-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2026; 16(1): 1-12
doi:10.5923/j.computer.20261601.01
Received: Dec. 20, 2025; Accepted: Jan. 15, 2026; Published: Jan. 23, 2026

Enhancing Phishing Attacks Detection by Optimizing URL Features Selection in Machine Learning-based Approach
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLSami El Flesh1, Muhammad Abdullah1, Abdulhamid Zaidi2
1Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Malaysia
2Department of Electronics and Computer Engineering Technology, Bailey College of Engineering and Technology, Indiana State University, Terre Haute, Indiana, USA
Correspondence to: Sami El Flesh, Department of Computer Science, Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, Serdang, Malaysia.
| Email: |  |
Copyright © 2026 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Despite ongoing efforts to enhance phishing detection methods and strategies, the use of cut-off ratings has primarily served to improve classification accuracy. However, current research is shifting toward URL feature discovery and machine learning approaches. Most contemporary anti-phishing studies focus on proposing novel feature selection techniques or optimizing classification algorithms. To the best of our knowledge, there remains a lack of reliable, effective, and systematic frameworks for feature selection that address the persistent inaccuracies in phishing detection. This gap stems from the limitations of existing feature selection algorithms, which often lack a rank identifier to determine the most optimal and impactful set of baseline URL features for phishing classification. Furthermore, the absence of a structured approach to refining these baseline features for machine learning classifiers exacerbates the problem. In this paper, we propose an algorithm that introduces a feature cut-off rank identifier. This mechanism benchmarks and selects features that exceed a defined threshold, ensuring only the most relevant attributes are used for phishing classification. Additionally, we present a systematic feature selection framework that employs data perturbation and data function perturbation ensembles to generate optimized baseline features. Experimental results demonstrate that these optimized features, when integrated with a Random Forest classifier, can accurately distinguish between phishing and legitimate websites with an accuracy of approximately 97%.
Keywords: Features selection, Machine Learning, Naïve Bayes, J48, Random Forest, Random Tree, REPTree, Spam email detection, SVM
Cite this paper: Sami El Flesh, Muhammad Abdullah, Abdulhamid Zaidi, Enhancing Phishing Attacks Detection by Optimizing URL Features Selection in Machine Learning-based Approach, Computer Science and Engineering, Vol. 16 No. 1, 2026, pp. 1-12. doi: 10.5923/j.computer.20261601.01.
Article Outline
1. Introduction
- Technology evolution is rising quite rapidly with the tremendous expansion of digital age that provides us with all the privilege of being at the forefront of the ongoing endeavor that has the high potential to uplift and shape our lives and future generations around the globe, digitality connected technology enabled us to be more efficient by leveraging on online services; especially in the past few decades, where many services become available online for our convenient such as online shopping, online banking, social media, government services, and many more. This evolution was the drive to the significant increase in online consumers and subsequently the phishing arracks are continuing to grow, with many instances still going unreported or underreported. In Figure 1 an illustration of a phishing campaign conducted in one of the oil services companies’ operating in Malaysia on quarter basis rollout to evaluate the reporting and susceptibility for approximately 2800 employees. The obtained responses are categorized in 4 indictors as below:
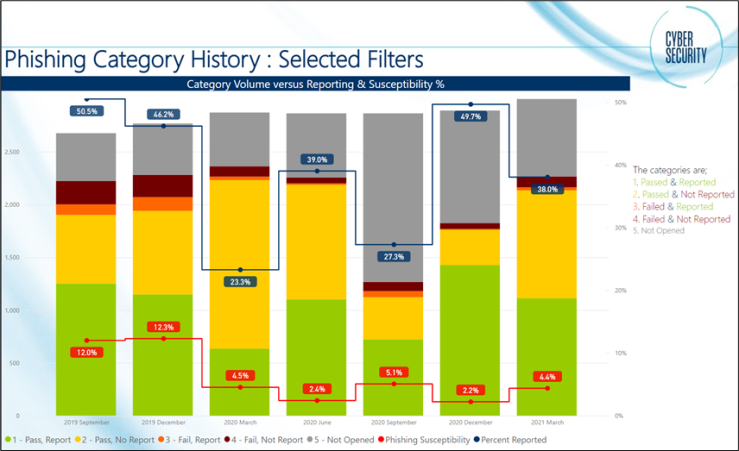 | Figure 1. Phishing Campaigns Reporting and Susceptibility |
2. Literature Review
- In this section we will share some of the comprehensive reviews and detailed discussions that researchers already published in the form of journals or conference proceeding to shed more light on the problem we are addressing which is phishing detection accuracy. By reviewing related work in the phishing detection and the classification methods and techniques has been employed by researchers to distinguish the legitimate URLs from the phishing ones.The risk of phishing exposure well known and recognized. In the 90s where a group of hackers called Warez community also known as first “phishers” have impersonated as American Online (AOL) employees and deceived the AOL’s users to collect their personal information and login credentials. As a global leader in internet service provider at that time with approximately a million subscriber and online consumers of their services. This indeed led to drag the hacker’s attention to conduct the phishing first seeds and since then the phishing tactics evolving until today. Thus, in order to better understand the evolution to phishing and anti-phishing techniques, we conducted an extensive literature review of the most relevant researches utilized URL features algorithms and machine learning.Historically, there are many phishing detection techniques and approaches has been employed by many researchers over the time and technology evolvement since the evolution of phishing where by some of the proven approaches might not be relevant today and to cope with the fast evolving technologies and significant increase of internet and communications consumers, exploring more efficient and automated approached become essential to leverage on more relevant technologies such as machine learning. To be more aligned with the research objectives and the attended approach for our methodology, we can categorize the methods that been employed in detecting whether the URL is phishing or legitimate into none-machine learning techniques and machine learning techniques.A. CONTENT AND SEARCH-BASED APPROACHIt is worth to mention that the main goal of phishing ULRs and webpages is to deceive online consumers and users around the global into making the websites they are consuming, and surfing look like a legitimate. The content-based analysis approach utilizing deep analysis of webpages contents and extract features via classifiers algorithms and use other services such as DNS servers, and search engines. This method relies highly on the visual content similarities to distinguish between phishing and legitimate websites. [1] have proposed a weighted classifier to decide if the words that extracted from HTML content and URLs, where those words might indicate any characterization of phishing setup for instance a brand name to replicate a legitimate website content. The weights are measured according to their location within the URLs. Then, the measured weights decoupled with the relevant term frequency-inverse document frequency (TF-IDF) weight, in a form a numeric presentation that illustrate the significant of any word to a document frequency, after that based on the world’s highest probability a list of words sent to search engine to get the highest frequency domain name among the top thirty outputs. At the end, a decision will be made if legitimate or phishing website by comparing the owners of nominated domain name which returned by WHOIS service. Although the proposed methodology seemed promising and giving the expected results, yet it’s still limited to words contained in the websites and not utilizing the features lookup from the URLs.In detecting phishing based on websites contents [2] proposed a methodology that analyze the logo images to identify whether if the relevant website identity is matching a phishing or legitimate website. The proposed solution consisted of logo extraction and identity verification. For the first step which is logo extraction as it is very difficult to distinguish which image is a logo and to have more realistic approach, they decided to download all the images by query the webpage and applied a subprocess to exclude any images unlikely to be a logo and for that the criteria defined as any image with one color scheme or any image with a width or height of less than 10 pixels. The in the second step which is verification of identity by utilizing Google Image search database the portrayed identify then retrieved. This allowed them to perform the identify comparison and validation and because domain name has relation with the logo, the domain name was considered the identity. Therefore, comparing the domain name returned from the query website with the one returned by Google Image search. The accuracy achieved by the proposed approach concluded as 93.4%. Yet, while the outcome looks superb, the True Negative Rate still low and giving the fact that it needs to download all the images to perform logo identification seemed a bit excessive computational process where other technologies might be more efficient for image process such as image recognition utilizes. Focusing on more lightweight detection approach using search engines for phishing website [3] introduced the lightest possible attributes/features namely domain name and page title instead of loading the complete webpage only these two features can be extracted. An n intelligent anti-phishing chrome extension was developed named light weight phish detector (LPD). The developed extension also suggests the webpage authenticity on top of detection. The LPD used very light features to identify phishing websites, but it may result a false positive over evolved and recent launched websites where phishers indeed will find it easy to deceive such lightweight utilizing only two features.B. FEATURE SELECTION AND MACHINE LEARNING APPROACHThe URLs features basically you could describe it as a combined number of attributes that form a unique path on the internet to reach out to a specific destination. This can be number of dots in the webpage URL, level of domain, URLs’ length, HTTPs exist or not, number of ‘@’, if ‘//’ exists in the path of webpage URL. The feature selection and machine learning approach now days significantly utilized by many researchers in the recent researches due to the promising results of increased accuracy as well as the automation aspect that brought by the machine learning concept. [4] conducted an evaluation comparison of few conventional feature selection methods to benchmark the performance of the feature selection methodology, which include correlation Based Feature Selection (CFS), filter measures such as (Relief-F and IG) and the wrapper method. According to results in findings the wrapper approach together with the best first forward search demonstrated an outperforms feature subset derived by Relief-F and Information Gain, whereas Correlation Based Feature Selection (CFS) showed the lowest performer. Also, the obtained results clearly indicate the effectiveness of predication and the consistent performance of Random Forest classifier compared to SVM and C4.5 classifiers. However, in some cases where performance come with a cost, in this case the computational overhead was a drawback for the wrapper method, which made it not the preferred method, hence the focus should be on optimizing the features filter measures to overcome the computational overhead concern and find less intensive computational methods. Evaluating two common features selection methods is the research base conducted by [5] namely wrapper and Correlation Based Feature Selection (CFS), where an experiment has been performed to test feature space searching methods and to be more specific both generic algorithm and greedy forward selection were the candidates applied on features extracted from the webpage itself combined with search capabilities. In this experiment the Classifiers Logistic Regression, Random Forest and Naive Bayes were used to evaluate the feature subsets performance. The obtained results revealed that wrapper method achieved highest detection accuracy compared to CFS. Yet, the wrapper method as well known it is more computationally intensive, hence it was not the preferred approach in the applications of feature selection. [6] have decided to evaluate 47 URL features to detect phishing URLs by using Chi-Square ranked values, Information Gain (IG) and correlation Based Feature Selection (CFS). The authors have observed a considerable reduction in the values of filter measures in the range of 20th to 21st features and have utilized this range gap as cut-off ranker in the values of filter measure to nominate top 20 features as baseline subset features. Although the results showed a stable detection accuracy when the nominated features subset are used, yet, while the results were showing a consistent and stable performance, it is not very clear on how they achieved the identification of the cut-off ranker computational wise. Further experiments have been conducted by using only 12 ULR features that produced as an outcome of intersecting the features subsets of IG, Chi-Square and CF. As per the results an impact of only (0.28%) in average decrease in accuracy in comparison to the accuracy of the full feature set. Thus, the proposed intersecting features subsets approach demonstrated the effectiveness of optimizing the feature dimensionality without necessarily impacting the accuracy performance.Similarly, by investigating the benchmark subset features [7] employed IG and Chi-Square to identify the benchmark of features subset for phishing detection. A systematic way to identify the cut-off ranks for features ranked by Chi-Square and IG was suggested by the authors. The proposed method was about threshold-based rule, where the cut-off ranks defined as a minimum two successive features with 50% variation in values of Chi-Square and Information Gain attributes rankers. The idea is to look at the value when the cut-off rank is triggered and compare the value against the recommended minimum value of filter measure. If it was below should be excluded.Leveraging on Information Gain (IG) and C5.0 classifier, [8] have decided to use the ranking among 40 gathered from previous techniques to detect phishing and spam. The analysis done by the authors was mainly by utilizing Information Gain (IG) ranker to three different datasets to cross-rank the features, with an objective to identify the most effective subset of features. By applying the intersection function over the top 10 features that already ranked by IG. On the other hand, using the obtained three feature sets evaluated the accuracy utilizing C5.0 classifier and the results revealed that the feature sets with higher IG valued outperformed the feature sets with lower IG values. However, the assessed performance was very limited to only one filter measure, namely IG. Ideally to have more productive study a minimum and common filter measures should have employed to provide some good insights. Using natural language processing together with machine learning a detection algorithm was proposed by [9] to perform a semantic based analysis of the content of the text to validate each sentence appropriateness. By applying Natural language processing (NLP) to extract and parse each sentence and based on the words analysis the algorithm tries to predict if the sentence is a command or a question, then the potential topics of the commands and questions are extracted by finding verb-direct object pairs and then each pair checked against topic blacklist database. The machine learning role is to generate the blacklist of suspected malicious pairs based on the training dataset. Yet, not enough experiments have been conducted and results only compared with Netcraft, also this approach relies on interception and analysis of texts in the email body which might not be a valid criteria after a while as the attackers become smarter every day and they learn from all the existing anti-phishing approaches.[10] proposed a phishing detection approach by using a feature selection framework that automatically nominating the most optimized URL features among the extracted 48 features extracted from the URLs by an invented algorithm called CDF-g in which works to determine the top effective features in machine learning via patterns recognition of filter measures values, thus theoretically should not be explicitly work for a specific dataset and forming more adaptive approach to other datasets as well. [11] found that nominated features baseline resulted from the proposed approach yield to a promising outcome when the baseline dataset leverage on the Random Forest Classifier compared to other classifier used in the experiment by achieving (94.6%) of detection accuracy using (20.8%) of the original features, in addition of accuracy the results revealed that the proposed solution by [12] computationally more lighter given that only (20.8%) of the original feature scope utilized and yet the results still competitive compared to other features sections proposed by other researchers in the related work.AdaBoost and MultiBoosting approach was proposed by [13] where every instance from the training dataset assigned with the associated equivalent importance by weighting the instance according to classifier’s output aiming to decrease the correctly classified instances, while increasing the incorrectly classified instances. This will lead to generate 2 sets low importance and more challenging. Then a classifier will eb built for the categorized data sets with more focus on the more challenging instances. And the weights of each instance are augmented in accordance with the new classification performance, with this exercise increase the possibility to identify and reclassify more challenging instances to low importance category. Adaboost with SVM classifier outperformed in term of detection accuracy. Nevertheless, the dependency on webpages content requires more testing to prove the performance consistency.Web pages contents extraction, URL feature extraction and high dimensionality optimization were the proposed technique by [14]. The main idea was to fine tune the extracted web pages contents and URLs features as a combination, then applying the high dimensionality minimization to reduce the variables set. Furthermore, the fins tuned dataset tested applying the machine learning classifier to measure the performance of the proposed model and compare it with results highlighted in related work section. The (SVM) support victor machine algorithm was the only classifier applied and the results reveals that the proposed model achieve better performance accuracy comparted to other classifiers. However, the results require further prove and investigation since the comparison used did not represents the actual performance since the results compared against neither used the same dataset nor the same classifiers.While previous related work has focused on different techniques and approaches to tickle phishing detection accuracy, yet the efforts towards optimized feature selection frameworks still evolving. [14] and [15] leveraged on webpage contents technique. However, this approach is either comes with high dependency on webpage content or very limited features were included in the scope. Also, the webpage content approach incudes but not limited to visual analysis which might be an overhead computational wise. Overall, the webpage contents technique might work very well, but from the effectiveness, automation, and computational standpoint this can be a limitation to adopt such techniques.On the other hand [16] used natural language processing techniques and machine learning to analyze the email content and identify some keywords that potentially can help to classify the email if legitimate or phishing by checking it against a list of maintained sensitive words or sentences. However, the attackers keep evolving and learn from the existing anti-phishing techniques to evade such approach. Besides that, maintaining the list of words can be a hassle and of course another dependency that we should try to avoid.[17] employed the attribute ranker approach to identify the baseline features. Only Information Gain (IG) was performed, and consistency nine features has been nominated across three different datasets, hence the obtained results not sufficient to conclude the achievement and effectiveness of the proposed framework.
3. Research Method
- The main purpose of this chapter is to shed some light on the proposed research methodology and how it was conducted to accomplish to achieve the research objectives of this research. In this chapter the methodology will be presented in a flowchart form to illustrate the high level of overview, followed by elaboration about each phase have been utilized. After extracting the baseline features dataset from the full features’ dataset, then apply different features ranking algorithms on different classifiers to realize the effect of feature selection and evaluate its impact on different type of classifiers using default settings and parameters offered by Weka Tool without expensively drilling down to fine-tune the parameters of classifiers. Our proposed methodology as illustrated in Figure 2.
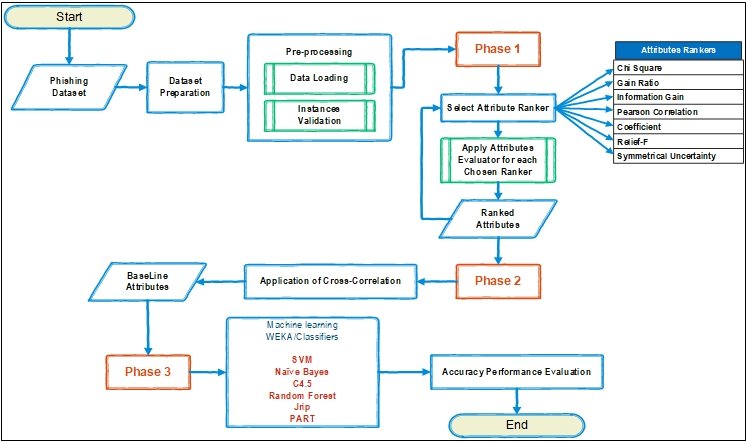 | Figure 2. Methodology Flow-chart |
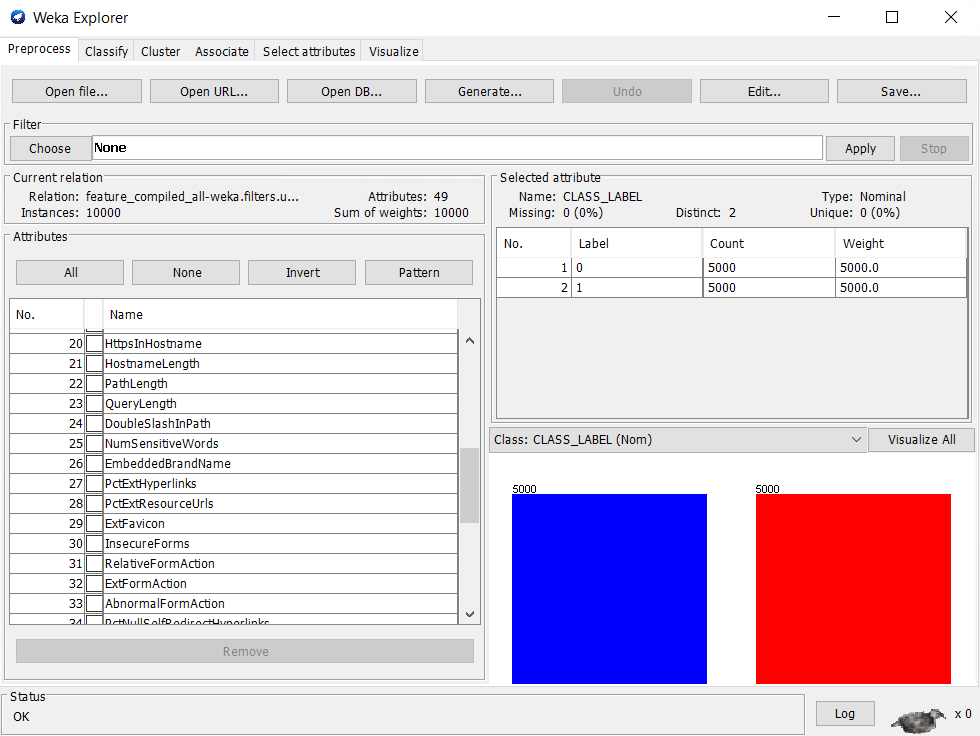 | Figure 3. Dataset Loading and Validation |
|
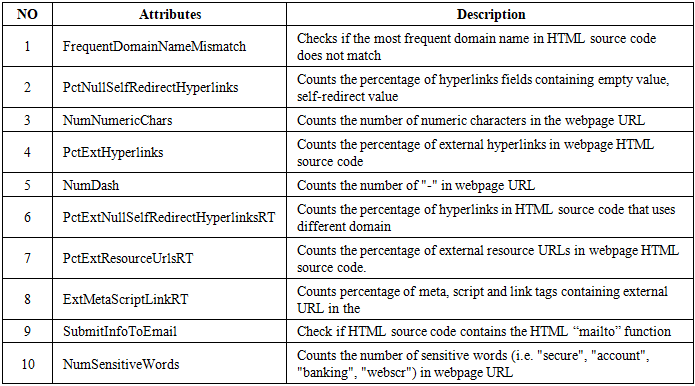
 | Figure 4. Example of Ranked Attributes Using Chi-square |
 | Figure 5. CCAR Algorithm |
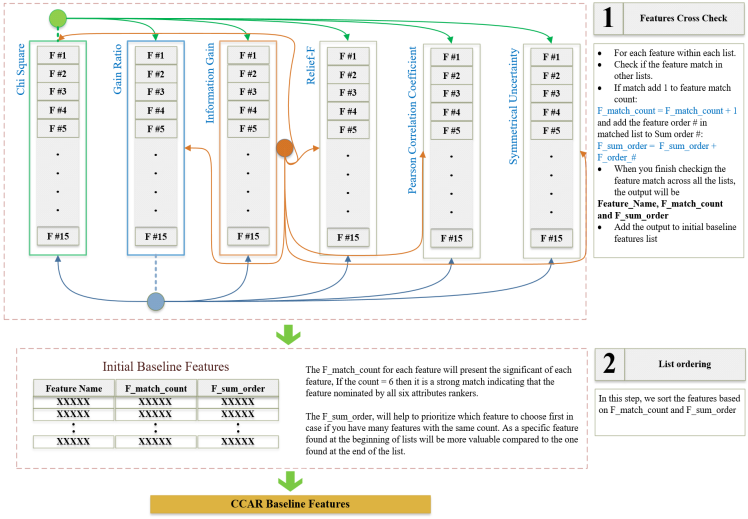 | Figure 6. Overview of the CCAR Framework |
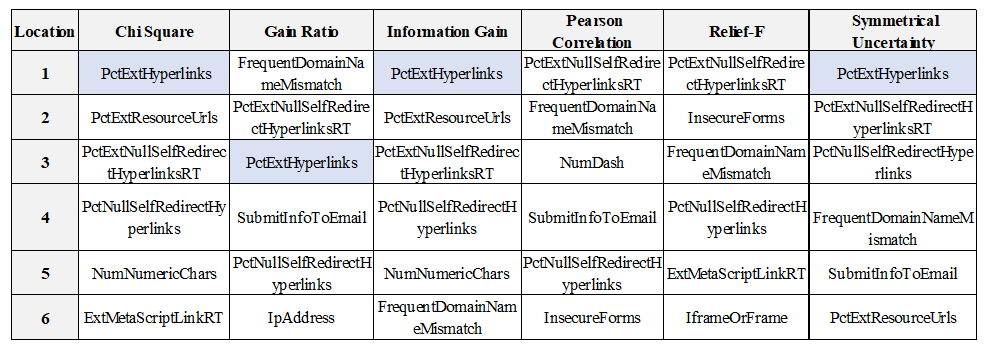 | Figure 7. Example of the CCAR Framework |
|
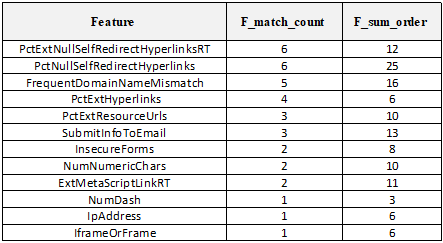
 | Figure 8. Illustration of Confusion Matrix |
4. Results and Discussion
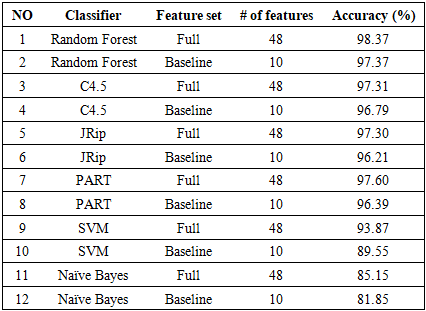
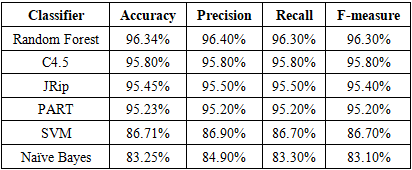
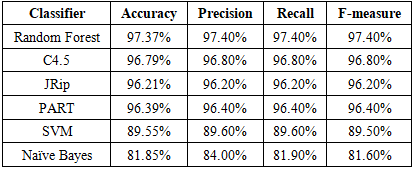
- The experiment conducted on the following hardware specifications:• Processor: Intel Core I5-2430M 2.4Hz• Memory: 8 GB DDR3• Hard Disk: 50 GB.This section we will shed some light on the redeployment results and discuss the findings, followed by the evaluation of the proposed methodology and the obtained results. Our proposed methodology called cross-correlation helps to identify the optimal features sub-set by excluding the least significant features. Our proposed method.is divided into three stages starting with applying the attributes ranker evaluators on the full dataset to generate a set of most significant features. After that we use cross-correlation function to generate the optimized baseline features and use these features to evaluate and compare our results with the HEFS techniques on different types of machine learning classifiers. Phishing attacks has been proven to be the most effective for hackers counting on the weakest line of defence in the security system which is the end-users. Hence our proposed method aiming to address and contribute to the ongoing efforts to determine the phishing attacks as accurate as possible.The goal of this experiment is to evaluate the effectiveness of the proposed baseline features in term of accuracy performance against six different machine learning classifiers algorithms namely Random Forest, C4.5, JRip, PART, Naïve Bayes and SVM. This is done by applying both full baseline features and proposed baseline features in all the aforementioned machine learning classifiers.
|
|
|
|
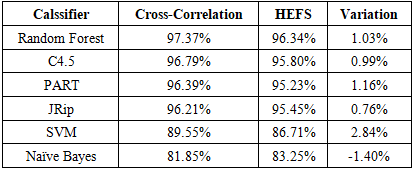
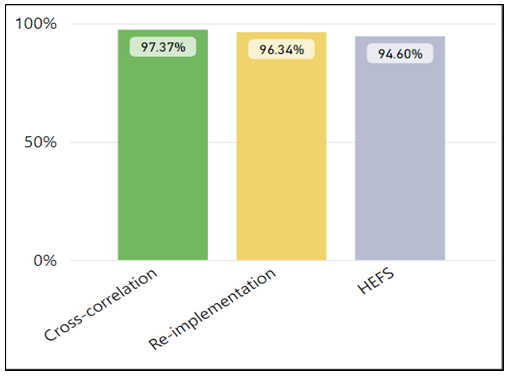 | Figure 9. Evolution of Accuracy Performance of HEFS, Re-implementation and Cross-Correlation |
5. Conclusions
- Phishing attacks and social engineering tactics are getting more sophisticated, more targeted, and more advanced. Despite all the efforts towards the anti-phishing techniques, there are many phishing attacks instances gone unreported. This is raising a major concern since the human factor plays a significant role in the anti-phishing defence system, hence leveraging on technology became prominently a must to automate the phishing detection with highest accuracy possible and shift the overburden load from end users to technology.The main objective of this project is to improve the accuracy of phishing attack detection by reducing the false positive rate. In order to achieve that, we proposed a feature selection technique called cross-correlation attribute ranker (CCAR) by leveraging the existing attributes rankers’ algorithms such as Information Gain, Gain Ratio, Chi-Square and few more. To evaluate the effectiveness of the proposed technique, we have measured and compared our results with the benchmark scheme called HEFS. Results show that our proposed technique clearly suppress almost all the accuracy obtained by the HEFS scheme. Although, several results obtained from our proposed work are not as accurate with the HEFS scheme. The obtained accuracy results are acceptable considering the significant reduction of the number of features being used in our evaluation.
6. Future Work
- About future work, writing code for the proposed cross-correlation model CCAR can improve and automate the process and potentially to explore more attributes rankers on top on the six rankers used in our project. Also, exposing the baseline features to other datasets can also help to validate the effectiveness of the proposed model and baseline dataset. In addition, exploring more machine learning classifiers can be another area for future work direction. Furthermore, looking at more optimizing baseline features without compromising the other performances could also be one of the promising future work directions.