-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Brain and Cognitive Sciences
p-ISSN: 2163-1840 e-ISSN: 2163-1867
2013; 2(5): 63-75
doi:10.5923/j.ijbcs.20130205.01
P300 Detection Using a Multilayer Neural Network Classifier Based on Adaptive Feature Extraction
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLArjon Turnip1, Sutrisno Salomo Hutagalung2, Jasman Pardede3, Demi Soetraprawata1
1Technical Implementation Unit for Instrumentation Development, Indonesian Institute of Sciences, Bandung, 40135, Indonesia
2Research Center for Calibration, Instrumentation and Metrology Indonesian Institute of Sciences, Tangerang Selatan, Indonesia
3Department of Informatics Engineering, Faculty of Industrial Technology, National Institute of Technology, Bandung, Indonesia
Correspondence to: Arjon Turnip, Technical Implementation Unit for Instrumentation Development, Indonesian Institute of Sciences, Bandung, 40135, Indonesia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
This paper proposes two adaptive schemes for improving the accuracy and the transfer rate of EEG P300 evoked potentials: a feature extraction scheme combining the adaptive recursive filter and the adaptive autoregressive model and a classification scheme using multilayer neural network (MNN). Using the signals extracted adaptively, the MNN classifier could achieve 100% accuracy for all the subjects, and its transfer rate was also enhanced significantly. The proposed method may provide a real-time solution to brain computer interface applications
Keywords: Brain Computer Interface, EEG-based P300, Adaptive Feature Extraction, Classification, Neural Network, Accuracy, Transfer rate
Cite this paper: Arjon Turnip, Sutrisno Salomo Hutagalung, Jasman Pardede, Demi Soetraprawata, P300 Detection Using a Multilayer Neural Network Classifier Based on Adaptive Feature Extraction, International Journal of Brain and Cognitive Sciences, Vol. 2 No. 5, 2013, pp. 63-75. doi: 10.5923/j.ijbcs.20130205.01.
Article Outline
1. Introduction
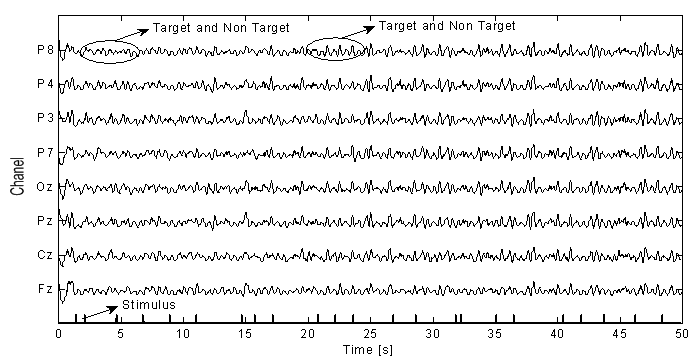
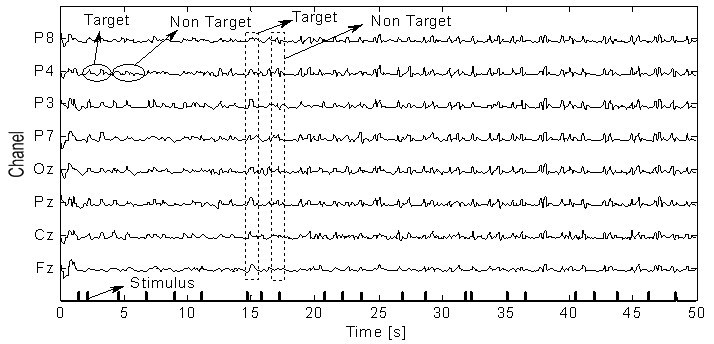
- A Brain Computer Interface (BCI) is a type of communication system that translates brain activities into electrical commands, enabling the user to control special computer applications or other devices simply by means of his or her thoughts[1, 2]. Such an interface can be used both in neuromuscular disorder clinics and in everyday life. A typical BCI schematic is shown in Figure 1. Brain signals are acquired by electrodes on the scalp and cleaned (i.e., amplified, sampled, and filtered) by preprocessing methods. Once cleaned, their features are extracted and classified to determine the corresponding types of mental activities that the subject performs. The classified signals are then used by an appropriate algorithm for the development of a certain application. Among the various techniques for recording brain signals[1-14], electroencephalography (EEG) is focused in this paper. EEG is most preferred for BCI applications due to its non-invasiveness, cost effectiveness, easy implementation, and superior temporal resolution[1], [9].Brain signals can be generated through one or more of the following routes: implanted methods, evoked potentials (or event-related potentials), and operant conditioning. Evoked potentials (in short, EPs) are brain potentials that are evoked by the cause of sensory stimuli. Usually they are obtained by averaging a number of brief EEG segments (called EEG trials) corresponding to the stimulus of a simple task. In a BCI application, control commands are generated through the EPs when the subject attempts an appropriate mental task[1],[3],[13-19]. This paper focuses on the EPs recorded at the eight electrodes (Fz, Cz, Pz, Oz, P7, P3, P4, and P8) in Figure 2[3].
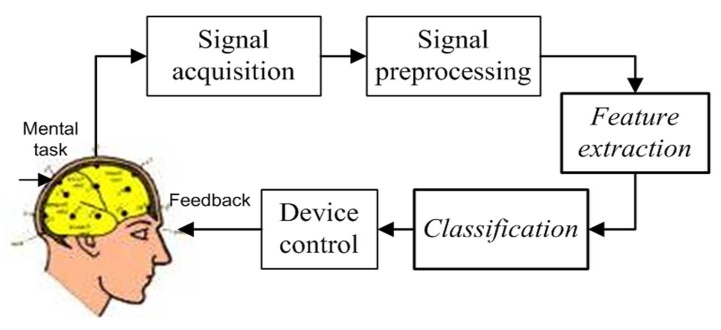 | Figure 1. Five key steps in BCI (feature extraction and classification are focused) |
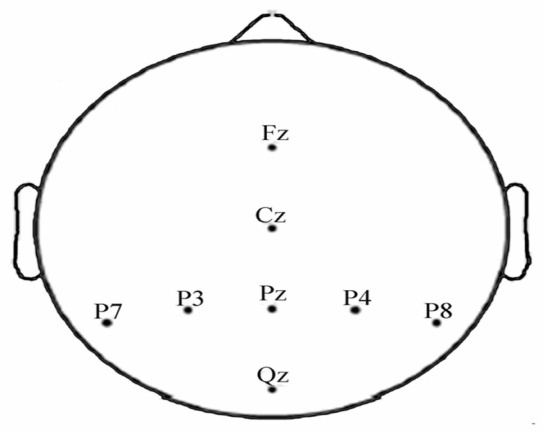 | Figure 2. Eight electrodes configuration used in experiment |
2. EEG Data and Preprocessing
- Since the purpose of this paper is to demonstrate the performance of the proposed method (i.e., the combined adaptive filter-AAR feature extraction and MNN classification) in comparison with the work of Hoffmann et al.[3], the present study uses the raw data in Hoffmann et al.[3]. Also, only the data of the 8 channels in Fig. 2 are used, which is claimed to be sufficient, by Hoffmann et al.[3], in that a good compromise between the sufficiency of accuracy and the computational complexity in handling the number of channels is achieved. Specifically, the used raw EEG data correspond to the signal sj(t) , j=1~M (here, M denote the number of electrodes, that is M = 8) in Figure 3.
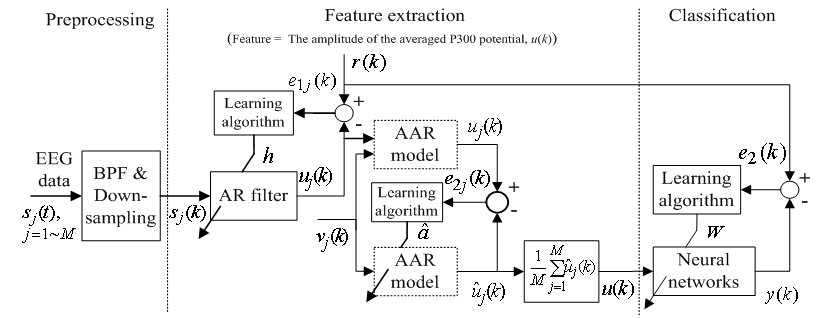 | Figure 3. Structure of the proposed feature extraction and classification algorithm |
3. Feature Extraction and Classification
- Each data set includes EEG data, events information, stimuli occurrence, target assignment, and target counting. The EEG data is of a matrix given by 34 rows
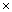 the number of samples (columns), which reflects the data of 32 electrodes and 2 reference signals (average signal from the two mastoid electrodes was used for referencing). The dimension of a trial vector is M
the number of samples (columns), which reflects the data of 32 electrodes and 2 reference signals (average signal from the two mastoid electrodes was used for referencing). The dimension of a trial vector is M 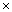 N, where M denotes 32 electrodes and N indicates the number of temporal samples of the trial. The goal of feature extraction is to find data representations that can be used to simplify the subsequent brain pattern classification or detection. The extracted signals should encode the commands made by the subject but should not contain noises or other interfering patterns (or at least should reduce their level) that can impede classification or increase the difficulty of analyzing EEG signals. For this reason, it is necessary to design a specific filter that can reduce such artifacts in EEG records. Thus, the AR-type is employed to adapt the coefficients of an FIR filter to match, as close as possible, the response of an unknown system[31-33]. In Figure 3, let
N, where M denotes 32 electrodes and N indicates the number of temporal samples of the trial. The goal of feature extraction is to find data representations that can be used to simplify the subsequent brain pattern classification or detection. The extracted signals should encode the commands made by the subject but should not contain noises or other interfering patterns (or at least should reduce their level) that can impede classification or increase the difficulty of analyzing EEG signals. For this reason, it is necessary to design a specific filter that can reduce such artifacts in EEG records. Thus, the AR-type is employed to adapt the coefficients of an FIR filter to match, as close as possible, the response of an unknown system[31-33]. In Figure 3, let  denote the raw data of 2048 Hz,
denote the raw data of 2048 Hz, 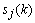 be the output of the BPF after down-sampling where k denotes the discrete time of 32 Hz, and
be the output of the BPF after down-sampling where k denotes the discrete time of 32 Hz, and 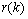 represent the desired reference sequence in association with the given stimulus (target). Then, the filter output
represent the desired reference sequence in association with the given stimulus (target). Then, the filter output 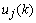 is given by
is given by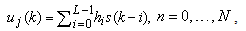 | (1) |
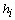 are the order and tunable coefficients of the filter, respectively. Let
are the order and tunable coefficients of the filter, respectively. Let 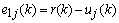 be the error between the reference signal
be the error between the reference signal 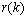 and the filter output
and the filter output 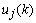 . The squared error is
. The squared error is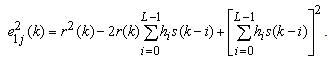 | (2) |
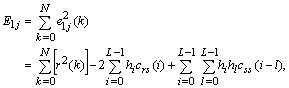 | (3) |
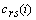 and
and 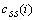 are the cross-correlation function between the reference and preprocessed signals and the autocorrelation function of the preprocessed signal, respectively. They are defined as
are the cross-correlation function between the reference and preprocessed signals and the autocorrelation function of the preprocessed signal, respectively. They are defined as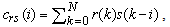 | (4) |
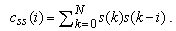 | (5) |
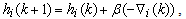 | (6) |
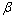 is a positive coefficient controlling the rate of adaptation, and the gradient
is a positive coefficient controlling the rate of adaptation, and the gradient 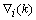 is defined as
is defined as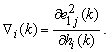 | (7) |
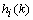 and replacing
and replacing 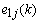 according to (1), we obtain
according to (1), we obtain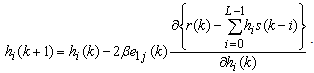 | (8) |
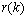 and
and 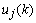 are independent of
are independent of 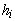 , (8) can be written as
, (8) can be written as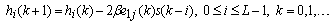 | (9) |
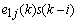 is the approximation of the negative of the gradient of the ith filter coefficients. This is the least mean squares recursive algorithm for adjusting the filter coefficients adaptively so as to minimize the sum of the squared error
is the approximation of the negative of the gradient of the ith filter coefficients. This is the least mean squares recursive algorithm for adjusting the filter coefficients adaptively so as to minimize the sum of the squared error 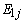 . Equation (1) with (9) represents the best model for
. Equation (1) with (9) represents the best model for 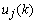 , whose output is feasible as input to the adaptive autoregressive (AAR) model.In the AAR model in Figure 3, a proper selection of its coefficients can represent the given signal well (in this paper,
, whose output is feasible as input to the adaptive autoregressive (AAR) model.In the AAR model in Figure 3, a proper selection of its coefficients can represent the given signal well (in this paper, 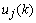 ). In minimizing the error, a proper updating algorithm and a proper model order are two important factors that need to be considered. The output of the AAR model is given in the following form[34]
). In minimizing the error, a proper updating algorithm and a proper model order are two important factors that need to be considered. The output of the AAR model is given in the following form[34]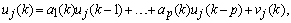 | (10) |
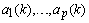 are the time-varying AAR model parameters,
are the time-varying AAR model parameters, 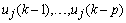 are the past p-samples of the time series where p is the order of the AAR model, and
are the past p-samples of the time series where p is the order of the AAR model, and 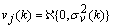 is a zero mean Gaussian noise process with variance
is a zero mean Gaussian noise process with variance 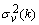 . Here, it is assumed that the parameters change slowly in time. The past samples and the estimated AAR parameters are written as
. Here, it is assumed that the parameters change slowly in time. The past samples and the estimated AAR parameters are written as 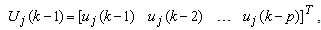 | (11) |
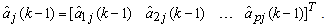 | (12) |
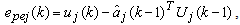 | (13) |
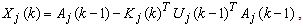 | (14) |
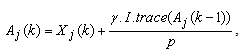 | (15) |
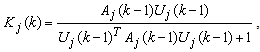 | (16) |
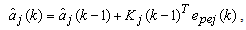 | (17) |
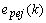 is the one-step prediction error of the jth channels,
is the one-step prediction error of the jth channels, 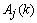 and
and 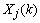 are the a priori and the a posteriori state error correlation matrix (p
are the a priori and the a posteriori state error correlation matrix (p  p),
p), 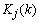 is the Kalman gain vector (1
is the Kalman gain vector (1 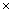 p),
p), 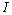 is the identity matrix, and
is the identity matrix, and 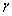 is the update-coefficient. If the estimates are near the true values (
is the update-coefficient. If the estimates are near the true values (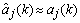 ), the prediction error
), the prediction error 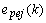 will be close to the innovation process
will be close to the innovation process 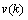 , and the mean square error would be minimum. Through the estimated coefficients, the estimated output,
, and the mean square error would be minimum. Through the estimated coefficients, the estimated output, 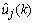 , of the AAR model were obtained.The artificial neural network has been employed in information and neural sciences for conducting research into the mechanisms and structures of the brain. This has led to the development of new computational models for solving complex problems involving pattern recognition, rapid information processing, learning and adaptation, classification, identification and modeling, speech, vision and control systems[25-30]. EEG signals in reality are generated by a nonlinear system comprising post-synaptic neurons firing action potentials; this makes the measured signals very noisy, and their classification performance is very poor. To overcome this problem, classification using an MNN is discussed in this subsection. Given a set of training samples
, of the AAR model were obtained.The artificial neural network has been employed in information and neural sciences for conducting research into the mechanisms and structures of the brain. This has led to the development of new computational models for solving complex problems involving pattern recognition, rapid information processing, learning and adaptation, classification, identification and modeling, speech, vision and control systems[25-30]. EEG signals in reality are generated by a nonlinear system comprising post-synaptic neurons firing action potentials; this makes the measured signals very noisy, and their classification performance is very poor. To overcome this problem, classification using an MNN is discussed in this subsection. Given a set of training samples 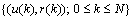 , error back-propagation training begins by feeding all
, error back-propagation training begins by feeding all 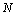 inputs through a multilayer perceptron network and computing the corresponding output
inputs through a multilayer perceptron network and computing the corresponding output 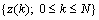 , as shown in Figure 3 (here, the initial weight matrix W(0) is chosen arbitrary). The sum of the square error is then given by
, as shown in Figure 3 (here, the initial weight matrix W(0) is chosen arbitrary). The sum of the square error is then given by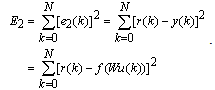 | (18) |
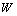 to minimize the error
to minimize the error 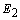 . This becomes a nonlinear least squares optimization problem, and there are numerous nonlinear optimization algorithms available to solve it. These algorithms all adopt an iterative formulation similar to
. This becomes a nonlinear least squares optimization problem, and there are numerous nonlinear optimization algorithms available to solve it. These algorithms all adopt an iterative formulation similar to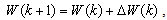 | (19) |
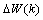 is the correction made to the current weight
is the correction made to the current weight 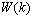 , which is solved using the steepest descend gradient method[37]. The derivative of the scalar quantity
, which is solved using the steepest descend gradient method[37]. The derivative of the scalar quantity 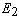 with respect to individual weights can be expressed as
with respect to individual weights can be expressed as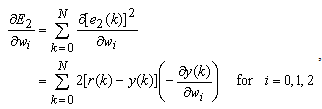 | (20) |
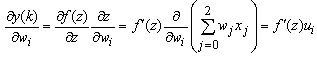 | (21) |
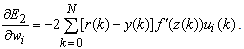 | (22) |
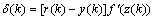 is introduced, the above equation can be expressed
is introduced, the above equation can be expressed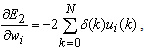 | (23) |
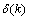 is the modulated error signal by the derivative of the activation function
is the modulated error signal by the derivative of the activation function 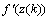 . The overall change
. The overall change 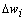 is thus the sum of that correction over all the training samples. Therefore, the weight update formula takes the following form
is thus the sum of that correction over all the training samples. Therefore, the weight update formula takes the following form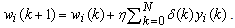 | (24) |
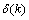 can be expressed as
can be expressed as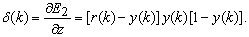 | (25) |
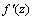 can be determined precisely without any approximation. Each of the weights updated time is called an epoch. In practice, the epoch size can be taken as the size of one trial. Here, the modified version of the weight update formula in (19) for training a multiple-layer neural network is presented. The net-function and output corresponding to the kth training sample of the jth neuron of the (Q-1)th layer are denoted by
can be determined precisely without any approximation. Each of the weights updated time is called an epoch. In practice, the epoch size can be taken as the size of one trial. Here, the modified version of the weight update formula in (19) for training a multiple-layer neural network is presented. The net-function and output corresponding to the kth training sample of the jth neuron of the (Q-1)th layer are denoted by 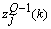 and
and 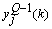 , respectively. The input layer, being the zeroth layer, is given by
, respectively. The input layer, being the zeroth layer, is given by 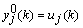 . The output is fed into the ith neuron of the Qth layer via a synaptic weight denoted by
. The output is fed into the ith neuron of the Qth layer via a synaptic weight denoted by 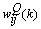 or, for simplicity,
or, for simplicity, 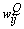 . The weight adaptation equation
. The weight adaptation equation 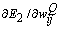 is expressed as[37]
is expressed as[37]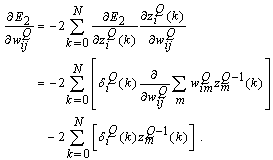 | (26) |
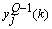 can be evaluated by applying the kth training sample
can be evaluated by applying the kth training sample 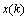 to the MNN with weights fixed to
to the MNN with weights fixed to 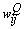 . However, the delta error term
. However, the delta error term 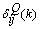 is not readily available, and so has to be computed. Note that
is not readily available, and so has to be computed. Note that 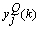 is fed into all
is fed into all 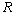 neurons in the (Q+1)th layer; hence
neurons in the (Q+1)th layer; hence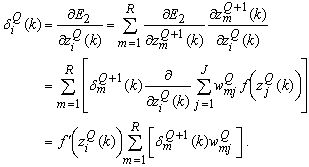 | (27) |
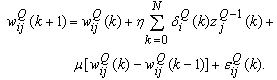 | (28) |
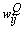 . The third term (the momentum term) provides a mechanism for adaptive adjustment of the step size. Both of the parameters (i.e., learning rate
. The third term (the momentum term) provides a mechanism for adaptive adjustment of the step size. Both of the parameters (i.e., learning rate 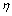 and momentum constant
and momentum constant 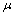 ) are chosen from the interval of[0 1]. The last term is a small random noise term that has little effect when the second and third terms have large magnitudes. When the training process reaches a local minimum, the magnitude of the corresponding gradient vector or the momentum term is likely to diminish. In such a situation, the noise term can help the learning algorithm leap out of the local minimum and continue to search for the globally optimal solution.It is difficult to compare performances of BCI systems, because the pertinent studies have derived and presented the results in different ways. Notwithstanding, in the present study, the comparison was made on the bases of accuracy and transfer rate. Accuracy is perhaps the most important measure of any BCI. Accuracy greatly affects the channel capacity and, thus, the performance of a BCI. And if a BCI is to be used in control applications (environmental controls, hand prosthetics, wheelchairs, etc.), its accuracy is, obviously, crucial. One needs only to imagine a wheelchair lacking controllability in the street. Besides accuracy, the transfer rate also is very important. The transfer rate (bits per minute) or speed of a particular BCI is affected by the trial length, that is, the time required for one selection. This time should be shortened in order to enhance a BCI’s communicative effectiveness. When considering using a BCI as a communication or control tool, then, it is important to know how long it takes to make one selection. Although a classification can be made in a short time interval, one selection cannot necessarily be made in that same time.BCI performance can be evaluated from the standpoint of (i) speed and accuracy in specific applications or (ii) theoretical performance measured in the form of the information transfer rate. The information transfer rate, as defined in[38], is the amount of information communicated per unit of time. The transfer rate is a function of both the speed and the accuracy of selection. The bits (bits/trial) can be used in comparing different BCI approaches or for measuring system improvements[8]. The bits ([3],[15],[16]) of a BCI with
) are chosen from the interval of[0 1]. The last term is a small random noise term that has little effect when the second and third terms have large magnitudes. When the training process reaches a local minimum, the magnitude of the corresponding gradient vector or the momentum term is likely to diminish. In such a situation, the noise term can help the learning algorithm leap out of the local minimum and continue to search for the globally optimal solution.It is difficult to compare performances of BCI systems, because the pertinent studies have derived and presented the results in different ways. Notwithstanding, in the present study, the comparison was made on the bases of accuracy and transfer rate. Accuracy is perhaps the most important measure of any BCI. Accuracy greatly affects the channel capacity and, thus, the performance of a BCI. And if a BCI is to be used in control applications (environmental controls, hand prosthetics, wheelchairs, etc.), its accuracy is, obviously, crucial. One needs only to imagine a wheelchair lacking controllability in the street. Besides accuracy, the transfer rate also is very important. The transfer rate (bits per minute) or speed of a particular BCI is affected by the trial length, that is, the time required for one selection. This time should be shortened in order to enhance a BCI’s communicative effectiveness. When considering using a BCI as a communication or control tool, then, it is important to know how long it takes to make one selection. Although a classification can be made in a short time interval, one selection cannot necessarily be made in that same time.BCI performance can be evaluated from the standpoint of (i) speed and accuracy in specific applications or (ii) theoretical performance measured in the form of the information transfer rate. The information transfer rate, as defined in[38], is the amount of information communicated per unit of time. The transfer rate is a function of both the speed and the accuracy of selection. The bits (bits/trial) can be used in comparing different BCI approaches or for measuring system improvements[8]. The bits ([3],[15],[16]) of a BCI with 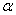 mental activities in its controlling set and a mean accuracy P (i.e., 1 − P is the mean recognition error), is given by
mental activities in its controlling set and a mean accuracy P (i.e., 1 − P is the mean recognition error), is given by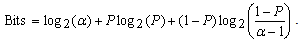 | (29) |
4. Results and Discussions
- The EEG signals were first preprocessed using a sixth-order band-pass filter with cut-off frequencies of 1 Hz and 12 Hz, respectively, see Figure 4. It can be seen that the signals were corrupted by noises. The feature extraction of the pre-processed signals of the eight electrodes (Fz, Cz, Pz, Oz, P7, P3, P4, and P8) has been compared for three cases: i) using only the AR filter, ii) Using only the AAR model, and iii) the proposed combination of both. In obtaining Figures 5-7, the first half of the first three sessions out of 4 sessions of a trial was used for training (i.e., the half for validation).
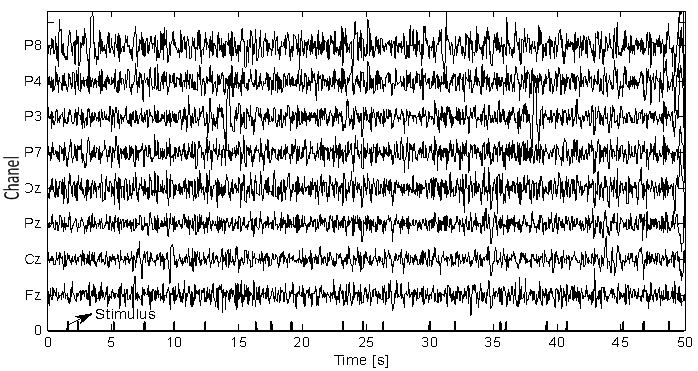 | Figure 4. EEG signals preprocessed using the BPF |
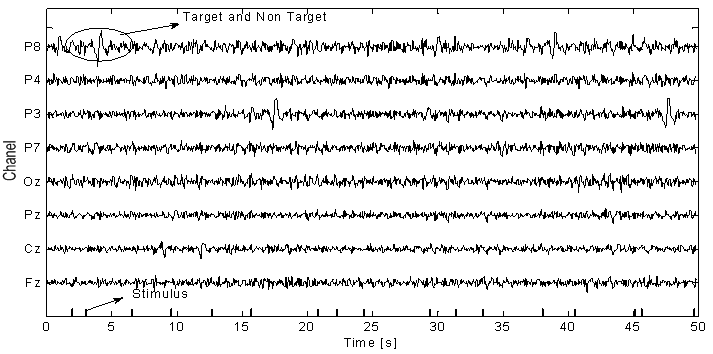 | Figure 5. Feature extraction using only the AR filter (w/o the AAR model) |
 | Figure 6. Feature extraction using only the AAR model (w/o the AR filter) |
 | Figure 7. Improved feature extraction using the combination of the AR filter and AAR model |
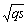 formula[39], where q is the number of neurons of the input layer and s the number of neurons of the output layer. In order to avoid overtraining and to achieve an acceptable generalization in the classification, three data sets were employed: a training set, a validation set, and a testing set. The neural network was trained using the training set (three sessions in the first evaluation and two sessions in the second evaluation), whose phase was completed when the performance for the validation set was maximized. The generalizability was tested using the testing set containing samples that had not been used previously. The performance was measured according to the specified performance function (i.e., mean square error). The convergence of the mean square errors to zero (using y(n): with proposed method and x(n): without proposed method, see Figure 8) verified the performance of the network with the proposed feature extraction method. Specifically, the curves show that by application of feature extraction, an acceptable level of accuracy was attained after about 500 iterations. However, without feature extraction, the same level of accuracy, after 1800 iterations, was the able-bodied subjects, indicating that the recorded signals from the former were more corrupted.
formula[39], where q is the number of neurons of the input layer and s the number of neurons of the output layer. In order to avoid overtraining and to achieve an acceptable generalization in the classification, three data sets were employed: a training set, a validation set, and a testing set. The neural network was trained using the training set (three sessions in the first evaluation and two sessions in the second evaluation), whose phase was completed when the performance for the validation set was maximized. The generalizability was tested using the testing set containing samples that had not been used previously. The performance was measured according to the specified performance function (i.e., mean square error). The convergence of the mean square errors to zero (using y(n): with proposed method and x(n): without proposed method, see Figure 8) verified the performance of the network with the proposed feature extraction method. Specifically, the curves show that by application of feature extraction, an acceptable level of accuracy was attained after about 500 iterations. However, without feature extraction, the same level of accuracy, after 1800 iterations, was the able-bodied subjects, indicating that the recorded signals from the former were more corrupted.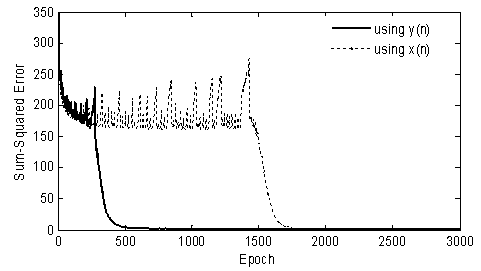 | Figure 8. Reduction of MNN training time by using the proposed feature extracted method |
|
|
|
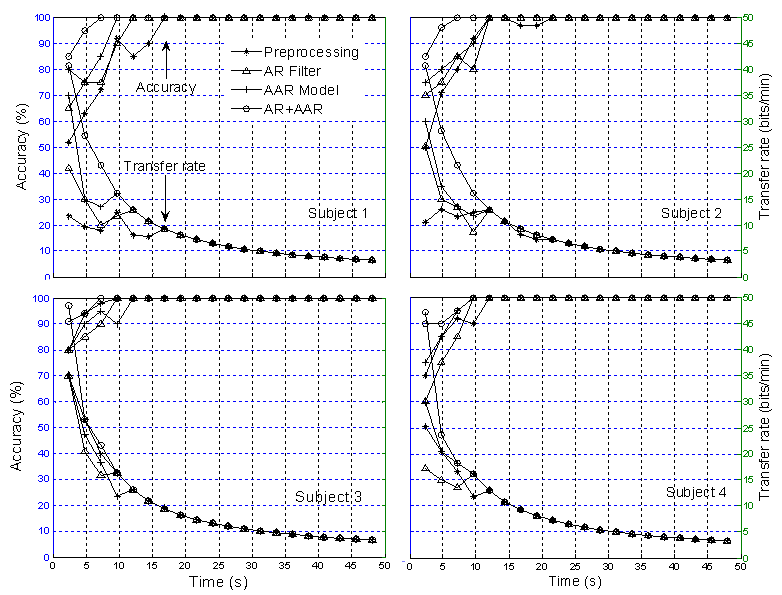 | Figure 9. Comparison of classification accuracy and transfer rate: Based on three sessions training for disabled subjects |
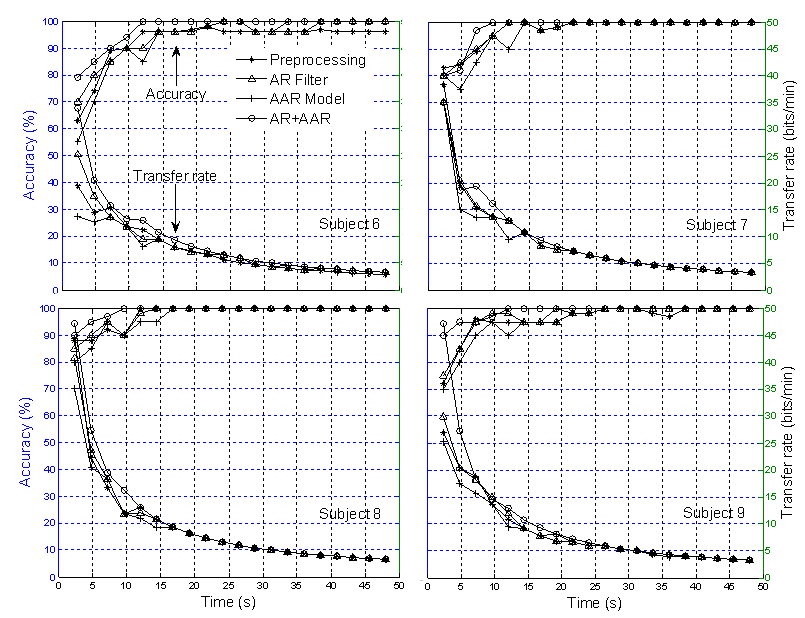 | Figure 10. Comparison of classification accuracy and transfer rate: Based on three sessions training for able-bodied subjects |
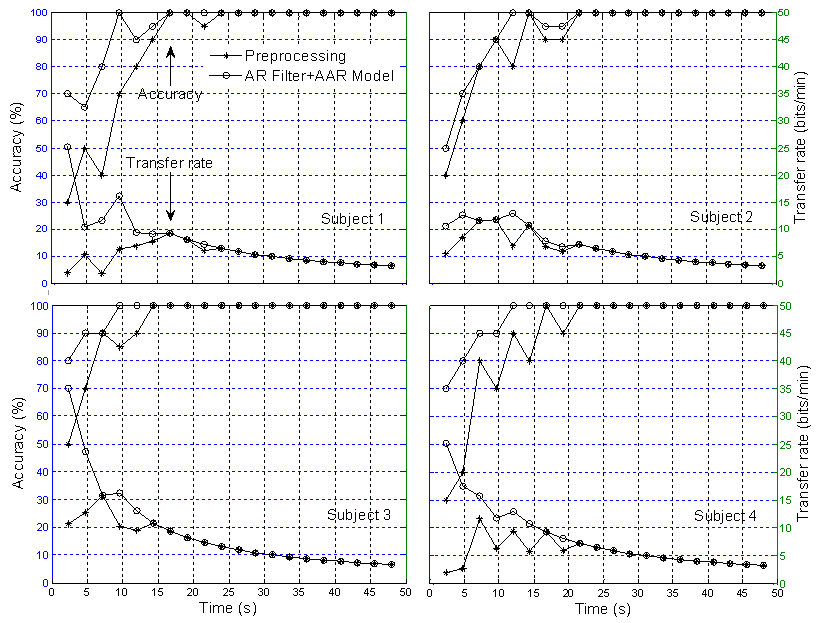 | Figure 11. Comparison of classification accuracy and transfer rate: Two sessions training in MNN for disabled subjects (* the preprocessed signal and O the AR+AAR feature extraction) |
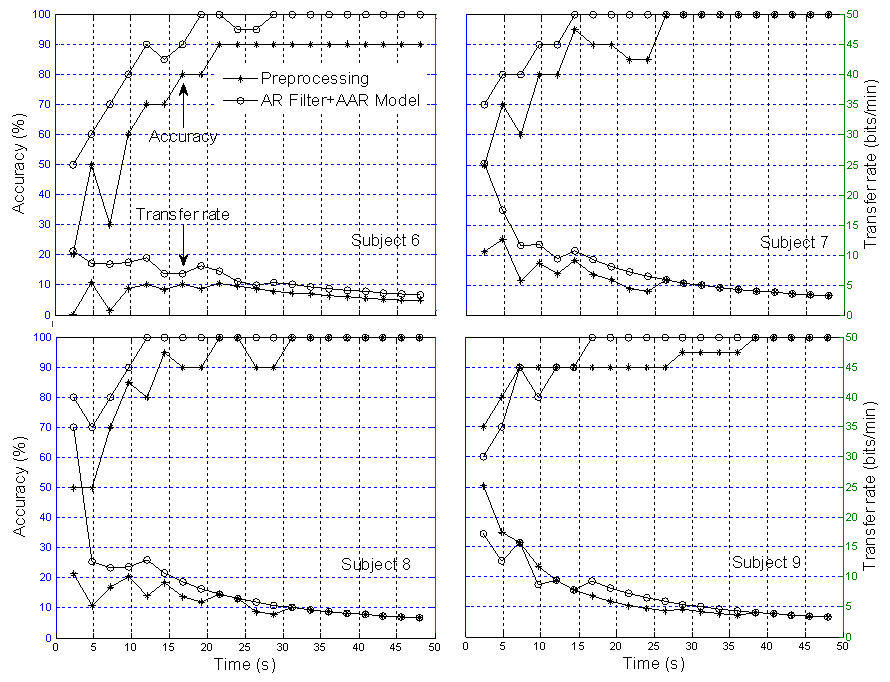 | Figure 12. Comparison of classification accuracy and transfer rate: Two sessions training in MNN for able-bodied subjects (* the preprocessed signal and O the AR+AAR feature extraction) |
5. Conclusions
- The feature extraction method introduced in this study showed how a better extraction result can be obtained when using the multilayer neural network (MNN) algorithm for single-trial EPs based on the P300 component from specific brain regions. An average 100% classification accuracy was achieved, both for four blocks over three sessions training and six blocks over two sessions training. With regard to the classification accuracy, the data indicates that a P300-based BCI system can communicate at a rate of 48.49 bits/min for disabled subjects and 47.10 bits/min for able-bodied subjects, respectively. The classification and transfer rate accuracies obtained using the AR filter and AAR model approaches separately were found to be only marginally superior to mere chance, indicating that neither approach is adequate for BCI applications. However, with the combined AR filter and AAR model method, the classification and transfer rate accuracies were far superior and, moreover, entirely BCI-implementable.
ACKNOWLEDGEMENTS
- This research was supported by the tematic program (No. 3425.001.013) through the Bandung Technical Management Unit for Instrumentation Development (Deputy for Scientific Services) and the competitive program (No. 079.01.06.044) through the Research Center for Metalurgy (Deputy for Earth Sciences) funded by Indonesian Institute of Sciences, Indonesia.
References
| [1] | E. Donchin, K.M. Spencer, R. Wijesinghe, The mental prosthesis: Assessing the speed of a P300-based brain - computer interface, IEEE Trans. Rehabil. Eng., vol.8, no.2, pp. 174-179, 2000. |
| [2] | R. Ortner, B.Z. Allison, G. Korisek, H. Gaggl, G. Pfurtscheller, An SSVEP BCI to control a hand orthosis for persons with tetraplegia, IEEE Trans. Neural Syst. Rehabil. Eng., vol.19, no.1, pp. 1-5, 2011. |
| [3] | U. Hoffmann, J.-M. Vesin, T. Ebrahimi, An efficient P300-based brain-computer interface for disabled subjects, J. Neurosci. Methods, vol.vol.167, no.1, pp. 115-125, 2008. |
| [4] | T. Yamaguchi, K. Nagala, P. Q. Truong, M. Fujio, K. Inoue, and G. Pfurtscheller, Pattern recognition of EEG signal during motor imagery by using SOM, Int. J. Innov. Comp. Inf. Control, vol.4, no.10, pp.2617-2630, 2008. |
| [5] | E. Niedermeyer, F.L. Da Silva, Electroencephalography, 5th Ed. Lippincott Williams & Wilkins, 2005. |
| [6] | Z. F. Zi, T. Sugi, S. Goto, X. Y. Wang, and M. Nakamura, A real-time data classification system for accurate analysis of neuro-biological signals, Int. J. Innov. Comp. Inf. Control, vol.7, no.1, pp.73-83, 2011. |
| [7] | E.M. Izhikevich, Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting, The MIT Press, Cambridge, Massachusetts, 2007. |
| [8] | A. Turnip and K.-S. Hong, Classifying mental activities from EEG-P300 signals using adaptive neural network, Int. J. Innov. Comp. Inf. Control, vol. 8, no. 9, pp. 6429-6443, 2012. |
| [9] | J.-S. Lin and W.-C. Yang, Wireless brain-computer interface for electric wheelchairs with EEG and eye-blinking signls, Int. J. Innov. Comp. Inf. Control, vol.8, no. 9, pp 6011-6024, 2012. |
| [10] | C. R. Hema, M. P. Paulraj, R. Nagarajan, S. Taacob, and A. H. Adom, Brain machine interface: a comparison between fuzzy and neural classifiers, Int. J. Innov. Comp. Inf. Control, vol.5, no.7, pp.1819-1827, 2009. |
| [11] | C. L. Zhao, C. X. Zheng, M. Zhao, J. P. Liu, and Y. L. Tu, Automatic classification of driving mental fatigue with eeg by wavelet packet energy and KPCA-SVM, Int. J. Innov. Comp. Inf. Control, vol.7, no.3, pp.1157-1168, 2011. |
| [12] | Z. S. Hua, X. M. Zhang, and X. Y. Xu, Asymmetric support vector machine for the classification problem with asymmetric cost of misclassification, Int. J. Innov. Comp. Inf. Control, vol.6, no.12, pp.5597-5608, 2010. |
| [13] | A. Shibata, M. Konishi, Y. Abe, R. Hasegawa, M. Watanabe, and H. Kamijo, Neuro based classification of facility sounds with background noises, Int. J. Innov. Comp. Inf. Control, vol.6, no.7, pp.2861-2872, 2010. |
| [14] | K.-C. Hung, Y.-H. Kuo, and M.-F. Horng, Emotion recognition by a novel triangular facial feature extraction method, Int. J. Innov. Comp. Inf. Control, vol.8, no.11, pp. 7729-7746, 2012. |
| [15] | S.T. Ahi, H. Kambara, Y. Koike, A dictionary-driven P300 speller with a modified interface, IEEE Trans. Neural Syst. Rehabil. Eng., vol.19, no.1, pp. 6-14, 2011. |
| [16] | E.M. Mugler, C.A. Ruf, S. Halder, M. Bensch, A. Kubler, Design and implementation of a P300-based brain-computer interface for controlling an internet browser, IEEE Trans. Neural Syst. Rehabil. Eng., vol.18, no.6, pp. 599-609, 2010. |
| [17] | D. Huang, P. Lin, D.-Y. Fei, X. Chen, O. Bai, Decoding human motor activity from EEG single trials for a discrete two-dimensional cursor control, J. Neural Eng., vol.6, no.4, pp. 046005, 2009. |
| [18] | O. Aydemir and T. Kayikcioglu, Comparing common machine learning classifiers in low-dimensional feature vectors for brain computer interface application, Int. J. Innov. Comp. Inf. Control, vol.9, no. 3, pp. 1145-1157, 2013. |
| [19] | V. Abootalebi, M.H. Moradi, M.A. Khalilzadeh, A comparison of methods for ERP assessment in a P300-based GKT, Int. J. Psychophysiol, vol.62, no. 2, pp. 309-320, 2006. |
| [20] | R.M. Chapman, H.R. Bragdon, Evoked responses to numerical and nonnumerical visual stimuli while problem solving, Nature, vol.203, no.12, pp. 1155-1157, 1964. |
| [21] | S. Sutton, M. Braren, E.R. John, J. Zubin, Evoked potential correlates of stimulus uncertainty, Science, vol.150, no. 700, pp. 1187-1188, 1965. |
| [22] | M. Onofrj, D. Melchionda, A. Thomas, T. Fulgente, Reappearance of event-related P3 potential in locked-in syndrome, Cognitive Brain Research, vol.4, no.2, pp. 95-97, 1996. |
| [23] | L.A. Farwell, E. Donchin, Talking off the top of the head: Toward a mental prosthesis utilizing event-related brain potentials, Electroenceph. Clin. Neurophysiol., vol.70, no.6, pp. 510-523, 1988. |
| [24] | A.D. Poularikas, Z.M. Ramadan, Adaptive Filtering Primer with Matlab, CRC Press Taylor & Francis Group, 2006. |
| [25] | S. Salehi and H. M. Nasab, New image interpolation algorithms based on dual-three complex wavelet transform and multilayer feedforward neural networks, Int. J. Innov. Comp. Inf. Control, vol.8, no.10(A), pp. 6885-6902, 2012. |
| [26] | C.-H. Liang and P.-C. Tung, The active vibration control of a centrifugal pendulum vibration absorber using a back-propagation neural network, Int. J. Innov. Comp. Inf. Control, vol.9, no. 4, pp. 1573-1592, 2013. |
| [27] | Y.-Z. Chang, K.-T. Hung, H.-Y. Shin, and Z.-R. Tsai, Surrogate neural network and multi-objective direct algorithm for the optimization of a swiss-roll type recuperator, Int. J. Innov. Comp. Inf. Control, vol.8, no.12, pp. 8199-8214, 2012. |
| [28] | R. Hedjar, Adaptive neural network model predictive control, Int. J. Innov. Comp. Inf. Control, vol.9, no.3, pp. 1245-1257, 2013. |
| [29] | I-T. Chen, J.-T. Tsai, C.-F. Wen, and W.-H. Ho, Artificial neural network with hybrid taguchi-genetic algorithm for nonlinear MIMO model of machining processes, Int. J. Innov. Comp. Inf. Control, vol.9, no.4, pp. 1455-1475, 2013. |
| [30] | T.-L. Chien, Feedforward neural network and feedback linearization control design of bilsat-1 satellite system, Int. J. Innov. Comp. Inf. Control, vol. 8, no.10(A), pp. 6921-6943, 2012. |
| [31] | P. He, G. Wilson, C. Russell, Removal of ocular artifacts from electro-encephalogram by adaptive filtering, Med. Biol. Eng. Comput., vol.42, no.3, pp. 407-412, 2004. |
| [32] | R.R. Gharieb, A. Cichocki, Segmentation and tracking of the electro-encephalogram signal using an adaptive recursive bandpass filter, Med. Biol. Eng. Comput., vol.39, no.2, pp. 237-248, 2001. |
| [33] | X. Wan, K. Iwata, J. Riera, M. Kitamura, R. Kawashima, Artifact reduction for simultaneous EEG/fMRI recording: adaptive FIR reduction of imaging artifacts, Clin. Neurophysiol., vol.117, no.3, pp. 681-92, 2006. |
| [34] | G. Pfurtscheller, C. Neuper, A. Schlogl, K. Lugger, Separability of EEG signals recorded during right and left motor imagery using adaptive autoregressive parameters, IEEE Trans. Rehabil. Eng., vol.6, no.3, pp. 316-325, 1998. |
| [35] | S. Roberts, W. Penny, Real-time brain computer interfacing: A preliminary study using bayesian learning, Med. Biol. Eng. Comput., vol.38, no.1, pp. 56-61, 2000. |
| [36] | J.G. Proakis, Digital Communications, McGraw-Hill, New York, NY, Third Edition, 1995. |
| [37] | A. Zaknich, Principles of Adaptive Filters and Self-learning Systems, Leipzig, Germany, Springer-Verlag London Limited, 2005. |
| [38] | C.E. Shannon, W. Weaver, A mathematical theory of communication, Bell System Technical Journal 27 (1948) 379-423 and 623-656. |
| [39] | D. Graupe, Princiles of Artificial Neural Networks, 2nd Ed. World Scientific Publishing Co. Pte. Ltd. 6 (2007). |
| [40] | Y. H. Hu and J.-N. Hwang, Handbook of Neural network signal processing, CRC Press, Washington, D.C., 2002. |