-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Networks and Communications
p-ISSN: 2168-4936 e-ISSN: 2168-4944
2012; 2(6): 138-141
doi: 10.5923/j.ijnc.20120206.01
Analyzing the Order Factor of Query Matrix in Private Information Retrieval Protocol for Outsourced Databases
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLSunil B. Mane 1, Pradeep K. Sinha 2
1Computer Engineering & Information Technology Department, College of Engineering, Pune, M.S., India
2(High Performance Computing), Center for Development & Advance Computing, Pune, M.S., India
Correspondence to: Sunil B. Mane , Computer Engineering & Information Technology Department, College of Engineering, Pune, M.S., India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In this paper, we present analysis of non-concurrent model of fast single-database Private Information Retrieval (PIR) scheme for maintaining data privacy with data confidentiality using encryption algorithm like AES for Outsourced Database Service (ODBS) Model. In this model encryption method maintains data confidentiality and a utility that help to create PIR reply which maintains data privacy. Single-database PIR schemes are generally unusable because of its expensiveness from computational point of view. This model suggests use of Graphics Processing Unit (GPU) commodity to process database. This model will help to achieve practical implementation of single-database PIR scheme which uses encryption algorithm to maintain data confidentiality as secondary goal and it serves to create database reply to maintain data privacy as primary goal. This paper shows some real time results that proves need of concurrency in PIR algorithms. Our paper describes the use of lattice based single-database PIR protocol with GPU as a processing unit to achieve high speed-up and hence, the performance of the system.
Keywords: Outsourced Database, Private Information Retrieval, User Privacy, Data Privacy
Cite this paper: Sunil B. Mane , Pradeep K. Sinha , "Analyzing the Order Factor of Query Matrix in Private Information Retrieval Protocol for Outsourced Databases", International Journal of Networks and Communications, Vol. 2 No. 6, 2012, pp. 138-141. doi: 10.5923/j.ijnc.20120206.01.
Article Outline
1. Introduction
- A PIR scheme is a protocol in which user retrieves a record or set of records out of n records from the database which has been outsourced by hiding the contents from service providers or database administrators. In order to preserve data privacy replicas of the database have been stored at the service provider end. Since service provider does not know the result of the query has calculated from which copy of the database. Another way is to allow a user to retrieve privately an element of a non-replicated database known as single-database PIR schemes. In single-database PIR schemes data privacy is related to the intractability of mathematical problem, instead of being based on the assumption that different replicas exists and do not collude against their users[1][2][3] .PIR schemes usually require the an enormous amount of computational power, but considering the huge number of applications these protocols have, it is important to develop practically implemented protocols that provide acceptable performances for as many applications as possible[1]. A major issue with single-database PIR schemes is that, they are computationally expensive. Indeed, in order to answer a query, the database must process all of its records. If in a given protocol, it doesn’t process some set of records, the database administrator will learn that, the user is not interested in them. This would reveal to the database administrator about partial information on which record the user is interested in, and therefore it is not as private as downloading the whole database and retrieving locally the desired entry.The computational cost for a server replying to a PIR query is therefore linear on the database size. Moreover, number-theoretic schemes have a very expensive cost per bit multiplication over a large modulus in the database. This limits both the database size and the throughput shared by the users.
2. Overall Design of Proposed Model
- In a PIR protocol, when a user wants to retrieve an element of index i from a database, he will use a PIR query generation algorithm with input i and send the resulting query to the database as shown in Figure1. In this paper we are focusing on the two security issues with respect to outsourced databases such as data privacy and data confidentiality. Since PIR protocol involves matrix operations, the performance of the system is also a major issue. In order to optimize the performance of the system, analysis of the existing PIR implementation is required. The two security issues are described as: Data privacy: Clients should not get more information than what they are querying on the server.Data confidentiality: Outsiders and even the server’s operators (database administrators) should not be able to see the outsourced data contents in any case (including when a client’s query is performed on the server). Usually it is achieved using encryption of databases.The model of PIR scheme given in[2],[3] is a lattice based implementation of PIR. We have added encryption as an addition to existing method and analysed the order of query matrix used in PIR algorithms. A reply generation contains matrix multiplication operations it handles the data privacy issue and encryption of the result gives the data confidentiality. It has been is described in three phases as shown below:
2.1. Request Generation
- The scheme has three global integer parameters: 2N, the dimension of the lattice and special parameters p and q. The database is described as a set of n elements, and we note i0 the index of the database element the user is interested in. To obtain a PIR request, the user will follow:1) Note l0 = ┌log (n × N) ┐ + 2 and set q as 22×l0−1 and p as a prime larger than 23×l0.
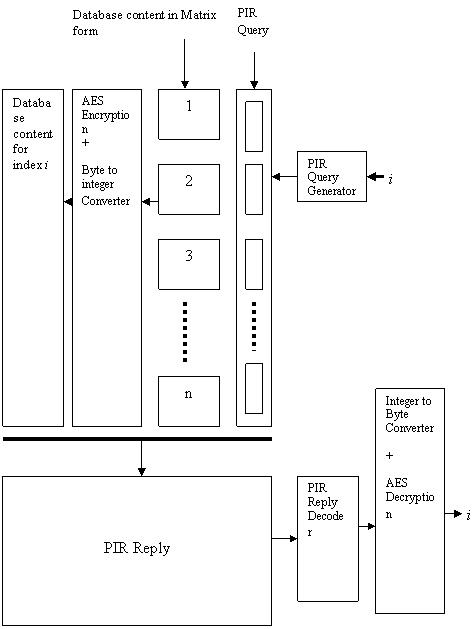 | Figure 1. Proposed model of PIR Protocol |
2.2. Answer Encoding
- Each element of the database ai (for i ∈ {1, · · ·, n}) is encoded as an L × N matrix Ai of l0-bit scalars. To answer to the PIR reply the database follows.1) Note A =[A1| · · · |An] the column concatenation of the database element matrices and B =[Bt1| · · · |Btn] t the row concatenation of the query matrices.2) Compute R = A × B over Z/pZ.3) Return R.The result is a L × 2N matrix over Z/pZ. As a database element is encoded as a L×N matrix of l0-bit scalars and p is 3l0-bit long, the expansion factor of the reply will be F = 6.
2.3. Information Extraction
- In order to simplify the description of the information extraction protocol we define how to operate for each row vector of the reply. In practice some of these operations are aggregated and done over many row vectors at the same time. To extract the information from a row vector Vx of the database reply, the client operates in two phases. First it unscrambles the vector and recovers the noise included in it (steps 1 and 2 of the protocol), and then he will filter out this noise to obtain the information (steps 4 and 5). Note that steps 4 and 5 are not done over Z/pZ, as they correspond to an Extended Euclid’s division over Z.1) Unscramble the noisy vector V’x = VxΔ−12) Retrieve E = V’x (D) – V’x (U) M1−1M2, The inserted noise, V’x (U) and Vx (D) being respectively the undisturbed and disturbed halves of V’x (i.e. the left half and the right half respectively).3) For each ex,y in E =[ex,1 · · · ex,N ], if ex,y > p/2 compute e'x,y = p − ex,y.4) For each e’x,y compute e’’x,y = e’x,y − ε With ε: = e_x,y%q if e’x,y%q < q/2 else ε := e’x,y%q − q .5) For each y ∈ {1 · · · n}, compute ai0, x, y = e’’x, yq−1.Query generation Algorithm creates PIR query for the input index i. The database content for the index i will be encrypted with AES encryption algorithm and its result is then converted into equivalent integers, which then will be converted into integer matrix form. The elements of this matrix are combined with the PIR query using the reply generation algorithm. The result is then sent back to the user. Finally, the user will decode the answer through a reply decoding algorithm & AES decryption algorithm.
3. Description of the Proposed Scheme
- In this section we describe an overview of our proposed PIR scheme. There are two factors which we have more focused on in this paper: • The bottleneck in PIR schemes is reply generation and it is not reply extraction[1].• The GPGPU (General-Purpose computation using Graphics Processing Units) computations will be on the common operations of Query generation & reply generation phase[1].In our proposed scheme the query generation (without common operation in reply generations) and reply extraction have been implemented straightforwardly. We describe a database as a set of n records. Each record ai is split into l0-bits sub-elements and represented as a matrix A. N and l0 are being two security parameters. Noting down Smax the size of the largest record in the database, parameter L is set to L = ┌ Smax / (N × l0) ┐. If a record is smaller than (L × N × l0) then end of the matrix filled up with a standard padding techniques like filling all the remaining elements of the matrix as ‘0’s.
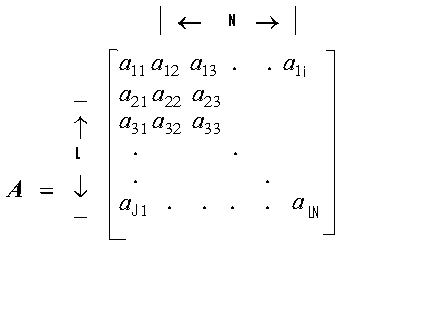 | Figure 2. Database result in integer matrix form |
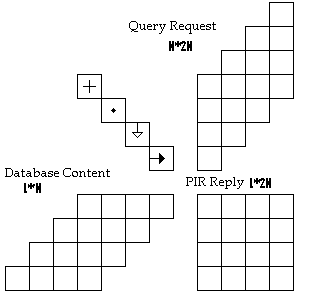 | Figure 3. PIR reply generation |
4. Implementation
- We have implemented the PIR scheme in non-concurrent paradigm. As per as practical implementation is concern, it is very clear that, in this particular scenario there is a need of having parallelism. Currently we have non-concurrent version of library which containing all operation needed for PIR. We have executed all the PIR operation on following configuration:Processor: Intel C2D T660 2.2 GHzRAM: 4 GHzOperating System: Ubuntu 9.10Programming Language: Java 6
5. Experimentation and Results
- Following Graph 1 plotted against Execution time vs. Value of dimensioning factor (N). As per the graph if dimensioning factor N increases linearly then the execution time T increases exponentially. E.g. suppose the number of records is 1024 or 512 and when the value of N > 6 execution time has tremendous increase as shown in the graph. Hence for high dimensioning value there is need of concurrency.
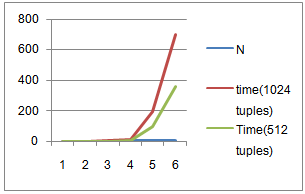 | Graph 1. Time in Sec. Vs. Order of Matrix |
6. Reply Generation of GPGPU
- The concept of general-purpose computation using graphics processing units (or GPGPU) has arisen in recent years. GPGPU applications make use of graphic processing units (GPU) as massively parallel processors, turned away from their original purpose but nonetheless highly efficient in numerous application domains. Combining both speed and bandwidth due to their parallel architecture (and accessible cost), GPU are an attractive choice for complex computations compared to traditional CPU since they exhibit significant performance overheads, and are supported by constantly improving high-level programming language provided by both GPU vendors and the academic community.GPU have now evolved from highly-specialized graphics processors into powerful, flexible programmable units, and become increasingly popular for a wide range of applications. All the existing PIR schemes are highly parallelizable. However, in the classic schemes, the basic operation for reply generation (per bit on the database) is a multiplication over a 1024 or 2048 bit modulus.[1] Our proposed model will parallelize all common basic operations in reply generation as well as Query matrix generation phase. The stream processors that form a GPU are not adapted to do directly such operations and trying to do a straightforward parallelization would result in very poor performance. The correct approach is to use the whole set of stream processors to split an exponentiation among them. This can be efficiently encoded through SIMD (Simple Instruction Multiple Data) instructions, on which GPUs are specialized. Each of these operations can be executed inside a single stream processor and the large number of these processors in modern GPUs results in a significant performance improvement.
7. Conclusions
- Our model of Private Information Retrieval protocol gives an idea of data privacy as well as data confidentiality with the help of encryption algorithm like AES algorithm. This paper shows relation between the value of dimensioning parameter N & execution time T (in sec.) on non-concurrent implementation. This paper also propose the use of GPGPU (General-Purpose computation using Graphics Processing Units) for implementation to increase speed of execution of protocol, which will leads to practical usability of PIR schemes in real world.