-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2012; 2(5): 43-45
doi: 10.5923/j.computer.20120205.01
Statistical Score Calculation of Information Retrieval Systems using Data Fusion Technique
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLB. Dhivakar 1, S. V. Saravanan 2, M. Sivaram 1, R. Abirama Krishnan 3
1CSE Department, Anna University of Technology, Coimbatore, 64104, India
2Principal, Christ the King Engineering, College, Karamadai, Coimbatore, 641104,India
3Lecturer in the PG Department of Commerce with CA, HKRH College, Uthamapalayam, Theni, 625516, India
Correspondence to: B. Dhivakar , CSE Department, Anna University of Technology, Coimbatore, 64104, India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Effective information retrieval is defined as the number of relevant documents that are retrieved with respect to user query. In this paper, we present a novel data fusion in IR to enhance the performance of the retrieval system. The best data fusion technique that unite the retrieval results of numerous systems using various data fusion algorithms. The study show that our approach is more efficient than traditional approaches.
Keywords: Rank Position, Borda Count, Condorcet Fusion, Fisher Criterion
Article Outline
1. Introduction
- A retrieval system is a machine that receives the user query and generate the relevance score for the query- document pair. The process of finding the needy information from a repository is a non-trivial task[1-3] and it is necessary to formulate a process that effectively submits the pertinent documents. The process of retrieving germane articles[4] is termed as Information Retrieval (IR). It deals with the representation, storage, organization of and access to the information items[3]. Fusion is a technique that merges results retrieved by different systems to form a unique list of documents. Document Clustering is based on particular ranked list and does not take benefit of multiple ranked list. The fusion function accepts these score as its output for the query document pair. A static fusion function has only the relevance scores for a single query-document pair as its inputs. A dynamic fusion function can have more inputs. To construct a dynamic fusion function that can adjust the way it fuses multiple retrieval systems relevance scores for a query document pair using additional input features such as query, retrieved documents and joint distribution of retrieval systems relevance score for the query. Various models, schemes and systems have been proposed to represent and organize the document collection in order to reduce the users’ effort towards finding relevant information[5]. In this study we present three different data fusion methods namely Rank Position, Borda Count, and Condorcet method in ranking retrieval systems. There are four feature selection techniques including Fisher Criterion, Golub Signal-to-Noise, traditional t-test and Mann-Whitney rank sum statistic.
2. Related Work
- Fox and Shaw showed the five combination function for combining scores[6]. They are as follows: CombMIN = Minimum of Individual SimilaritiesCombMAX = Maximum of Individual SimilaritiesCombSUM = Summation of Individual SimilaritiesCombANZ = CombSUM ÷ Number of non zero SimilaritiesCombMNZ = CombSUM × Number of non zero Similarities.Fusion functions which are different from Comb- functions with respect to the generation of answer sets, are also found in the literatures[8]. These functions assign ranks to the documents in the answer set against the relevance score assignment mechanism adapted in Comb-functions. Few such fusion techniques which emulate the social voting schemes, are the Borda and Condorcet fusions[8]. Borda Fuse and Condorcet’s fuse, and showed that the use of social welfare functions (Roberts, 1976) as the merging algorithms in data fusion generally outperforms the CombMNZ algorithm. Extensive work on Comb functions has been carried out by Lee[9–11] and based on the results he proposed few new rationales and indicators for data fusion. He concluded that CombMNZ is the better performing function than the others. The Probabilistic approach[12] differs from the Comb-functions in the way it selects a best performing strategy from a pool based on a predetermined probability value. The probabilistic model selects only one strategy from the pool while all other strategies remain unused. Hence, evolutionary algorithms are used to select the best performing strategies[13]. Meng and his co-workers (2002) indicate that metasearch software involves four components:1. Database search engine selector: the search engines [database] to be mingle selected using some system selection methods2. Query reporter: the queries are submitted to underlying search engines.3. Document Selection tool: Documents to be used from each search engine are determined. The simplest way is the use of the top documents.4. Unification of Result : The results of search engines are combined using merging techniques.
2.1. Lees Overlap Measure
- Lee’s [Lee, 1997] overlap measures, Orel and Ononrel, which measure the proportion of relevant and nonrelevant documents in the intersection of the two lists. These two measures are calculated as:
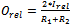 | (1) |
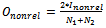 | (2) |
3. Data Fusion Scheme for Determining Top Ranked Relevant Documents
3.1. Rank Position Method
- The rank position of the retrieved documents are used to merge the documents into a single list . The rank position is determined by the retrieval system. We call d as the original document, while its counterparts in all other documents list are called Reference documents Rd of d. The following equation shows the statistical score calculation of document I using the position information of this document in all the systems (j=1,2,3,4…n).
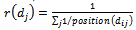 | (3) |
3.2. Borda Count Method
- Borda count and Condorcet method are based on democratic election strategies. The person with high score gets n votes and each successor gets one vote less than the predecessor i.e (n-1). If there are persons who are not interested in voting process, then the score is evenly divided among unranked candidates.Then, for each subsequent, all the votes are supplemented and the alternative with the highest number of score wins the election.
3.3. Condorcet Method
- In the Condorcet election method, voters rank the candidates in the order of partiality. It is a distinctive method that denote the winner as the candidate. Which prevail each of the other candidates in a pair-wise evaluation. To rank the documents we use their win and lose values.
4. Selection of Information Retrieval Systems for Data Fusion Technique
- We consider three approaches for the selection of information retrieval systems to be used in data fusion.Best: The best performing retrieval systems that achieve high percentage of the relevant documents retrieved are employed for statistical score calculation.Normal : All systems to be ranked are used in data fusion.Bias: The dissimilarity measure of the retrieval systems are used in data fusion. The Fisher Criterion, Golub Signal-to-Noise , traditional t-test and Mann-Whitney rank sum statistic were applied to calculate the statistical score, S, for the IRs. In these techniques, each system was measured for correlation with the class according to some measuring criteria in the formulas. The systems were ranked according to the score, S, and the top ranked relevant documents in the IRs were selected. The Fisher Criterion, fisher is a measure that indicates how much the class distributions are separated. The coefficient has the following formula:
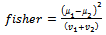 | (4) |
 | (5) |
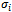 is the standard deviation of the relevant documents retrieved in class i.Traditional t-test,ttest assumes that the values of the two class variances are equal. The formula is as follows:
is the standard deviation of the relevant documents retrieved in class i.Traditional t-test,ttest assumes that the values of the two class variances are equal. The formula is as follows: 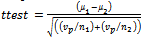 | (6) |
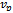 is the pooled variance.The Mann-Whitney rank sum statistics, mann has the following formula:
is the pooled variance.The Mann-Whitney rank sum statistics, mann has the following formula: 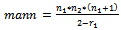 | (7) |
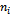 is the sizes of class ,
is the sizes of class , 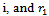 is the sum of the ranks in class i. The score,S, for each relevant documents retrieved in the IR is thus calculated by using the formula in these statistical techniques.The bias concept is used for the selection of IR system for data fusion. The cosine similarity measure is given by the following equation:
is the sum of the ranks in class i. The score,S, for each relevant documents retrieved in the IR is thus calculated by using the formula in these statistical techniques.The bias concept is used for the selection of IR system for data fusion. The cosine similarity measure is given by the following equation: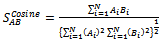 | (8) |
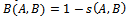 | (9) |
5. Discussion
- So far, our study suggest that, for our choice of retrieval systems, there is an opportunity to improve the retrieval performance by fusing the above mentioned approach. Our preferred design of effective statistical score calculation of information retrieval systems is a multilayer technique to maximize precision and improve the retrieval performance that satisfies the user needs. In this paper we have summarized various methods that are used in different articles published in the journal thereby incorporating and integrating few of the approaches may lead to better precision and recall values. Our significant contribution is thereby invoking the methods thereby integrating few of the techniques from various research articles so that it will be useful to the researchers for their valuable work in the future.
ACKNOWLEDGEMENTS
- Our Sincere thanks to our Professor Dr.S.V.Saravanan, Principal, Christ the King Engineering College for his valuable support in documenting and framing a new approach in this paper from various previously published articles in the journal.