-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Brain and Cognitive Sciences
p-ISSN: 2163-1840 e-ISSN: 2163-1867
2012; 1(3): 18-25
doi: 10.5923/j.ijbcs.20120103.02
Intentional Memory Instructions do not Improve Visual Memory
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLD. Alexander Varakin , Kendra M. Frye , Bailee Mayfield
Department of Psychology, Eastern Kentucky University, Richmond, KY, 40475, USA
Correspondence to: D. Alexander Varakin , Department of Psychology, Eastern Kentucky University, Richmond, KY, 40475, USA.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
The current experiment examines whether intentional encoding instructions improve long-term recognition memory for visual appearance. Past experiments suffer from various methodological flaws, such as inadequate statistical power or confounding of variables such as attention and task relevance withintentional memory instructions.In the current experiment, the effect of memory instructions was examined using a factorial design, so that attention to/task relevance of objects could be manipulated independently of memory instructions. The sample size was large enough to achieve power equal to .80 for medium effect sizes (f = .25). There was no effect of intentional memory instructions. These results suggest that observers cannot easily enhance encoding and storage of visual information in long-term memory.
Keywords: Visual Memory, Long-term Memory, Intention
Article Outline
1. Introduction
- The human ability to recognize previously viewed pictures is remarkable.Recognition memory performance far exceeds chance levels in experiments that use very large study sets ([1]-[6]) or very long retention intervals ([5], [7], [8]), even when successful performance requires memory for visual details of scenes ([3],[9]), isolated objects ([1], [2]), or objects presented within scenes ([10], [11]).Why are people so good at recognizing previously viewed pictures? It has recently been proposed thatour visual systems are constantly creating and using visual memory, even visual long-term memory (VLTM), in the service of everyday tasks such as object perception ([12]).Part of the reason why visual memory may be needed to support object perception is that the eyes receive a different pattern of stimulation from a given object every time something in the environment changes, be it a change in vantage point due to eye, head or body movement, or a change in the position or orientation of the object itself. Despite these frequent changes in the pattern of visual stimulation from a given object from one moment to the next, we have little trouble recognizing that (for example) the mouse on the desk right now is the same mouse that was present a few seconds, minutes or even days ago. If object perception routinely relies on VLTM ([12]), then it suggests that encoding and storage of information about various aspects of the visualappearance of pictorial stimuli might be a relatively automatic process. After all, we do not usually have to try very hard to recognize particular objects, it just seems to happen. If encoding and storage of visual information into VLTM is a relatively automatic process, then an observer may have to do little more than attend to an object in order to form a relatively detailed representation of it in VLTM. Existing results are consistent with this claim: people perform very well on recognition tests for visual details even when the test is a surprise ([13]-[17]). Given these results, one question that arises is whether or not performance on visual memory tests will improve in situations where observers do expect a memory test. That is, will observers perform better on a recognition test for visual appearance when the objects are initially studied under intentional (memory test is expected) as opposed to incidental (memory test is not expected) encoding conditions? Past research investigating this question has produced mixed results.
1.1. No Benefit from Intentional Memory Instructions
- There are several experiments that find no difference between intentional and incidental encoding conditions in terms of subsequent recognition memory performance. In these experiments, participants in both incidental and intentional conditions are typically given a task that requires them to attend to all to-be-remembered objects ([14]-[17]), or eye tracking technology is utilized to ensure that these objects are fixated, and therefore attended ([13]). Ensuring that to-be-remembered objects are attended and task-relevant during the study phase is important because both attention and task-relevance of visual features can influence encoding and storage of visual information in memory ([11],[14], [18]). Object features that are relevant for an observer’s task are more likely to be attended and remembered even when observers are not intentionally trying to encode visual information for a subsequent memory test ([14], [17]). Thus, investigatingwhether intention has any special effects on visual memory requires careful control or monitoring of attention.Although the experiments suggesting that intentional encoding instructions do not enhance visual memory adequately control observers’ attention, theysuffer fromvarious other methodological shortcomings. One issue is statistical power. Sample sizes are often too small to detect even medium size effects. For example, Castelhano and Henderson ([13], Experiment 3) had only 10 participants in each condition. For a medium effect size (f = .25 or d = .50), power would be less than .20 (for an independent group t test or ANOVA). Clearly, if the effect of intentional encoding is anything less than large, then Castalhano and Henderson did not have a very good chance of detecting this effect (which they noted in their paper). Other experiments that find no effect of intentional encoding instructions sometimes use larger sample sizes but suffer from another methodological flaw – participants were not randomly assigned to experimental conditions (as in [14], [16], [17]). Of course, random assignment of participants to experimental conditions is a fundamental property of well-designed experiments, but in these cases, the experimenters weren’t so much interested in directly comparing memory performance under incidental and intentional encoding conditions as they were in testing whether the effect of another factor generalized from incidental to intentional encoding conditions. For example, Varakin and Loschky ([16]) were primarily interested in comparing recognition performance for object appearance alone with recognition performance for the conjunction of object appearance and scene viewpoint. So while many experiments found no benefit of intentional memory instructions on VLTM, testing for a main effect of intentional instructions was not the primary purpose of these studies, but a side issue.
1.2. Benefit from Intentional Memory Instructions
- In contrast to the null effect of intentional memory instructions often found in experiments that weren’t intended to test for such an effect, experiments that are explicitly concerned with the effect of intentional instructions often find benefits ([19], [20]). At the very least, these results suggest that intentional memory instructions have an effect on visual memory tasks. However, these experiments confound intentional encoding instructions with attention and task relevance and therefore are consistent with the idea that intention has no effects above and beyond the effects of selective attention. That is, these experiments are consistent with the idea that intentional memory instructions induce observers to select objects as task relevant via attention, without affecting the processes related to encoding and storage of visual information that occur after such selection.For example, in a series of 5 experiments Block ([20]) consistently found that participants who expected arecognition memory test for a given category of objects (e.g. faces or birds) performed better than participants who did not expect the test. Participants in the incidental conditions were given a cover task that required paying attention objects in the study phase, but not the objects that would eventually appear on the memory test. For example, participants in experiments 1 and 5 of Block ([20]) were told the experiment was investigating how crowds or pictures affect mood. In experiments 2, 3 and 4 of Block ([20]), participants viewed a series of objects and were told to count how many cars appeared. In both experiments, participants in the intentional condition were additionally told to memorize a particular category of object (e.g. faces or birds) for the memory test. Notice that participants in the incidental conditions were not given any reason to select individual objects from the category that ended up appearing on the memory test. Thus, these objects might have been looked at (as objects were presented one at a time), but not selected by attention as task-relevant.In other research, Beck, Levin and Angelone ([19]) found better performance in an intentional change detection condition compared to an incidental condition in which observers were instructed to search for a pair of eye glasses within each scene. Like Block ([20]), it is possible that the Beck et al. ([19]) results can be explained entirely in terms of differential allocation of selective attention and task-relevance between intentional and incidental conditions, without positing that intention enhances the encoding and storage of visual information in memory. In the incidental change detection condition, participants were searching for an object that was not present in the picture and it was assumed that participants would exhaustively search the scene and therefore attend to each object (including the change relevant object). However, this assumption might not be justified, as observers attempting to memorize a scene typically look at a greater proportion of objects than observers engaged in visual search, who presumably restrict fixations to regions that have a high probability of containing the target ([21]).Since the search target was a pair of eye glasses, participants would focus attention on horizontal support surfaces (e.g. tables, chairs, shelves) rather than vertical surfaces (e.g. walls).If the changing object was located on a vertical surface (e.g. a picture on the wall), then it might not be attended at all.In summary, experiments that find an effect of intentional encoding instructions are consistent with the hypothesis outlined earlier: encoding and storage of visual details in VLTM is part and parcel of selecting an object as relevant for an ongoing task.Intentional memory instructions might simply affect which objects participants select as task relevant, without modulating the processes related to encoding and storage of visual information that occur after selection.
1.3. The Present Experiment
- The present experiment was designed to test of the hypothesis that intentional memory instructions do not have any special effects on visual memory performance over and above the effects of selective attention.To this end, the current experiment was designed to correct some of the methodological shortcomings of previous research that failed to find this effect (in particular, the methods in [16]).First, the task-relevance of the to-be-remembered objects during study was manipulated independently of intentional memory instructions.One group of participants performed a cover task in which processing objects as objects (i.e. simply responding whenever any discrete object was cued) was required, thus making the objects relevant for the task.Another group of participants performed a task in which objects were to be treated the same as empty locations (in terms of responding).In the second cover task, participants did not have to differentiate between discrete objects and empty locations (i.e. empty in the sense that they didn’t contain a single discrete object), thus, objects were not task relevant.Within each of these conditions, some participants were further instructed to remember what the objects looked like (intentional), whereas others were not (incidental).If intent-to-remember visual information enhances encoding and storage of visual information, then intentional encoding instructions should enhance performance in both cover task conditions.A second important feature of the current experiment is that an a priori power analysis was conducted to ensure that the experiment would have a reasonable chance (power = 1-β≥ .80) of detecting medium size effect main effects (f= .25).The results of this analysis (performed using G*Power 3.1.3, [22]) indicated that a total sample size of N = 128 (at least n = 32 per group) was required to achieve this level of power using a between subject ANOVA with 1 degree of freedom in the numerator and 4 groups. Finally, participants were randomly assigned to experimental conditions.
2. Method
2.1. Participants
- A total of 155 students participated in exchange for course credit. Nineteen participants’ data were dropped because they failed to complete the cover task, leaving a final N = 136. Because participants were randomly assigned to groups, group sizes were unequal, ranging from 32 to 37.
2.2. Apparatus
- The experiment was run on iMac computers with 21.5-inch LED-backlit displays. Screen resolution was set at 1920 x 1080 pixels. SuperLab Pro 4.0 (Cedrus cooperation, San Pedro, California, CA) controlled stimulus presentation and recorded responses.
2.3. Stimuli
- Eight pairs of digital photographs (451 x 480 pixels), depicting various indoor and outdoor environments were used for the recognition memory test (see Figure 1 for an example pair).Pictures subtended about 10.5 x 11.2 degrees of visual angle, assuming a 60cm viewing distance (this viewing distance was assumed for all visual angle reports, but actual viewing distance varied because head movement was not restrained).Each member of a pair was exactly the same except for the features of a single object (henceforth, the critical object).Critical objects differed in terms of color (3 pairs), surface pattern (3 pairs), or both (2 pairs).The shape (in terms of pixels) of each critical object was exactly the same in both versions.Two additional “filler” digital photographs (also 451 x 480 pixels) were used during the study portion of the experiment to prevent primacy and recency effects.
 | Figure 1. An example pair of pictures |
2.4. Design and Procedure
- The two factors of primary interest were cover task (object task vs. brightness task) and memory instructions (incidental vs. intentional), which were crossed to create 4 separate groups (n = 33 in the object/intentional group, n = 32 in the object/incidental group, n = 37 in the brightness/incidental group, n =34 in the brightness/intentional group).In the object task conditions, participants were instructed to respond whenever an object “lit up” (i.e. increased in brightness), and to withhold response whenever an empty location lit up.In the brightness task, participants were instructed to respond whenever anything in the picture lit up, and the difference between object-filled and empty locations was not mentioned.Within each cover task condition, some participants were additionally informed that there would be a memory test for the “visual appearance” of the objects in the scene, and that the test would require them to choose among two alternative versions of scenes, one containing an object they had viewed, and one that contains an object with a different visual appearance.
 | Figure 2. A schematic example (pictures not to scale) of the cuing sequence in each trial. In each frame following the “No Cue” frame, one object or empty location is brighter than it is in the preceding frame |
3. Results and Discussion
3.1. Recognition Memory
- Significance tests were performed in SPSS 19 (IBM), and the effect size measure f was calculated using G*Power 3.1.3 ([22]) based on output (partial n2) from SPSS1.
3.1.1. Accuracy
- The primary dependent variable of interest is accuracy on the 2AFC memory test (see Figure 3). Data were submitted to a 2 x 2 between subject ANOVA with cover task (object vs. brightness) and memory instructions (incidental vs. intentional) as factors. None of the effects were significant: main effect of cover task, F (1, 132) = .09, p = .76, f= .03; main effect of memory instructions, F (1, 132) = 1.22, p = .27, f = .09; interaction F (1, 132) = .51, p = .48, f = .06.Despite the fact that the interaction from the omnibus ANOVA was not significant, a simple effects analysis was conducted comparing the effect of memory instructions for each cover task condition. Normally, simple effect analysis would not be conducted in a situation such as this because it would increase statistical power by increasing the risk of a type 1 error. In the current context however, the comparisons were justified on a priori grounds. Still, there was no effect of memory instructions in either the object (p> .78, f = .02) or brightness groups (p = .19, f = .11).
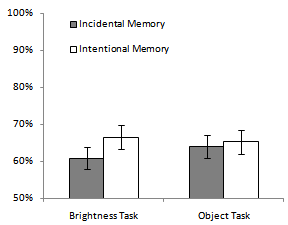 | Figure 3. Percent accurate recognition on the 2AFC test. Error bars represent ±SEM |
3.1.2. Response Time
- Mean response times (RT; time from trial onset to the mouse click) for the 2AFC trials were also analysed as a dependent variable. In the analysis reported here, each participant’s mean RT for 2AFC trials was calculated, ignoring whether the response was correct or incorrect (see Figure 4). Analyses were also conducted in which separate mean RTs were calculated for correct and incorrect responses. These analyses are not reported because the pattern of significance among the factors of interest was identical to the analysis reported here, and many participants (n = 27) had fewer than 2 incorrect responses.
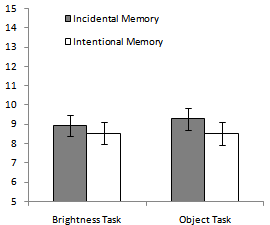 | Figure 4. Mean of mean response times (in seconds) for the 2AFC test, collapsing over accurate and inaccurate responses.Error bars represent ±SEM |
3.1.3. Discussion
- Results of the recognition test are consistent with the idea that intentional memory instructions do not improve encoding and storage information in VLTM.In both cover task conditions,there were no significant differences between the intentional and incidental memory instruction groups in terms of accuracy or response time.However there was a trend toward better accuracy and faster responding in the intentional conditions (see Figures 2 and 3), thus it remains possible that the effect of intentional instructions is real, but was not large enough to be detected here.In terms of accuracy, the effect of memory instructions trended in the right direction especially clearlyfor participants in the brightness task conditions. Participants in the intentional conditions performed better than those in the incidental conditions by 6% points.Even if this difference had turned out to be significant it would not have constituted strong evidence that intent-to-remember does anything to improve visual memory over and above directing selective attention to relevant objects. Participants in the incidental/brightness condition were not aware that the cued objects were relevant for the task, whereas those in the intentional/brightness condition were aware of their relevance.As such, it might be somewhat surprising that intentional memory instructions had no effect even in the brightness task.To get some idea as to why this may have occurred, cover task performance was analysed as well (see next section).The response time results also trended in the right direction, in that participants in the intentional conditions responded more quickly during the memory test than participants in the incidental conditions.Interpreting this result would have been difficult had it been significant.Faster response time could indicate faster processing or increased confidence.However, memory instructions had no significant effects, further supporting the idea that intentional memory instructions do not always affect visual memory much.
3.2. Cover Task Performance
- Participants in the object task conditions responded (on average) to 90% (SD = 11%) of cued objects and 16% (SD = 20%) of cued empty locations.Participants in the brightness task conditions responded (on average) to 95% (SD = 17%) of cued objects and 72% (SD = 29%) of cued empty locations.These data indicate that participants in both conditions were following task instructions: participants in the object task condition tended to respond only to objects, and those in the brightness task conditions responded to both objects and empty locations.A 2x2x2 ANOVA with memory instructions and cover task as between subject factors, and cue type (object vs. empty location) as a within subject factor was conducted to verify this pattern (only significant effects are reported here, remaining Fs (1, 132) < 1.23, ps> .25).The effect of cover task was significant, F (1, 132) = 119.56, p< .001, reflecting that participants in the brightness task (M = 84%) responded to more cues than participants in the object task (M = 52%).The effect of cue type was also significant, F (1, 132) = 510.48, p< .001, reflecting that object cues (M = 93%) were responded to more frequently than empty location cues (M = 44%).The interaction between cover task and cue type was also significant, F (1, 132) = 142.84, p< .001, reflecting that the effect of cue type was larger in the object task than the brightness task. All of these effects are expected based on the instructions given to the participants.However, a simple effects analysis testing the effect of cue type for each cover task revealed a significant effect of cue type in both cover task conditions, both ps< .001.Thus, even in the brightness task, participants responded more to cued objects than to cued empty locations.This result is important to the extent that it may account for why there was no statisticallysignificanteffect of intentional memory instructions on recognition memory in the brightness task conditions.Perhaps some participants were predisposed to perform the object-task rather than the brightness task, even without instruction or knowledge of that condition, thereby attenuating the effect of cover task instructions and increasing memory performance. This account is highly speculative, as there were many uncontrolled differences between cued objects and cued empty locations (e.g. overall luminance, color, location etc.) in these scenes.
4. General Discussion
- The primary purpose of the present experiment was to test whether intentional memory instructions improve performance on VLTM tests.Using standard conventions for measuring effect size, the current experiment suggests that intentional memory instructions may not even have a medium size effect on subsequent recognition performance.These data are therefore consistent with the idea that the visual-cognitive processes involved in identifying an object (as an object) leads to the formation of a relatively detailed visual representation(because performance in the incidental conditions was above chance), and furthermore, that intentional instructions do not necessarily improve the usefulness of these representations enough to enhance performance on a visual memory test.These results might, at first glance, seem surprising.However, as mentioned in the introduction, and as will be elaborated below, these results are consistent with recent theorizing about the nature of visual memory.A few caveats should be mentioned first.It is important to point out that the idea is neither that visual memory is “photographic”, nor that every aspect of every pattern of light that impinges upon the retina is encoded and stored in long-term visual memory.First, while people are very good at recognizing objects based on visual details, performance is still far from ceiling. Moreover, people are much worse at recognizing the conjunction of object appearance details and scene viewpoint ([16], [23]), thus, visual memory is not photographic.Second, and perhaps more importantly, although memory for attended objects is quite good, memory for (and even awareness of) unattended objects is much worse ([11], [24]).Third, even if people do routinely encode details of attended objects, and use these representations for object perception ([12]), people may not routinely use information in visual memory for other more general purposes. For example, people may not use detailed visual representations to monitor the stability of the visual world in general ([25]), which can contribute to phenomena such as change blindness (the failure to notice between view visual change, e.g. [26]).Given these caveats, the suggestion would be that encoding and storage of detailed visual information into a stable store, such as VLTM, will occur so long as an object is attended, and that merely knowingabout an upcoming recognition test for visual appearance will not always improve the quality of VLTMenough to affect performance on the recognition test.This provisional hypothesis, that intentional-memory encoding has little or no effect on visual memory over and above the effects of attention and task relevance (see also [13], [14], [17]),might be less surprising when one considers what would have to happen in order for such instructions to have beneficial effects.First, there would need to be a set of tasks that actually improve the encoding and storage of visual information over and above the effects of selective attention and task-relevance.In the current experiment, we found no evidence that task affects visual memory.However, this result should not be taken to indicate that encoding and storage into visual memory is a fixed and immutable process. Some recent research supports the idea that visual memory can be affected by a task’s processing requirements.For example, memory is better following preference-judgment or exemplar judgment tasks than labelling or basic-level categorization tasks ([27], [28]).However, the existence of such tasks is not sufficient for intentional memory instructions to have an effect.Observers would also need accurate metacognitive knowledge – they would have to know which kinds of processing tasks actually improve visual encoding and storage, when to use them, and how to engage them in the absence of overt instruction.If observers have misplaced beliefs about how to best process visual information and commit it to memory, then they will be unlikely to engage in the sort of processing that actually improves visual memory when they are simply asked to remember what objects look like.Thus, assuming it is possible in principle to improve visual memory for objects (the current results do not support, but also do not rule out, this possibility), the current results can be explained in terms of a metacognitive failure. The current participants did not provide any metacognitive judgments, however, recent work on visual metacognition ([29]) and metamemory ([30]) suggest that people have misplaced beliefs about how vision and memory actually work.An alternative possibility is that participants have accurate metacognitive knowledge, but were unable to engage in the necessary processing, perhaps because of demands caused by the cover task.Since the current experiment did not include a no-cover task condition in which participants were simply told to memorize the pictures, this possibility cannot be ruled out. However, a recent paper using the same stimuli, cuing procedure, and a very similar 2AFC test, but without the cover task requirements ([23]), found similar accuracy rates for recognition (67%) of object appearance as the current experiment’s intentional conditions (65% in the object task and 67% in the brightness task). Given the similarity of 2AFC recognition performance when no cover task is being performed, and the recent research demonstrating large metacognitive failures in vision and memory ([29], [30]), it seems somewhatunlikely that participants knew how to improve visual memory, but were prevented from doing so because of the experimental protocol.While this study addresses some important methodological concerns, there are still some important limitations.It is possible that intentional memory instructions would be more effective under another set of circumstances.For example, participants in the intentional encoding conditions might have focused on a set of visual features that were not useful for succeeding on the memory test used here (e.g. participants may have focused on size or shape, which would not have been helpful in the current context). Thus, future studies may be more systematic about controlling which kinds of visual information will be useful for succeeding on the memory test. It is also possible that motivational factors are important. After all, participants in the current experiment’s intentional encoding conditions may have been aware of the upcoming memory test, but they were not given any particular reason to succeed on it.The delay between study and test might also be an important factor. In the current experiment, the time between study and test was long enough to measure visual long-term memory as it is currently theoretically defined ([7]), but by ecological standards, the delay was still fairly short – only a few minutes at most.It remains possible that intentional memory instructions would have effects as the time between study and test increased from minutes to hours to days (etc.).There are many other factors that could potentially influence whether intentional memory instructions have effects, in addition to those mentioned above. It is therefore necessary to exercise caution when making generalizations concerning this particular result.In conclusion, the current results reinforce the findings of past research that people perform well on recognition memory tests for visual details, even when the test is a surprise.And while it remains possible that under a different set of circumstances intentional instructions might improve performance, the current experimental results are consistent with the idea that intentional memory instructions do not alwaysimprove the encoding and storage of visual information over and above the effects of attention and task relevance, at least, not enough to be easily experimentally detected.
Notes
- 1. SPSS calculates partial n2 differently than G*Power. G*Power documentation(http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3/) notes that n2SPSS =n2N/(N + k(n2 - 1)), where n2 is G*Power’s value, N is the total sample size, and k is the number of groups. SPSS values were converted to G*Power values prior to computing f.
ACKNOWLEDGEMENTS
- This work was supported by a Junior Faculty Research Grant from the College of Arts and Sciences at Eastern Kentucky University awarded to DAV.The authors would like to thank Keith Klemes and Jaime Hale for assistance with data collection.