-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2024; 14(6): 155-161
doi:10.5923/j.computer.20241406.05
Received: Sep. 28, 2024; Accepted: Oct. 16, 2024; Published: Oct. 18, 2024

Leveraging Large Language Models for Log Mining: A New Paradigm in Data Analysis
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTML1Cisco Systems, San Jose, CA, USA
2Indiana University Bloomington, Indiana, USA
Correspondence to: Abhishek Gupta, Cisco Systems, San Jose, CA, USA.
| Email: |  |
Copyright © 2024 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Log mining is a crucial task in IT operations, security, and software development for identifying anomalies, patterns, and trends in system logs. Traditional methods for log analysis rely heavily on rule-based approaches or machine learning models that require significant feature engineering. The rise of large language models (LLMs) presents a novel opportunity for log mining, given their ability to understand unstructured text and learn from contextual patterns without extensive pre-processing. This paper explores the potential of LLMs for log mining, discusses challenges, and proposes a framework for their effective application. We demonstrate that LLMs can automate anomaly detection, failure prediction, and even root cause analysis in log data, surpassing conventional approaches in flexibility and efficiency.
Keywords: Data Analysis
Cite this paper: Abhishek Gupta, Leveraging Large Language Models for Log Mining: A New Paradigm in Data Analysis, Computer Science and Engineering, Vol. 14 No. 6, 2024, pp. 155-161. doi: 10.5923/j.computer.20241406.05.
Article Outline
1. Introduction
- Logs are a vital component in the lifecycle of modern computing systems, offering a wealth of information about system states, errors, and user interactions. With the increasing complexity of distributed systems, the volume and variety of logs generated have grown exponentially, making manual log analysis increasingly impractical. Conventional log mining techniques depend on structured logs or predefined patterns for anomaly detection and root cause analysis. However, these methods struggle with the vast diversity of log formats and the ambiguity inherent in natural language messages.Large language models (LLMs), such as GPT-4, BERT, and their variants, have shown exceptional proficiency in understanding and generating natural language, making them prime candidates for log mining. These models can process unstructured and semi-structured log data, identifying patterns, anomalies, and correlations without the need for manual feature extraction or complex preprocessing pipelines. This paper explores the application of LLMs in log mining, examining their benefits, limitations, and potential use cases.
2. Motivation
- The complexity and scale of modern IT systems and applications demand more sophisticated tools for log mining. The rise of cloud computing, microservices, and distributed architectures has increased the volume, velocity, and variety of log data. LLMs, with their advanced understanding of language and ability to model context, offer a promising approach to tackling these challenges. Their potential to process logs as semi-structured or unstructured text makes them highly adaptable across industries and use cases.
3. Background
- Log MiningLog mining involves the extraction of meaningful insights from log data generated by systems, applications, and devices. The primary goals of log mining include:• Anomaly detection: Identifying unusual events that may indicate failures, security breaches, or other issues.• Failure prediction: Forecasting system failures before they occur based on historical data.• Root cause analysis: Determining the underlying cause of a failure or anomaly by tracing the sequence of events.• Pattern recognition: Discovering recurring behaviors, trends, or dependencies within logs.Traditional Approaches to Log MiningTraditional methods rely on structured query languages, regular expressions, or custom rules to parse and analyze logs. While these methods work well for structured logs, they struggle to handle unstructured logs or discover hidden patterns across heterogeneous log formats. Recent advances in machine learning have introduced models that can learn from structured logs, but these models typically require significant domain expertise to engineer relevant features.Rule-Based SystemsHistorically, log mining has relied on rule-based systems. These systems utilize manually defined patterns, keywords, or regular expressions to parse and extract meaningful information from logs. While effective for well-understood, repetitive patterns, they often fail in dynamic environments where logs change in structure or content. Rule-based systems struggle to generalize across different log types, leading to an increased maintenance burden.Machine Learning-Based MethodsMore recently, machine learning techniques have been applied to log mining, particularly for anomaly detection. These methods involve supervised or unsupervised learning, where models are trained on historical log data to classify normal and anomalous behaviors. However, machine learning approaches require significant data preprocessing, feature engineering, and labeling efforts, which limit their adaptability and scalability across different log formats.Large Language Models (LLMs)LLMs, particularly transformer-based models, have revolutionized natural language processing (NLP) tasks such as text classification, machine translation, and sentiment analysis. These models are pre-trained on massive corpora and fine-tuned for specific tasks. By capturing complex syntactic and semantic relationships in text, LLMs offer significant advantages over traditional NLP techniques:• Contextual understanding: LLMs consider the context of words and phrases in large text segments, making them more robust for unstructured text analysis.• Pre-training and fine-tuning: LLMs can be pre-trained on large, generic corpora and fine-tuned for specific tasks like log analysis.• Transfer learning: Pre-trained LLMs can generalize across multiple domains with minimal additional training, making them suitable for diverse log sources.Advantages of LLMs in Log MiningLLMs bring several advantages over traditional log mining approaches:Understanding Semi-Structured and Unstructured DataUnlike traditional methods that require strict log format rules, LLMs can handle semi-structured and unstructured log data. This flexibility is crucial in environments where logs vary in structure, such as across different microservices or applications. LLMs can process logs in a manner similar to natural language, identifying meaning and relationships even when the log entries are verbose or inconsistently formatted.Contextual UnderstandingLogs often contain sequences of events that are contextually related but may not appear obviously connected in traditional log analysis. LLMs excel at understanding contextual relationships across sentences or log lines, which helps in identifying causality, correlating events, and performing root cause analysis. By analyzing logs holistically rather than line by line, LLMs can improve the accuracy of detecting complex issues.Anomaly DetectionAnomaly detection is a critical task in log mining, especially for detecting security incidents or performance degradation. LLMs can be fine-tuned to detect subtle deviations from normal log patterns, leveraging unsupervised learning to automatically identify outliers without needing predefined rules. Additionally, LLMs can use their language comprehension capabilities to interpret the meaning of anomalies, offering explanations rather than just flagging errors.Scalability and TransferabilityLLMs can be easily scaled across different systems and applications. Since they are trained on a wide corpus of data, LLMs can generalize across different log formats, whether they come from cloud environments, web servers, or network devices. This transferability reduces the need for custom log parsers or format-specific configurations, making them ideal for heterogeneous IT environments.Multi-Task CapabilitiesOne of the most significant advantages of LLMs is their ability to perform multiple log mining tasks with a single model. For example, the same LLM can be used for:• Anomaly detection• Log summarization• Query generation• Pattern extraction• Root cause analysisThis reduces the complexity of maintaining separate tools or models for different tasks and provides a unified platform for log mining.
4. Case Study
- The ELK Stack helps by providing users with a powerful platform that collects and processes data from multiple data sources, stores that data in one centralized data store that can scale as data grows, and that provides a set of tools to analyze the data. It very predominantly used for log analysis and search use cases.The ELK Stack (Elasticsearch, Logstash, and Kibana) is popular because it provides a powerful, flexible, and scalable solution for log and data analysis. Collects and centralizes logs from various sources, making it easier to monitor and troubleshoot systems. Elasticsearch offers fast, full-text search capabilities and sophisticated analytics, enabling quick insights from large datasets. Logstash processes and transforms data in real-time, allowing for immediate analysis and monitoring. Kibana provides an intuitive interface for visualizing data, creating dashboards, and generating reports. The stack scales horizontally, handling large volumes of data efficiently. Being open source, it has a large and active community, extensive documentation, and no licensing costs. Supports a wide range of data sources and formats, making it versatile for various use cases. Integrates well with other tools and technologies, enhancing its utility in diverse environments. These factors make the ELK Stack a popular choice for log management, monitoring, and data analysis. It very popular and big enterprise business like Wells Fargo, Adobe, Cisco, Comcast, SAINT-GOBAIN etc. (few of the popular names) heavily use it for observability. Elastic Observability. (n.d.). Retrieved from https://www.elastic.co/customers Imagine a complex distributed application where traditional observability tools generate a large volume of logs and metrics. An LLM can automatically analyze logs to detect unusual patterns or errors. Integrating large language models into observability practices can significantly enhance the ability to monitor, analyze, and maintain complex systems. By providing intelligent insights, real-time anomaly detection, automated root cause analysis, and natural language querying, LLMs can improve system reliability, reduce downtime, and make the lives of system administrators and engineers easier.
5. Applying LLMs to Log Mining
- Log Representation for LLMsLogs typically contain a mix of structured information (e.g., timestamps, error codes) and unstructured text (e.g., error messages). LLMs, which excel at understanding text, can be applied to both structured and unstructured parts of the log data. However, preparing logs for LLM-based analysis requires addressing several challenges:• Preprocessing: Logs must be tokenized and normalized to remove unnecessary information (e.g., IP addresses, file paths) or noise (e.g., debug messages).• Embeddings: LLMs convert logs into dense embeddings, capturing both the explicit content and implicit context of each log message.• Sequence management: Since logs are often long and sequential, they must be segmented in a way that preserves event ordering and contextual information, which is crucial for tasks like anomaly detection.Anomaly DetectionAnomalies in logs often indicate system failures or security breaches. LLMs can be fine-tuned to detect such anomalies by learning normal log patterns during training and flagging deviations from those patterns. The advantages of using LLMs for this task include:• Contextual anomaly detection: Unlike traditional methods that rely on predefined rules, LLMs can learn what constitutes "normal" behavior in a system and flag deviations based on a deeper understanding of context and patterns across log entries.• Unstructured data handling: LLMs can process unstructured text within logs and correlate it with structured data, offering a more holistic view of the system's state.Failure PredictionLLMs can be used to predict failures by identifying subtle patterns in log sequences that precede system breakdowns. This is achieved by training the model on historical logs containing both normal and failure scenarios:• Sequence modeling: Transformers in LLMs excel at capturing long-range dependencies between log events, making them effective for analyzing logs where failure events may be preceded by long sequences of seemingly normal events.• Transfer learning: Pre-trained LLMs can quickly adapt to different systems and datasets, enabling failure prediction in environments with limited labeled data.Root Cause AnalysisRoot cause analysis in log mining involves identifying the primary reason for an observed issue by tracing it through log data. LLMs can assist in this by:• Correlation extraction: LLMs can identify causal relationships between log events and highlight correlations that point to the root cause.• Summarization: Advanced language models can summarize large volumes of log data, providing a condensed view that highlights critical errors or anomalies leading up to an issue.• Contextual tracing: By understanding the log context, LLMs can automatically surface the most relevant portions of the log for investigation, reducing the time needed for root cause identification.Log Clustering and Pattern RecognitionLLMs can be used to automatically group similar logs together by learning embeddings that represent semantically similar log entries. This can be useful for:• Clustering: Grouping log entries that share similar patterns, which can reduce redundancy and help identify repetitive errors or issues.• Pattern extraction: Discovering common sequences or behaviors within logs, enabling better understanding of normal and abnormal system behavior.
6. Design
- We will use logs data store Elasticsearch for all explanations. Here we will be integrating Elasticsearch with Large Language Models (LLMs) to query logs for identifying potential issues can be an efficient and powerful method to analyze system behavior, detect anomalies, and provide explanations in real-time. Elasticsearch, being a distributed and scalable search engine for logs, can act as the data source, while LLMs can perform advanced log understanding, contextual analysis, and problem detection.Here’s a step-by-step approach to using logs data from Elasticsearch to feed an LLM for querying and detecting issues.System OverviewThe overall architecture can be broken down into three main components:• Elasticsearch: Acts as the storage and search engine for log data.• ETL/Preprocessing Layer: Responsible for extracting logs from Elasticsearch, formatting, and preparing the data.• Large Language Model (LLM): Processes the logs, detects anomalies, and answers queries on issues found in logs.Data Flow Architecture1. Log Ingestion into Elasticsearch: Logs from various sources (e.g., applications, services, infrastructure) are continuously ingested into Elasticsearch.2. Preprocessing & Data Pipeline: A pipeline fetches logs from Elasticsearch, performs necessary preprocessing, and feeds the processed logs to the LLM.3. Query & Analyze via LLM: Users query the LLM using natural language to find issues, detect anomalies, or get explanations about system behavior.4. Real-time Feedback & Reporting: The LLM provides actionable insights and detailed analysis back to users, either through an API, a dashboard, or alerts.SetupIngesting Logs into ElasticsearchEnsure that all logs are ingested into Elasticsearch using the typical ELK stack or other log ingestion mechanisms such as:• Filebeat or Logstash for capturing logs from various sources.• Logs should be indexed into Elasticsearch in a structured format (JSON) with appropriate fields like timestamp, log level, message, service name, etc.Extracting Logs from ElasticsearchTo extract logs from Elasticsearch for feeding into the LLM, you can use the Elasticsearch Query API. Here's an example Python script using the Elasticsearch client to retrieve logs:
 Preprocessing Logs for LLMLogs need to be formatted and cleaned before passing them to the LLM. The preprocessing could include:• Removing unnecessary noise (e.g., timestamps if not relevant).• Formatting logs into structured or semi-structured formats that the LLM can interpret easily.• Aggregating similar logs or combining related events into a single sequence for better context understanding.Example preprocessing:
Preprocessing Logs for LLMLogs need to be formatted and cleaned before passing them to the LLM. The preprocessing could include:• Removing unnecessary noise (e.g., timestamps if not relevant).• Formatting logs into structured or semi-structured formats that the LLM can interpret easily.• Aggregating similar logs or combining related events into a single sequence for better context understanding.Example preprocessing: Feeding Logs to LLMYou can feed the preprocessed logs to an LLM such as OpenAI’s GPT-4 via an API or a fine-tuned LLM model. The LLM can then be queried with natural language questions.Example LLM query using an API:
Feeding Logs to LLMYou can feed the preprocessed logs to an LLM such as OpenAI’s GPT-4 via an API or a fine-tuned LLM model. The LLM can then be queried with natural language questions.Example LLM query using an API: In this example:• Logs are extracted from Elasticsearch and preprocessed into a single text block.• The user submits a query like “Are there any performance issues or anomalies in the logs?”• The LLM analyzes the logs and returns insights, such as performance issues, security warnings, or anomalous behavior.Real-Time Log Monitoring with LLMsTo provide real-time insights, this process can be automated using a continuous pipeline:• A script or system polls logs from Elasticsearch at regular intervals (e.g., every minute).• Logs are processed and analyzed using the LLM.• Alerts are triggered or reports generated based on the LLM’s feedback (e.g., anomalies detected, warnings).Building a Retrieval Augmented Generation (RAG) System with Elasticsearch and an LLMUnderstanding RAGA RAG system leverages external knowledge sources to enhance the capabilities of an LLM. By retrieving relevant information from these sources, the LLM can provide more accurate, informative, and up-to-date responses. In other words, it is an AI technique/pattern where LLMs are provided with external knowledge to generate responses to user queries. This allows LLM responses to be tailored to specific context and responses are more specific.
In this example:• Logs are extracted from Elasticsearch and preprocessed into a single text block.• The user submits a query like “Are there any performance issues or anomalies in the logs?”• The LLM analyzes the logs and returns insights, such as performance issues, security warnings, or anomalous behavior.Real-Time Log Monitoring with LLMsTo provide real-time insights, this process can be automated using a continuous pipeline:• A script or system polls logs from Elasticsearch at regular intervals (e.g., every minute).• Logs are processed and analyzed using the LLM.• Alerts are triggered or reports generated based on the LLM’s feedback (e.g., anomalies detected, warnings).Building a Retrieval Augmented Generation (RAG) System with Elasticsearch and an LLMUnderstanding RAGA RAG system leverages external knowledge sources to enhance the capabilities of an LLM. By retrieving relevant information from these sources, the LLM can provide more accurate, informative, and up-to-date responses. In other words, it is an AI technique/pattern where LLMs are provided with external knowledge to generate responses to user queries. This allows LLM responses to be tailored to specific context and responses are more specific.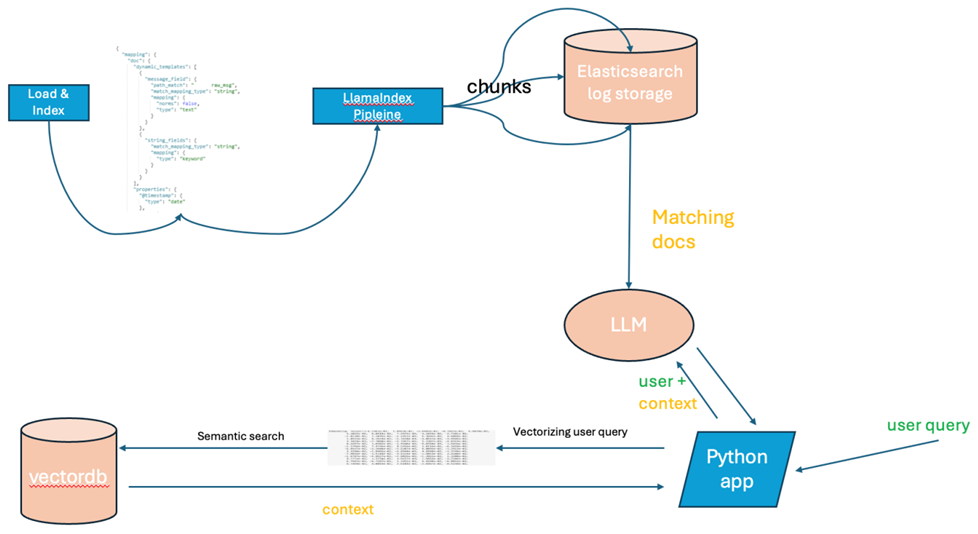 | Figure |

7. Challenges and Considerations
- ScalabilityLLMs, while powerful, can be resource intensive. Applying LLMs to large-scale log datasets requires significant compute power, memory, and careful handling of model inference costs. Solutions such as model distillation or model pruning may be necessary to deploy LLMs efficiently in production environments.Model distillation involves training a smaller model to replicate the behavior of a larger, pre-trained model The process aims to transfer knowledge from the large model to the smaller one, making the smaller model almost as effective as the large one but much more efficient.Model pruning involves removing less important weights or neurons from the model to reduce its size and computational requirements. The goal is to maintain as much of the model's performance as possible while making it more efficient.Example:
 Both model distillation and model pruning are effective techniques for reducing the size and complexity of large language models while maintaining their performance. They address key challenges such as computational requirements, memory usage, and deploy ability, making LLMs more practical for real-world applications. The choice between distillation and pruning depends on the specific requirements and constraints of your use case.Retrieval-Augmented Generation (RAG)Retrieval-Augmented Generation (RAG) is a technique that enhances large language models (LLMs) by incorporating external knowledge during the generation process. This approach combines retrieval models with generative models to provide more accurate and contextually relevant responses.Providing context with user query, reduces the scope for LLM, it helps run the results more accurately and much faster.context = vectordatabase.query(query_string, numresults)Here:vectordatabase.query - is the handle to vector databasenumresults - Number of documents returned by vector database query
Both model distillation and model pruning are effective techniques for reducing the size and complexity of large language models while maintaining their performance. They address key challenges such as computational requirements, memory usage, and deploy ability, making LLMs more practical for real-world applications. The choice between distillation and pruning depends on the specific requirements and constraints of your use case.Retrieval-Augmented Generation (RAG)Retrieval-Augmented Generation (RAG) is a technique that enhances large language models (LLMs) by incorporating external knowledge during the generation process. This approach combines retrieval models with generative models to provide more accurate and contextually relevant responses.Providing context with user query, reduces the scope for LLM, it helps run the results more accurately and much faster.context = vectordatabase.query(query_string, numresults)Here:vectordatabase.query - is the handle to vector databasenumresults - Number of documents returned by vector database query Fine-Tuning for Log-Specific TasksLLMs are typically pre-trained on general-purpose text data. To be effective in log mining, they must be fine-tuned on domain-specific datasets, which can be costly in terms of labeled data. Approaches like few-shot learning and transfer learning can help minimize this requirement.InterpretabilityLLMs, by nature, are often seen as black-box models, making it difficult to interpret why a certain anomaly was detected or why a failure is predicted. Developing methods to improve the interpretability of LLM-based log mining is crucial for gaining trust from domain experts and operations teams.Log HeterogeneityLogs come in various formats, and the lack of a unified structure poses a challenge for LLMs. Preprocessing steps, such as transforming logs into a standard format or schema, are essential to ensure that LLMs can effectively process log data from diverse sources.
Fine-Tuning for Log-Specific TasksLLMs are typically pre-trained on general-purpose text data. To be effective in log mining, they must be fine-tuned on domain-specific datasets, which can be costly in terms of labeled data. Approaches like few-shot learning and transfer learning can help minimize this requirement.InterpretabilityLLMs, by nature, are often seen as black-box models, making it difficult to interpret why a certain anomaly was detected or why a failure is predicted. Developing methods to improve the interpretability of LLM-based log mining is crucial for gaining trust from domain experts and operations teams.Log HeterogeneityLogs come in various formats, and the lack of a unified structure poses a challenge for LLMs. Preprocessing steps, such as transforming logs into a standard format or schema, are essential to ensure that LLMs can effectively process log data from diverse sources.8. Future Directions
- Real-Time Log Mining with LLMsFuture work could focus on applying LLMs in real-time log mining scenarios, where logs are processed as they are generated. This would enable immediate anomaly detection, failure prediction, and root cause analysis, significantly improving system reliability and security.Integration with Observability ToolsIntegrating LLM-based log mining with modern observability tools (such as Prometheus, Grafana, and ELK Stack) could enhance the ability to monitor and analyze system performance holistically. This would enable seamless insights from both structured metrics and unstructured logs.Hybrid ModelsCombining LLMs with other machine learning techniques, such as anomaly detection models or graph-based models, could improve the precision of log mining tasks. Hybrid models may also reduce the computational burden on LLMs by delegating specific tasks to more lightweight models.
9. Conclusions
- Large language models present a transformative opportunity for log mining, enabling more sophisticated anomaly detection, failure prediction, and root cause analysis. By leveraging LLMs' ability to understand unstructured text and detect contextual patterns, organizations can automate and enhance their log analysis processes, leading to improved system reliability and operational efficiency. While challenges such as scalability and interpretability remain, the potential benefits of LLMs in log mining are significant, marking them as a valuable tool in modern IT and DevOps environments.