-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2024; 14(3): 56-66
doi:10.5923/j.computer.20241403.02
Received: Jun. 6, 2024; Accepted: Jun. 24, 2024; Published: Jul. 6, 2024

Leveraging Deep Learning Techniques for Enhanced Intrusion and Malware Detection Performance
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLAsmaa Ourdighi, Sarah Yamina Messaoudi, Ikram Belabed
Department of Computer Science, University of Sciences and Technology of Oran –Mohamed Boudiaf, El M'Naouer Oran, Algeria
Correspondence to: Asmaa Ourdighi, Department of Computer Science, University of Sciences and Technology of Oran –Mohamed Boudiaf, El M'Naouer Oran, Algeria.
| Email: |  |
Copyright © 2024 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

As computer networks become increasingly complex; the network security sector faces evolving cyber threats, highlighting the critical role of Intrusion Detection Systems (IDS) in identifying attacks. Currently, Deep Learning (DL) is gaining momentum as a preferred technique due to its ability to generalize in classification tasks. This study evaluates DL techniques for IDS and Malware Detection Systems (MDS) by comparing their performance under identical conditions. The choice of DL methods challenges conventional notions about designing effective neural architectures and input data types, including tabular data. Hence, we assess a basic ANN, more suitable for our case, alongside Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) model combined with Long Short-Term Memory (LSTM) tailored for sequential or temporal data. DL networks undergo testing on the NLS-KDD and Malware datasets, achieving an accuracy of 99.99% for IDS and 99.97% for MDS, with RNN-LSTM emerging as the top performer in both cases.
Keywords: Artificial Intelligence, Deep learning, Intrusion Detection Systems, Malware Detection Systems
Cite this paper: Asmaa Ourdighi, Sarah Yamina Messaoudi, Ikram Belabed, Leveraging Deep Learning Techniques for Enhanced Intrusion and Malware Detection Performance, Computer Science and Engineering, Vol. 14 No. 3, 2024, pp. 56-66. doi: 10.5923/j.computer.20241403.02.
Article Outline
1. Motivation and Related Works
- Nowadays, computer networks are faced with a significant influx of data from sources such as the Internet of Things (IoT), cybersecurity, mobile devices, businesses, social networks, healthcare, etc. To effectively protect these networks, intelligent analysis and automated solutions are essential. Artificial intelligence (AI), particularly machine learning and deep learning techniques, offer a powerful solution [1]. By leveraging the capabilities of AI, we can develop intelligent applications capable of analyzing large volumes of data, detecting threats in real-time, and automating security responses [2].The DL introduction into cybersecurity has brought significant advancements in cyber-attacks detection and prevention [3]. Deep learning has significantly evolved within the cybersecurity industry, demonstrating its crucial role in enhancing threat detection and bolstering system resilience. Companies such as Darktrace utilize artificial intelligence to detect suspicious behaviors across networks. Cylance employs sophisticated deep learning algorithms to proactively identify and mitigate malware attacks by analyzing intricate behavioral patterns within files. Vectra Networks utilizes advanced deep learning techniques to monitor and promptly detect internal threats, offering automated threat responses. PatternEx enhances accuracy by reducing false positives through machine learning, while Sophos AI effectively identifies ransomware and targeted attacks using robust deep learning methodologies. These advancements underscore how deep learning plays a pivotal role in safeguarding systems against cyber threats, swiftly identifying malicious activities and bolstering overall network and computer security. In this section, we showcase a selection of research studies employing DL for IDS.In Alom et al. [4], they employ a Deep Belief Network (DBN). A DBN is a deep generative model comprised of a visible layer and multiple hidden layers of latent variables. While connections exist between the layers, there are no connections between units within each layer [5]. The proposed system is capable of detecting attacks, and the accuracy of network activity is also identified and classified into five groups based on factors such as limited, incomplete, and nonlinear data sources. Compared to the existing system, the detection accuracy reaches 97.5% after 50 iterations. However, the DBN requires initial unsupervised pre-training and careful adjustment of hyperparameters to achieve good performance, which can involve numerous trials and errors.Next, Tang et al. [6] implemented a Deep Neural Network (DNN) for IDS in a Software Defined Network (SDN) controller to monitor all flows of OpenFlow switches. They trained the model on the NSL-KDD dataset for binary classification (normal/anomaly) using only 6 basic features out of the 41 available. The model was optimized by varying the learning rate from 0.1 to 0.0001. Their model achieved an accuracy of 75.75%. Other works, such as those by [7], [8], [9], [10], pursued similar approaches.DL algorithms, especially Convolutional Neural Networks (CNNs), have demonstrated remarkable capabilities in automatically extracting intricate patterns and features from complex data, such as network traffic [11]. For instance, in the work of [12], a CNN was implemented to model network traffic events as time-series of TCP/IP packets within predefined time periods. Drawing inspiration from natural language processing techniques, the authors utilized a 1D Convolution layer [13]. This approach enabled modeling network traffic events as chronological data series, where instead of using 2D image data as input, the CNN processed a series of data in 1D format organized over time intervals. Different architectures were proposed, each containing an input layer, hidden layers with one or more CNN layers, and output layers such as FFN or RNN/LSTM/GRU to determine the optimal architecture. All experiments were conducted over 1000 epochs, and the CNN-LSTM achieved a high accuracy of 99% on the KDDCup 99 dataset.Wu et al. [14] proposed an IDS model using Convolutional Neural Networks (CNNs) to automatically select traffic features from raw datasets, improving class accuracy and reducing the false alarm rate (FAR). Similarly, Xiao et al. [15] proposed an efficient IDS based on CNN, initially performing feature extraction using techniques like principal component analysis (PCA) and autoencoder (AE). They transformed the one-dimensional vector (feature set) into a two-dimensional matrix before inputting it into the convolutional neural network. Experimental results on the KDD Cup'99 dataset demonstrated efficiency in terms of learning and testing phase times, though with lower detection rates for U2R and R2L classes compared to other attack classes. Studies by [16], [17] recommend analysing network traffic using DL models, following a similar approach. However, CNNs may face challenges in capturing temporal dependencies within data sequences critical for detecting specific intrusion patterns, and their limited interpretability complicates understanding detected attack patterns.In reference [18], IDS based on RNN using GRU as the main memory with a multilayer perceptron and softmax classifier was proposed. Testing on the KDD Cup'99 and NSL-KDD datasets showed good detection rates compared to other methodologies, with lower detection rates observed for minority attack classes like U2R and R2L.Although our work focuses on deep learning, other machine learning studies have also achieved equally remarkable performances. In the work by Ferrag et al. [41], decision tree-based algorithms were utilized to assess performance on the CICIDS and BOT-IoT datasets, achieving respective accuracies of 96.665% and 96.995%. Similarly, Kunhare et al. [42] employed a random forest algorithm to select relevant features for reducing irrelevant attributes in intrusion detection. They conducted a comparative study using various classifiers including k-nearest neighbors (k-NN), support vector machine (SVM), logistic regression (LR), decision tree (DT), and naive Bayes (NB) to evaluate different metrics of intrusion detection systems (IDS). The particle swarm optimization (PSO) algorithm was applied to optimize the selected features on the NSL-KDD dataset, resulting in an accuracy of approximately 99.26%.In conclusion, these examples underscore that the utilization of deep learning in Intrusion Detection Systems (IDS) and Malware Detection Systems (MDS) remains a pertinent research topic. DL enables exploration of various ANN approaches, continuously improving system performance [19]. Factors such as structure, data flow, neuron density, layer number, and deep activation filters contribute to expanding the perspectives of these approaches. However, variations in training and testing conditions, datasets used, and output classes considered may lead to comparative survey challenges in objectivity and effectiveness. Our work offers a concise comparative analysis aiming to improve IDS and MDS performances by presenting referenced DL methods. Based on related works, RNN and CNN approaches show efficiency in major performances. Additionally, the characteristics of input data play a crucial role in designing artificial neural network models. Different types of data, such as time series, sequential inputs, spatial data, or tabular datasets, often demand specific architectures tailored to handle their respective input data propagation. As a result, our study investigates three approaches (ANN, RNN-LSTM, and CNN) to observe and evaluate IDS and MDS performances based on input data nature. Following experimentation, we integrated LSTM into CNN architecture for further improvement.
2. Theoretical Background
- The utilization of deep learning techniques offers numerous advantages, particularly in its capacity to extract intricate patterns and generalize to novel data. Our study aims to assess the performance of existing models. Among the various architectures examined, we have selected the most commonly used static and dynamic models, along with hybrid versions: Artificial Neural Networks (ANNs), Recurrent Neural Networks (RNNs), and Convolutional Neural Networks (CNNs) paired with Long Short-Term Memory (LSTM). In this section, we briefly outline the theoretical background of these approaches.
2.1. ANN Approach
- A simple Artificial Neural Network (ANN) consists of multiple layers of neurons: an input layer, one or more hidden layers, and an output layer, as illustrated in Figure 1. Each neuron in a layer receives weighted inputs, sums them, and passes them through an activation function before transmitting them to the next layer. This process is repeated until the data reaches the output layer, where the final output is generated.
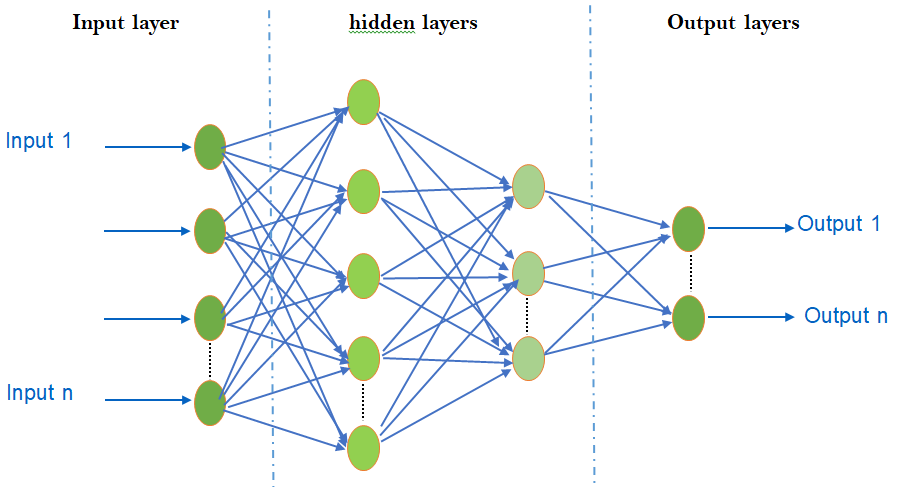 | Figure 1. ANN topology |
2.2. RNN Approach
- The main characteristic of an RNN is its utilization of recurrent loops, enabling the network to transfer information across different time steps. At each step of the sequence, the RNN takes into account the current input along with the internal state, or memory, computed from preceding steps. It then generates an output and updates its internal state for use in the subsequent step [20]. This recurrent mechanism empowers the RNN to capture long-term dependencies within the sequence.The Figure 2 illustrates how the hidden state of an RNN at time step t is determined based on the hidden state at the previous time step, the input at time step t, and the associated weights and biases. The RNN consists of input layer x, hidden layer h, and output layer o. When unfolding the loop, the standard RNN repeats this structure multiple times, with the state h of each iteration serving as input to the next. Denoting the input, hidden, and output layers at time t as x(t), h(t), and o(t) respectively, the output o(t) is calculated as follows:
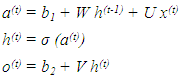 | (1) |
 | Figure 2. RNN topology |
2.3. CNN Approach
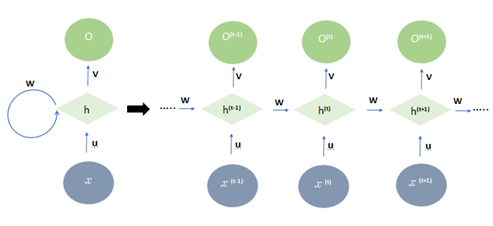
- Proposed in the work of LeCun et al. [21], CNNs are feed-forward artificial neural networks capable of recognizing simple objects with high shape variability [22]. CNNs are a specific type of artificial neural network designed for supervised learning, particularly for processing data with a grid-like structure such as images or temporal sequences [13].CNNs are typically structured as a sequence of layers, alternating between convolutional layers, activation layers (such as ReLU), and pooling layers. Additionally, fully connected layers may be appended at the end of the network for classification purposes, as described in Figure 3.
 | Figure 3. CNN topology |
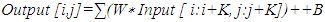 | (2) |
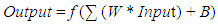 | (3) |
2.4. LSTM Approach
- No Introduced by Hochreiter and Schmidhuber [23], the Long Short-Term Memory (LSTM) networks represent a refined iteration of Recurrent Neural Networks (RNNs), adept at overcoming the challenge of vanishing or exploding gradients through the integration of a complex structure and long-term memory mechanisms. Their primary function lies in capturing prolonged dependencies within sequential data. LSTMs utilize specialized LSTM units, specifically engineered to manage sequences while accounting for temporal dependencies [24]. The Long Short-Term Memory (LSTM) layer, a fundamental component of recurrent neural networks, is intricately structured with multiple gates and a memory cell. These elements work collaboratively to meticulously regulate the flow of information within the network. Below, we present several gates, including the forget gate, the input gate, and the output gate, which regulate the flow of information through the memory cell. The forget gate, in (4), controls the amount of past information to forget or retain in long-term memory. The input gate determines which new information should be stored in long-term memory, as shown in (5). Lastly in (6), the output gate controls the amount of information to be transmitted to the output based on the current state of the memory cell.
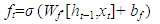 | (4) |
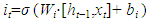 | (5) |
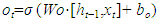 | (6) |
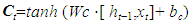 | (7) |
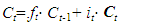 | (8) |
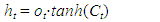 | (9) |
3. Datasets Used
- For this study, we utilized two datasets commonly used: the NSL-KDD dataset for IDS and the Malware dataset for MDS. The NSL-KDD dataset is a commonly referenced dataset for intrusion detection in computer networks. It was developed to improve upon the original KDD Cup 1999 dataset by addressing certain limitations and rendering it more realistic [25] [26]. The NSL-KDD dataset contains four categories of network attacks: "DoS" (Denial of Service) attacks, "Probe" attacks, "R2L" (Unauthorized Remote Access) attacks, and "U2R" (Privilege Escalation) attacks. Each entry in the NSL-KDD dataset is tagged with an attack class, signaling whether it represents an attack or a non-malicious activity. In this dataset, there are 125,973 instances with 41 attributes or features. The features are divided into three main type as follows: features extracted from the TCP/IP connection, features to access TCP packet payload and time-based traffic features and host-based traffic features [27].For malware case, based on the characteristics of the observations, the Malware dataset was created in a Unix/Linux-based virtual machine for classification purposes, containing benign and malware software for Android devices. The dataset comprises 100,000 observation data points and 35 features.
4. Methodology
- For this study, each employed approach exhibits distinct characteristics, all of which play a vital role in effectively detecting intrusions and malware. The detection methodology hinges on binary classification, as illustrated in Figure 4. All approaches adhere to the same block diagram design. In this section, we will provide comprehensive descriptions of the design steps.
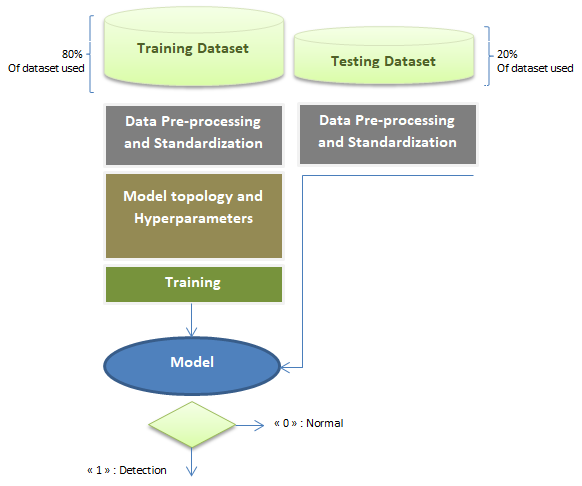 | Figure 4. Block diagram of the proposed architectures for IDS and MDS |
4.1. ANN Model
- As Artificial Neural Networks (ANNs) can be utilized for intrusion or malware detection by analyzing network flow behavior. Prior to input into the ANN, collected information requires preprocessing, which could entail normalization, discretization, or feature transformation to suit the ANN input. Consequently, the remainder of the ANN architecture, including the number of hidden layers, neurons per dense layer, activation functions, etc., remains to be defined randomly [28].Then, the simple ANN is trained using a labeled dataset. These labeled data are typically divided into two categories: normal or intrusion data for IDS, and benign or malware data for MDS. The ANN learns to recognize characteristic patterns of intrusions from these training data. Once the ANN is trained, it is evaluated on an independent test dataset.For the IDS, the ANN was constructed using the TensorFlow library. The model comprises five dense layers with 64 neurons each and utilizes Rectified Linear Unit (ReLU) activation functions. The output layer is configured with a single unit and uses a sigmoid activation function.For the MDS, a sequential architecture in Keras was employed. The model starts with an input layer with 27 neurons, corresponding to the number of attributes in a data instance. Subsequently, 50 hidden layers were added with ReLU activation functions. The output layer consists of two neurons representing the classification classes, utilizing a softmax activation function which generates probabilities for each output class.
4.2. RNN-LSTM Model
- To detect intrusions using an LSTM, the network is trained on a pre-processed dataset transformed into sequences of vectors, where each vector represents a measurement or feature at a given time. During training, the LSTM learns to predict the class of each input sequence, i.e., whether it is an intrusion or not. It also learns to update its internal state (cell state) based on the input sequence, allowing it to consider long-term contextual information. Once the LSTM is trained, it can be used to detect intrusions by providing input data sequences and observing the predictions made by the model. If the LSTM predicts a high probability of intrusion for a given sequence, this may indicate the presence of malicious activity.Meanwhile, the MDS model is sequentially constructed. Initially, the input dimensions determine the size of the third dimension, and the output size is set to two neurons. Subsequently, the model consists of two LSTM layers, each employing the ReLU activation function. Additionally, two dense layers are included, with the final layer outputting a single value with 2 features, totalling 258 trainable parameters.
4.3. CNN-LSTM
- In this final part, we developed a CNN and Long Short-Term Memory (LSTM) model for our IDS. The model begins with a 1D Convolution Layer consisting of 32 filters, a kernel size of 9, padding to ensure the output size matches the input size, and a ReLU activation function. It outputs a one-dimensional array of 41 points with 32 channels, totaling 320 trainable parameters. The second layer is a MaxPooling1D Layer with a pooling window size of 2. The third layer is an LSTM Layer with 16 units and a dropout of 0.2. Finally, the last layer is a Dense Layer with a single output unit.For malware detection, the CNN-LSTM model includes multiple layers. It starts with an Embedding Layer that converts inputs into dense vectors of size 8. Following this, a Batch Normalization Layer is applied to normalize activations from the previous layer, aiding in training stability. The model also incorporates a 1D Convolution Layer with 32 filters of size 9. Subsequently, a MaxPooling1D Layer reduces spatial dimensions by extracting maximum values within windows of size 2. An LSTM Layer with 512 units follows to capture sequential dependencies in the data. Lastly, a Dense Layer with a single unit and sigmoid activation produces the final output of the model, representing a probability between 0 and 1.
5. Resultats and Discussions
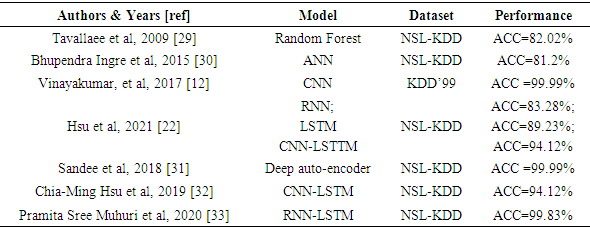
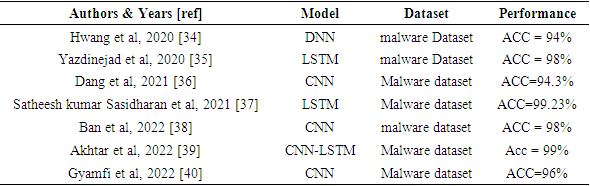
- We implemented three Deep Learning models: ANN, CNN, and RNN, each incorporating LSTM. These models were trained and tested on two subsets of data: the NSL-KDD dataset for intrusion detection and the Malware dataset for malware detection, as shown in Table 1 and Table 2, respectively.
|

|

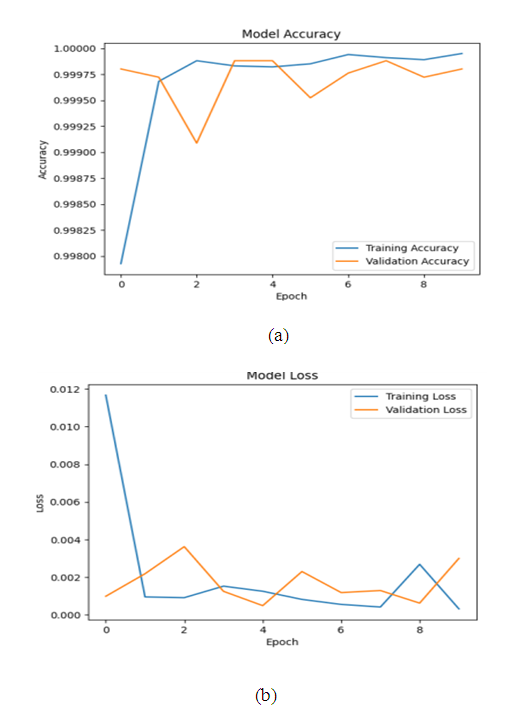 | Figure 5. Evolution of training and validation accuracy (a) and loss (b) of the ANN model over epochs for intrusion detection in the NSL-KDD dataset |
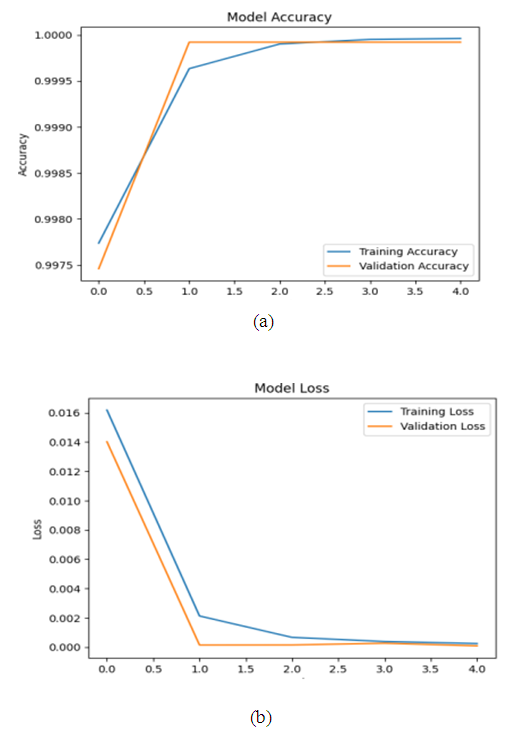 | Figure 6. Evolution of training and validation accuracy (a) and loss (b) of the RNN-LSTM model over epochs for intrusion detection in the NSL-KDD dataset |
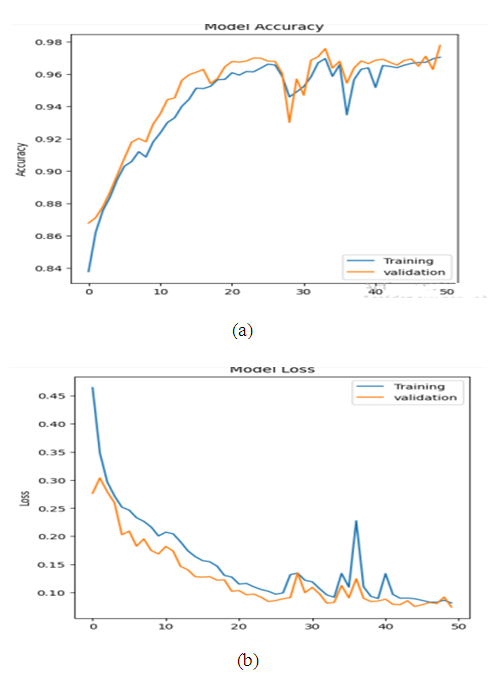 | Figure 7. Evolution of training and validation accuracy (a) and loss (b) of the CNN-LSTM model over epochs for intrusion detection in the NSL-KDD dataset |
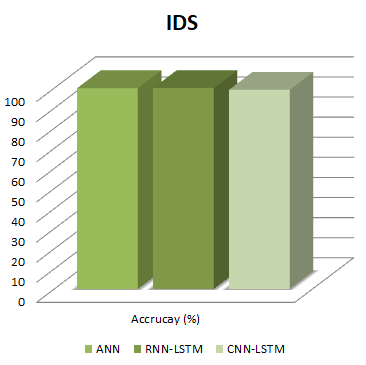 | Figure 8. Optimal accuracy results for the proposed DL methods for intrusion detection |
|
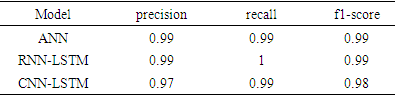
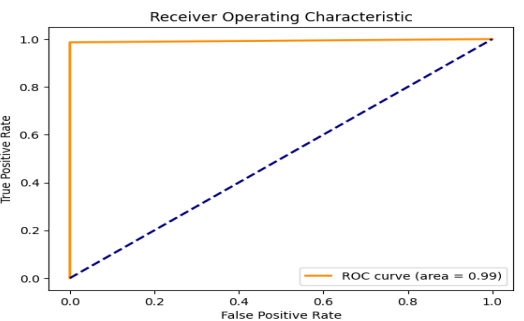 | Figure 9. ROC Curve of RNN-LSTM for intrusion detection |
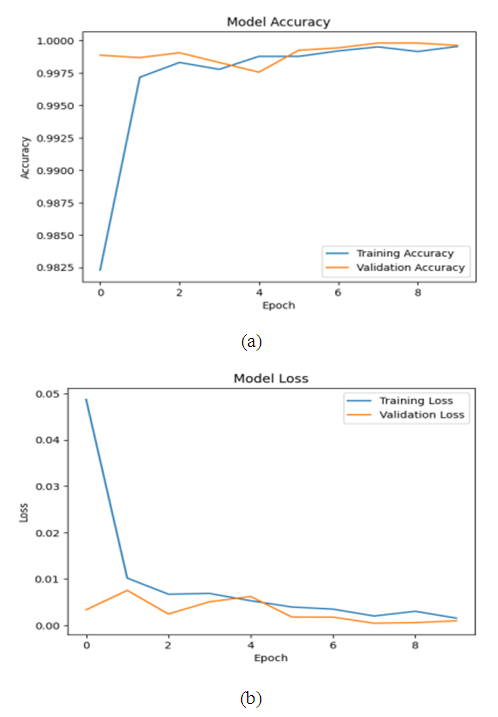 | Figure 10. Evolution of training and validation accuracy (a) and loss (b) of the ANN model over epochs for intrusion detection in the Malware dataset |
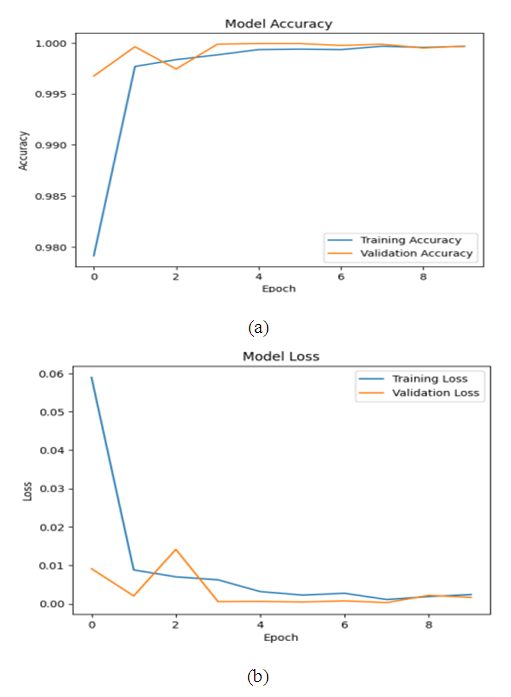 | Figure 11. Evolution of training and validation accuracy (a) and loss (b) of the RNN-LSTM model over epochs for intrusion detection in the Malware dataset |
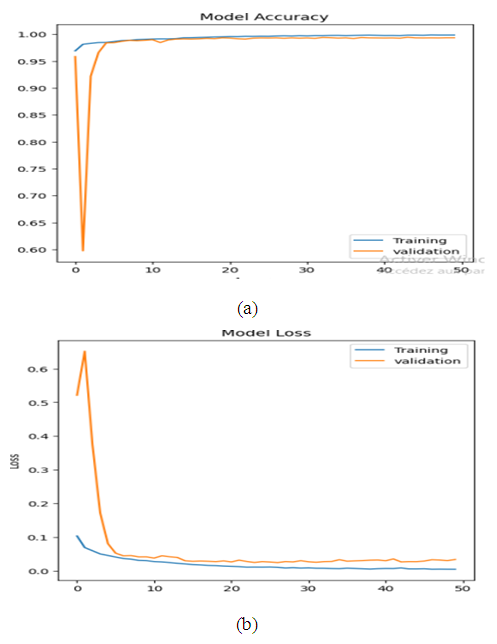 | Figure 12. Evolution of training and validation accuracy (a) and loss (b) of the CNN-LSTM model over epochs for intrusion detection in the Malware datase |
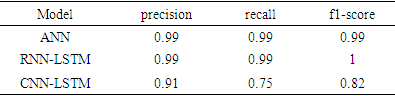
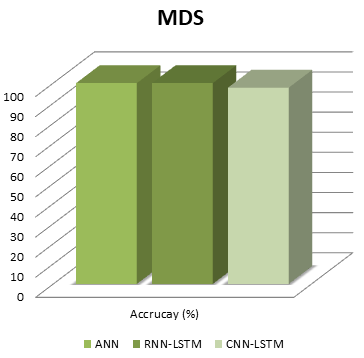 | Figure 13. Optimal accuracy results for the proposed DL methods for Malware detection. |
|
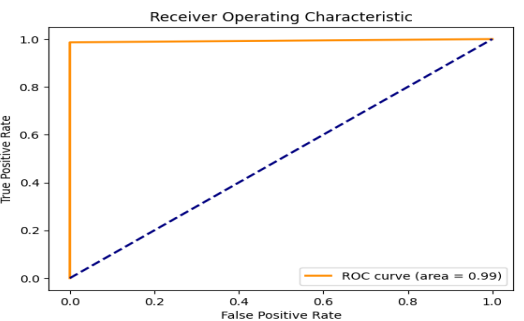 | Figure 14. ROC Curve of RNN-LSTM for Malware detection |
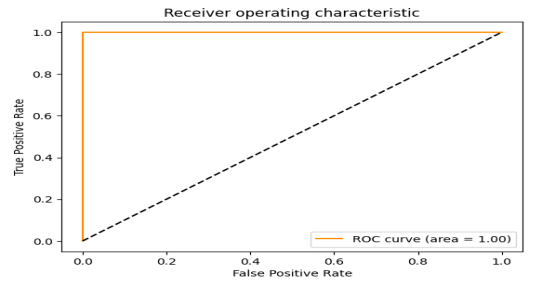 | Figure 15. ROC Curve of a simple RNN for Malware detection |
|
|
6. Conclusions
- In our study aimed at enhancing intrusion detection and preventing cyber-attacks, we integrated deep learning into various methodologies. Inspired by prior research, we implemented different models: Artificial Neural Networks (ANNs), Recurrent Neural Networks with Long Short-Term Memory (RNN-LSTM), and hybrid Convolutional Neural Networks with LSTM (CNN-LSTM). Using the NSL-KDD and Malware Dataset, our objective was to achieve accurate detection and promptly uncover attacks using a DL-based system. Remarkably, we found that the RNN-LSTM system exhibited superior performance, achieving an accuracy of 99.99% for IDS. For malware detection, all DL approaches surpassed 99% accuracy, with ANN showing particularly notable improvement.