-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Information Science
p-ISSN: 2163-1921 e-ISSN: 2163-193X
2011; 1(1): 32-35
doi: 10.5923/j.ijis.20110101.05
Context Free Data Cleaning and its Application in Mechanism for Suggestive Data Cleaning
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLSohil D. Pandya 1, Paresh V. Virparia 2
1MCA Department, Sardar Vallabhbhai Patel Institute of Technology (SVIT), Vasad, 388306, India
2G H Patel PG Dept. of Computer Science & Technology, Sardar Patel University, Vallabh Vidyanagar, 388120, India
Correspondence to: Sohil D. Pandya , MCA Department, Sardar Vallabhbhai Patel Institute of Technology (SVIT), Vasad, 388306, India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Organizations are being flooded with massive transactional data. This data is of no use, if not analysed properly, to reach to any strategic decision and ultimately to achieve competitive advantage. The efficient data analysis is one of the success strategies. The analysis is highly dependent on the quality of the data. The clean data will lead to efficient data analysis. In this paper, authors suggest application of similarity metrics in context free data cleaning and a mechanism to suggest correct data based on learning from patterns derived in the prior phase. The sequence similarity metrics like Needlemen-Wunch, Jaro-Winkler, Chapman Ordered Name Compound Similarity and Smit-Watermen are used to find distance of two values. Experimental results show that how the approach not only effectively cleaning the data but suggesting suitable values in order to reduce the data entry errors.
Keywords: Context Free Data Cleaning, Similarity Metrics
Cite this paper: Sohil D. Pandya , Paresh V. Virparia , "Context Free Data Cleaning and its Application in Mechanism for Suggestive Data Cleaning", International Journal of Information Science, Vol. 1 No. 1, 2011, pp. 32-35. doi: 10.5923/j.ijis.20110101.05.
Article Outline
1. Introduction
1.1. Data Cleaning
- Organizations are being flooded with massive transactional data every year. This data needs to be analysed carefully to achieve competitive advantage in order to achieve excellence. Some organizations have moved to and others are moving to develop business intelligence solutions by analysing this data, identifying patterns among them, and deciding strategies after evaluating the patterns. The efficiency and reliability of this analysis relies heavily on the quality of the data. The data quality measures like completeness, valid, consistent, timeliness, accurate, relevance etc. allow quantifying data in order to achieve high performance results of various data analyses. Because of human interventions and computations at various levels, noise is added in data before it got stored[4]. Noise is “irrelevant or meaningless data”[1], which leads to deterioration of outcome of data[2]. The data cleaning processes mainly focused on detection and removal of noise. Using Similarity Metrics in data cleaning process to identify and replace incorrect sequence with correct sequence based on distance between them is an interesting way of cleaning of data[5]. Here, the distance for various similarity may be based on numbers of characters, number of replacements needed to convert one sequence to another, number of re-arrangements required, most similar characters, any combinations of all above, etc. the distance between two sequence ranges from 0.0 to 1.0. For example,the distance between “Malaysia” and “Mallayssia” for various similarity metrics is shown in table 1.The purpose of this paper is to demonstrate application of similarity metrics in context free data cleaning and again use the learned knowledge in further cleaning. Authors developed the algorithm and function – cleanAssit to perform the said job. The later section of the paper describes the algorithm and function & their experimental results.
|
1.2. Related Work
- With the usage of similarity metrics, Lucasz have proposed and implemented algorithm by using Levensthein Distance[2]. He suggested usage of data mining techniques like clustering and classification for context dependent and context free cleaning of data. He later used more factors for optimizing results.Hui-Zen, et-al. has suggested Data Cleaner for cleaning large databases.[1]Authors themselves extended the technique suggested by Lucasz (by experimenting various similarity metrics, their permutations, etc.) and make appropriate changes for improved cleaning. Authors also extended the concept to develop a mechanism that would suggest users the best possible correct sequence based on their response. These best possible correct sequence will be decided by –(1) The sequence set which was generated by the context free data cleaning.(2) Users support and confidence to accept/reject the suggestions. The above said process will deliver effective results as more usage by users and gradually by learning from users. Over a period of time the system become more & more mature enough to generate near to perfect results.
2. Algorithm
2.1. Assumption
- 1. Typographic errors are less (ranges 5% to 20%) and similar in nature.2. Results may depend upon dataset is to be cleaned and the distance metric is to be used.
2.2. Important Terms
- 1. The function M : S x S
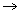 R2 is a distance metric between the elements of the set S, such that M (sm, sn) = (dmn, rmn)Where, dmn = Dw (vm,vn), dmn
R2 is a distance metric between the elements of the set S, such that M (sm, sn) = (dmn, rmn)Where, dmn = Dw (vm,vn), dmn 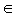 (0,1) (Dw is measure of similarity between two text strings)
(0,1) (Dw is measure of similarity between two text strings)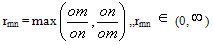 2. Similarity relation ‘~’ over the set is a relation defined in that way that:
2. Similarity relation ‘~’ over the set is a relation defined in that way that: 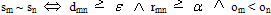 , where is
, where is 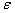 threshold distance - acceptableDist and
threshold distance - acceptableDist and 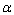 is occurrence ratio - occurRatio.3. pc = (nc / na) * 100 (percentage of correctly altered values)4. pi = (ni / na) * 100 (percentage of incorrectly altered values)5. p0 = (n00 / n0) * 100 (percentage of values marked during the review as incorrect, but not altered during cleaning)(where nc is number of correctly altered values, ni is number of incorrectly altered values, na is total number of altered values, n00 is the number of elements marked as incorrect during the review process that were not altered, n0 is the number of values identified as incorrect)6. CleanAssist is a function, which suggests reference data generated during context-free cleaning process has following features:a. For Correct Input – It suggests most similar suggestion with high updated frequency and confidence.b. For Wrong Input – i. Historical Mistakes – It suggest the most correct texts based on previous mistakes and also updates if user accepts.ii. New Mistakes – It suggests the most matches by matching the entered string with previous mistakes and correct values based on distance threshold and also remember new mistakes. Next, if the user has done the same mistake, it will take it as a historical mistake.
is occurrence ratio - occurRatio.3. pc = (nc / na) * 100 (percentage of correctly altered values)4. pi = (ni / na) * 100 (percentage of incorrectly altered values)5. p0 = (n00 / n0) * 100 (percentage of values marked during the review as incorrect, but not altered during cleaning)(where nc is number of correctly altered values, ni is number of incorrectly altered values, na is total number of altered values, n00 is the number of elements marked as incorrect during the review process that were not altered, n0 is the number of values identified as incorrect)6. CleanAssist is a function, which suggests reference data generated during context-free cleaning process has following features:a. For Correct Input – It suggests most similar suggestion with high updated frequency and confidence.b. For Wrong Input – i. Historical Mistakes – It suggest the most correct texts based on previous mistakes and also updates if user accepts.ii. New Mistakes – It suggests the most matches by matching the entered string with previous mistakes and correct values based on distance threshold and also remember new mistakes. Next, if the user has done the same mistake, it will take it as a historical mistake.2.3. Algorithm – Context Free Data Cleaning
- The algorithm has two important components - clustering and similarity and two important parameters acceptableDist (which is a minimum acceptable distance required during matching and transformation) and occurRatio (as defined in 2.2). To measure the distance we experimented on following Similarity Metrics:1. Needlemen-Wunch2. Jaro-winkler
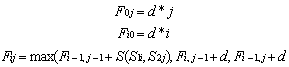 3. Smith-Watermen4. Chapman Ordered Name Compound SimilarityThe Needleman-Wunch algorithm, as in (1) performs a global alignment on two sequences and commonly used in Bioinformatics to align protein sequences[6]. Where S (S1i, S2j) is the similarity of characters i and j; d is gap penalty. The Jaro-Winkler distance, as in (2), is the major of similarity between two strings[6]. It is a variant of Jaro distance[6].
3. Smith-Watermen4. Chapman Ordered Name Compound SimilarityThe Needleman-Wunch algorithm, as in (1) performs a global alignment on two sequences and commonly used in Bioinformatics to align protein sequences[6]. Where S (S1i, S2j) is the similarity of characters i and j; d is gap penalty. The Jaro-Winkler distance, as in (2), is the major of similarity between two strings[6]. It is a variant of Jaro distance[6].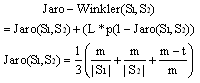 | (2) |
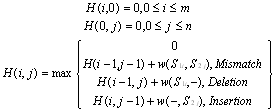 | (3) |
2.4. Function– CleanAssit
- After the first and/or sub-sequential run for various data set the function – cleanAssit is incorporated in the system so as to suggest the correct data values. This function has features as discussed in 2.2.Call these steps when user entered string changes –(1) For the entered sequence of text, display the matching comparators.(2) If the results are not found in step-1, then display the matching comparables. Also make necessary updates, if user selects the comparable, in frequency and confidence of comparables and comparators.(3) If the results are not found in step-2, then display the most matched comparator by matching entered text to comparators and/or comparables based on acceptableDist. Also make necessary inserts with entered sequence and selected comparator.
2.5. Implementation
- The implementation of the above algorithm and function is done using NetBeans IDE in Java language with back-end as MySQL.
2.6. Experimental Results & Discussion
- The experimental results and discussion is section 3.
2.7. Limitations
- a. The reference set generated during context-free data cleaning.b. The support and confidence of the user on selecting/rejecting the suggestions.
2.8. Applications
- 1) Cleaning of data where reference data set is not available or difficult to construct.2) Natural Language Processing.3) Genetics to identify matching and/or replacement of sequence.4) Spell Checkers5) Understanding the demographic mindsets of data entry operators in injecting data to the system.
2.9. Future Scope
- 1) This algorithm can be extended in the direction of automatic selection of similarity metric based on the nature of the data.2) The algorithm may allow little intervention of user before transforming of comparable to comparator (it may be time consuming, but can be allowed as it is not a daily process).3) The cleanAssist function can be optimized and linked with real world data, if available.
3. Experimental Results & Discussion
- To test the above algorithm and function, authors have used data downloaded from Internet. The data has following attributes – student id, name, address, city, district, state, country, phone no, and email address. The experiment was done on district attribute. The experimental results were tested for the measures pc, pi, and p0 (as discussed in 2.2).
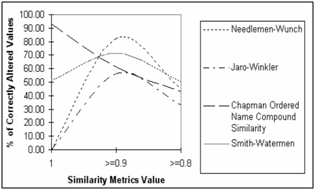 | Figure 1. Percentage of correctly altered values. |
 | Figure 2. Example of context free data cleaning by an algorithm. |
 | Figure 3. Example of suggestions by cleanAssist. |
4. Conclusions
- The above said algorithm, its implementation and results were motivating. Still there are future scope lies in the said mechanism (as discussed in 2.8). Authors wish to apply above algorithm in various applications (as discussed in 2.7) and test the applicability. Overall the algorithm and function helps to clean the data where reference data set is not available.