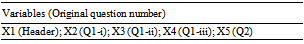-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Information Science
p-ISSN: 2163-1921 e-ISSN: 2163-193X
2013; 3(1): 13-23
doi:10.5923/j.ijis.20130301.03
Leveraging Framework Documentation Solutions for Intermediate Users in Knowledge Acquisition
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLSin-Ban Ho1, Ian Chai2, Chuie-Hong Tan1
1Faculty of Computing and Informatics, Multimedia University, Jalan Multimedia, 63100, Cyberjaya, Selangor, Malaysia
2Faculty of Engineering, Multimedia University, Jalan Multimedia, 63100, Cyberjaya, Selangor, Malaysia
Correspondence to: Sin-Ban Ho, Faculty of Computing and Informatics, Multimedia University, Jalan Multimedia, 63100, Cyberjaya, Selangor, Malaysia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Frameworks are increasingly employed as a useful way to enable object-oriented reuse. However, understanding frameworks is not easy due to their size and complexity. Previous work concentrated on different ways to document frameworks, but it was unclear which ones actually were better. This paper presents a novel way of investigating the different philosophies for framework documentation. The philosophies include minimalist, patterns-style and extended javadoc (Jdoc) documentation. Using a survey of 90 intermediate users engaged in Command and Adaptor design patterns coding work, this exploratory study discovered that minimalist documentation has positive impacts in encouraging knowledge acquisition, significantly in terms of the framework functional workings. This concludes that documentation solutions with the minimalist principle can lead intermediate users to faster growth in learning two of the design patterns.
Keywords: Framework Documentation, Knowledge Acquisition, Patterns
Cite this paper: Sin-Ban Ho, Ian Chai, Chuie-Hong Tan, Leveraging Framework Documentation Solutions for Intermediate Users in Knowledge Acquisition, International Journal of Information Science, Vol. 3 No. 1, 2013, pp. 13-23. doi: 10.5923/j.ijis.20130301.03.
Article Outline
1. Introduction
- One of the key challenges to object-oriented frameworks is introducing the design patterns to intermediate users. Intermediate users are those who have already had some experience with the framework in question but not yet experts, i.e. they are between the novice and advanced levels. The subjects would perform the coding details of a particular portion of the code while the instructor ensures that the coding exercise is being followed with the help from the check-point time made available in the documentation.This paper reports and discusses results from an empirical study on framework documentation. This practice populates a documentation model with the necessary technical and development how-to’s to get the task done[1]. The general problem of how to document framework is large. The scope of this research work is to tackle intermediate user documentation or tutorials.
2. Motivations of the Study
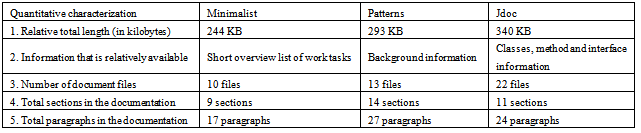
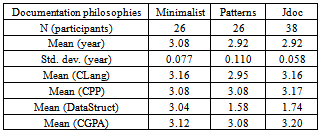
- One of the earliest works on empirical study in software environments is the goal/question/metric (GQM) goal template proposed by Basili and Rombach[2]. There are tendencies where instantiated goals show certain similarities. The purpose of using GQM paradigm is to refine the goals into quantifiable, reducing complexity and putting in knowledge learned from previous experiments. Basili et al. [3] provide the following five parameters in a GQM goal template:(a) Object of study: a process, product or any other experience model.(b) Purpose: to characterize (what is it?), evaluate (is it good?), predict (can one estimate something in the future?), control (can one manipulate events?), improve (can one improve events?)(c) Focus: model aimed at viewing the aspect of the object of study that is of interest, such as reliability of the product, defect detection/prevention of the process, accuracy of the cost model.(d) Point of view: the perspective of the person needing the information, e.g. in theory testing the point of view is usually the researcher trying to gain some knowledge.(e) Context: models aimed at describing the environment in which the measurement is taken.Selecting a particular type of process for study, the GQM template then becomes: Analyse framework documenting techniques to evaluate their effectiveness on a product from the point of view of the knowledge builder in the context of a particular domain. For some widely-used frameworks like Swing[4], educators may write more easily-understood documentation to teach less-experienced programmers.Studies in pedagogical documentation show that the behaviour in organising a programming guide is a domain that has been used to describe the manner how beginners learn how to use a framework. For some time, studies have reported behaviour differences in pedagogical framework documentation. The three philosophies being evaluated in this study include minimalist[5], patterns-style[6,7] and extended javadoc documentation[8,9]. Each is compatible with the idea of mixing texts, examples and diagrams.John Carroll’s innovation, minimalist documentation, is based on the idea that people do not want information irrelevant to the task at hand. This idea attempts to give the reader the minimal amount of information to get the task done, and arrange it in short pages or index cards of information so that users can read in whatever order suits them[5]. As each minimalist page or card contains little information, they often refer to other pages or cards. Hence, they lend themselves well to hypertext presentations like the Web. Carroll gives these guidelines for minimalist documentation:● Training on real tasks: people are more motivated to do an exercise when it relates directly to something useful they want to do.● Getting started fast: if there is too much to read before readers get to typing something on the computer, they will lose interest and miss things.● Reading in any order: topics are brief and allow readers to choose whatever order seems best to them.● Coordinating system and training: instead of giving all the detailed steps, let the learner interact with the system.● Supporting error recognition and recovery: instead of giving step-by-step instructions that assume readers will repeat flawlessly, expect them to fail and give them the resources to understand how to recover.● Exploiting prior knowledge: instead of using insider jargon, use analogies to readers’ prior experience to help them understand.● Using the situation: take advantage of the expectations learners bring to the situation.Most documentation focuses on specific computer software. These sources typically tell how people are supposed to perform tasks, not what they actually do[10]. In conjunction with this purpose, one of the objectives of a pattern is to get readers to understand some of the rationale for the solution, so that they can decide when to apply the pattern. A definition commonly used at Pattern Languages of Programs (PLoP) conferences for patterns is:A pattern is a proven successful solution to a recurring problem in a context.Patterns lend themselves well to hypertext presentations such as those found on the Web, since they refer to other patterns when a problem or its solution is too big to discuss in one sitting. Meszaros and Doble[11] said that patterns should have these elements:● Pattern Name: so that people can refer to the pattern.● Problem: a lengthy description of the problem it solves.● Solution: there may be different solutions to the same problem depending on the context. A prescription for how it works.● Context: the circumstances of the problem impose constraints on the solution.● Forces: often contradictory considerations that must be taken into account when choosing a solution to a problem.Clements et al.[12] said that the patterns style should consist of partial design solutions found repeatedly in actual practice. As mentioned above, patterns also provide background information (the context) and not just the raw solution. We present this background information first, before the how does it work section, where the readers may follow to apply the solution to an actual system. Patterns style addresses the application-specific problem in a specific context. It proposes a development solution that can serve as the basis for teaching intermediate users how to reuse components available within a framework.Jdoc incorporates the HTML documentation generated by the javadoc tool. The class information, such as inheritance and subclasses are provided at the top of the Jdoc. This is followed by a textual description of the class, constructors and methods, which contain their pseudo code with hypertext links to the particular steps. Erik Berglund[8] centred much of his library communication work on the Java programming language domain and javadoc tool that provides automatic generation of reference documentation from Java source files. The javadoc tool represents the state of the art in automated documentation generation and online reference documentation.The minimalist documentation only provides the information directly relevant to the task at hand. The patterns documentation in addition provides background information that explains the context in which the solution should be applied. The Jdoc documentation provides classes, inheritance and methods information, which are not found in both minimalist and patterns documentation.Table 1 summarizes some key points of the documentation philosophies. Each of these philosophies sounds reasonable from their description. Each documentation philosophy is compatible with the idea of testing one’s documentation on end-users and making changes based on their reactions. Each of them is open to the idea of mixing text, examples, and diagrams.
|

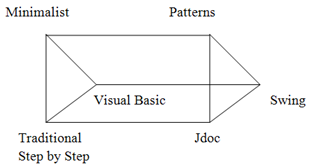 | Figure 1. Information spectrum of a knowledge acquisition model |
3. Experiment Description
- This research work used an exercise-based research typically used in empirical software engineering. One of the main components of the research methodology is exercise-based investigation, which was preceded with the presentation of a certain documentation set. Overall, it consists of the following four activities:● Activity I: Forming the research question and formulating hypotheses based on the relevant literature.● Activity II: Developing the documentation sets to test the hypotheses.● Activity III: Building the exercise instrument and the collection of data through exercises.● Activity IV: Analysis of the data collected as part of Activity III.The formulated hypotheses were used to design the documentation sets and the respective exercise, which were pre-tested for usability, soundness, and readability before it was rolled out for collecting data from the field. The data collected were then statistically analysed using suitable data analysis techniques.
3.1. Documentation Procedure
- The documentation procedure of Figure 2 is composed of five steps. In the first step, we manually identify which tutorial that would correspond to the work task discussed in the textbook[19]. The textbook provides the rationale for the work task, supporting the scenario in demonstrating the Command and Adaptor (CmdAdp) design patterns.
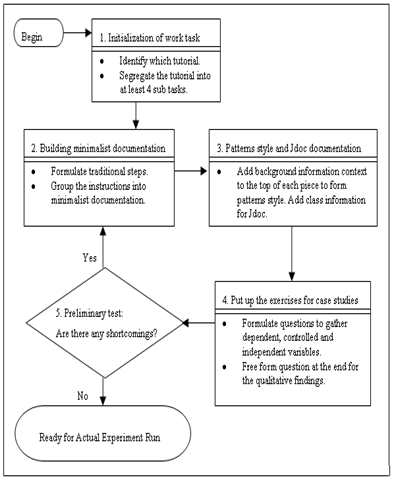 | Figure 2. An overview of the documentation procedure |
 | Figure 3. Examples of the documentation fragment which was presented in all the three documentation groups |
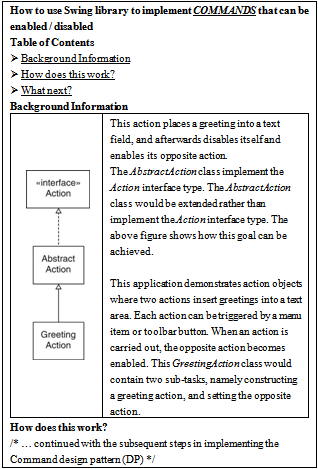 | Figure 4. Example of the documentation fragment that is available in the patterns style documentation, but not available in the minimalist and Jdoc documentation |
 | Figure 5. Example of the documentation fragment that is available in the Jdoc documentation, but not available in the minimalist and patterns style documentation |
|
3.2. Hypotheses
- Standard significance testing is used to clearly specify the effects of the three documentation philosophies. The null hypotheses are stated as follows.E1H0 - There will be no difference between patterns and minimalist documentation for the intermediate users in doing the same exercise.E2H0 – There will be no difference between patterns and Jdoc documentation for the intermediate users in doing the same exercise.E3H0 – There will be no difference between minimalist and Jdoc documentation for the intermediate users in doing the same exercise.The interpretations of the experiment are derived from the rejection or non-rejection of these hypotheses for each expectation.
3.3. Participants
- There are 90 participants in this study. 33 (36.7%) are female and 57 (63.3%) are male, with the mean years in the university of 2.97, and SD of 0.436, a minimum 2 years and maximum 4 years in the university. Participants are all information technology undergraduates who undergo the object-oriented programming course at the university. The normal age of the students at this level is 22 years old.To be able to test the hypotheses of our experiment, three different groups of the CmdAdp documentation are required. We arrange the participants into three different groups, according to their tutorial sections. Table 3 shows more detailed information about the groups.
|
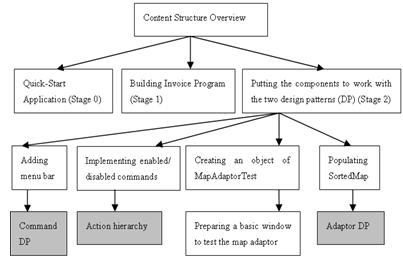 | Figure 6. Overview of the content structure. The grey boxes are UML diagrams |
3.4. Procedure (Tasks)
- The pedagogical documents are developed on a workstation using an html editor such as Dreamweaver. These documents are subsequently uploaded to a web server so that the users can access the on-line documentation. Before the experiment begins, a digital clock is displayed on the projector for the subjects’ common reference.Our method of observation consists of a survey with two sections. The subjects receive this survey printed on paper. The first section requests the subjects to record their completion time after each task, while the second section includes eleven post mortem questions of various types including multiple-choice, ratings and free-form question. The responses to this free-form question raised by more than two subjects are recorded as qualitative findings. These responses are delivered in handwriting. However, the overall amount of the text written is small, so handwriting speed is not a limiting factor.
3.5. Experimental Design
- Our experimental design uses one independent variable (factor) and six dependent variables. The independent variable consists of the documentation group. The dependent variables are the completion time, number of difficulties faced, semi completion time, workings and comprehension (understanding of the exercise).Independent variables:Documentation type: We use three documentation philosophies, as described in section 1, each with a similar purpose: to complete the given work task.Dependent variables:Semi Completion time: Time taken for the subjects to do their first compilation.Completion time: The time taken to finish the entire exercise.Comprehension: The subjects have to identify the method, procedure, line of the code, and constants that perform the given task. There are a number of questions to test their understanding of the code.Workings: This is to test how well the subjects are able to follow the instructions for assigning default settings to the CmdAdp components.Number of difficulties faced: Instead of giving all the detailed steps, some parts of the documentation let the learners interact with the system. The subjects are to record and accumulate the number of problems they encounter.Appendix A provides the exercise of the experiment. This gives a more specific description on what the exercise ask for the dependent variables and how they are measured. The data collected from this experiment is discrete, either right or wrong for a particular question. This evaluation approach is a kind of examination or exercise, not a survey of opinions. Thus, factor analysis for convergent validity is not required for these direct observable variables[22,23]. The validation of these variables is well supported with their propositional discrete nature[24], i.e. the exact total of correct answers and factual nature, such as the exact completion time of various tasks.
3.6. Validity
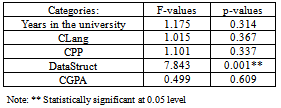
- Internal validity is the degree to which conclusions can be drawn about the casual effect of independent variables on the dependent variable. To see whether the groups differ significantly, we perform ANOVA tests on the three groups of participants. In Table 4, with all the p-values > 0.05, except for the Data Structures and Algorithms course that they took in the prior semester, there is no major significant difference detected. The random assignments of the three tutorial groups are balanced in terms of their years in the university, the courses like C and C++ language, and Cumulative Grade Point Average (CGPA).
|
4. Data Analysis, Results and Discussion
4.1. Statistical Analysis on the Results
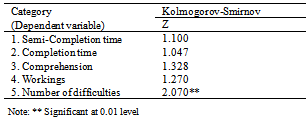
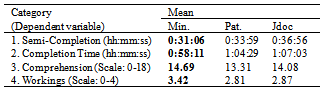
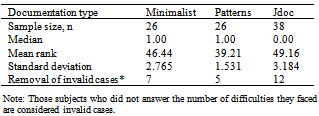
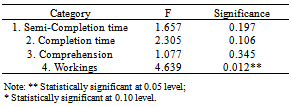
- Statistical analyses are conducted using Statistical Package for Social Science (SPSS). The results are based on the sample of 90 responses. The data is analysed to see if one of the documentation sets let the participants compile (Semi-Completion) and finish the fastest (Completion) with the number of difficulties recorded by the subject at these intervals (Number of difficulties), as well as understand the most (Comprehension). We also check for test scores on how well their knowledge in the inner workings of the framework (Workings). Since we do not want to rely on the assumption of normal distribution, we test for the normality of the dependent variables. From the normality test in Table 5, we discover that all dependent variables except Number of difficulties are normally distributed for each participant group. Thus, for this dependent variable, medians will be used as the expected values, rather than the means, as shown in Table 6 and Table 7. There exists a small outlier and we have checked that the results are resilient to the removal of the outlier.
|
|
|
|
|

4.2. Regression Model for Future Prediction
- In order to further validate the various points, let us build the regression model[29]. We extract the models to predict future data trends for continuous valued functions[30] with the assumption that the determinant is linearly related to the factors. The proposed model for regression testing is explained by Greene[31] and Gujarati[32], which can be denoted by the following basic form:
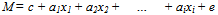 | (1) |
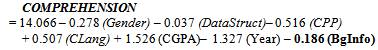 | (2) |
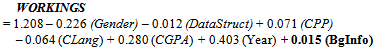 | (3) |
 | (4) |
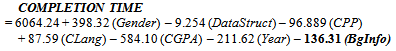 | (5) |
5. Conclusions
- In this work, a set of philosophies for organizing pedagogical textual and graphical information on the CmdAdp documentation has been proposed. This work reveals the missing salient variable in the recent individual differences study by Graff[33], i.e. the time users spent at each page of hypertext. From the results, we realize that the effects of the patterns style documentation are not supreme all the time. Perhaps, for intermediate users, patterns are not always the best. Furthermore, Pressman[1] suggested that patterns are not suitable for every situation. Interestingly, minimalist documentation shows an overwhelming advantage in terms of the intermediate users' completion speed and comprehension in fulfilling requirements.The quantitative results show that minimalist documentation did not have a significant impact on the time and comprehension that it took to perform the programming tasks. Nevertheless, in terms of the functional workings of the framework, minimalist documentation had a practically and significantly positive impact, in spite of the fact that the participants were not experts in applying design patterns into programming tasks. The aim of using the most effective documentation is to provide intermediate users with a good process that will lead to faster growth in learning the CmdAdp design patterns. All these results demonstrate the behaviours of CmdAdp intermediate users in using pedagogical framework documentation.
ACKNOWLEDGEMENTS
- The study described in this paper would not be possible without the cooperation and willingness of the experimental subjects and course tutors. The authors also thank the anonymous reviewers for their valuable suggestions that improved the paper.
APPENDIX
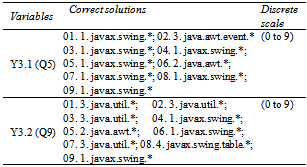
- the exercise itemsNote: (Qn) refers to the original question number in the exercise. The dependent variables are numbered with prefix ‘Y’, while the demographic characteristics are numbered with prefix ‘X’.Section 1. Documentation on the Command and Adaptor ProgramY0 to Y2, Y5: Check point time, Completion time and the Number of DifficultiesPlease record time as ‘hh:mm:ss’:
 Section 2. Tutorial Exercise on the Command and Adaptor ProgramY3: Comprehension (Understanding of the exercise)Y3.1: In Command DP code, indicate the respective package that provides the listed class/interface. Answer with numbering: 1. javax.swing.*, 2. java.awt.* or 3. java.awt.event.*
Section 2. Tutorial Exercise on the Command and Adaptor ProgramY3: Comprehension (Understanding of the exercise)Y3.1: In Command DP code, indicate the respective package that provides the listed class/interface. Answer with numbering: 1. javax.swing.*, 2. java.awt.* or 3. java.awt.event.*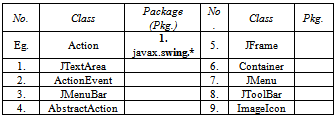 Y3.2: In Adaptor DP code, indicate the respective package that provides the particular class. Answer with respective numbering: 1. javax.swing.*, 2. java.awt.* 3. java.util.* or 4. javax.swing.table.*
Y3.2: In Adaptor DP code, indicate the respective package that provides the particular class. Answer with respective numbering: 1. javax.swing.*, 2. java.awt.* 3. java.util.* or 4. javax.swing.table.*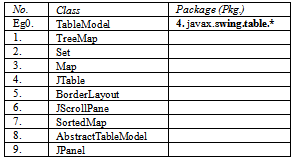
 Y4: WorkingsY4.1: In CommandTest code, the text appears when goodbyeAction is selected: ________________Y4.2: In your CommandTest program, indicate the title name of the window: ________________Y4.3: Initially, size set for MapAdaptorTest frame: x: _______ pixels; y: ________ pixelsY4.4: The code to suit MapAdaptorTest frame into its components’ size: ____________________
Y4: WorkingsY4.1: In CommandTest code, the text appears when goodbyeAction is selected: ________________Y4.2: In your CommandTest program, indicate the title name of the window: ________________Y4.3: Initially, size set for MapAdaptorTest frame: x: _______ pixels; y: ________ pixelsY4.4: The code to suit MapAdaptorTest frame into its components’ size: ____________________ FX: Demographic CharacteristicsX1: Gender*: Male / FemaleLegend: * Please circle one of the items above.X2 to X4: What grade did you obtain for the following subjects: (state your answer as far you can recall)
FX: Demographic CharacteristicsX1: Gender*: Male / FemaleLegend: * Please circle one of the items above.X2 to X4: What grade did you obtain for the following subjects: (state your answer as far you can recall) X5: Indicate your CGPA thus far: _______________
X5: Indicate your CGPA thus far: _______________