-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
International Journal of Control Science and Engineering
p-ISSN: 2168-4952 e-ISSN: 2168-4960
2020; 10(2): 23-30
doi:10.5923/j.control.20201002.01
Received: Sep. 22, 2020; Accepted: Oct. 16, 2020; Published: Oct. 26, 2020

Continuous Lyapunov Controlled Non-linear System Optimization Using Deep Learning with Memory
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLAmr Mahmoud1, Youmna Ismaeil2, Mohamed Zohdy1
1Department of Electrical and Computer Engineering, Oakland University, Rochester, MI, USA
2Department of Computer Science, Saarland University, Saarbrucken, Germany
Correspondence to: Amr Mahmoud, Department of Electrical and Computer Engineering, Oakland University, Rochester, MI, USA.
| Email: |  |
Copyright © 2020 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Initially selected system and controller parameters don't often guarantee continued system stability and performance mainly due to the introduction of unexpected system disturbances or unknown system dynamics. In this research we present a novel approach for detecting early failure indicators of non-linear highly chaotic system and accordingly predict the best parameter calibrations to offset such instability using deep machine learning regression model. The approach proposed continuously monitors the system and controller signals. The Re-calibration of the system and controller parameters is triggered according to a set of conditions designed to maintain system stability without compromise to the system speed, intended outcome or required processing power. The deep neural model predicts the parameter values that would best counteract the expected system in-stability. To demonstrate the effectiveness of the proposed approach, it is applied to the non-linear complex combination of Duffing-Van der pol oscillators. The approach is also tested under different scenarios the system and controller parameters are initially chosen incorrectly or the system parameters are changed while running or new system dynamics are introduced while running to measure effectiveness and reaction time.
Keywords: System parameterization, Deep Machine Learning, Complex system, Non-linear controller, Duffing-van der pol, Lyapunov control
Cite this paper: Amr Mahmoud, Youmna Ismaeil, Mohamed Zohdy, Continuous Lyapunov Controlled Non-linear System Optimization Using Deep Learning with Memory, International Journal of Control Science and Engineering, Vol. 10 No. 2, 2020, pp. 23-30. doi: 10.5923/j.control.20201002.01.
Article Outline
1. Introduction
- Lyapunov control has been proven successful in controlling highly chaotic non-linear oscillators [1] [2] [3]. One of the fundamentals that contribute to the success or failure of any type of control strategy is the controller and system parameters. Therefore, researchers have explored different methods to find the precise parameters that would lead to achieving the best system results [4] [5]. One of the methods utilized to achieve the previously mentioned goals is Genetic algorithm (GA). GAs have been successful in cases where all the system dynamics are clearly defined and known to some extent or with systems where limited system disturbances are introduced and minor parameter tuning is required [6] [7]. In some cases, several system assumptions are needed in order to allow the GA to run successfully. Due to some of the limitations found in using GAs such as inability to quickly converge to the final solution or adapt to unknown system dynamics or unknown disturbances. Researchers though after different approaches that wouldn't reduce the system agility and at the same time would be able to handle unknown system characteristics. A hybrid approach of Fuzzy Control and GAs was researched in [8] but system linearization is a requirement in order to use the previously mentioned method [8]. Another approach that is recently being researched is the use of Machine Learning to enhance the controller performance. For example, through the use of Episodic learning [9] [10]. Most recently, there is the introduction neural Lyapunov control which proposes the use of deep learning to find the control and Lyapunov functions. The approach mentioned in [9] [10] is suitable for find the best system parameters that would initially lead the system to stability and reduced the system error. The problem with approach in [9] [10] is that it assumes that the system is deterministic, time invariant, and affine in the control input. while in real life situation external perturbations might occur resulting in system failure at any moment while the system is running [11] [12]. The approach proposed in [25] [26] and [27] attempts to predict the control and Lyapunov functions that would lead to system stability but under specific conditions where the system dynamics are deterministic in nature. The approach proposed in this research is novel to the best of our knowledge in that it discards the assumption of an ideal environment or fully known system dynamics and seeks continuous enhancement of the controller outcome through continuous monitoring of the system error, refence signal, system dynamics and control signal and accordingly adjust the system and controller parameters to improve the controller performance without the need to disrupt the system output.The focus of the research is to allow the Deep Learning Algorithm to learn the system from a continuously improving dataset and according to the slope of the output error the algorithm relearns the system and collects the needed information. The proposed method is applied to a non-linear chaotic combined system of Duffing and Van der pol oscillators [24]. The aforementioned system was chosen to test the Deep learning algorithm response to unpredicted system disturbances and unknown system dynamics [21] [22] [23]. An algorithm was developed to aid and trigger the Deep Neural Network when needed to adapt to new system dynamics and according to pre-set conditions. The algorithm records and feeds an updated data set to the DNN in order to relearn the system dynamics if certain conditions are detected to be true. Once the process of retraining is complete, the algorithm generates a random array of parameters and the array of parameters is fed to the DNN to predict the output error. If the DNN predicts that the error slope will be reduced from the current value improving the performance of the system, then the suggested controller parameters are allowed to be set as the new controller parameters. Otherwise the algorithm would create a new array set of randomly generated parameters and re-feed them to the DNN to provide its predictions in a continuous loop. Once the controller parameters are updated the algorithm monitors the actual error compared to the predicted error to determine the network viability and accordingly if the error difference is greater than a set value the algorithm would trigger a retraining request of the DNN.
2. Lyapunov Control on Duffing - Vanderpol Oscillator Model
- An easy way to comply with the paper formatting requirements of SAP is to use this document as a template and simply type your text into it.This section provides an overview of the Duffing-Van der pol system dynamics. Duffing-Van der pol mathematical model is
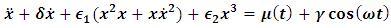 | (1) |
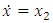 | (2) |
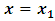 | (3) |
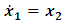 | (4) |
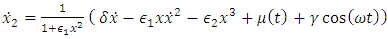 | (5) |
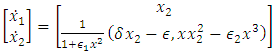 | (6) |
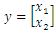 | (7) |
3. Lyapunov Controller Design
- In this section we give an overview of the controller design. The controller is designed with the purpose of achieving Duffing- van der pol oscillator system stability at an increased forcing frequency. Desired state qd and actual state q.
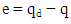 | (8) |
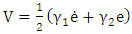 | (9) |
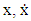 | (10) |
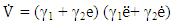 | (11) |
 | (12) |
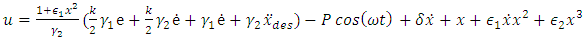 | (13) |
4. Simulation Results for Unoptimized System
- Section 4 will provide an overview of the results after running the system with the Lyapunov controller and manually selecting the parameters that lead to reduced error across the time frame of 2.5s. The Duffing- van der pol oscillator model was ran with the following selection of parameters. δ=0.5, ε1=1.6, ε2=-0.8, P=3, ω=10 and the control parameters γ1 =12, γ2 =4, k=115. The parameters were manually adjusted and tuned to give low error 1 and high stability 2.
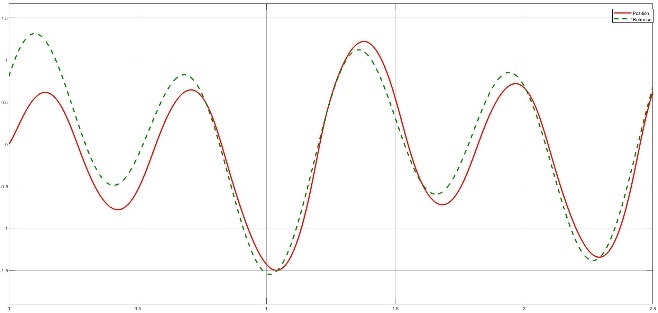 | Figure 1. Reference signal (dotted green) 5th harmonic function with amplitudes of 0.1, 0.5 and 1 and Lyapunov controller output (red) for t=2.5s |
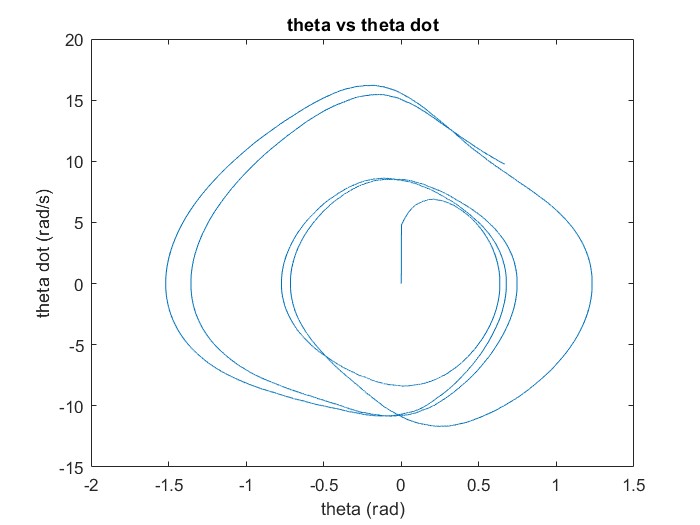 | Figure 2. Phase portrait showing a stable system with no interference under the harmonic reference signal t=2.5s |
5. Lyapunov Controller Parameteroptimization
5.1. Overview
- The process of selecting the proper Sigmas to reduce the error of the model can be modelled as an exhaustive search problem. Where several Sigmas are tried and the one that results in a reduction in the system error is selected. Though this process results in the best Sigmas, yet it is time consuming. To overcome this problem, we developed a deep learning model that researches different system and controller parameters. A given sigma is good if it reduces the error of the system. The pipeline is presented in Fig. 5. Initially, the model is run, and the system error is monitored. If the error surpasses a curtain threshold the neural network is queried for a sigma that would reduce the system error given the current state of the system. The algorithm for the entire process is defined below. The network proposed in Fig.3 is initially trained and then used to predict new Sigmas; Sigma 1 (s1), and Sigma 2 (s2) if the system error (sys err) exceeds a given threshold (0.8).
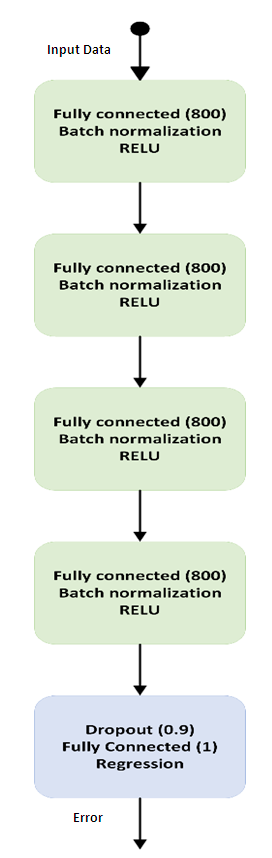 | Figure 3. Neural network used for predicting the best Sigmas that would result in a decrease in the system error. The input to the network is the time (t), displacement (x), velocity (v), Sigma 1 (s1), Sigma 2 (s2) and the output is the expected system error (Error) for the system. s2 = - s1/8 |
 | Algorithm 1. Adaptive Algorithm Steps for Sigma prediction |
5.2. Dataset
- The Time, Error, velocity, position and control signal were collected every 1 millisecond and added into an array of values. The dataset was split into 60% training and 40% test. A continuous update to the dataset is done according to the calculated error slope every 10ms (100 iterations) as explained above.
5.3. Network Architecture
- The network architecture is in Fig. 3 The network is composed of 5 blocks (15 layers). The number of layers 15 was chosen for its efficiency and high performance. It was found that if a lower number of layers is used the DNN performance was affected and when a higher number of layers was used it had no effect on the performance but reduced the DNN efficiency. A block is composed of 3 layers: a fully connected convolution layer followed by batch normalization layer and rectified linear unit (RELU) in Eqn.14.
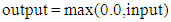 | (14) |
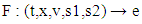 | (15) |
5.4. Network Training and Testing
- The network is initially trained for 5 epochs using Adam optimization algorithm. The learning rate is initially set to 0.001 and is reduced by a factor of 0.2 every 5 epochs. This allows large weight changes in the beginning of the learning process and small changes or fine-tuning towards the end of the learning process. This gives more time for fine-tuning. While the model is running if the system error passes a given threshold the Neural network is used to choose two Sigmas that would lower the error. This is done by selecting a uniformly distributed random number in the interval [-50, 50] for s1. The restriction of s1 and s2 was added later in the research to avoid the genetic algorithm and DNN going into a continuous loop of changing the Sigmas to find the perfect candidate. It was also found that the smaller the sigma the better the system outcome but in order to maintain controller flexibility the range was set to [-50, 50] to account for unexpected changes in the system behaviour. The network does not pass the proposed Sigma 1 and Sigma 2 to the model and controller unless Sigma 1 and Sigma 2 are predicted to reduce the system error. This helps in tuning the entire pipeline to take small/large steps to change the behaviour of the duffing van der pol model given that sudden large changes in the Sigmas may result in system failure. The idea behind predicting the error and not the Sigmas is the fact that we can have more than one error for a given Sigma, which gives more flexibility for choosing the range of sigmas to consider. The root of the mean square error graph for the first 5 epochs are plated in Fig. 4. The results show that the neural network presented in Fig. 5 was able to predict the error with an error of 0.03564.
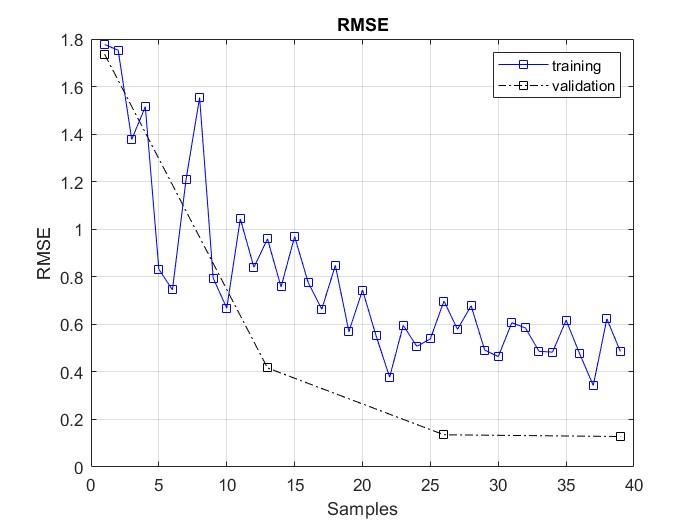 | Figure 4. Neural network used for predicting the best Sigmas that would result in a decrease in the system error. The input to the network is the time (t), displacement (x), velocity (v), Sigma 1 (s1), Sigma 2 (s2) and the output is the expected system error (Error) for the system |
6. Results and Discussion
- In Fig. 5 the system is shown to go into instability and fails 0.3 seconds from start due to the use of unfit Sigma 1 = 100 and Sigma 2 = 0.6 while in Fig. 5 we show that using the proposed deep neural network to predict the appropriate Sigma 1 and Sigma 2 lead to stabilizing the system and maintaining the system error under the set threshold.The results show the efficiency of the neural network in predicting the error given the sigma, as well as the efficiency of the algorithm in preventing the system from failing likewise in continuously enhancing its performance by keeping the system error as low as possible. On the other hand, maintaining a constant sigma results in large system error and the system might eventually fails.
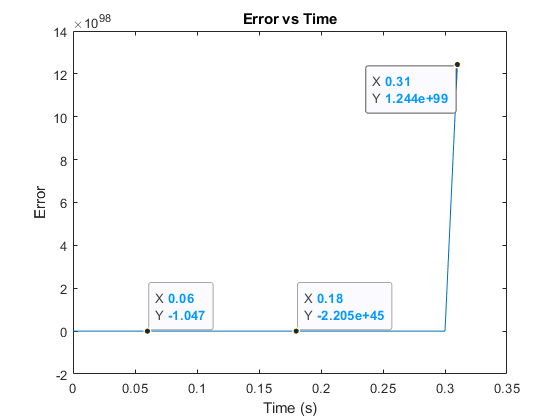 | Figure 5. The system error goes to infinity as shown when the algorithm is not applied |
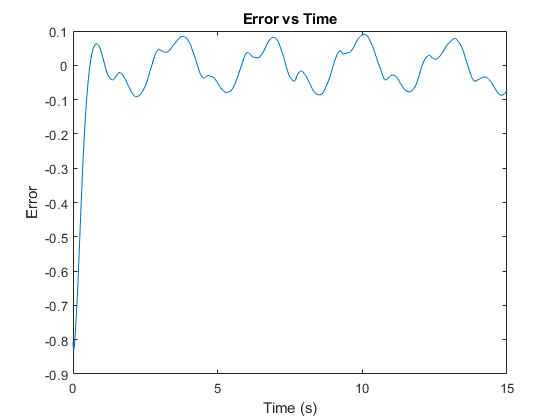 | Figure 6. The system error after using the neural network in Fig. 7 to get a good estimate of s1 and s2 |
6.1. Algorithm Reaction to Parameter Sabotage
- To elaborate on the ability of the proposed solution to tackle mid system instability or sudden changes. The system parameters are manually overwritten while the system is running to measure the NN and Algorithm effectiveness in returning the system to stability.As demonstrated by Figs 7 and 8 the deep network was able to predict the best parameters to re-establish stability of the system and controller within 0.4 ms.
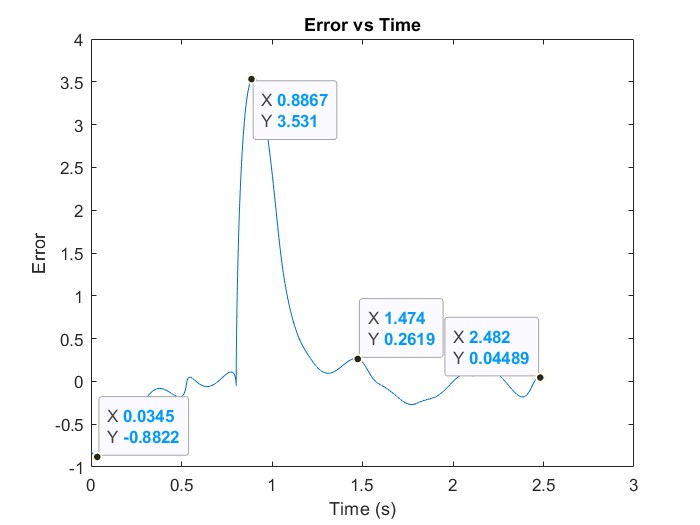 | Figure 7. Error uptick at t = 0.8867 |
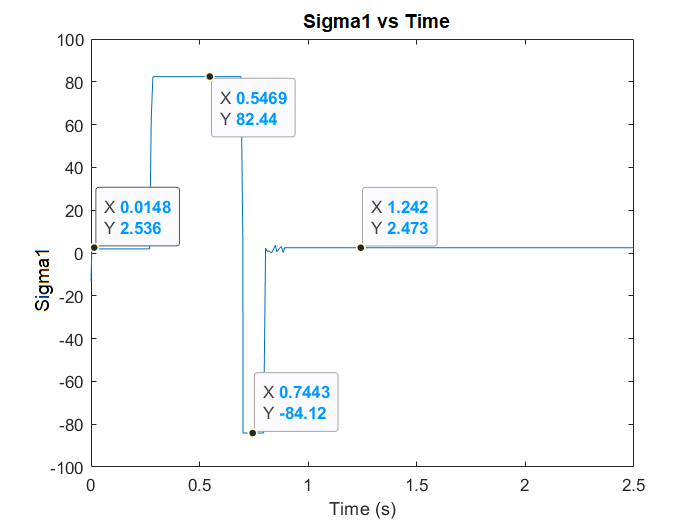 | Figure 8. The Algorithm reacting to the sudden change by adjusting Sigma 1 |
6.2. Improving the System Performance
- In this section we show the ability of the proposed method in finding the best system parameters while the system and controllers are running.
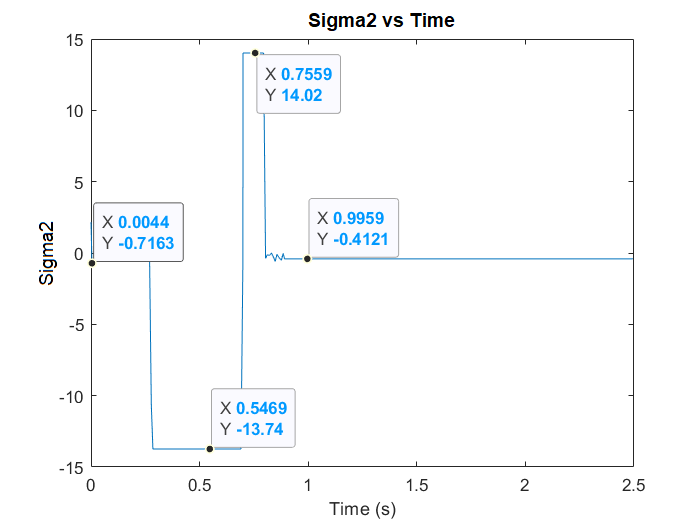 | Figure 9. The Algorithm reacting to the sudden change by adjusting s2 |
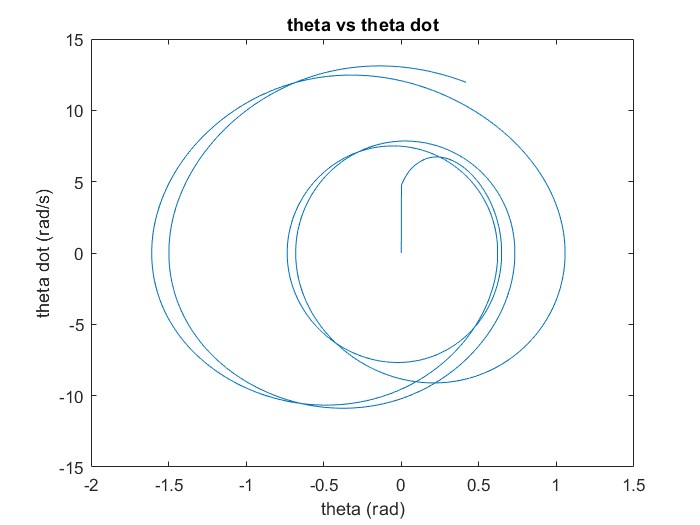 | Figure 10. Phase diagram of the algorithm before and after finding the optimal system parameters for the conditions which shows major improvement compared to Fig.4 |
6.3. Network Retraining
- During the re-training phase of the neural network we noticed that without the use of the memory it might take longer and, in some cases, go into an infinite state without finding the optimum solution. The speed with which the system returns back to it stable state affects the retraining phase as we only consider the change in the average of the system error. If the difference between the previous system error average and the new system error average is not large enough then the condition for retraining won’t be met and the system will get stuck trying to find a pair of Sigmas that would result in error reduction. This won’t be possible without memory because the moment the network is retrained the new data overwrites the information learned by the network. The use of memory allows the network to remember the stable and perturbed history of the system parameters.
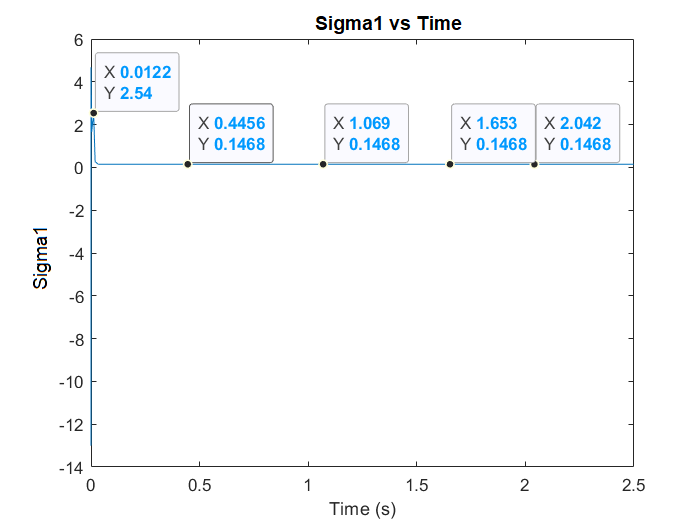 | Figure 11. s1 and s2 are changed while the system is running to improve performance and reduce error |
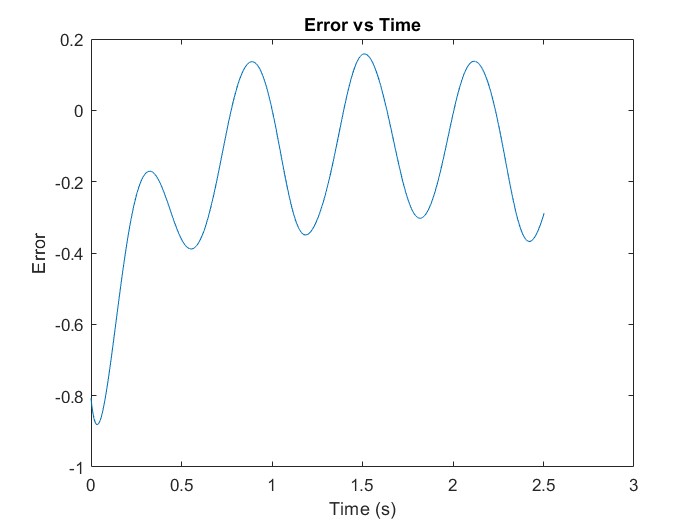 | Figure 12. Error is shown to be reduced from the starting point by updating the system parameters and the algorithm is successful in maintain the error within bounds |
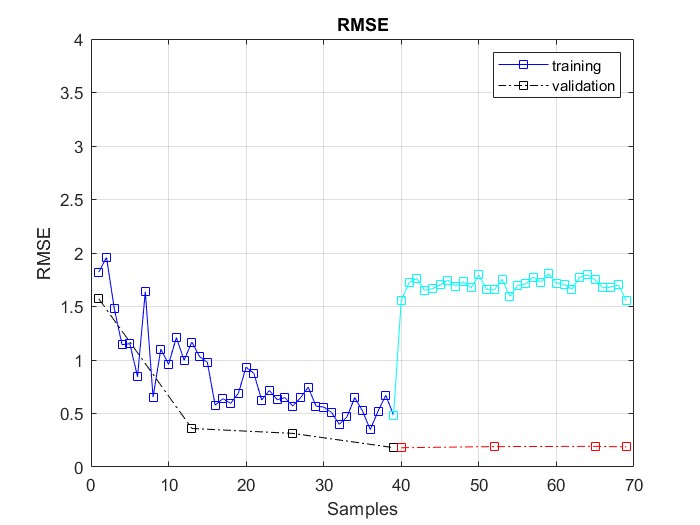 | Figure 13. Re-training to improve the deep neural network performance in order to adapt to the introduction of new system dynamics |
7. Conclusions and Future Work
- Lyapunov control was applied to Duffing- van der pol oscillator model that is experiencing chaotic behaviour. The study shows the effectiveness of deep learning combination with nonlinear Lyapunov control in finding the best parameters to maintain system stability. The study shows that deep learning with the proposed algorithm enables the user to effortlessly find the best parameters for the controller and the system initially and recalibrate the parameters if any disturbances or new dynamics are introduced to the system. In future work we would like to investigate the effect of changing the control strategy according to the type of instability detected. We speculate that depending on the type of perturbations and system dynamics, changing the control strategy might be more effective than changing the parameters only. Future considerations include a network that can determine which control strategy would have the highest impact on returning the system to stability and cause error reduction. The proposed approach can be aided with the use of generative adversarial networks (GAN).