-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Information Science
p-ISSN: 2163-1921 e-ISSN: 2163-193X
2018; 8(1): 1-12
doi:10.5923/j.ijis.20180801.01

A Context-Adaptive Ranking Model for Effective Information Retrieval System
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLKehinde Agbele, Eniafe Ayetiran, Olusola Babalola
Department of Mathematics and Computer Science, Elizade University, Ilara-Mokin, Nigeria
Correspondence to: Kehinde Agbele, Department of Mathematics and Computer Science, Elizade University, Ilara-Mokin, Nigeria.
| Email: |  |
Copyright © 2018 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

When using Information Retrieval (IR) systems, users often present search queries made of ad-hoc keywords. It is then up to information retrieval systems (IRS) to obtain a precise representation of user’s information need, and the context of the information. Context-aware ranking techniques have been constantly used over the past years to improve user interaction in their search activities for improved relevance of retrieved documents. Though, there have been major advances in context-adaptive systems, there is still a lack of technique that models and implements context-adaptive application. The paper addresses this problem using DROPT technique. The DROPT technique ranks individual user information needs according to relevance weights. Our proposed predictive document ranking model is computed as measures of individual user search in their domain of knowledge. The context of a query determines retrieved information relevance. Thus, relevant context aspects should be incorporated in a way that supports the knowledge domain representing users’ interests. We demonstrate the ranking task using metric measures and ANOVA, and argue that it can help an IRS adapted to a user's interaction behaviour, using context to improve the IR effectiveness.
Keywords: Context-awareness, Information retrieval, DROPT technique, Information relevance
Cite this paper: Kehinde Agbele, Eniafe Ayetiran, Olusola Babalola, A Context-Adaptive Ranking Model for Effective Information Retrieval System, International Journal of Information Science, Vol. 8 No. 1, 2018, pp. 1-12. doi: 10.5923/j.ijis.20180801.01.
Article Outline
1. Introduction
- Recent years have witnessed ever-growing amount of online information. The development of the World Wide Web (WWW) led to increase in the volume and diversity of accessible information. The question that now arises is how access to this information can be effectively supported. Users require the assistance of tools aimed to locate documents that satisfy their specific needs. Information retrieval (IR) concerns searching documents for information that meet a user need. Traditionally, document representations are expressed by extracting meaningful keywords (index terms) from the documents in the form of a cross-reference lookup. When the user sends a search request, a representation of his/her information need will also be expressed in the same manner. Then the user query and the representation of the document will be matched according to specific matching conditions. Results are presented to the user in a form of a ranked list that contains the most relevant documents. Most of the documents that are retrieved however are irrelevant to the user because search engines cannot determine the user context. Diverse IR models have been developed for this purpose.Ideally, the relevance of documents should be defined based on user context. Thus, the problem of ranking of retrieved documents should be based on user context and preferences. Relevance is a standard measure utilized in IR to evaluate effectiveness of an IR system based on the documents retrieved. The concept of relevance, however, is one that is subjective and influenced by diverse factors. To this end, user perception and user knowledge level are factors that influence the relevance of a retrieved document. Therefore, there has been a paradigm shift from a view of relevance as simple term matching between query and document, to a view of relevance as a cognitive and dynamic process involving interaction between the information user and the information source. It is important for IR systems to obtain accurate representations of users‘ information needs and context of information need. Hence, search knowledge encompasses a wide variety of aspects of the search, such as the interaction mode by users. A context refers to the environment around a user that reflects or affects the user's search goal. Web search personalization is the process that allows a search engine to adapt the search results to user's specific goal by integrating user's context information beyond the query provided. The goal of context information is to determine what a user is trying to accomplish. We propose a solution to this problem to quantify the context of retrieved information. The technique aims to avoid the drawback of manually scanning through and selecting from a long list of documents. We also apply context-awareness to reformulate queries in order to improve the predicted relevance of retrieved documents.The rest of the paper is organised as follows: Section 2 presents the background and related work. Section 3 describes the context-adaptive IRS model. Sections 4 describes the DROPT technique while Section 5 describes the experimental design. Sections 6 and 7 present the results of the experiments. Section 8 presents the statistical analysis results and discussions. Section 9 concludes the paper.
2. Background and Related Work
- One of the key drivers and developments towards creating personalized solutions that support context-adaptive systems has been the results from research work in personalization systems. The main indication derived from these results showed that it was very difficult to create generic personalization solutions, without in general having a large knowledge about the particular problem being solved. These seemed to result in either a very specialized or a rather generic solution that provided very limited personalization capabilities. In order to address some of the limitations of classic personalization systems, researchers have looked to the new emerging area defined by the so-called context-aware applications and systems (Abowd et. al., 1997 and Brown et. al., 2007). The term context and context-awareness, denotes a general class of systems that can sense a continuously changing physical environment and provide relevant services to users on this basis Dey, (20011). The definitions of context are varied, from the surrounding objects within an image, to the physical location of the system's user. The definition and treatment of context varies significantly depending on the application of study (Edmonds, 1999). Context in information retrieval has also a wide meaning, going from surrounding elements in an XML retrieval application (Arvola et. al., 2005), recent selected items or purchases on proactive information systems (Billsus et. al., 2005), broadcast news text for query-less systems (Hezinger et al., 2003), recently accessed documents (Bauer and Leake, 2001), visited Web pages (Sugiyama et al., 2004), past queries and clickthrough data (Bharat 2003; Dou et. al., 2007; Sugiyama et. al., 2004; Shen et. al., 2005), text surrounding a query (Finkelstein et. al., 2001), text highlighted by a user (Finkelstein et. al., 2001), recently accessed documents (Bauer and Leake, 2001) etc.Context-aware systems can be classified by 1) the concept the system has for context, 2) how the context is acquired, 3) how the context information is represented and 4) how the context representation is used to adapt the system. One of the most important parts of any context-aware system is the context acquisition. Note that this is conceptually different to profile learning techniques, context acquisition aims to discover the short-term interests (or local interests) of the user (Dou et. al., 2007; Sugiyama et. al., 2004; Shen et al; 2005), where the short-term profile information is usually disposed once the user's session is ended. On the other hand, user profile learning techniques do cause a much great impact on the overall performance of the retrieval system, as the mined preferences are intended to be part of the user profile during multiple sessions. One simple solution for context acquisition is the application of explicit feedback techniques, like relevance feedback (Rocchio and Salton, 1971 and Salton and Buckley, 1988). Relevance feedback builds up a context representation through an explicit interaction with the user. In a relevance feedback session: 1) The user makes a query. 2) The IR system launches the query and shows the result set of documents. 3) The user selects the results that considers relevant from the top n documents of the result set. 4) The IR system obtains information from the relevant documents, operates with the query and returns to 2). Relevance feedback has been proven to improve the retrieval performance. However, the effectiveness of relevance feedback is considered to be limited in real systems, basically because users are often reluctant to provide such information [Sugiyama et al., 2004], this information is needed by the system in every search session, asking for a greater effort from the user than explicit feedback techniques in personalization. For this reason, implicit feedback is widely chosen among context-aware retrieval systems (Kelly and Teevan, 2002; Shen et al., 2005; White and Kelly, 2006). Based on this fundamental definition, various authors (Emmanouilidis et. al, 2013; Jara et. al, 2013; Noh et. al, 2012 and Xu and Deng 2012) focus on different aspects of context-awareness, including modelling interactions between users and IR systems nature, and how to modelling context. The research reported in Nyongesa and Maleki-Dizaji (2006) showed that based on preferences of users, genetic algorithms (GA) could be applied to improve the search rresults. Similarly, the work reported in Koorangi and Zamanifar (2007) proposed improvement of internet engines using multi-agent systems. In this work, a meta-search engine gives a user documents based on an initial query while a feedback mechanism returns to the meta-search engine the user’s suggestions about retrieved documents. In Allan (2002), contextual information retrieval (CIR) is defined as: "combine search technologies and knowledge about query and user context into a single framework in order to provide the most appropriate answer for user's information needs". CIR intends to optimize the retrieval accuracy by involving two related steps: appropriately defining the context of user information needs, commonly called search context, and then adapting the search by taking it into account in the information selection process. Several studies have addressed context specification within and across application domains (Jara et. al, 2013; Dinh and Tamine 2012; Kebler et. al, 2009; Goker and Myrhaug, 2008; Vieira et. al, 2007). Device, user, task, document and spatio-temporal are the five context specific dimensions that have been explored in context-based information retrieval literature (Emmanouilidis et. al, 2013; Dinh and Tamine 2012; Li et. al, 2011; Asfari et. el, 2009; Mylonas et. al, 2008; Anand and Mobasher, 2007; Maeco et. al, 2013; Lukowic et. al, 2011; Zhou et. al, 2012). In Shen et. al., (2005) proposed a ranking technique for multi-search projections on the Web for results aggregation model based on query words, search results, and search history to achieve user’s intention. To this end the Web can offer a rich context of information which can be expressed through the relevancy of document contents. In Shivaswamy and Joachims (2011) proposed a model for online learning that is specifically adequate for user feedback. The experiment conducted shown retrieval effectiveness for web search ranking. In the context of web search ranking, these techniques aim at finding the best ordering function over the returned documents is important. The authors argue that, regression on labels may be adequate and, indeed, competitive in the case of large numbers of retrievals. To make the web more interesting, there is need to develop a good and efficient ranking algorithm to deliver more suitable results for users. Agbele [2014] developed and coined the acronym DROPT (Document Ranking OPTimization) to name a new adaptive algorithm that provides a limited number of ranked documents in response to a given query. The author argue that, it can improve the ranking mechanism for the search results in an attempt to adapt the retrieval environment of the users and amount of relevant context-aware information according to each user’s request. The DROPT measure must be self-learning that can automatically adjust its search structure to a user’s query behaviour. The DROPT technique is employed in this paper to improve the retrieval effectiveness based on the user interaction behaviour as depicted in Figure 1.
3. Context-Adaptive for IR System
- Context-adaptive IR requires an adaptation of the processed information with respect to the individual users. It depends on the user’s personal context-adaptive whether a user blog article is worth reading with respect to the user’s expectations and abilities. We are thus looking for a workflow to enable how users can judge context changes for adaptive retrieval based on the user profile. One major problem of most current IR system is that they provide uniform access and retrieval of IR results to all users specially based on the query terms users entered to the system. To address these issues we propose a context-adaptive IR model based on document preferences as search context to rank individual users results effectively and the behaviour that individual user has engaged in during the matching tasks. The idea of context-adaptive is to predict relevant ranked documents according to relevance weights. This demonstrates a search context from search engine by observing and analysing user behaviour (i.e. keyword matching based querying frequency). The workflow of the design and evaluation of this proposed context-adaptive IR model is shown in Figure 1(see Appendix A). We generate two user predictive models about document ranking: 1) a predictive user model of the relevance of document content; 2) a predictive user model of ranking for currently retrieved documents. We believe this model (Table 1) can enhance individual user’s system retrieval performance greatly.
|
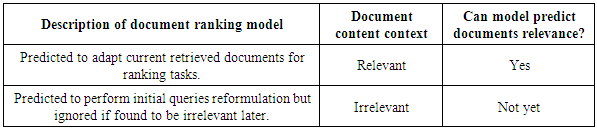
4. DROPT Technique
- This section describes the document ranking technique for context-aware IR known as a document ranking optimization (DROPT) according to information relevance. A document ranking technique is an algorithm that tries to match documents in the corpus to the user, and then ranks the retrieved documents by listing the most relevant documents to the user at the top of the ranking. Unfortunately, despite the exposure of individual users to domain of Web retrieval and online documentation systems with document ranking features; it rarely addresses the information relevance of ranked output as core issue.
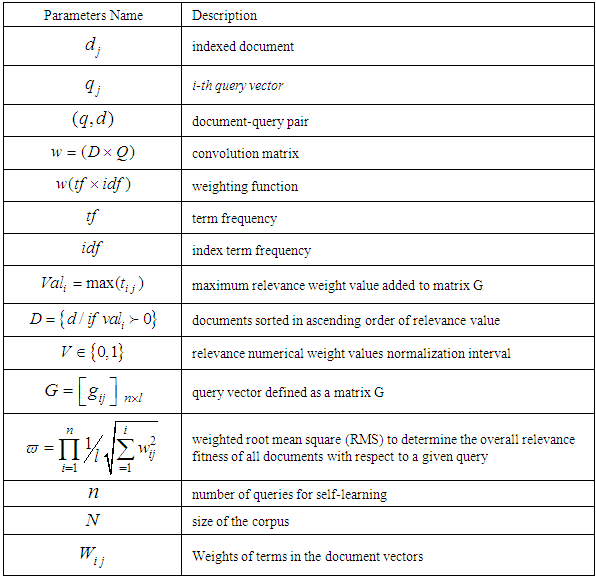
4.1. Parameters Used for Ranking Principles
- In this sub-section we study the problem of ranking of retrieved documents. For example, we desire to rank a set of scientific articles such that those related to the query ’information retrieval’ are retrieved first. The basic assumption we make is that such a ranking can be obtained by a weighting function
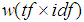 which conveys to us how relevant document d is for query q. The document ranking will be done by taking a weighted average of all determined parameters. Table 2 depicts the summary of notations.
which conveys to us how relevant document d is for query q. The document ranking will be done by taking a weighted average of all determined parameters. Table 2 depicts the summary of notations.
|
4.2. Formalization of Mathematical Model Definitions
- This optimization of IR is obtained by ranking the documents according to a relevance numerical weight value
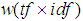 which is obtained from the weighting function w in descending order. Then we wish to return a relevance numerical weight subset
which is obtained from the weighting function w in descending order. Then we wish to return a relevance numerical weight subset 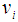 of
of 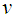 such that for each
such that for each 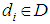 , we optimize the following weighting function:
, we optimize the following weighting function: 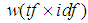 | (1) |
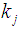 across a document
across a document 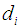 .The DROPT technique is based on IR result rankings, where a ranking R consists of an ordered set of ranks. Each rank consists of a relevance numerical weight value
.The DROPT technique is based on IR result rankings, where a ranking R consists of an ordered set of ranks. Each rank consists of a relevance numerical weight value 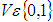 where v represents the relevance numerical weights of the retrieved documents. Each rank is assigned an ascending rank number n, such that:
where v represents the relevance numerical weights of the retrieved documents. Each rank is assigned an ascending rank number n, such that: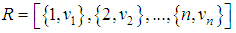 | (2) |
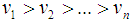 Our technique, DROPT is composed of six steps. Step 1: Initialization of Parameters (a) Let a query vector, Q, be defined as:
Our technique, DROPT is composed of six steps. Step 1: Initialization of Parameters (a) Let a query vector, Q, be defined as: 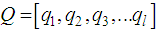 | (3) |
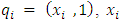 being a term string with a weight of 1.(b) Let the indexed document corpus be represented by the matrix:
being a term string with a weight of 1.(b) Let the indexed document corpus be represented by the matrix: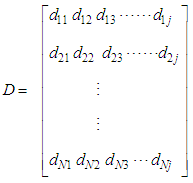 | (4) |
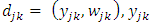 being an index string, with weight
being an index string, with weight 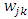 .(c) We compute the convolution matrix
.(c) We compute the convolution matrix 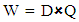 by a simple multiplication of the document vectors and the query vectors representing:
by a simple multiplication of the document vectors and the query vectors representing: 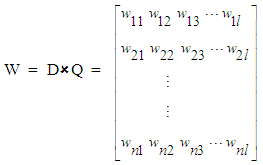 | (5) |
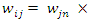 is equal string ignore case
is equal string ignore case 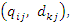 where
where 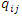 are query vectors,
are query vectors, 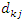 are document vectors,
are document vectors, 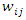 are weights of terms in the document vectors, and
are weights of terms in the document vectors, and 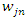 are weights of terms in the query vectors, while n is the number of retrieved documents that are indexed by at least one keyword in the query vector. The matrix W gives a numeric measure with no context information. Step 2: Search String Processing The comparison of the issued query term against the document representation is called the query process. The matching process results are a list of potentially relevant context information. Individual users will scrutinize this document list in search of the information they needs. Step 3: Calculate Relevance WeightRetrieved documents that are more relevant are ranked ahead of other documents that are less relevant. It is important to find relevance numerical weights of the retrieved documents and provide a ranked list to the user according to their information requests.(a) Based on equation (1), the relevance weight is obtained according to document content. (b) Subsequently we calculate the average mean weight using the weighted root mean squares (RMS) to determine the overall fitness value of retrieved documents with respect to a given query calculated as:
are weights of terms in the query vectors, while n is the number of retrieved documents that are indexed by at least one keyword in the query vector. The matrix W gives a numeric measure with no context information. Step 2: Search String Processing The comparison of the issued query term against the document representation is called the query process. The matching process results are a list of potentially relevant context information. Individual users will scrutinize this document list in search of the information they needs. Step 3: Calculate Relevance WeightRetrieved documents that are more relevant are ranked ahead of other documents that are less relevant. It is important to find relevance numerical weights of the retrieved documents and provide a ranked list to the user according to their information requests.(a) Based on equation (1), the relevance weight is obtained according to document content. (b) Subsequently we calculate the average mean weight using the weighted root mean squares (RMS) to determine the overall fitness value of retrieved documents with respect to a given query calculated as: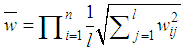 | (6) |
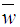 is the average relevance mean weight of each retrieved document, n is the number of keywords terms occurrences in each retrieved document, l is the total size of the keywords in the corpus, and wij are the sum weights of terms of the document vectors. Step 4: User Feedback about Retrieved DocumentsUser feedback about retrieved documents is based on overall relevance weights
is the average relevance mean weight of each retrieved document, n is the number of keywords terms occurrences in each retrieved document, l is the total size of the keywords in the corpus, and wij are the sum weights of terms of the document vectors. Step 4: User Feedback about Retrieved DocumentsUser feedback about retrieved documents is based on overall relevance weights 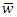 to construct a personalized user profiling of interests. We can achieve this when a user indicates the documents that are relevant or otherwise, from the designated databases context. (a) The overall relevance judgment is given by:
to construct a personalized user profiling of interests. We can achieve this when a user indicates the documents that are relevant or otherwise, from the designated databases context. (a) The overall relevance judgment is given by: 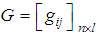 | (7) |
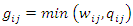 and 1 ≤ i ≤ n, 1 ≤ j ≤ l and G is a query vector with a small-operator defined as a matrix,
and 1 ≤ i ≤ n, 1 ≤ j ≤ l and G is a query vector with a small-operator defined as a matrix, 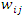 are weights of terms of the document vectors, and
are weights of terms of the document vectors, and 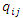 are queries vectors. Any numerical weight component of matrix G greater than the average mean weight,
are queries vectors. Any numerical weight component of matrix G greater than the average mean weight, 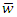 (6) will be retained to add to a matrix T given by:
(6) will be retained to add to a matrix T given by: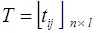 | (8) |
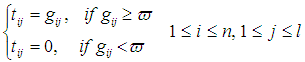 (b) Based on matrix T (8) we calculate relevance numerical weight values, for all set of documents D, which are the largest weighting values for each corresponding vector given by:
(b) Based on matrix T (8) we calculate relevance numerical weight values, for all set of documents D, which are the largest weighting values for each corresponding vector given by: 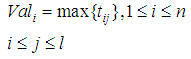 | (9) |
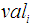 was higher than the overall average relevance weight would be predicted as a relevant document; any document with a lower value would be predicted as irrelevant document (9). Thus average relevance mean value within the normalization interval
was higher than the overall average relevance weight would be predicted as a relevant document; any document with a lower value would be predicted as irrelevant document (9). Thus average relevance mean value within the normalization interval 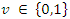 is computed for each document given by:
is computed for each document given by: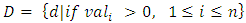 | (10) |
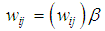 | (11) |
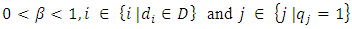 We coined the acronym DROPT to name our adaptive algorithm that provides a limited number of ranked documents in response to a given query. Also it can improve the ranking mechanism for the search results in an attempt to adapt the retrieval environment of the users and amount of relevant context information according to each user’s request. Finally, the DROPT measure must be self-learning that can automatically adjust its search structure to a user’s query behaviour.
We coined the acronym DROPT to name our adaptive algorithm that provides a limited number of ranked documents in response to a given query. Also it can improve the ranking mechanism for the search results in an attempt to adapt the retrieval environment of the users and amount of relevant context information according to each user’s request. Finally, the DROPT measure must be self-learning that can automatically adjust its search structure to a user’s query behaviour. 5. Experimental Design
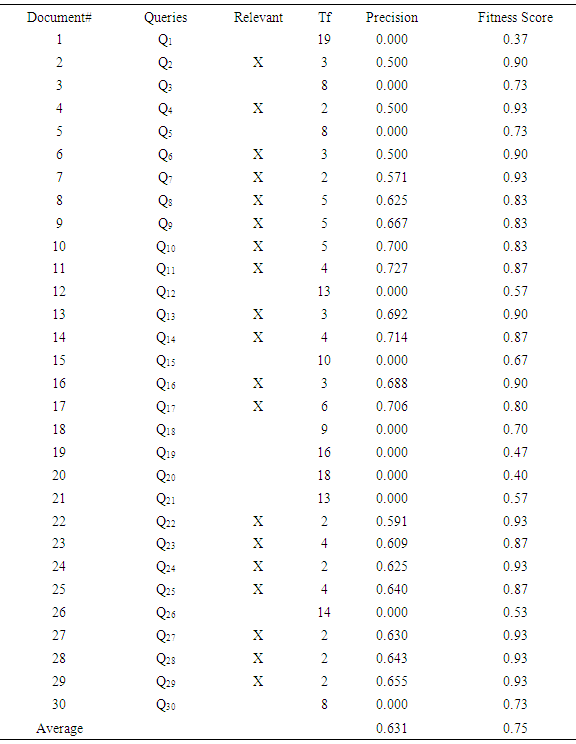
- The experiment was designed to study a new user’s behaviour source i.e. ranking of retrieved documents that can influence the information retrieval process. Though considering user searching actions (i.e. clicking on a document in a search result, printing a document, moving a document into a folder, etc.) as sources for implicit relevance of documents, the techniques presented in this paper is different because it considers document ranking. From that view, the techniques is interesting and innovative as it emphasizes that the IR process is not just about matching between documents and queries but relationships among matching, user actions and user preferences in ranked documents of retrieved results. The experiment was designed and piloted using systems that allows interactive information retrieval (IIR) experiments that log users ‘in different browsers interactive search behavior. The system has a search engine where tables are created for experimental generated data from searching tasks. The systems were used to determine the frequency of keyword matching-based querying results to monitor the progress of the experiment. They performs several information related tasks activities such as searching, filtering, matching, displaying, and learning information needs over time. This is concerned with the reuse of the existing standards, approaches, and how to incorporate them into the design of the IR system. During the search, the participant interactions with the search engine were logged via the system log in menu. In each search task, the participants were asked to obtain the frequency of keyword matching based querying across a document; that were relevant to meet their information requests. The behavioral measures we examine are the frequencies of the user issued query (i.e. frequency of keyword matching based querying) while interacting with the IR system.We involved three system users (Master students) in the area of Computer Science in the Department of Computer Science to collect data through the WampServer search engine back end prototype. The three study system user participants were given 10 search tasks each in their domain of knowledge. During the search context, the students’ interactions with the search engine back end prototype were logged via the system log in menu with their "student identification number". In each task, the students were asked to obtain the frequency of keyword matching based querying across a document that were relevant to meet their information requests to achieve document ranking task based on individual users’ preference, or ignore documents that were found to be irrelevant. The user behavioural measures we examine are the frequencies of the issued query. The function of the frequency of the keyword across a document from the document database collected is stored in the WampServer site localhost database. WampServer is a Windows Internet environment that allows user to create Internet applications with Apache 2, PHP and a MySQL database. PHP Myadmin allows user to manage easily our databases. This measure was used to predict the ‘relevant” documents marked ‘X” for document ranking model. To evaluate the performance of the proposed technique, we performed an experiment on small scale search of different 30 queries from the system users to validate the effectiveness of the technique. Table 3 gives the statistics of the queries considered in the experiment. The personalized predictive ranking model identifies retrieved documents to individual user from the domains according to his/her preferences.
|
6. Ranking Performance Results
- With the intention of measure ranking performance, the DROPT technique, according to Agbele (2014) for ranking search results list was tuned by experimenting with the prototype system for relevance judgment. In this paper, each query produced a document based on the matching conditions and the retrieval was repeated for 10 query reformulations from the domain of system user experts. The underlying philosophy of the relevance judgment rules for user model judgment using the DROPT technique is to rank those documents, which exceeded the overall weighted fitness score that the system user judges to be relevant to his/her information needs, and ignore those documents the system users judge to be irrelevant (less preferred).
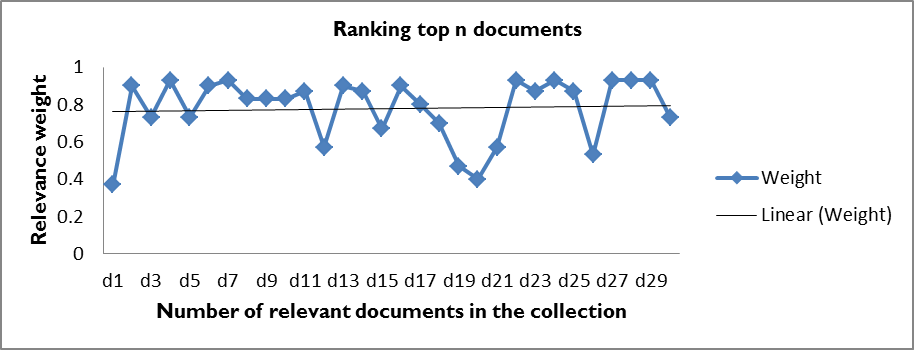 | Figure 2. Ranking performance graph results at the known relevant documents |
7. Comparison of DROPT Technique with TF-IDF Method
- In this section, we present the results that show the performance of our DROPT technique against a traditional tf-idf method. We compared our ranking algorithms with selected well-known baseline algorithms such as TF-IDF to evaluate the performance of our ranking technique in standard "Precision at position n" (P@n) measure. For the information needs and document collection of the experiment, relevance was assessed by different system users in their domain of experts. They are knowledgeable in their domain and were asked to judge the relevance of the retrieved documents on a six level scales: (0=Harmful, 1=Bad, 2=Fair, 3=Good, 4=Excellent and 5=Perfect) with respect to a given query. For comparison of results, we have used P@n metrics Jarvelin and Kekalainen (2010). Precision at n measures the relevancy of the top n results of the ranking list with respect to a given query according to equation (12).
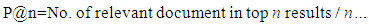 | (12) |
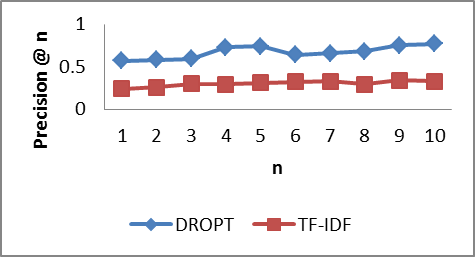 | Figure 3. Ranking performance graph results at the known relevant documents |
8. Statistical Analysis and Discussion
- Agbele et. al (2016) presented the DROPT algorithm results and extended in this present paper by performing statistical analysis using ANOVA on 30 queries. Significance test interpretation was carried out in this research study with the purpose of measuring the effectiveness of IR system using interactive reinforcement learning (user’s feedback and context-awareness) in comparison to relevance feedback. The test was established to reject the null hypothesis, H0 that there is difference between the group means of Domain of system user participants 1, 2, and 3. Rejecting H0 infers accepting the alternative hypothesis; H1 with at least one of the means is different from others in retrieval efficacy in order to improve the system performance. Since F-statistical table falls to the left of F-distribution (5.19 > 4.74) under the acceptance region. Therefore we may conclude at a 5% level of significance test that there is a significant difference in the means of at least one group of Domains 1, 2, and 3. This is because the values of ad-hoc keywords matched against documents that were searched independently across each of the domains of system user’s participants and the corresponding values of occurrences of issued query were obtained. The interpretation of this statistical result demonstrates the improvement of information retrieval efficacy through the attributes from the user behaviour actions while interacting with the IR system.Our results on the indexed ad-hoc keywords represent domain of the system user’s three participants in an in-lab experimental setting. The results demonstrate that combining individual system user’s behavioral measures can improve ranking prediction accuracy (according to relevance weights), for documents ranking tasks, and however that individual users ranking performed much better than combining document rankings of the systems. This accomplishes personalization of retrieved documents for individual users as the focus of this paper. The retrieval effectiveness is measured using well known metrics Precision and Recall, at known relevant documents. Definitions:Let MSB depicts variance between the three domains considered in this study. Let MSW depicts variance within the three domains considered in this study.In order to evaluate both the means and standard deviations of the keyword matching based querying experiments, we construct hypothesis test based on the values obtained across all issued queries after 30 generations (10 search tasks from each participant domain) using Analysis of Variance (ANOVA).H0: μ = μ 1 = μ 2 = μ 3 where 1, 2, and 3 are domains considered in this study.H1: At least one of the means is different from the others.
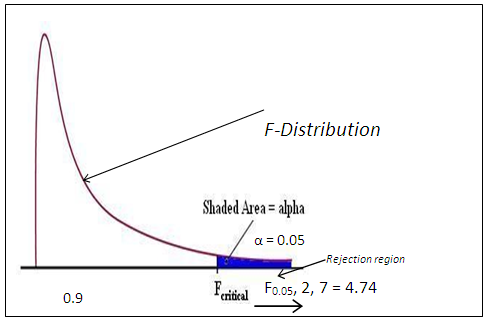 | Figure 4. Showing values of 4.74 at F 0.05, 2, 4.74 |
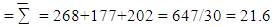 The mean for each domain are evaluated as follows:
The mean for each domain are evaluated as follows: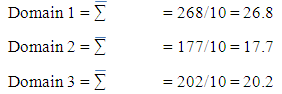 The variance for each domain is evaluated as follows:Domain 1 = 228.9/10 = 22.89Domain 2 = 154.5/10 = 15.45Domain 3 = 200.01/10 = 20.01Mean of mean
The variance for each domain is evaluated as follows:Domain 1 = 228.9/10 = 22.89Domain 2 = 154.5/10 = 15.45Domain 3 = 200.01/10 = 20.01Mean of mean 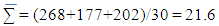 Also MSB = ∑ could be determined as follows:
Also MSB = ∑ could be determined as follows: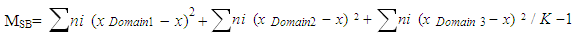 MSB = 10(26.8-21.6)2 + 10(17.7-21.6)2 + 10(20.2-21.6)2 /3-1 = 442.1/2 = 221.05MSB = 221.05Also, MSW = ∑ MSW = (10-1) Domain1 + (10-1) Domain 2 + (10-1) Domain 3 (10-1) / N-KDomain 3/30-3= 9(9.94) +9(12.73) +9(10.45)/7=298.08/7MSW = 42.58Therefore, the test statistics is F = MSB/MSW = 221.05/42.58 = 5.19
MSB = 10(26.8-21.6)2 + 10(17.7-21.6)2 + 10(20.2-21.6)2 /3-1 = 442.1/2 = 221.05MSB = 221.05Also, MSW = ∑ MSW = (10-1) Domain1 + (10-1) Domain 2 + (10-1) Domain 3 (10-1) / N-KDomain 3/30-3= 9(9.94) +9(12.73) +9(10.45)/7=298.08/7MSW = 42.58Therefore, the test statistics is F = MSB/MSW = 221.05/42.58 = 5.199. Conclusions
- Using adaptive IR system, situations can be detected and classified as contexts. Once the proposed system has recognized in which context an interaction takes place, this information can be used to change and adapt the behaviour of IR applications and systems. One has to keep in mind that users learn how to interact with the system, and that they adapt their behaviour. So, it is crucial to develop understandable context-aware IR system that adapts to the users’ expectations. In line with this, well-designed context-awareness is a great and powerful way to make user-friendly and enjoyable IR applications.User interactive behavior measures on relationships among matching help understand how users interact on the clicked documents in response to a given query, and they are indicative of document relevance. Also, user interactive behaviours measures during user actions help describe what the user does between issuing one query and the next. User interactive behaviours about user preferences help understand how to acquire search results. This in turn could improve the information retrieval effectiveness. The adapted search results means to explicitly make use of the user context to tailor search results. Our results demonstrate a significant effect of document ranking on predictive ranking model according to document relevance. Document ranking not only affected the user interactive behaviour as predictors of document relevance, it also affected the relevance weights for each of the user interactive behaviours to improve IR effectiveness. In addition, when document information is available, the ranking model gives better prediction of document relevance. Therefore, we can conclude that it is important for adapted IR systems to detect the context in which a search is conducted, especially the document ranking, and then to apply the user model to adapt search results to individual users. Also document ranking influenced how users interacted with search systems during search sessions. The interpretation of the statistical results using ANOVA demonstrates the improvement of information retrieval effectiveness through the attributes.A DROPT technique has been evaluated to reflect how individual user judges the context changes in IR from the user behaviour actions while interacting with the IR system results ranking. Predictive user model of document ranking were presented to adapt retrieved documents to individual users during their search context, rather than after they finish the entire ranking tasks.
ACKNOWLEDGEMENTS
- The authors would like to thank Elizade University Management for funding this research project.
Appendix A
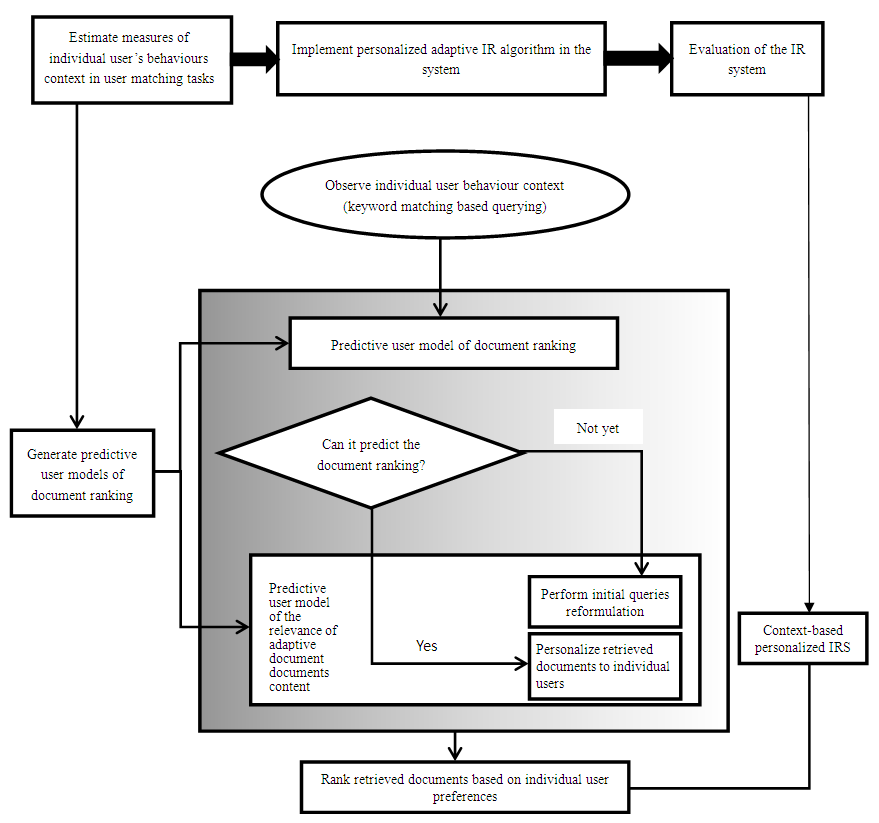 | Figure 1 |