-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Information Science
p-ISSN: 2163-1921 e-ISSN: 2163-193X
2012; 2(6): 75-78
doi: 10.5923/j.ijis.20120206.02
Pseudonmization Techniques for Privacy Study with Clinical Data
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLYahaya Abd. Rahim , Shahrin Sahib , Mohd Khanapi Abd Ghani
Fac. of Information & Communication Technology, Universiti Teknikal Malaysia Melaka, UTeM, Durian Tunggal, 76109, Malaysia
Correspondence to: Yahaya Abd. Rahim , Fac. of Information & Communication Technology, Universiti Teknikal Malaysia Melaka, UTeM, Durian Tunggal, 76109, Malaysia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Privacy includes the right of individuals and organizations to determine for themselves when, how and to what extent information about them is communicated to others. The growing need of managing large amounts of data in hospital or clinical raises important legal and ethical challenges. This paper introduces and show the testing implementation of the privacy-protection problems, and highlights the relevance of trusted third parties and of privacy-enhancing techniques (PETs) in the context of data collection, e.g., for research. Practical approaches on the pseudonymization model for batch data collection are presented. The actual application of the described techniques today proves the possible benefits for health that innovative privacy-enhancing techniques can provide. Technical PET solutions can unlock valuable data sources, otherwise not available.
Keywords: Pseudonmization, Privacy, Privacy-Enhancing Technique
Cite this paper: Yahaya Abd. Rahim , Shahrin Sahib , Mohd Khanapi Abd Ghani , "Pseudonmization Techniques for Privacy Study with Clinical Data", International Journal of Information Science, Vol. 2 No. 6, 2012, pp. 75-78. doi: 10.5923/j.ijis.20120206.02.
Article Outline
1. Introduction
- Organizations like hospitals, clinics or pharmacies collect, store and process vast amounts of personal data. They are interested in releasing their data for research or other public benefit purposes. However, much of this data is of a sensitive nature (e.g. medical data) and although generally used for the benefit of the community, it can be easily abused by malicious people.Currently incidents are frequently reported in the public media, but lack of concern about the sensitive data. However, people tend to become more apprehensive when their personal healthcare-related data are at stake, mainly because they can easily imagine motives for abuse and understand the impact of such abuse. Another obvious case in point is that at some point in their life practically everyone is confronted with loan and insurance applications. Recent incidents such as the one in which an outsourced transcribers’ threatened to disclose all medical records she had been processing for a US hospital[1] clearly illustrate that the threat to privacy is genuine. Public authorities are also sharply aware of these repercussions, and they are putting considerable effort into privacy protection legislation[2, 3]. Nowadays, we can’t deny that privacy protection directly impacts personal well-being as well as society as a whole. Indeed, some go as far as to believe that failure to protect privacy might lead to our ruin[4]. Privacy is in fact recognized as a fundamental human right.In Malaysia; until now there are no special bodies that are pay careful attention to the requirement of obtaining the informed consent from subjects. Because of that, most of the hospital or clinical are too caution regarding assessing their information because they known the impact of the information enclosed are very complex; thus a real danger that informed consent is rather an ill-informed consent. Research ethics and security guidelines demand research units to divert more and more resources and time to privacy and identity protection, but burdensome requirements governing the transmission of medical information could unnecessarily discourage research. Well-intentioned privacy laws should not clash with the legitimate use of information when clearly to the public’s benefit.Protecting human rights, for example, privacy, while maximizing research productivity is a major challenge. A first step towards this goal is the research and implementation of technical solutions to the privacy problem. Privacy-enhancing techniques or technologies (PETs) should be provided with to unlock invaluable data sources for the benefit of society without endangering individual privacy.This paper focuses on the possible use of privacy enhancing techniques in the context of research and statistics for health care.
2. Privacy Enhancing Techniques
- There are many situations in which privacy can be an issue. Until now, much research covers many different areas, including anonymous: • Communication (anonymous remailers, anonymous surfing, etc.),• Transactions,• Publication and storage,• Credentials,• In files and databasesIn this paper focusing is more to medical applications, in which privacy issues are raised by the information content of the stored data. Privacy-enhancing techniques for privacy protection within databases help us to protect the privacy of a subject of a database record like person records or organization records that listed in the database. Simply put, these privacy-enhancing techniques allow storing relevant and useful information in a way that no one can ever find out, who the information is actually about. Lists are some of the examples of these techniques are (non exhaustive list):• ‘‘Hard” de-identification by the owner of the data;• Various types of anonymization and/orpseudonymization;• Privacy risk assessment techniques;• Controlled database alteration (modification, swapping or dilution of data);• Data flow segmentation;Today, privacy-enhancing technique technology has already proven its usefulness for privacy protection in marketing and research data collection in United State[5] and even in Malaysia or other Asia countries like Singapore, Japan and etc, the (PETs) is growing up parallel with the countries urbanization. However in this paper, our focus with the lays on implementation of pseudonymization techniques, and complementary PETs enhancing with clinic environment in Malaysia country; and our experiment is one of the public hospital, in south city.
3. Pseudonymization Techniques
- Pseudonymization refers to privacy-enhancing techniques and methods used to replace the true (nominative) identities of individuals or organizations in databases by pseudo-identities (pseudo-IDs) that cannot be linked directly to their corresponding nominative identities[6].With this technique, the data that contains, identifiers and ‘‘payload data” (non-identifying data) are separated. The pseudonymization process translates the given identifiers into a pseudo-ID by using secure, dynamic and preferably irreversible cryptographic techniques (the identifiertransformation process should not be performed with translation tables). For an observer, the resulting pseudo-Ids are thus represented by complete random selections of characters. This transformation can be implemented differently according to the project requirements. Pseudonymization can:• always map a given identifier with the same pseudo-ID;• map a given identifier with a different pseudo-ID;• time-dependant (e.g. always varying or changing over specified time intervals);• location-dependant (e.g. changing when the data comes from different places);• content-dependant (e.g. changing according to the content);Pseudonymization is used in data collection scenarios where large amounts of data from different sources are gathered for statistical processing and data mining (e.g. research studies). In contrast with horizontal types of data exchange (e.g. for direct care), vertical communication scenarios (e.g. in the context of disease management studies and other research) do not require identities as such: here pseudonymization can help find solutions. It is a powerful and flexible tool for privacy protection in databases, which is able to reconcile the two following conflicting requirements: the adequate protection of individuals and organizations with respect to their identity and privacy, and the possibility of linking data associated with the same data subject (through the pseudo-IDs) irrespective of the collection time and place.Because of this flexibility, however, correct use of pseudonymization technology is not as straightforward as often suggested. Careless use of pseudonymization technology could lead to a false feeling of privacy protection. The danger mainly lies within the separation of identifiers and payload. The important things that should be alert before we precede this process make sure that payload data does not contain any fields that could lead to indirect re-identification, i.e. re-identification based on content, not on identifiers. The key to good privacy protection through pseudonymization is thus careful privacy assessment. Privacy gauging or privacy risk assessment is measuring the risk that a subject in a ‘‘privacy protected” database can be re-identified without cooperation of that subject or against his or her will. This consists in measuring the likelihood that a data subject could be re-identified using the information that is available (hidden) in the database. The lower this re-identification risk, the better the privacy of the subject listed in that database is protected. Conducting a privacy analysis is a difficult task. At this point in time, no single measure for database privacy is fully satisfying and this matter is still a hot topic in scientific communities. However, extensive research, mainly conducted by statisticians (area of statistical databases, etc.) and computer scientists like data miners or security experts are making significant progress.From our literature view, using privacy risk assessment techniques, pseudonymization performance can be guaranteed. Data collection models are used to estimate the risk level for re-identification by attackers (a priori risk assessment). How the data should be separated (identifiers versus payload), filtered (removal of information) and transformed (transforming payload information in order to make it less identifying) is subsequently determined on the basis of these results. This means that in fact that one of the uses of privacy risk assessment techniques is to determine correct configuration of PETs. Many more aspects of the pseudonymization process are closely linked and key to ensuring optimum privacy protection, as for example, the location of the identifier and payload processing, the number of steps in which the pseudonymization is performed.
4. Pseudonymization Implementations
- The pseudonymization as described above provides privacy protection for data collection for research and market studies. Two logical entities involved in handling the data are:1. The data suppliers or ‘sources’;2. The data collectors, one or several ‘data registers’ where the pseudonymized data are stored. Data suppliers typically have access to nominative data (e.g. treating doctors), the data collectors should only have access to anonymous data.
4.1. Batch Data Collection
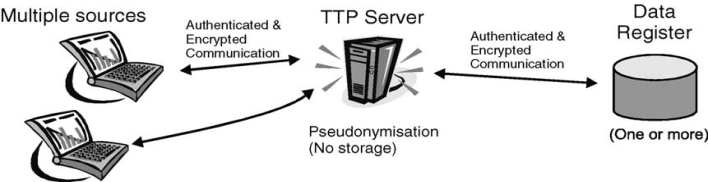 | Figure 1. Communicating Entities |
5. Conclusions
- Privacy includes the right of individuals and organizations to determine for themselves on when, how and to what extent information about themselves can be communicated to others. Several types of privacy-enhancing technologies exist that can be used for the correct treatment of sensitive data in health, but in this paper we focus that advanced pseudonymization techniques can provide optimal privacy protection of individuals. The research also shows that the privacy-enhancing techniques currently deployed for medical research, which proves that the use of pseudonymization and other innovative privacy enhancing techniques can unlock valuable data sources, otherwise legally not available.