-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2012; 2(5): 46-57
doi: 10.5923/j.computer.20120205.02
A Language Independent Platform for High Secured Communication Using Encrypted Steganography
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLVijayaratnam Ganeshkumar 1, Ravindra L. W. Koggalage 2
1Creative Technology Solutions Pte Ltd, Sri Lanka
2Deputy Vice Chancellor (Academic), General Sir John KotelawalaDefence University, Sri Lanka
Correspondence to: Vijayaratnam Ganeshkumar , Creative Technology Solutions Pte Ltd, Sri Lanka.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Computer usage is increasing, for both social and business areas, and it will continue to do so. This naturally leads to an increase in the way in which we as individuals and organizations we work for may be attacked.Increase of cyber-crime has compelledto re-think for a secure communication medium in our day-to-day life. Protecting the information during transmission is a foremostchallenge against eavesdroppers. Encryption is one of the widely used techniques that ensure the security of the message. However, sending encrypted messages often draw eavesdropper’s attention. Steganography is a method of letteringsecret messages in a way that nobody except for the sender and the recipient would suspect the existence of the hidden message. In other words, it’s an art/science of hiding messages. Steganography is often combined with cryptography so that even if the message is discovered it cannot be read.Historical steganography involved techniques such as disappearing ink or microdots. Modern steganography involves in computer files such as images, audio, video files and even in text documents. However, each stereographic technique is focused in just one medium; such as image or audio file and etc. And each steganographic algorithms had independent implementation; as a resultthere is no generic framework or application that will produce stegano medium for an end-user. In this paper, a generic framework is presented, which provides generic steganographic functionality via well-defined Application Programming Interface (API). So that the advanced developers can develop framework modules, this can be used by the end-users directly as stegangraphicapplication. And also this paper describes a newly invented steganographic technique which utilizes the inter-character spacing of a Rich-Text-Format (RTF) document. This technique can be used to transmit concealed messages in multi-language or combination of languages, which can be represented in Unicode. As an additional optimization technique; user defined code based (UDC) technique is also proposed to achieve compression of Unicode languages. Another advantage is that this technique can be used to send multi different language secret messages through the communication channel.
Keywords: Steganography, Cryptography, Security, Unicode, Multi-language, Encryption, Eavesdropper, Framework
Article Outline
1. Introduction
- Over the last few years, the usage of internet has been dramatically increased from youngsters to an expert. Not only internet has become an essential part of our daily life, but also been a reason for increase of cybercrime and cyber terrorism. Consequently, computer users have raisedthe level of anxietyin information security. The common question from any computer user would be ‘How securely a message can be sent over the internet?’ The level of security required by the user may vary from very low (such as forwarding a joke) to a very high (sending credit card information). To provide required security many attempts can be seen, and most widely used method is based on cryptography.Cryptography is the study and practice of encoding datausing transformation techniques so that it can only be decoded by specific users. In simpler words, it is a theory of secret writing. Cryptography is accepted as the most secured method of sharing information by security experts. However it has its own inherited weaknesses. For an example, the eavesdropper can easily suspect that a secret message is been transmitted just by tapping the message. Hence the eavesdropper may use cryptanalysis techniques to reveal the original message. As a counter measure for this weakness, a technique is desirable which should not draw attention of eavesdroppers. When a secret message is been transmitted. This is the exact idea behind the concept of Steganography. The main advantage of steganography when compared to cryptography is that the eavesdropper would not suspect that there is a hidden secret message, and hence it may not draw their attention. While cryptography is about protecting the content of messages, steganography is about concealing their very existence[1].The word steganography is of Greek origin and means "concealed writing" from the Greek words steganos (στεγανός) meaning "covered or protected", and graphein (γράφειν) meaning "to write". The first recorded use of the term was in 1499 by Johannes Trithemius in his Steganographia, a treatise on cryptography and steganography disguised as a book on magic[2]. The first recorded uses of steganography can be traced back to 440 BC, when Herodotus mentions two examples of steganography in The Histories of Herodotus.Demaratus sent a warning about a forthcoming attack to Greece by writing it directly on the wooden backing of a wax tablet before applying its beeswax surface[1], and this believed to be where the steganography had started. From the day it started, steganography is performed on images, multimedia files, and text, word and PDF files. Time to time steganography technique has evolved, and modern techniques are performed on H.264 video sequence[3], power point files[4] and stegno-digital-signals[5]. As a practice, message is entered usually in only one language. Most of the steganography algorithms are language depended. Researcher NatthawutSamphaiboon have proposed a steganography method for Thai text[6], Mohammad Shirali-Shahreza proposed method for Persian/Arabic Unicode text[7] and Changder presents new technique for Hindi language[8]. However, in the proposed framework, it supports multi languages (mixture of languages that can be used in a single message).
2. Addressed Problem
- In encryption, there are several algorithms such as RSA, Triple-DES, Blowfish, etc[19]. PGP and Microsoft are two main companies providing commercial cryptographic libraries which enable encryption. Therefore developers can use the API/SDK provided by them and develop their own security components. However, there is no such generic framework available for steganographic techniques.Presently modern steganography targets the digital medium such as images, documents, media files (audio/video) to hide secret messages. For example in in the case of text based steganography. There are several algorithms like Line shifting and word shifting. However for an end-user, it is not that easy to use such an algorithms as there is no user friendly tools/software available in the market. This paper presentsa layered architectural framework which can be used by the developer as well as end-user. In the case of developer, Steganographic Framework supports component or module based development platform where they could develop framework modules. For the end-user, how stegno medium is generated is not that important but what they really need is an application that would generate stegno message with minimum effort. It should also facilitate such as flexibility, ease of use and high security.According to the previous researches in steganography methods, each of them provides a language dependent algorithm, so that they cannot be used to send multi language messages. The proposed framework and the stegno RTF module is not language dependent and can be used in multi-language messaging and multiple language messages. In the case of multi-language message which consists of more than one language such as Sinhala, Tamil and Arabic. Hence it supports messages in different combinations of languages as follows:- Combination of languages in one language.- One message in one language, but collection of messages in different languages.- Independent from the transmitted language.
3. Related Work
- A. Steganography on ImagesImage is the most popular stegno channel used in steganography. Image is a collection of numbers that constitute different light intensities in different areas of the image[9]. This numeric representation forms a grid and the individual points are referred to as pixels. Most images on the internet consists of a rectangular map of the image’s pixels (represented as bits) where each pixel represents its colour[10]. The least significant bit (LSB) insertion is the most common way of embedding messages in the cover image. The least significant bit (8th bit) of all the bytes in the images is encoded with the secret message.B. Text SteganographyThere are quite a number of researches had already explored in new textual steganographic techniques. In Line shifting method, the lines in the text are vertically shifted to some degree (each line is shifted to 1/300 up or down) and the secret information is hidden by creating a unique shape of the text[11]. Also, if the text is re-typed or a character recognition program (OCR) used, the information will be destroyed.Shifting the words horizontally and changing the distance between words, and then information is hidden in the text[11] are called Word shifting. Same as Line shifting, retyping or OCR will destroy the message.C. Stegano on H.264 Video using Chaos-based AlgorithmRecently BoWanget. al. has done an exploration on how a message can be concealed into H.264 video stream. A steganographic algorithm for H.264 standard is proposed in their paper, in which chaos encryption is applied to the secret message before embedding[3]. D. Steganography on WLANMost of the network based steganography focus on Ethernet header modification and some focuses on timing channel based steganography[5]. The IEEE 802.11 MAC frame provided by the protocol has to be evaluated for possible points of transparent modification, where an embedding has no impact on the overall functionality of the underlying network traffic (the cover). This frame, which contains all IEEE 802.11 protocol data as well as the payload and consists of the nine fields[5].E. Steganography in Thai TextNatthawutSamphaiboon and Matthew N. Dailey[6] proposed a new blind steganographic scheme for Thai text that exploits redundancies in the way TIS-620 represents compound characters combining vowel and diacritical symbols. They found that the modifications made, when information bits are embedded in the carrier text are unnoticeable to casual observers[6].F. Persian/Arabic Unicode Text SteganographyTwo Iranian researchers Mohammad Shirali-Shahreza and SajadShirali-Shahreza have proposed a steganographic method conceal Persian and Arabic text using the different shapes regarding to its position in the word[7].G. Hindi Text SteganographyAn Indian researcherK.Prasad, invented a steganographic algorithm to conceal Hindi letters and its diacritics and numerical code. He suggests his method of approach can be applied to Hindi like other Indian languages[12].
4. Part I – Steganography in English Language
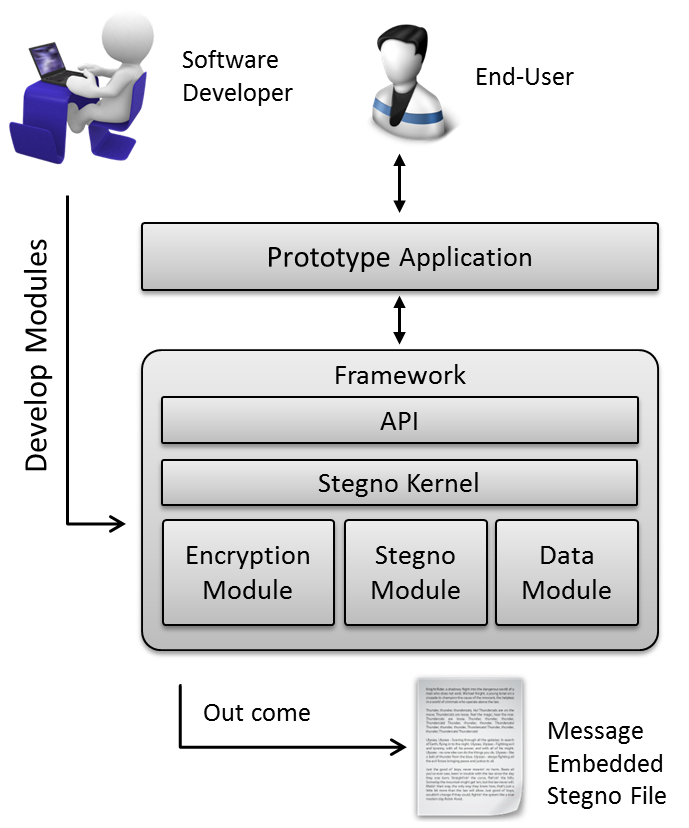 | Figure 1. Steganography Framework |
|
| |||||||||||||||||||||||||||||||||
 | Figure 2. Encoded message |
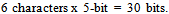 | (1) |
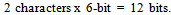 | (2) |
 | Figure 3. UDC Encoded RTF file |
 | Figure 4. UDC Encoded RTF in word processor view |
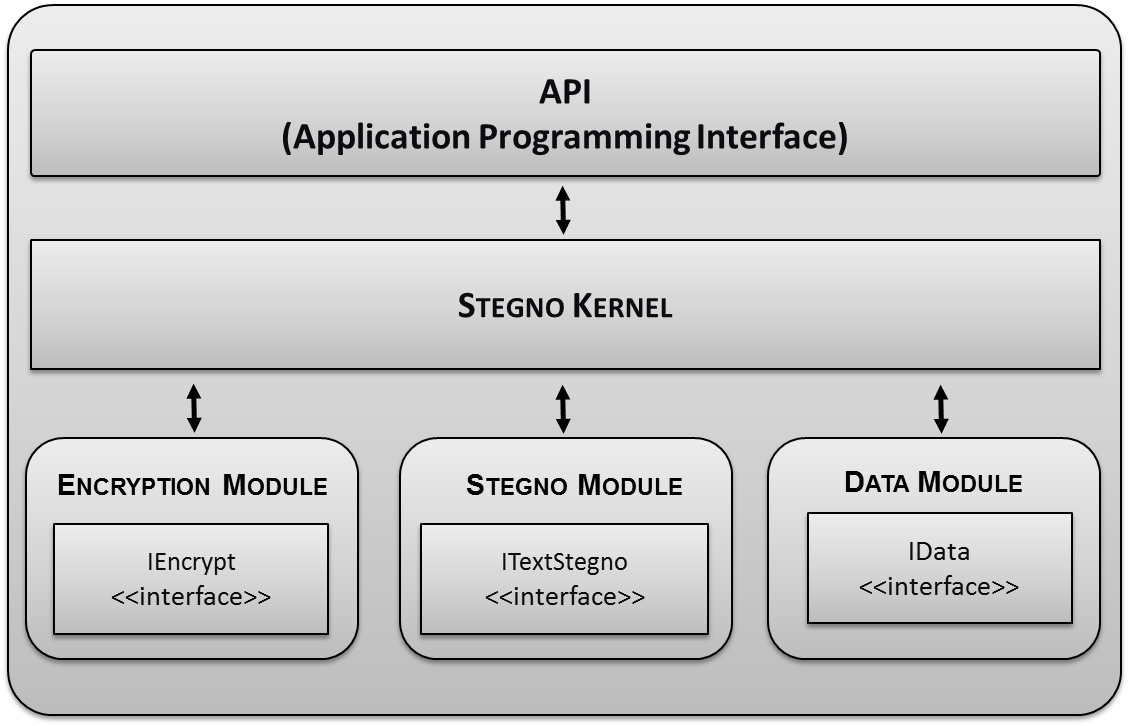 | Figure 5. High level design of the Framework |
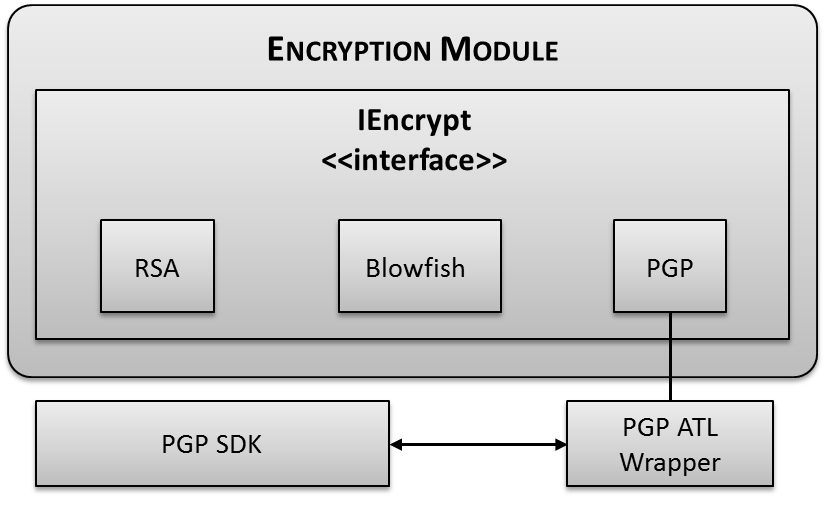 | Figure 6. Encryption module |
 | Figure 7. Stegno module interface |
 | Figure 8. Data module interface |
5. Part II – Multi Language Messages
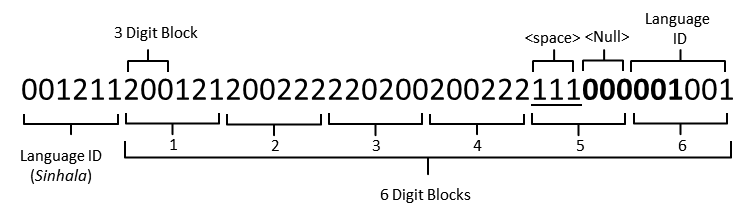
- According to the past researches, most of the steganographic algorithms are tightly coupled with particular language. These algorithms cannot hide languages. As an extension, this section proposes a language independent encoding method, which can encode messages in any language or combination of languages which can be represented in Unicode. What is Unicode?Computers deal with numbers in different bases (binary, octal, hex). They store all alpha numeric & special characters by assigning a unique number for each one. Before Unicode was invented, there were hundreds of different encoding systems for assigning these numbers. There was no single encoding system could contain enough characters: for example, the European Union alone requires several different encodings to cover all its languages. Even for a single language like English, no single encoding was adequate for all the letters, punctuation, and technical symbols in common use[13].These encoding systems have conflict with one another. That is, two encodings can use the same number for two different characters, or use different numbers for the same character. Any given computer (especially servers) needs to support many different encodings; yet whenever data is passed between different encodings or platforms, that data always runs the risk of corruption[13].Unicode provides a unique number for every character, which is independent from the platform, the program, and the language[13].A. Enchanced Encoding using UDCAccording to the Unicode standard, Unicode values range from 0000-FFFF, which contains 65535 characters. Thus each language has its own range of character mapping according to the Unicode standard.
|
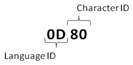 | Figure 9. Custom language and character ID mapping for Sinhala language |
|
 (data)” the local language is more understandable since English is used in braces.This section describes how to encode a message which was articulated using only one language using the proposed method. Let’s assume a message in Sinhala ‘’is the secret message that needs to be encoded. First step is to identify each character in the message and list down with the respective Unicode values and the corresponding User Defined Codes as in Table 5.As described earlier (Fig.9), the first two characters of the Unicode values are used as Language ID and the last two as the Character ID.Table 6 (column UDC) shows results of UDC encoding for each Unicode value.Since the entire message is in single (Sinhala) language, all the Language IDs are same for all the characters. Therefore, it is possible to assume the Language ID as the common value and excludes it from subsequent characters except for the first. The Fig.10 depicts the complete UDC encoded bit stream of the message.
(data)” the local language is more understandable since English is used in braces.This section describes how to encode a message which was articulated using only one language using the proposed method. Let’s assume a message in Sinhala ‘’is the secret message that needs to be encoded. First step is to identify each character in the message and list down with the respective Unicode values and the corresponding User Defined Codes as in Table 5.As described earlier (Fig.9), the first two characters of the Unicode values are used as Language ID and the last two as the Character ID.Table 6 (column UDC) shows results of UDC encoding for each Unicode value.Since the entire message is in single (Sinhala) language, all the Language IDs are same for all the characters. Therefore, it is possible to assume the Language ID as the common value and excludes it from subsequent characters except for the first. The Fig.10 depicts the complete UDC encoded bit stream of the message.
|
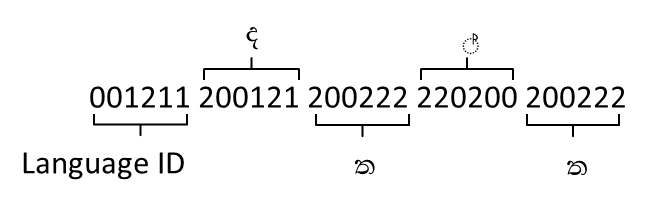 | Figure 10. UDC encoded message |
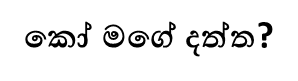 Careful analysis would reveal that the message typed in combination of two languages; Sinhala and Basic Latin (English). The characters are in Sinhala but
Careful analysis would reveal that the message typed in combination of two languages; Sinhala and Basic Latin (English). The characters are in Sinhala but
|
 ’ is encoded in the same way as discussed earlier. Next, the special character
’ is encoded in the same way as discussed earlier. Next, the special character 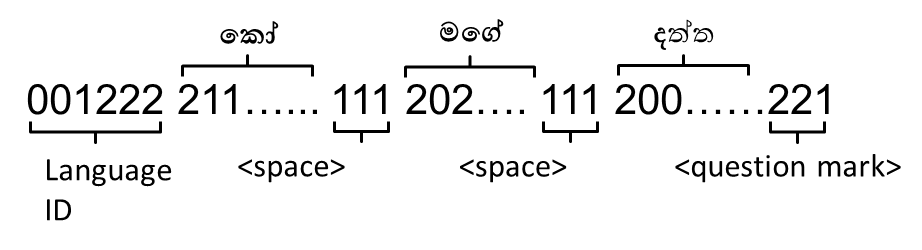 | Figure 11. UDC encoded message with special character |
 | Figure 12. Multiple language messages |
 ’, the next character is in English, so then there must be new Language ID for the rest of the characters. At the receiving/decoding end, there must be a way to instruct the decoder of a language termination. Therefore,
’, the next character is in English, so then there must be new Language ID for the rest of the characters. At the receiving/decoding end, there must be a way to instruct the decoder of a language termination. Therefore, 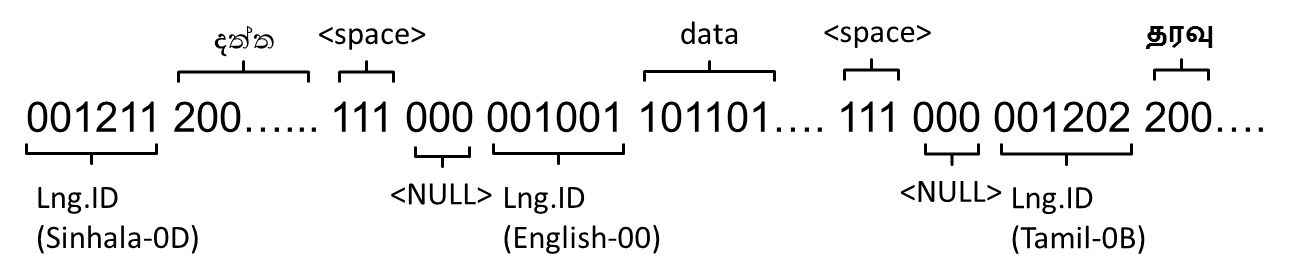 | Figure 13. UDC encoded message with three languages |
 | Figure 14. Decoding process |
6. ExperimentalResults
- This section is separated into two parts. First part evaluates the 6-bit UDC encoding and framework, whereas Part II assesses the multi-language encoding using Unicode.To evaluate the extended 6-bit UDC encoding, few sample messages were compared with Potdar’s method. Table 8 shows the sample messages and the character count for each method (5-bit and 6-bit). At a glance one may think 5-bit is better as it gives higher compression; however there are advantages & disadvantages for each method.According to the results (table 8), Potdar’smethod is better for the message ’A’ as it takes only 150 bits compared to 6-bit method. This is because the message ‘A’ consists of only alphabetic characters. However, for message ‘B’, it is other way round, since numeric values are in the message. The Potdar’s method requires more bits, because the numeric values are first converted to alphabetic characters (80000 à eighty thousand) and encoded. Same applies to messages ‘C - E’.
|
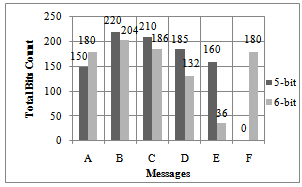 | Graph 1. Visual representation of Table 8 |
|
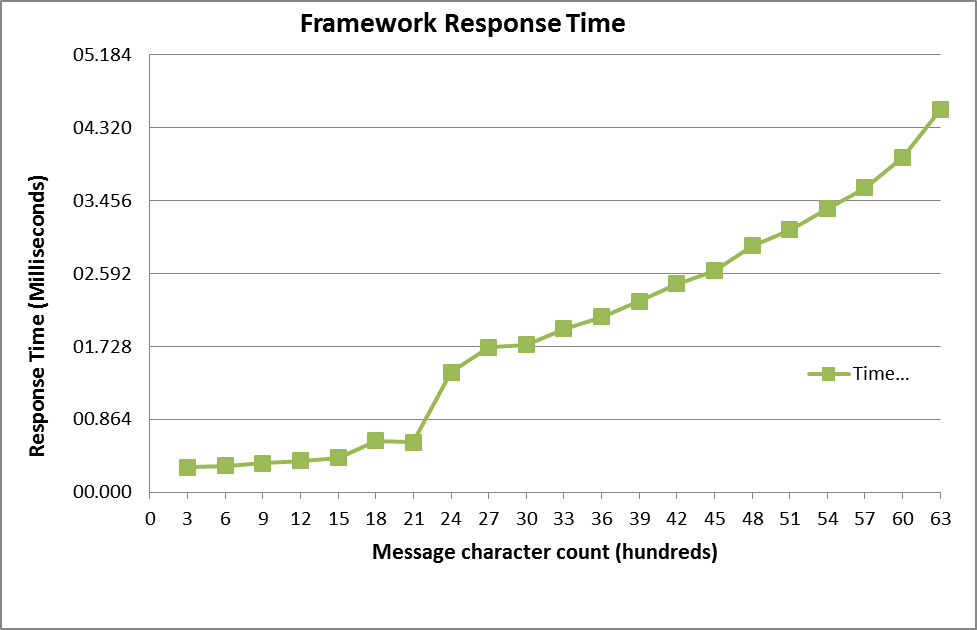 | Graph 2. Visual representation of Number of characters vs. Framework process |
 | Figure 15. Message in Russian, Greek and Urdu |
| |||||||||||||||||||||||||||||||||||||
|
7. Framework &Prototype Application Demo
- This section describes the prototype application which was developed using Steganography Framework. This demo application was developed to prove the ease of use for the end-user. You may find an online video of the prototype application.Demo: http://www.screencast.com/t/MAjp6dAczThis prototype application uses RTF stegno module and PGP as the encryption module. Collection of news article database was used as the data module. The application development environment as follows:.Net 2.0 and C#Microsoft SQL server 2008PGP desktop edition
8. Conclusions
- A common steganographic framework is presented in this research paper is useful for both an end-user as well as the developer.The prototype application demonstrates how flexible it is for an end-user to generate a stegno medium. In addition, a third party security product integration support provides more secured stegno messaging. This was demonstrated by integrating PGP to the framework as an Encryption module. In this manner any security algorithm (RSA, Triple DES, and Blowfish) can be integrated as modules. As for developers, the framework architecture opens the creativity by providing Stegno, Security and Data module APIs, so that they can develop modules and offer to end-users.UDC encoding is carried out as a pre-encoding step, to convert the secret message before applying the steganographic technique. This has further enhanced the strength of secrecy and compression of the information to be sent. In addition, the encoding supports multi language and multiple language stegno messaging. Therefore, an end-user can use this for messages containing any Unicode supported language and generate a stegno medium. This technique is further extends to encode multiple languages, so that a message can contain more than one language. As inter character spacing of the RTF file is utilized as a steganographic technique, it is possible to hide a secret message in one language into a document in another language Consequently the embedding technique is not depended on the language of the RTF document (transmitting message) and hence even a third party revealed the secret message, it can be in a totally different language which they do not understand. Therefore the possibility of revealing the original message is very low. This even increases the robustness of the proposed method.
ACKNOWLEDGEMENTS
- We would like to extend our very special heartfelt gratitude and appreciation to Mr. Marcelo Bossi, Senior Manager Business Development at PGP Corporation who has given extensive support by providing PGP SDK evaluation copy for our research, and also Mr. David Wiener, Associate General Counsel at PGP also remembered at this moment.
References
| [1] | Stefan Katzenbeisse, Information Hiding Techniques for Steganography and Digital Watermarking, Fabien, Ed.: Artech, 99. |
| [2] | Wikipedia.[Online].http://en.wikipedia.org/wiki/Steganography. |
| [3] | JiuchaoFeng, Guangzhou Bo Wang, "A chaos-based steganography algorithm for H.264 standard video sequences," Communications, Circuits and Systems, ICCCAS 08. International Conference. |
| [4] | Ling-Hwei Chen Wen-Chao Yang, "A novel steganography method via various animation effects in PowerPoint files," IEEE, Machine Learning and Cybernetics, International Conference, vol. 6, pp. 3102-3107, July 08. |
| [5] | Jana Dittmann, Andreas Lang, Tobias Kühne Christian Krätzer, "WLAN Steganography: A First Practical Review," ACM, International Multimedia Conference, pp. 17 - 22, 06. |
| [6] | NatthawutSamphaiboon and Matthew N. Dailey, “Steganography in Thai Text”, ECTI-CON 08. |
| [7] | Mohammad Shirali-Shahreza, SajadShirali-Shahreza, “Persian/Arabic Unicode Text Steganography”, The Fourth International Conference on Information Assurance and Security, 08. |
| [8] | Changder, S. Debnath, N.C. Ghosh, D, “A New Approach to Hindi Text Steganography by Shifting Matra”, International Conference on Advances in Recent Technologies in Communication and Computing, ARTCom '09, pp. 199-202. |
| [9] | I.V. Karpinskyy, M.P. Sagan, A.M. Vasiltsov, "Development of VHDL-based core with embedded steganography function," CAD Systems in Microelectronics, CADSM 03. Proceedings of the 7th International Conference, pp. 260- 261. |
| [10] | J.H.P. Eloff, M.S. Olivier T. Morkel, "An Overview Of Image Steganography," Proceedings of the Fifth Annual Information Security South Africa Conference. |
| [11] | M., Tehran Shirali-Shahreza, "Text Steganography by Changing Words Spelling," Advanced Communication Technology, ICACT 08 10th International Conference, vol. 3, pp. 1912-1913. |
| [12] | Alla, K. Prasad, R.S.R., “An Evolution of Hindi Text Steganography," Information Technology: New Generations, ITNG 09 Sixth International Conference, pp. 1577-1578. |
| [13] | The Unicode Standard, http://www.unicode.org, last visited: 14 May 2010. |
| [14] | Wikipedia,[Online].http://en.wikipedia.org/wiki/Chinese_character#Number_of_Chinese_characters. |
| [15] | Wikipedia,[Online].http://en.wikipedia.org/wiki/Han_unification. |
| [16] | Yong-Won Kim, Kyung-Ae Moon, and II-Seok Oh, "A Text Watermarking Algorithm based on Word Classification and Inter-word Space Statics," 03. |
| [17] | V.M. Han, S. Chang, E, Potdar, "Dictionary Module and UDC: Two new approaches to Enhance Embedding Capacity of a Steganographic Channel," Industrial Informatics, INDIN '05. 3rd IEEE International Conference, pp. 697- 700. |
| [18] | (2010, December) Tech-faq.com.[Online].http://www.tech-faq.com/cryptography.html. |
| [19] | (2010, Devember) Mycrypto.net.[Online].http://www.mycrypto.net/encryption/crypto_algorithms.html. |
| [20] | (2010, September) Tools.ietf.org.[Online].http://tools.ietf.org/html/rfc1896. |
| [21] | PeterWayner, Disappearing Cryptography Information Hiding Steganography and Watermarking, 3rd ed.: Morgan Kaufmann, 2002. |
| [22] | Ajith Abraham, Computational Social Network Analysis: Trends, Tools and Research Advances (Computer Communications and Networks), 1st ed., Aboul-Ella Hassanien, Ed.: Springer, 2009. |
| [23] | Rainer Böhme, Advanced Statistical Steganalysis (Information Security and Cryptography), 1st ed.: Springer, 2010. |
| [24] | Hiding in Plain Sight: Steganography and the Art of Covert Communication: Wiley, 2003. |
| [25] | Stefan Katzenbeisser, Information Hiding Techniques for Steganography and Digital Watermarking: Artech, 1999. |
| [26] | Jatinder N. D. Gupta, Handbook of Research on Information Security and Assurance, 1st ed.: Information Science Reference, 2008. |
| [27] | Barry J. Blake, Secret Language: Codes, Tricks, Spies, Thieves, and Symbols: Oxford University Press, 2010. |
| [28] | Dorothy Elizabeth Robling Denning, Cryptography and Data Security: Addison-Wesley, 1982. |