-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2015; 5(2): 30-36
doi:10.5923/j.computer.20150502.02
The Study of Fraud Detection in Financial and Credit Institutions with Real Data
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLSevda Soltaniziba1, Mohammad Ali Balafar2
1Department of Computer Engineering, Germi Branch, Islamic Azad University, Germi, Iran
2Department of Communications Engineering, Faculty of Electronic and Copmuter Enginerring, Universty of Tabriz, Tabriz, Iran
Correspondence to: Mohammad Ali Balafar, Department of Communications Engineering, Faculty of Electronic and Copmuter Enginerring, Universty of Tabriz, Tabriz, Iran.
| Email: |  |
Copyright © 2015 Scientific & Academic Publishing. All Rights Reserved.
This paper presents a review of data mining techniques for the fraud detection. Development of information systems such as data due to it has become a source of important organizations. Method and techniques are required for efficient access to data, sharing the data, extracting information from data and using this information. In recent years, data mining technology is an important method that it has changed to extract concepts from the data set. Scientific data mining and business intelligence technology is as a valuable and somewhat hidden to provide large volumes of data. This research studies using service analyzes software annual transactions related to 20000 account number of financial institutions in the country. The main data mining techniques used for financial fraud detection (FFD) are logistic models, neural networks and decision trees, all of which provide primary solutions to the problems inherent in the detection and classification of fraudulent data. The proposed method is clustering clients based on client type. An appropriate rule for each cluster is determined by the behavior of group members in case of deviation from specified behavior will be known among suspected cases. The study data were based on the type of client clustering, so each cluster representing a certain type of client, the procedure will have a different behavior. To sum up this paper was studied by decision tree algorithm and neural network model. Models are able to extract about a lot of the rules related to client behavior. Each node in the graph model is built by selecting the corresponding table, chance percent of suspected cases have been identified.
Keywords: Data mining, Fraud detection, Financial fraud, Clustering, Classification
Cite this paper: Sevda Soltaniziba, Mohammad Ali Balafar, The Study of Fraud Detection in Financial and Credit Institutions with Real Data, Computer Science and Engineering, Vol. 5 No. 2, 2015, pp. 30-36. doi: 10.5923/j.computer.20150502.02.
1. Introduction
- Fraud involves one or more persons who intentionally act secretly to deprive another of something of value, for their own benefit. Fraud is as old as humanity itself and can take an unlimited variety of different forms. However, in recent years, the development of new technologies has also provided further ways in which criminals may commit fraud [3]. This approach (fraud detection) makes use of an “operations cycle” and a “development cycle” to detect fraud in health care claims. First, a Peer Group Analysis variant is used to find health care providers which “standout from the mainstream”, which are then presented to a security unit. In the development cycle, rules should be induced based on the expert analysis of the outliers. As in [15], these rules are proposed to be cloned and mutated. Details about the development cycle process are not given. In this study, it has tried first, full explanation of the types of fraud was common in financial institutions, in general and money laundering in particular, and intelligent data mining system to be expressed in the following manner. Fraud from different views is visible, including views of the social, legal, and economic. Fraud in Czech, business, loan and money laundering is instances of fraud in the financial context that our focus is on money laundering (a special type of fraud in the bank with the aim of hiding the true source of money).There are different definitions for internal fraud, including:• acts to deceive, exploit or circumvent the law and regulations, with the exception of special events [9]. Use of jobs for personal enrichment, intentional abuse or misuse of the resources and assets of the organization. According to the Association of Fraud Examiners expert, to 959 cases of occupational Fraud as follows: organizations in the United States lose to fraud about 7% of its annual revenue [2].Analysis of an average of $ 175,000, which lost a quarter of these cases for amounts less than $ 1 million. Instance of fraud since the beginning of fraudulent behavior to it diagnosis took 2 years. The most common is fraud scheme corruption, fraudulent billing Fraud 27% and 24%, respectively. It seems that the implementation of anti- fraud controls can be largely effective, and etc…For reasons that are mentioned in the client's employee drivers could potentially be committing fraud.Over the past two decades, the competitive landscape has changed significantly in the banking industry [19]. This is due to factors such as new regulations, globalization, technology development and product services into the bank and a significant increase in demand of our clients. Changes in banking activities and the increasing complexity of existing rules in banks are created new topics in the field of bank fraud. Major and Riedinger [21] describe a workflow and system to setup fraud detection departments with results of its use in the real world. Similar work was done by Ortega et al. who introduced a data mining based system that decreased the time it takes to detect fraud by 76% from an average of 8.6 months to 2 months [22]. Because Major and Riedinger and Ortega et al., describe real systems that are used to find fraud they cannot go into details of the exact working of the systems. Doing this would give fraud perpetrators an advantage on penetrating the fraud defense. Fraud detection techniques, in addition to fraud and scams in which an organization has identified and provides analysis, to somehow try to predict the future behavior of their users or clients to will decrease the risk of fraud. Due to high costs caused by direct or indirect fraud or fraud in financial institutions, banks, financial institutions and money to crooks and fraudsters are aggressively seeking to expedite the recognition activities. The importance of this is due to its direct impact on client service organizations to reduce operating costs and remain as a credible and reliable provider of financial services.Review of literatureData has become one of important organizations with the development of information systems. The methods and techniques are required for efficient data access, data sharing, data extraction and use of this information. There are many alternative approaches to fraud detection and deterrence [5]. Bolton and Hand [4] discuss techniques used in several subgroups within fraud detection such as credit card and telecommunications, and related domains such as money laundering and intrusion detection. Kou et al outline techniques from credit card, telecommunications, and intrusion detection [18]. Weatherford recommends back propagation neural networks, recurrent neural networks and artificial immune systems for fraud detection [25].It is an example of straightforward application of existing data mining algorithms to an “ideal” data set: it uses neural networks for credit card fraud detection data [20]. The neural network is a technique that imitates the functionality of the human brain using a set of interconnected vertices [13] [27]. It is widely applied in classification and clustering, and its advantages are as follows. First, it is adaptive, second, it can generate robust models, and third, the classification process can be modified if new training weights are set. Neural networks are chiefly applied to credit card, automobile insurance and corporate fraud. Unfortunately, details about the used features are not given. Currently, identification of fraudulent claims is achieved using a scoring method to implement a claim auditing strategy. In recent years, data mining technology has become as one of the most important concepts extracted from the data set. Because, its technology has provided as scientific intelligence and valuable commercial and it obscured for a large amount of data. Various fields have been identified for data mining applications and developing. Various data mining techniques have been applied in FFD, such as neural networks [8] [11] [12] [16] and decision trees [17], among others. Data mining techniques covered by survey papers and bibliographies include outlier detection [14], skewed/imbalanced/rare classes [26], sampling [10], cost sensitive learning, stream mining, graph mining [24] and scalability [23]. The most common areas can be noted include medical issues, education, production and quality control, retail, and banking and insurance industry as well as marketing and supply chain issues. But one of the applicable the field of data mining is related to client relationship management. Today, there is the high volume of client data in the database and organizations, it is providing the potential for data mining process and hide knowledge extraction. The importance of issues is such as client retention and increase the value and profitability of their companies has reinforced the need to use data mining techniques. The present study is an attempt to analysis of a financial institution and credit clients, client hide behavioral patterns detection to improve the process of fraud detection in these institutions have taken advantage of it. Financial institutions are among the organizations that interact directly with clients. Therefore, the analysis of client behavior is important to increase their loyalty. In recent years, with increased access to client data and improved data analysis capabilities by intelligent methods, various activities have been carried out to analyze client behavior. One of these activities is the use of intelligent systems for detecting fraud in financial institutions. Currently fraud is wide range in financial institutions that have been material and immaterial losses many financial institutions and bank clients.Research hypothesesThe main hypothesis of this research is development of data mining combined with pattern matching techniques to construct a scenario with practical and valuable solutions and complete fraud detection system available.Data mining and data mining algorithms is appropriate to predict large data database.• Classification, is learning function that categories a data item into one of several classes of predefined (for example, a client classified as "frauds" or "non-frauds")• regression, is learning function that a data item is classified into a true predict (e.g forecast of fraud by a client)• clustering, is a description that seeks to identify a finite set of categories or clusters are used to data describe. (For example, identify target groups of clients)• Dependency modeling, is focusing on describing the dependencies and relationships between data (for example, find ways unknown to fraud clients)• a change and deviation, detection in the identify of data significant changes, with a focus on values, principles or the previous measurement. (For example, find ways to unusual usage patterns of clients Institute for fraud detection)• Decision tree, which is a powerful tool for prediction and classification a similar structure tree.
2. Materials and Methods
- The study is based on data collected has been one of the country's financial and credit institutions and the purpose of this proposal predictable patterns of fraud and to prevent fraud by institution profiteer clients. The study is one of the financial institutions includes transactions on accounts of clients, legal and real. Studied data collected from about 20 thousands client accounts during the one-year period, of which about 25 million records are for a variety of clients. So that clients is divided in three groups of clients, legal client and government and non-government agencies related companies as well as actual clients that is the clients majority of financial institutions. Methods1) The first, study of account behavior should be specified normal behavior procedure for each account.2) Due to the large number of account numbers, account individual behavior is not true in this case, it should be defined for each account a certain procedure.3) It can not specify a fixed behavior pattern for each account. Because it is possible for a client's behavior is a normal behavior and abnormal behavior lead to a different account. For example, you may withdraw or deposit the amount of 150 million dollars for a client's normal behavior, but the behavior of a group of clients who usually have low amounts transactions, are considered to be suspicious behavior.4) So, data clustering should have been used and data clustered to close together in a cluster to take account behavior.The study data were based on the type of client clustering, so each cluster representing a certain type of client, the procedure will have a different behavior. In this study, to determine cases of fraud requires a Boolean data type as “fraud anticipate " would be the initial value will be equal to 0. If exceed behavior of an account from the normal rang, the value of this field will change to 1. This will be implies for abnormal behavior (suspicious behavior) (figuer 3).To predict of fraud using a decision tree used of input data including the type of client, the number of deposit transactions, the total deposit transactions, the number of withdraw transactions, the total withdraw transaction. In this study, 30 percent of data is used as training data and 70 percent of data as the test data.Decision tree operator used to fraud predict of test data. This function builds a model based on the training data set and the model of is build predicts attribute to especially target of test data where it is lacking this amount. Tools used in this research are: 1. SqlServer 20122. AnalysisService20123. Excel20124. DataMining tool has been added to Excel softwareVarious methods have been used to predict Fraud. One of these methods, the use of neural network is more efficient than other algorithms. This algorithm model learns using neural network trained by error back-propagation algorithm. Architecture of this type of artificial neural network is called multi-layer Perceptron. The foundation of operator is such a multiple layers considered for it. Construct the inner layer neural network can be defined with the help of Hidden Layers parameter list. Each entry in this list defines a new hidden layer. If the user does not specify any hidden layers it will be added to the network by default a hidden layer. Most fraud departments place monetary value on predictions to maximize cost savings/profit and according to their policies. They can either define explicit cost or benefit models [7]. Cahill et al [6] suggests giving a score for an instance (phone call) by determining the similarity of it to known fraud examples (fraud styles) divided by the dissimilarity of it to known legal examples (legitimate telecommunications account).
3. Results
- The results of the decision treeDecision Trees is one of the most powerful tools common to classify and predict. In this section the results of the model based on decision tree algorithm reviewed.In Figure 1 possibility of fraud is shown based on entire of statistical population in used model of decision tree.
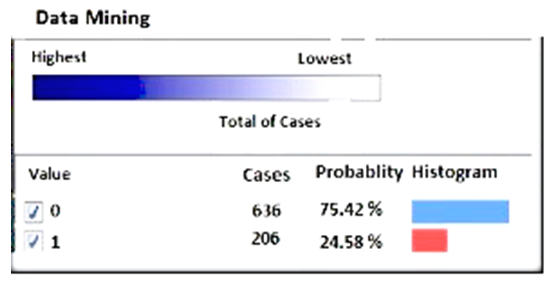 | Figure 1. Possibility of fraud in entire of statistical population |
|
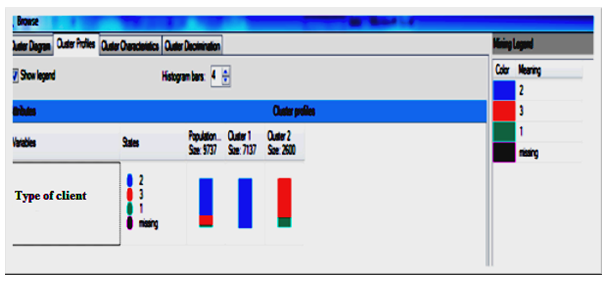
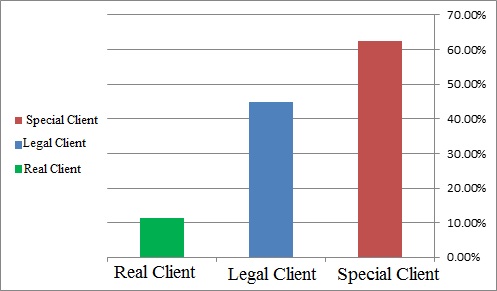 | Figure 2. Chart of clients’ fraud |
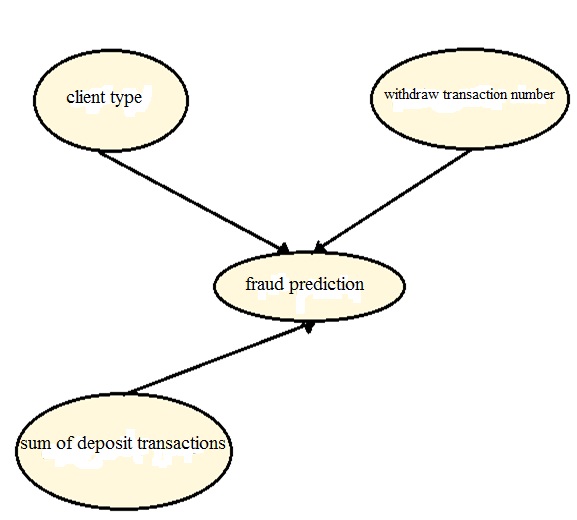 | Figure 3. Diagrams created a network model |
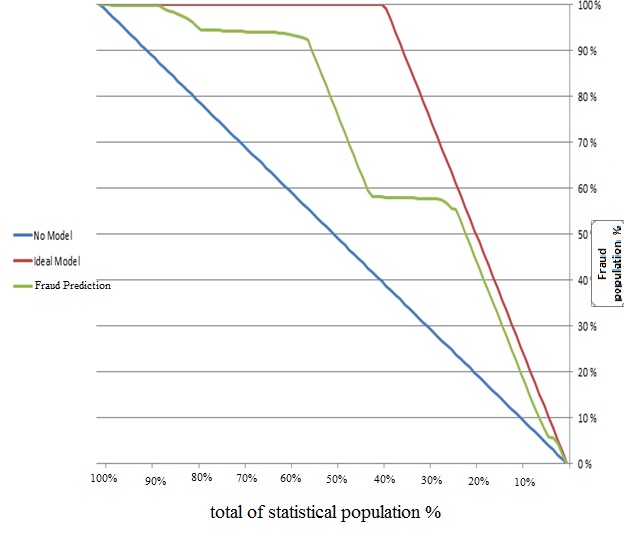 | Figure 4. Ratio of frauds population to total of statistical population in decision tree model |
 | Figure 5. The total of used population in modeling |
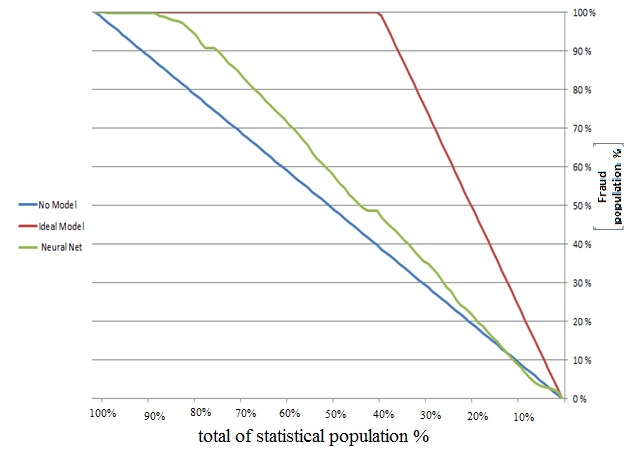 | Figure 6. Fraudulent population ratio to total of population in the neural network model |
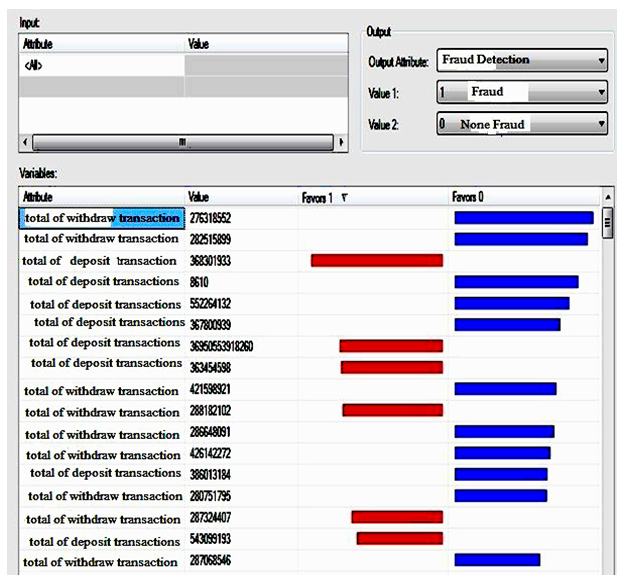 | Figure 7. Chart created by classes label for neural network model |
4. Conclusions
- Details of transactions is an important source related to the 20,000 financial institution clients account number that it is an important source for data mining. Because, very high volume of information are related to transactions of client's account that represents their behavior and source of high information is dynamic. One of the main problems of financial and credit institutions by extending the jobber clients, increased behavioral diversity and the loss of financial resources and it will be reduce institute consumer confidence. Therefore, terrorist actions of some jobber clients should have been identified and possibly to submit proposals to prevent a fall in the confidence of clients and increased the security of the financial institutions. In this study suggest that the use of decision trees because the goal is to predict consumer fraud and financial institutions, after mining the type of anticipation. Model based on decision tree algorithm better, it has higher accuracy and speed than neural network. When the decision tree due to prune the tree after the tree branches that the risk of fraud is minimal, they will be removed. This method makes it easier to evaluate the model. Missing data very little in model created in detail of transactions on client accounts, but the accumulation of information and the use of CIFs data preparation phase is very important. If the predictive of fraud is respect to client account transactions behavior it should be based on the type of client, transactions are aggregated. After this stage, the aggregated data should be normalized. Because there is no specific measure to analyze the obtained data are very hard, but if the data has a high or low level that they are better understood. Therefore, data should be normalized. One of the benefits of the details of transactions on client accounts to other clients of the financial institution and credit characteristics, including characteristics such as age, place of residence, education, address, etc. The data mining techniques of outlier detection and visualization have seen only limited use. The lack of research on the application of outlier detection techniques to FFD may be due to the difficulty of detecting outliers. Indeed, Agyemang et al. [1] point out that outlier detection is a very complex task akin to finding a needle in a haystack. Distinct from other data mining techniques, outlier detection techniques are dedicated to finding rare patterns associated with very few data objects. In the field of FFD, outlier detection is highly suitable for distinguishing fraudulent data from authentic data, and thus deserves more investigation. Fanning and Cogger highlight the challenge of obtaining fraudulent financial statements, and note that this creates enormous obstacles in FFD research.it is concluded that its attention toward finding more practical principles and solutions for practitioners to help them to design, develop, and implement data mining and business intelligence systems that can be applied to FFD [12]. The data is quite dynamic, and the data revealed, if the behavior of client changes the above-mentioned. Data normalization is better after aggregation of information on the different patterns of clients’ behavior. In this study, it concluded that the possibility of fraud was high for many special clients and it may have transport with different ways of such as dirty money through the financial institution, and legal clients through the creation of fictitious institution want to make money laundering that registration of the company or institution should be considered very carefully to prevent such acts. Conclusions are as follows:1) The presence of special clients in each institution will benefit to institutions and it is very useful to rise of institute resources. On the other hand, based on the results, the possibility of fraud is more among clients. Therefore, more focus is needed to uncover cases of fraud this group of clients. 2) Measures should be considered in addition trust of legal clients, transactions of these clients more control, as well as the delivery of documents when opening an account for legal clients more control in order to reduce the amount of fraud of group of clients.3) Measures should be considered to determine actual client behavior groups. In this case the behavior of a client can be more easily analyzed and identified suspicious.