for Open Systems Interconnection. The National Information Standards Organization (NISO), an American National Standards Institute (ANSI) accredited standards developer that serves the library, information, and publishing communities, approved the original standard in 1988. After which several revised versions of the standard have been published by NISO[6]. Z39.50 defines a standard way for two computers to communicate for the purpose of information retrieval, and makes it easier to use large information databases by standardizing the procedures and features for searching and retrieving information. Specifically, Z39.50 supports information retrieval in a distributed, client and server environment where a computer operating as a client submits a search request to another computer acting as an information server. Software on the server performs a search on one or more databases and creates a result set of records that meet the criteria of the search request. The server returns records from the result set to the client for processing. The power of Z39.50 is that it separates the user interface on the client side from the information servers, search engines, and databases[6]. Z39.50 provides a consistent view of information from a wide variety of sources, and can be implemented on any platform, thus enabling easy communication among different computer systems with different operating systems, hardware, search engines, database management systems. A Z39.50 implementation enables one interface to access multiple systems providing end users with virtually transparent access to other systems[8]. Users access multiple systems with the familiar commands and displays of their own local systems. New commands and search techniques do not have to be learned. The results of the search are presented on the local system in the formats and styles users are accustomed to. Search and retrieval process involving two automated libraries in a library system operating Z39.50 protocol could be explained using a Z39.50 Information Retrieval Model as shown in fig. 1[9]. The following stages describe communication process above[9] involving two library/information systems running on Z39.50 platform;i The Client handles the user interface ii The Origin takes information from the client and sends it to the target across a network iii The Target receives the information from the origin and communicates the search to the database serveriv The Server handles the database search and returns retrieved information to the target v The Target sends information to the origin across a network vi The Client receives information from the origin and displays results for the user.
3. Problems Hampering Standardization of Library Automation
- As earlier stated, to achieve systems interoperability there is need for a standardized library automation system. The following can hamper standardization of library automation system ·Quackery·Lack of funds to provide for standard library automation software and hardware·Poor knowledge of library automation process·Poor knowledge of library automation standards e.g. MARC, Z39.50 etc. ·Ignorance of the need for system standardization during automating process·Lack of expert cataloguers knowledgeable in standardized machine readable cataloguing·Poor network infrastructure·Epileptic power supply·High cost of standard library automation hardware and software·High cost of Internet connectivity
4. The Way Forward in Ensuring Interoperability
- Automated libraries involve networks of all kinds and use different hardware and software platforms. To enable interconnectivity to such a diversity of systems and to enable mutual sharing of resources and exchange of data between them requires that all of them follow internationally agreed upon standards.
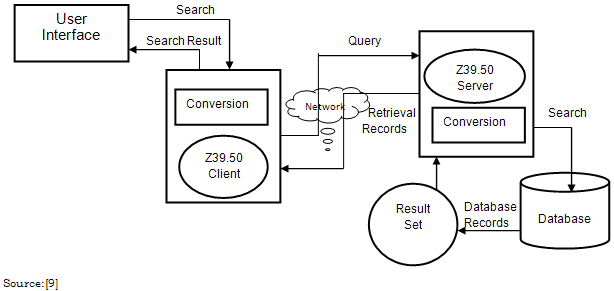 | Figure 1. Z39.50 Information Search and Retrieval Model |
- ·Networks operate at different levels in respect of:·the variety of resources they handle,·the computer hardware they use,·operating system platforms,·the language used to describe subject content,·the support to protocols and standards they provide, and·the back-end software in use.One element in all library automation and networking today that has assumed highest priority is the use of (wherever possible) international standards (especially Z39.50, XML, OAI-PMH, MARC or DCMES) for the following.·Metadata standards which includes standards for data elements as well as identification, description and representation standards·Information exchange standards ·Communication standards ·Content representation standards·Interoperability standardsThe above categorization is only used for convenience and it must be emphasized that there is considerable overlap in the purpose and function of these standards. It is important that these should be understood and used in library systems if there is to be effective automation and networking.
5. Conclusions
- The technological changes and development of numerous library networks using contrasting hardware and software platforms require library software interoperability. One major goal for automating libraries is to encourage resource sharing. In a bid to achieve this and many more there is the need for library automating to adhere to specifications and standards that will allow for system interoperability with other libraries and information systems. Besides, if we develop our library systems taking into account interoperability and compatibility, we will be moving towards the direction of integrating all libraries and information systems of the world to a single global library system which will in turn facilitate the effort towards the achievement of a universal bibliographic control.
6. Recommendations
- The software requirement at various levels of operations in an automated library should incorporate the following special features:·The software package should be an integrated one, to support library automation and database construction and information retrieval.·It should support international data standards such as MARC-21 and DCMES.·It should work in multi-user and network environment.·It should support copy cataloguing authoritative MARC-21 cataloguing sources via the web.·It should provide high-level language interface to the database for the user to write any special routines to manipulate the database.·It should facilitate federated searching to different databases using an interoperability standard such as Z39.50.·The software should allow the building of an OAI-PMH compliant institutional repository of self-archived materials.·It should allow harvesting metadata from other OAIPMH compliant repository.One of the major problems faced while developing systems for library automation, is the issue of interoperability thus, standardization is an important considerations for library system designers[2]. Interoperability of library systems can be achieved by a number of means, such as through adopting:·Common user interfaces.·Uniform naming and identification systems.·Standard formats for information resources.·Standard metadata formats.·Standard network protocols.·Standard information retrieval protocols.·Standard measures for authentication and security, and so on.