-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Information Science
p-ISSN: 2163-1921 e-ISSN: 2163-193X
2013; 3(3): 63-69
doi:10.5923/j.ijis.20130303.03
A Neural Network Approach to Selection of Candidates for Electoral Offices by Political Parties
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLA. E. Akinwonmi, B. M. Kuboye, A. F. Thompson
Department of Computer Science,The Federal University of Technology, Akure. P.M.B. 704
Correspondence to: A. E. Akinwonmi, Department of Computer Science,The Federal University of Technology, Akure. P.M.B. 704.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Useful governance comes from a reliable electoral process. Such begins from candidate selection within political parties. In Nigeria, factors such as electoral system, party ideology, political culture, and the organization of government, overtime had influenced candidates’ selection processes for the conduct of political party primaries invariably make it subjective. Thus candidates who make it through such process are not always the party’s best. Invariably, many of these candidates loose the general elections. Obviously, advancement in technology has gradually changed nearly every facet of live yet there exist exceptions in the area of democratizing the electoral system. In this paper, we present a feed forward/back propagation neural network based approach to selecting suitable candidates for elective positions before general elections. We had to enlarge the training dataset through interpolative synthesis. Our result proved that the approach was efficacious. In this report, we present an introduction to the problem and the methodology of solving the problem. Thereafter, we reported on the design, implementation and the results obtained from the system. We drew useful conclusions were later drawn from the results.
Keywords: Feed Forward, Back Propagation, Feed Forward Neural Network, Candidate Rating, Candidate Selection
Cite this paper: A. E. Akinwonmi, B. M. Kuboye, A. F. Thompson, A Neural Network Approach to Selection of Candidates for Electoral Offices by Political Parties, International Journal of Information Science, Vol. 3 No. 3, 2013, pp. 63-69. doi: 10.5923/j.ijis.20130303.03.
Article Outline
1. Introduction
- Good governance is an upshot of a qualitative electoral process: beginning from candidate selection or nomination within political parties, permeating candidate screening by national electoral commission through to the actual contest in general elections. Factors such as electoral system, party ideology, political culture and the organization of government, overtime, had influenced candidates’ selection processes[1]. In some countries gerrymandeering is used to favour certain candidates. In the United States of America, the exact mode of which primaries or caucuses are conducted and the voting procedures for delegates is defined by each state's local office of political parties[2]. Education, career experiences and exposure of candidates can facilitate or undermine a candidate’s success in the polls.Many Americans believe that Sarah Palin (ex RepublicanVice Presidential candidate) was instrumental to McCain loss of election to Obama in the election that led to the latter’s victory in 2009. The pre-election debates revealed Palin as a “limited to career” person, hence she went off topic numerous of times during the debates. This was more revealing as she was unable to mention a name of a single newspaper or magazine which she had read[3]. In Nigeria, the precise process of candidate selection within most parties is not well grasped by the citizenry including many politicians. This is more so because available literature on intra-party processes is largely inadequate. Moreover, the ideal of what parameters and criteria to use for candidate selection varies largely within many political parties while it is vague in some. In general, political parties usually present candidates for general elections after selections are made through intra-party elections, recommendations or appointments. In most cases the parties. The survey by[4]on candidate selection criteria by parties further revealed that, education, professional experience, political experience, criminal records, origin, age and other basic demographics were used as criteria for selection in many cases. Certain selection criteria are specified in many cases. These may include gender representation in other cases[5]. In most successful elections, education, experiences and exposure of candidates have roles to play. These criteria are best described as rudimentary and they do not form the basis by which party delegates cast their votes. There has to be a more reasonable means of selecting a candidate from the ostensibly qualified lot within a political party.In that regard, we believe that candidate selection can be made more objective and goal-driven if quantifiable, resultant but consequential parameters are included as criteria for candidate selection. On such, each candidate can be rated and assessed against a set benchmark that will be agreeable to the party members. It is expected that such rating will provide a model for assessing each ostensiblyqualified candidate’s electoral prospect, personal understanding and alignment with parties manifestoes vis-à-vis electorates’ expectations. Unfortunately, not all parties have the internal democracy, the genuine or generally acceptable method of selecting candidates in Nigeria[6]. Experiences have shown some power manipulating bodies or individuals in the parties deliberately or surreptitiously block due process of selecting candidates (ibid). In most of the parties in Nigeria, bribery and sit-tight syndrome have been institutionalized as mode of candidate selection rather than objectivity and credibility (ibid). Unmistakably Nigeria’s experience has regrettably not demonstrated an acceptable level of democratic compliance. Rather, “god-father” influence, money might and intimidations have characterized internal selection of candidates for elective posts in Nigeria.Undoubtedly, a substantial and gradual technological lift has been witnessed in nearly every facet of our lives as a nation, there still exist exceptions in the sphere of democratization of the electoral system. Several efforts made hitherto to upgrade the traditional voting system had failed. Introduction of E-voting has consistently and cleverly been resisted even by the assembly. Sadly, the customary voting system, with all its inherent shortcomings and pitfalls has been inefficient in the overall voting time and cost. It has remained very unreliable at its best when compared with an E-voting system which is accurate, verifiable, democratic, private, and convenient and in which “polls are popping up all over the World Wide Web, with a few clicks of your mouse”[7]. The hand-marked, hand-collated and hand-appraised traditional political selection process can only get more cumbersome and unnecessarily time-sapping. Worse still, such methods are infested with human errors and vulnerable to premeditated manipulations and rigging by individuals involved in the processes. Thus the integrity of the processes is grossly jeopardized. Fair enough, computers have proved very efficient at solving problems with direct or known solutions through conventional problem analysis and coding[8]. However when an explicit description of the solution to a problem is not feasible or where complex conventional approach to solving problems is inadequate, Artificial Neural Networks (ANNs) can be used. The network’s ability to accumulate knowledge about objects and processes using learning algorithms makes their application at solving complex problems very promising and attractive ([9],[10]). Since they can learn from example or experience, ANNs have been used in solving decision-making problems including: classification, generalization, pattern recognition, learning, non-linearity, abstraction, and analysis of noisy or incomplete data[[11],[12],[13],[14].Moreover, neural networks can adapt themselves during training based on examples of similar problems even without a desired solution to the problem[15]. If sufficiently and carefully trained, a neural net is able to associate the problem data to the solutions, relate inputs to outputs, and offer a feasible solution to a novel problem (ibid).In this paper we present a feed forward / backward error propagation neural network based method to implement selection of candidates for electoral positions based on benchmarked criteria.
1.1. Related Studies
- Feed forward/back propagation neural networks have been used in solving character matching problems which good results[16].[17] Presents an expert system for evaluation of the unemployed at certain offered posts. The system used Neuro-Fuzzy techniques to analyze a corporate database of unemployed and enterprises profile data. Thereafter, a Sugeno type Neuro-Fuzzy inference system was used to process the matching of an unemployed with an offered job. Moreover,[18] using a Feed Forward/BackPropagation neural network engine, designed and implemented a NN based system for recognizing musical notes. In the area of using synthetic data,[19] presented a method for artificial interpolation of data for training purpose in classifier. The result shows that a classifier trained as such did not perform less than that trained on real data. It also proved that such use of synthetic data was safe.
2. Methodology
- We studied the selection criteria and manifestoes of some political parties in the country in the past and at present. We selected ten criteria across party boundaries which were used to assess candidates.From candidates’ particulars we selected information about education, previous experience and exposure. Whereas from party manifestoes, we selected specific electoral promises including agricultural inputs, free and compulsory education, provision of portable water, provision of electricity, employment generation, good health care delivery and provision of good road networks.We trained a feed forward/back propagation neural network with digitalized benchmarked scores as a target for comparison, targeting an output of 1. The network configuration was stored for the target candidate. The network was then run using the digitalized scores of candidates. Output values were recorded and compared with the target. A selection order was generated from the output based on how a candidate compares with the benchmark. Output values ranges from 0 to 1. The candidate with the closestvalue to 1 is selected as the candidate for the position.
3. Design and Implementation
- We applied object-oriented features of Visual Basic to enhance modular techniques in the design of basic functional components. There are four main functional modules of the Candidate selection system (Figure 1). These include the data entry module, digitalization module, the feed forward neural engine and the output module. Other auxiliary components were coded into the system to enhance data collation, accessibility and testing. All components, though integrated, are reusable and separable.
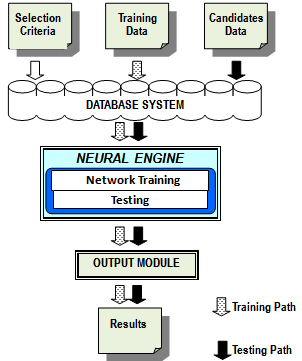 | Figure 1. Conceptual diagram of the neural-network-based candidate selection software |
3.1. Setting up the Network
3.1.1. Training Set
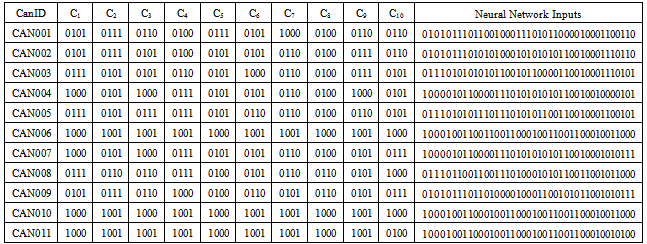
- Reports from pattern recognition investigations have shown that the classifier trained on the most data are give better performance[20],[21],[22]. However, implementing such approach suffers some setbacks which include the high cost of large training sets. Moreover such dataset are difficult to obtain in many cases. The major challenge encountered in this investigation was the scanty nature of available training datasets obtained from section 2 above. Worse still such may not be representative of the universe of discourse. In addition,[19] showed thatsuch datasets may be imbalance, as one class may be represented by too insufficient samples while others have too many.Fair enough, Nonnemaker’s investigation in[19] offered a method to ease this problem through the generation of artificial (synthetic) data. The result of that work and others alsoin[22],[23] and[24] show that training on interpolated data issafe. Such training reportedly gave a good performance when tested on the pure samples. Consequently, we had to synthetically enlarge the training set for better result. Thus we obtained synthetic derivations from interpolation of the sample scores obtained from section 2 above. A variant of the method used by Nonnemakerwas adapted and presented as follows:i. For each selection criterion, werandomly chose 20“seed” samples of the collected training data.ii. For each of the 20 seed points of that selection criterion we derived a training point in a convex space represented by the seeds points by randomly assigning20 weights w1, w2…w20such that w1 +w2 +…w20 = 1iii. We multiplied each seed point s1, s2…s20by its corresponding weight w1, w2…w20 vialinearalgebraiv. We calculated the new training point, t, by summing s1w1, s2w2,… s20w20 over all pointsv. We repeated steps ii to iv to obtain each training points needed for each criterion.vi. We repeated step i for every set of training points.We convertedeachset of criteriato binary and concatenate as shown in table 2 of section 4. For n criteria for each candidate, the concatenated equivalence is inputted to the input neurons (p1,p2,…pn) of the network and processed by the neural network in the configuration shown below:
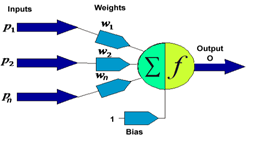 | Figure 2. Conceptual neuron (adopted[25]) |
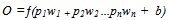 | (1) |
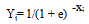 | (2) |
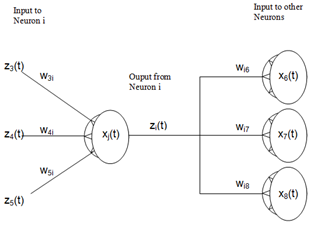 | Figure 3. Conceptual diagram of interconnected neurons (adopted[25]) |
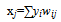 | (3) |
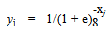 | (4) |
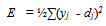 | (5) |
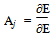 | (6) |
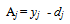 | (7) |
3.2. Choosing the Number of Hidden Neurons
- We used the approaches reported in[16] to choose the number of hidden neurons. This is precisely obtained by dividing the sum of input neurons and output neurons by 2. For this research, 40 input neurons and 1 output neuron per data item were used.
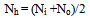 | (8) |
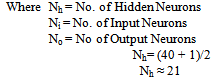 After setting the parameters above, the following steps were taken: Training involved finding the error value for each Output Node which is
After setting the parameters above, the following steps were taken: Training involved finding the error value for each Output Node which is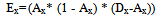 | (9) |
 The Hidden Neuron Error was calculated for each Neuron by totalling each dendrites weight multiplied by its output neurons error. The resultant value was then multiplied by the current neuron’s activation. We then used the Output Error to adjust the weights of the dendrites backward (Back-Propagation) from the Output Neurons to the Input Neurons dendrites. In[16] the new weight of each hidden-output dendrite value was set as shown in equation 10.
The Hidden Neuron Error was calculated for each Neuron by totalling each dendrites weight multiplied by its output neurons error. The resultant value was then multiplied by the current neuron’s activation. We then used the Output Error to adjust the weights of the dendrites backward (Back-Propagation) from the Output Neurons to the Input Neurons dendrites. In[16] the new weight of each hidden-output dendrite value was set as shown in equation 10.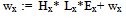 | (10) |
 Above step was repeated with new Weights for each Input-Hidden Dendrite. At this point, the Network was configured for training. Fundamentally, one the reasons for training the network is to derive the input weight and dendrite strength for each neuron at which the network learns from training with training data (benchmark). Once these are derived, the network is saved into a *.nM#) file.
Above step was repeated with new Weights for each Input-Hidden Dendrite. At this point, the Network was configured for training. Fundamentally, one the reasons for training the network is to derive the input weight and dendrite strength for each neuron at which the network learns from training with training data (benchmark). Once these are derived, the network is saved into a *.nM#) file.3.3. Training the Network
- The network was initially tested with a linearly separable problem, in which it learned at about 2000 epochs. This gave a preliminary proof that the network was properly coded and that it could learn. The network started learning after being trained for about 500 epochs. We limited our configuration to 2000 epochs in order to avoid over-learning and memorization of data.
3.4. Running the Network
- The training data (benchmark) and other candidates’ data (data not used during training) were used to run the network. The outputs were then saved into the database.
4. Results
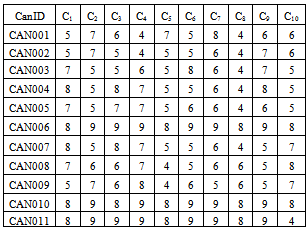
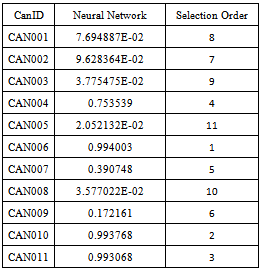
- Table 1 shows the score of each candidate in decimal.The decimal candidate scores on each criterion in Table 1 were converted to binary numbers as shown in Table 2.Table 2 below shows the candidate data, the digitalize data (input) and the output from the neural network.The last column shows the concatenated binary scores for the input into the neural engine. The corresponding output signals are shown in Table 3.These output values show how each tested candidate stood compared with the benchmark. The results show that CAN006 compares best with the benchmark hence the selection order was 1. All other candidates compared with the training data as reflected in their corresponding selection order. Our result showed CAN006 as the best fitting for the benchmark out of all candidates.
|
|
|
5. Conclusions
- In this research, we are cognisant of the limitations that may likely be posed by three factors: insincerity of some candidates about their electoral promises;unavailability of funds to implement the contents of some party’s manifestoes after successful elections andsubjective influence on selection process by “god fathers” as observed within some parties. We noted that these challenges are idiosyncratic and human–created. Therefore, the trend might not be observable in all parties or other spheres of application.Sincesolving themwas not part of the aims of this research, information about them were neitherdeliberately nor directly processed in anyway.Hence, givena sane and safelevel of generalisation within the universe of discourse, this research demonstrated the applicability of synthetic training data to NNfor solving selection problem. The neural network has been able to establish a useful method of selecting candidates for elective offices in Nigeria. There is also the possibility of usageacross political platforms as it is not strongly tied to a specific political system or elective post.It is also believed that the experiment offers an extensible template that may be applicable to solving problems in other spheres of candidate selection for posts aside political offices.