-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Networks and Communications
p-ISSN: 2168-4936 e-ISSN: 2168-4944
2017; 7(1): 24-31
doi:10.5923/j.ijnc.20170701.03

Big Data Analytics for Network Intrusion Detection: A Survey
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLLidong Wang , Randy Jones
Institute for Systems Engineering Research, Mississippi State University, Vicksburg, USA
Correspondence to: Lidong Wang , Institute for Systems Engineering Research, Mississippi State University, Vicksburg, USA.
| Email: |  |
Copyright © 2017 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Analysing network flows, logs, and system events has been used for intrusion detection. Network flows, logs, and system events, etc. generate big data. Big Data analytics can correlate multiple information sources into a coherent view, identify anomalies and suspicious activities, and finally achieve effective and efficient intrusion detection. This paper presents methods and subsequent evaluation criteria for network intrusion detection, stream data characteristics and stream processing systems, feature extraction and data reduction, conventional data mining and machine learning, deep learning, and Big Data analytics in network intrusion detection. Current challenges of these methods in intrusion detection are also introduced.
Keywords: Big Data, Big Data Analytics, Heterogeneous Data, Network Security, Intrusion Detection, Deep Learning, Machine Learning, Data Mining
Cite this paper: Lidong Wang , Randy Jones , Big Data Analytics for Network Intrusion Detection: A Survey, International Journal of Networks and Communications, Vol. 7 No. 1, 2017, pp. 24-31. doi: 10.5923/j.ijnc.20170701.03.
Article Outline
1. Introduction
- The concepts of network and information security related to a large-scale cyber-attack in the US have continued to dominate headlines and surpasses any probability of a land-based terror attack in the US. The FBI Director testified in an interview before the Senate Homeland Security Committee in 2013 that cyber-attacks had surpassed land-based terror attack threats in the US and have become a major threat which has continued to rise [1]. In the area of cyber security, effective and efficient situational awareness often requires knowledge of current and historical cyber (i.e. host or network) activities to detect and respond to threatening behaviours [2]. The analysis of cyber threats could be improved by correlating security events from numerous heterogeneous sources [3]. Organizations must implement intrusion detection and prevention systems (IDPS) to protect their critical information against various kinds of attacks because anti-virus software and firewalls are not enough to provide full protection for their systems [4].Intrusion detection systems (IDSs) can be categorized into three types: a network-based intrusion detection system (NIDS), a host-based intrusion detection system (HIDS), and a hybrid-based intrusion detection system (hybrid IDS). An HIDS detects malicious activities on a single computer while an NIDS identifies intrusions by monitoring multiple hosts and examining network traffic. In an NIDS, sensors are located at choke points of the network to perform monitoring, often in the demilitarized zone (DMZ) or on network borders and capture all the network traffic. Hybrid-based IDSs detect intrusions by analysing application logs, system calls, file-system modifications (password files, binaries, access control lists, and capability databases, etc.) and other host states and activities [5]. IDSs are often used with other technologies (e.g., routers and firewalls). IDS technologies such as HIDS, NIDS, network behaviour anomaly detection (NBAD), and wireless local area network (WLAN) IDS are used together to correlate data from each device and make decisions according to what these IDSs monitor [6].An intrusion prevention system (IPS) is an advance combination of anti-virus software, personal firewalls, and IDS, etc. The objective of an IPS is not only to detect attacks, but also to stop them by responding automatically such as disabling connections, logging users offline, ending processes, and shutting the system down, etc. Intrusion prevention systems can be classified into two categories: network-based intrusion prevention systems and host-based intrusion prevention systems [4]. The purpose of this paper is to investigate the state-of-the-art of the methods and techniques in network intrusion detection, and the advances and challenges of Big Data analytics in intrusion detection to explore new techniques that aid in intrusion detection analysis.
2. Methods in Network Intrusion Detection and Evaluation Criteria
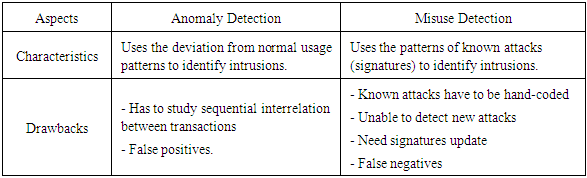
- There are three kinds of intrusion detection methods including signature-based detection (also called misuse detection), anomaly-based detection, and hybrid intrusion detection. The commonly used and accurate of these is signature-based intrusion detection. After a new attack is launched, the attack pattern or signature is defined which can be targeted resources during an attack, the way that the resources are targeted in, or a name (in characters) within the body of the attack code. Network security specialists can design a defence against a new assault after the attack signature is studied. Per the proposed defence, the IDS is updated accordingly to detect the new attack pattern and response to it. This method is very effective in detecting known attacks and produces a small number of false positive (FP) alarms which classify normal traffic as malicious. However, if the attack pattern is slightly altered, this method will not be able to identify the changed versions of the attack [7]. An anomaly detection system has a profile of normal behaviour patterns about the defence system. A coming data pattern is classified as an attack when it is different from the normal pattern. The anomaly detection method can use unsupervised learning techniques to detect new emerging attacks without the need for labelled patterns; however, it has the possibility to generate false alarms [8]. Anomaly detection techniques demonstrate good accuracy in detecting network-level attacks such as the SYN flood, teardrop, and denial of service (DOS), etc.; but not in recognizing application level exploits such as Remote to Local (R2L) and User-to-Root (U2R). All of anomaly detection schemes consider only the packet header fields such as flags, port numbers, and IP addresses, etc.; therefore, they work well if an attack involves only the related fields at the network level. Unfortunately, they have no way to detect attacks if the payload is involved, for example, an attack on Microsoft IIS induces users to download a malicious script file, but because there are no invalid packet header fields involved, header-based techniques will not trigger any alarm. Malicious payload is a type of application level attack; if the payload is ignored in anomaly-based detection, poor performance in detecting payload associated attacks is obvious [9]. The hybrid intrusion detection method has been developed to improve the performance and capabilities of intrusion detection and prevention systems (IDPS) by combining the signature-based method (misuse detection) and the anomaly-based method [10].Some evaluation criteria that can be used to compare the performance of algorithms in an IDS include [11]: 1) accuracy, 2) false negative rate (FNR), 3) false positive rate (FPR), 4) time used, 5) memory consumption, and 6) Kappa Statistic. Among the six evaluation criteria, three practical criteria are often used for the IDS [12]:Ÿ Accuracy: measuring the percentage of failure and correct detection as well as the number of false alarms generated from the IDS.Ÿ FNR: the percentage of the samples that are reported as normal when they are actually anomalous. In the false negative situation, the IDS does not detect real attacks.Ÿ FPR: the proportion of normal instances that are incorrectly classified as anomalous.Table 1 shows a comparison of characteristics and drawbacks between the anomaly method and the misuse method for intrusion detection [10]. Table 2 compares three detection methods based on different performance criteria [13].
|
|

3. Stream Data on the Communication Network
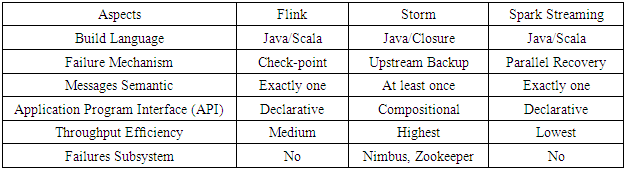
- Stream data and its processing have the following characteristics: it is dynamic and constantly changing, has large volume, allows only one or a small number of scans, flows in and out in a fixed order, and requires quick responses. Web click streams and network traffic are typical examples of stream data. Effective analysis and management of stream data is a huge challenge since stream data is generally not stored in any type of data repository. The continuous query model is a typical query model in a stream data management system where predefined queries evaluate incoming streams constantly, collect aggregate data, respond to the changes of data streams, and report their status. Stream data mining involves dynamic changes and efficient discovery of general patterns within the stream data. People are interested in identifying intrusions based on the anomaly of message flow that can be discovered by dynamically constructing stream models and clustering stream data, or comparing the current frequent patterns with those at specific previous times. Most stream data resides at a low level of abstraction, but analysts are usually more interested in higher as well as multiple levels of abstraction. Therefore, multidimensional and multi-level on-line analysis and mining should be conducted on stream data as well [14].The main problems associated with stream data mining are: concept evolution, concept drift, and infinite length. Concept evolution is defined as the development of novel classes, while concept drift means data changes with time. Infinite length means that stream data requires infinite length storage and training time [15]. Concept drift in the learning model is introduced because of the velocity component of big stream data; specifically, concept drift indicates that statistical properties of the target variable predicted by a model change with time in unforeseen manner. This is a major problem since the prediction will be less accurate with time [12]. Real-time intrusion detection is a tedious task because of the large volume of data involved. Data imbalance is also a major hurdle. If the imbalance level in the data is high, classifiers will be lower in accuracy and reliability. Imbalance is an inevitable problem in real-time data due to the large size and low frequency of certain transactions. Sampling techniques are common approaches to reducing the impact of imbalance on classifiers [16].Malicious attacks and intrusions are dynamic and are needed to perform intrusion detection in a real-time environment with data streams. An event may be normal on its own, but it is malicious if it is considered as part of a sequence of events. Stream data analysis is used to help identify intrusions in this kind of situations. It can be very useful in identifying sequences of events that frequently occur together, discovering sequential patterns, and recognizing outliers or anomalies [10]. There are three main types of anomalies [17]: 1) point anomalies—data samples that are detected as anomalies with respect to the rest of a dataset; 2) collective anomalies—collections of data samples that are anomalous altogether; and 3) contextual (conditional) anomalies—being anomalous only in certain contexts. A live network situational awareness system was developed based on streaming algorithms for determining important stream features and identifying anomalous behaviour. In addition, the performance of this system was improved through refining and enhancing a well-known streaming algorithm. This system was used in a live high-speed mid-scale enterprise network and the performance and detection results of the system was presented [2].Massive on-line analysis (MOA) is a framework for stream data mining including tools for collecting and evaluating machine learning algorithms. It can implement clustering, classification, regression, frequent graph mining, and frequent pattern mining. It contains online and offline collections for clustering and classification as well as evaluation tools. MOA is currently one of the best tools for stream data mining [15]. Stream data may be collected from various sources and processed in a stream processing engine so that the results are written to a destination system. Flink, Storm, and Spark Streaming are three main open source platforms for distributed stream-processing. Flink and Storm are up to 15 times higher in throughput efficiency than Spark Streaming, a micro-batch processing system. Storm is better in throughput efficiency than the others, but Spark Streaming is robust in node failures and provides a recovery without losses [18]. Storm is one of the main distributed stream processing engines. It has had a lot of applications such as continuous computation, real time analytics, distributed remote procedure calls (RPC), online machine learning, and the ETL (extract, transform, and load) process. Storm is fault-tolerant and scalable, and guarantees that data will be processed [19]. Table 3 [20] compares the three stream processing systems.
|
4. Data Mining and Machine Learning Applications in Network Intrusion Detection
4.1. Big Data, Feature Extraction, and Data Reduction for Network Intrusion Detection
- Feature selection is important in machine learning and data mining. Removing redundant or irrelevant features and performing principal component analysis (PCA) result in data dimension reduction. Feature selection can improve the prediction performance of models through reducing the data dimension and speeding up the learning process. Feature selection has many applications that are involved with high dimensional data. Most studies have been conducted in an off-line learning approach that the features of training samples were given a priori. However, such an assumption is not suitable in some real-world applications where training instances may arrive in an online manner or it is costly to collect all the data. Online feature selection (OFS) was studied. The purpose of online feature selection is to develop online classifiers that only use a small and fixed number of features [23]; therefore, making online feature selection for mining big data an important research topic. Big data is defined as “datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyse.” The volume of big data in many sectors ranges from a few dozen terabytes (TB: approximately 1012 bytes) to multiple petabytes (PB: approximately 1015 bytes) [24]. Big data can be too large in volume, moves too fast, or may not fit the strictures of conventional database architectures [25]. Technologies for big data include machine learning, data mining, crowd sourcing, natural language processing, stream processing, time series analysis, cluster computing, cloud computing, parallel computing, visualization, and graphics processing unit (GPU) computing etc. [26, 27]. Distributed file systems, cluster file systems, and parallel file systems are the main tools used in big data [24].Unfortunately, redundant attributes and records make intrusion detection in Big Data analytics an especially complicated and challenging task [28]. PCA has been used in extracting features from the attributes of high dimension datasets, especially datasets with redundant attributes. Experts have used this method in feature selection for IDSs [29]. Unsupervised anomaly detection in unstructured system logs was studied using PCA and its effects, which were also presented in the study. Dimension reduction is highly important for both performance and efficiency and helps reduce computational complexity in anomaly identification and improves the performance of the classifiers [17].
4.2. Conventional Data Mining and Machine Learning in Network Intrusion Detection
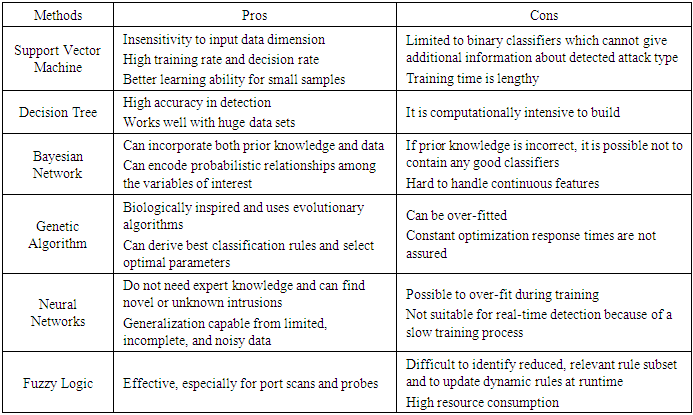
- Data mining methods such as clustering, classification, and association rule mining are often used to obtain valuable information of network intrusion through analysing the network data. Clustering can be used in both misuse detection and anomaly detection while classification is mainly used in anomaly detection and is a supervised learning method. An IDS based on classification can classify all the network traffic into either malicious or normal. Association rule mining searches for frequently occurring items from a large dataset and identify correlation relationships or association rules between data items of the large dataset [30]. Specifically, there is difference between the applications of classification and clustering in IDSs [31]: 1) Clustering: An advantage of clustering over the classification method is that it does not need to use labelled data set. Clustering is useful in intrusion detection because malicious activity should cluster together, separating itself from normal activity. 2) Classification: A classification-based IDS tries to classify all the traffic into either malicious or normal. The challenge is how to minimize the number of false negatives and false positives. Five general techniques have been used to perform classification for intrusion detection including support vector machine (SVM), fuzzy logic, inductive rule generation, neural networks, and genetic algorithms.Some data mining algorithms are good for attack or intrusion detection. For example, the decision tree (DT) is thought one of the most effective and efficient techniques of detecting attacks in anomaly detection. Other data mining techniques such as support vector machines (SVM), Naive Bayes, Random Forest, and neural networks have been used in analysing the traffic of network systems. Attack signatures are needed in misuse detection which uses techniques such as SVM, neural networks, and DT. A hybrid classifier, on the other hand, is a mix method based on algorithms such as neural networks, k-nearest neighbours (k-NN), DT, and fuzzy logic. It can detect both misuse attacks and anomaly attacks. Network events have been treated as data stream and various data stream-based learning models have been used in presenting a new insight about intrusion detection [32]. The applications of data mining in communication network control include [33]: Ÿ Classification of network status, application types, and user types, etc. to take the most suitable action for each situation. Ÿ Clustering of users or nodes into groups based on commonalities such as applications, channel conditions, hardware resources, and position to improve network load distribution, network performance, and user satisfaction. Ÿ Developing regression models to predict service duration, traffic load, channel quality, the number of service requests, and desired service quality.Ÿ Identify frequent sequential patterns to find typical network traffic trends, typical user behavior, and network security attacks, etc. Ÿ Discovering association rules between network control parameters, user satisfaction, and network performance. Intrusion detection based on text processing has been a research topic in information and network security. An intrusion detection mechanism using the text-processing based k-nearest neighbour (k-NN) classifier was presented. The classifier was used on the database DARPA 1998 and was shown to produce better results than those of other algorithms [34]. Summarizing research in attack detection is presented here as follows [35]: 1) emphasis on trying to find hybrid solutions and detection classification from the year 2001 to 2008; 2) emphasis more on data mining and machine learning, as well as hybrid solutions of anomaly detection and misuse detection from 2010 to 2015. Machine learning methods have been studied for the design of IDS including Bayesian networks, linear genetic programming (LGP), neural networks, support vector machines (SVM), fuzzy inference systems (FISs), and multivariate adaptive regression splines (MARS), etc. Neural networks especially, have been used in both misuse detection and anomaly detection [36]. Machine learning methods like SVM are also under the umbrella of data mining and each of the data mining and machine learning methods has its own pros and cons in intrusion detection. Table 4 [37] describes and compares these methods.
|
4.3. Deep Learning in Network Intrusion Detection
- Deep learning is also called deep machine learning, hierarchical learning, or deep structured learning. It can be unsupervised or supervised learning from the collected data based on multiple layered models. Deep learning algorithms are very useful for analysing large amounts of unsupervised data with high variety, which gives it potential in analysing network data for intrusion detection. However, deep learning has some challenges in big data [38]:Ÿ Large-scale deep learning models are appropriate in handling large volume of inputs associated with big data. However, how to determine the optimal number of model parameters and how to improve the computational practicality is a challenge in deep learning for big data. Ÿ High-dimensional data sources can result in large volumes of raw data, making it a challenge to develop deep learning algorithms for big data with high dimension.Ÿ It is necessary to adapt deep learning to stream data because within incremental learning for non-stationary data, one of the challenges is handling streaming and fast-moving input data.
5. Big Data Analytics in Network Intrusion Detection
- Conventional technologies often cannot support long-term and large-scale analytics primarily because retaining large volume of data is often not economical or feasible. Therefore, most event logs and other recorded activities are deleted after a fixed retention period. Secondly, it is too inefficient to conduct analysis and complex queries on unstructured and large datasets with noisy and incomplete data. Big data applications are becoming a part of security management software because they help prepare, clean, and query heterogeneous data with incomplete and/or noisy records [39]. In addition, issues related to data fusion, security information and event management (SIEM) systems, and heterogeneous intrusion detection architectures have been studied [3].Big Data analytics for intrusion detection and mitigating network security problems has been attracting more and more attention because it promotes the study of large volumes of complex and disparate data with various formats from heterogeneous sources, detects anomalies, and combats cyber- attacks. Ultra-high-dimensional data models can be created to profile stream data accurately online, which helps predict and detect intrusion and attacks in real time [40]. Big Data technologies like the Hadoop ecosystem and stream processing can store and analyse large heterogeneous datasets at a high speed, transforming security analytics by: (a) capturing large scale data from numerous internal and external sources such as vulnerability databases; (b) conducting deep analytics on the data; (c) achieving real-time analysis of stream data, and (d) presenting an integrated view of security-related information. Because Big Data analytics tools need to be configured properly, system analysts and architects are required to have an intimate knowledge of their systems [41].By correlating the security events from heterogenous sources, a holistic view and excellent situational awareness of intrusion or attacks can be achieved. Only a single event source like network traffic can generate big data and introduce challenges; however, the more heterogeneous data sources available, the more challenges and complicated big data will become. On the other hand, integrating security events from heterogeneous sources (such as netflow, firewalls, IDS, and host log files) for better situational awareness is another major challenge. Furthermore, a comprehensive approach is required to develop tools, techniques, and infrastructure that adapts to permit continuous querying over stream data and spans across the areas of statistical analysis, deductive reasoning (inference), inductive reasoning (machine learning), and high performance computing (parallelization). Automated (or at least partially automated) distribution of tasks over clusters and big data-specific parallelization techniques are also necessary for effective stream processing [22].A model with a three-layered architecture has been used to describe big data systems, including an application layer, a computing layer, and an infrastructure layer. The application layer includes software or other application resources for implementing data analytics while the computing layer is also called the middleware layer, including the software tools for integrating and managing data. And the infrastructure layer, which includes a network of storage systems based on virtualization and cloud computing is also a system of distributed hardware for storing big data [42]. Big data technologies can be categorized into stream processing and batch processing. Stream processing is performed on data in motion; while batch processing is performed on data at rest. A typical technology with the batch processing of big data is Hadoop. Using a Big Data analysis system that can conduct both stream processing (real-time analytics) and batch processing is the best defence strategy that will efficiently perform intrusion detection and protect critical information infrastructures (CIIs) [42]. Network intrusion prediction and detection is time-sensitive needs highly efficient Big Data technologies to deal with problems on the fly [20].An advanced persistent threat (APT) is a targeted attack against a high-value asset or a physical system and is one of the most serious information security problems. Big Data analysis is an appropriate approach to APT identification [41] because of the assistance in facilitating APT identification by supporting [43]: Ÿ Anomaly detection based on the correlation of historical and recent events. For example, an increased volume of Domain Name System (DNS) traffic from a system during a short time can be due to legitimate users’ behaviors. But such a pattern indicates covert data exfiltration if it is also detected in historical traffic over a period of days. Furthermore, this kind of correlation helps reduce the false positive rate (FPR) of alerts. Big Data analytics increases the scope and quantity of data that can compute correlation.Ÿ Managed and dynamic capture, integration and correlation of data from heterogeneous data sources like network traffic, event data (e.g., IDS, network devices), and operating system artifacts help defenders correlate sporadic low-severity events as the result of ongoing intrusion or attack behavior. Compared with SIEM systems, Big Data analytics does not have a limited-time window within which the correlation is performed.
6. Conclusions
- Anomaly detection methods are good in detecting network-level attacks, but not in detecting application level exploits. Accuracy, FNR, and FPR are three practical evaluation criteria for the IDS. Storm, Flink, and Spark Streaming are primary open source platforms for distributed stream-processing. Removing redundant and irrelevant features helps feature selection and PCA is an approach to extracting features from high dimension data. Intrusion detection can be improved by a comprehensive approach to monitoring security events from various heterogeneous sources. Conventional data mining and machine learning methods are useful in intrusion detection, but they have limitations in dealing with big data on the network. Deep learning algorithms also have some challenges in big data, but have the potential in analysing large amounts of unsupervised network data with high variety for intrusion detection.Big Data analytics can be used to analyse network traffic, virus signatures, user behaviours, website profiles, and timing of incident events, etc. It can also compute the correlation of attributes from heterogeneous sources and improve agency’s security through the continuous monitoring of stream data. Streaming data analysis in real time is becoming the fastest and most efficient way to obtain useful knowledge. One Big Data challenge in stream processing is the proper storage, processing, and management of big volumes of stream data. Big Data analytics has the potential to solve the problems and challenges in cleaning and querying data with incomplete and/or noisy records and in a variety of data structures due to heterogeneous data sources.
ACKNOWLEDGMENTS
- This paper is based upon work supported by the U.S. Army TACOM Life Cycle Command under Contract No. W56HZV-08-C-0236, through a subcontract with Mississippi State University (MSU), and was completed for the Simulation Based Reliability and Safety (SimBRS) research program at MSU.
Disclaimer
- Reference herein to any specific commercial company, product, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or favouring by the United States Government or the Department of the Army (DoA). The opinions of the authors expressed herein do not necessarily state or reflect those of the United States Government or the DoA, and shall not be used for advertising or product endorsement purposes.As the author(s) is (are) not a Government employee(s), this document was only reviewed for export controls, and improper Army association or emblem usage considerations. All other legal considerations are the responsibility of the author and his/her/their employer(s).