-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
July, 2012;
doi: 10.5923/j.computer.20120001.01
Aprendizaje de Secuencias de AcciÓN Para la Toma de Decisiones en Instalaciones DomÓTicas
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLVicente Botón-Fernánde , José Luis Redondo-Garcí , Adolfo Lozano-Tello
Quercus Software Engineering Group Universidad de Extremadura Escuela Politécnica, Campus Universitario s/n, 10071
Correspondence to: Vicente Botón-Fernánde , Quercus Software Engineering Group Universidad de Extremadura Escuela Politécnica, Campus Universitario s/n, 10071.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Conocer los hábitos de comportamiento de los individuos puede contribuir a la toma de decisiones en entornos centrados en los humanos. Este trabajo presenta un modelo de aprendizaje dentro del proyecto IntelliDomo, un sistema capaz de aprender los hábitos de los individuos y de realizar la toma de decisiones para generar automáticamente reglas de producción que anticipen las actividades periódicas y frecuentes de los usuarios. La capa de aprendizaje incorpora nuevas características como la detección de secuencias de acción, ya que los hábitos pueden definirse mejor si están relacionados con acciones encadenadas, creando relaciones de acción-acción.
Keywords: Inteligencia Ambiental, Toma de Decisiones, Algoritmos de Aprendizaje, OntologÍAs, Intellidomo
Article Outline
1. Introducción
- En los últimos años, el diseño de entornos inteligentes se ha convertido en una de las áreas de investigación que está ganando importancia rápidamente en campos como la asistencia sanitaria, la eficiencia energética, etc donde la interacción entre los usuarios y el entorno constituye un factor fundamental. Además, factores como el envejecimiento de la población, el coste de los servicios de salud, y la importancia de que las personas vivan con independencia en sus hogares, están acrecentando aún más la necesidad de desarrollo de estas tecnologías. Una característica importante que deben poseer estos entornos es la habilidad para adaptarse a las preferencias de los habitantes y tener la versatilidad para tomar decisiones en todo tipo de situaciones. En este sentido, encontrar patrones de comportamiento dentro de una secuencia de eventos para predecir acciones futuras puede encaminarnos hacia la consecución de dichos objetivos. En consecuencia, el sistema será capaz de identificar y reconocer el comportamiento humano para utilizar este conocimiento en la toma de decisiones, anticipándose a las necesidades y preferencias de los habitantes. Por otra parte, la información adquirida por estas técnicas de detección de comportamiento podría utilizarse para llevar un seguimiento de las actividades periódicas de los usuarios y el orden en que las realizan, lo cual es especialmente interesante en el caso de personas ancianas para detectar posibles casos de Alzheimer y actuar en consecuencia[1].Obviamente, para descubrir estos hábitos y preferencias se necesita una tarea previa de aprendizaje. En un entorno inteligente, aprendizaje significa que el entorno tiene que adquirir conocimiento sobre las preferencias de los usuarios, su comportamiento común o patrón de actividad de una forma discreta y transparente para el usuario.El uso de ontologías[2] para clasificar los tipos de dispositivos domóticos y su funcionalidad supone una forma apropiada de representación de los conceptos de estos entornos. Las ontologías y las reglas SWRL (Semantic Web Rule Language) proporcionan una definición precisa de una taxonomía domótica: la localización de los dispositivos físicos, sus características y categorías funcionales (seguridad, eficiencia energética, confort…), y las relaciones entre ellos. Además, estas representaciones son reutilizables, por lo que otros usuarios pueden utilizarlas para clasificar sus propios componentes domóticos y construir reglas que permitan controlar el comportamiento del entorno.Este artículo describe las nuevas funcionalidades de la capa de aprendizaje de IntelliDomo, una propuesta de minería de datos para la gestión de sistemas AmI (Ambient Intelligence) y para el aprendizaje de comportamiento humano basada en ontologías, incluyendo ahora el reconocimiento de secuencias de acción. El resto del artículo se estructura de la siguiente forma: la sección 2 presenta distintas técnicas que se han utilizado hasta ahora para el desarrollo de modelos de aprendizaje en entornos inteligentes. La sección 3 describe la arquitectura y las características principales de los distintos módulos que conforman nuestro modelo de aprendizaje. La sección 4 profundiza en el funcionamiento de los algoritmos utilizados para el desarrollo del módulo de aprendizaje; y en la sección 5 se presenta uno de los casos de estudio utilizados para probar la validez de la aplicación. Por último, la sección 6 está dedicada a las conclusiones y trabajos futuros.
2. Minería de Datos Aplicada a Entornos Inteligentes
- En la actualidad, el desarrollo de técnicas de minería de datos para procesar e interpretar los datos capturados de un conjunto de sensores y actuadores en un entorno inteligente está ganando importancia debido a la necesidad de satisfacer los gustos de los usuarios y anticiparse a sus hábitos frecuentes. Existe un número significativo de proyectos de investigación sobre sistemas AmI que controlan y automatizan las tareas de los usuarios con distinto grado de éxito, y la mayoría de estos trabajos se centran en unos aspectos my concretos debido a la alta complejidad de estas arquitecturas. Sin embargo, la cantidad de literatura sobre entornos inteligentes que utilizan ontologías y reglas de producción como bases representativas no es demasiado extensa. A continuación, se presenta una visión general de algunas de las técnicas de aprendizaje automático que se han utilizado para el aprendizaje de patrones humanos y que de alguna forma han influido en el trabajo que aquí se expone.
2.1. Redes Neuronales
- Entre los primeros grupos de investigación que se encargaron de desarrollar aplicaciones para entornos inteligentes donde los patrones de los usuarios estaban involucrados se encuentran los de Mozer et al.[3] y Chan et al.[4]. Por un lado, en[3] se encargaron de diseñar un sistema de control adaptativo del entorno llamado Neural Network House, que estudiaba el estilo de vida de sus habitantes y el consumo de energía. Para ello utilizaron una red neuronal para predecir dónde se iba a encontrar el usuario en los próximos segundos, y usaban esta información para controlar la iluminación.Por otra parte, Chan et al.[4] desarrollaron un sistema que predecía la presencia o ausencia de usuarios, así como su localización. El sistema comparaba la ubicación actual con la predicción elaborada para determinar si la situación actual era normal o inusual.Basada en una red neuronal auto-adaptativa conocida como GSOM (Growing Self-Organizing Maps), Zheng et al.[5] diseñaron una plataforma de minería de datos para el análisis de actividades humanas dentro de un entorno domótico. Además, esta propuesta proporciona varios métodos que permiten un mejor análisis en áreas de interés muy concretas.
2.2. Aprendizaje Por Refuerzo
- Algunos de los grupos que hemos citado anteriormente han desarrollado un módulo basado en aprendizaje por refuerzo para dotar al entorno de la capacidad de adaptación.En este sentido, Mozer et al.[6] utilizaron Q-Learning para regular el alumbrado del entorno. El sistema trataba de minimizar el consumo de energía en tanto que el usuario no mostrase disconformidad, tomando como punto de partida la suposición de que el usuario no tenía preferencias iniciales.
2.3. TÉCnicas de Clasificación
- Otros grupos de investigación han optado por utilizar técnicas de clasificación como árboles de decisión o reglas de inducción. Los investigadores que trabajan en el entorno conocido como SmartOffice[7] desarrollaron, utilizando árboles de decisión, una aplicación que generaba reglas para separar y distinguir situaciones donde los datos del entorno indicaban reacciones diferentes por parte del usuario.Lühr et al.[8] presentaron un trabajo de minería de datos basado en la aplicación de IAR (Intertransaction Association Rule) para la detección de comportamiento anómalo en los usuarios de una vivienda domótica. Las IARs son reglas de implicación que permiten capturar las relaciones, no secuenciales, de los eventos capturados dentro de una vivienda. En este proyecto se utilizaban sus propiedades para detectar el comportamiento nuevo y, posiblemente anormal, en los habitantes y tomar partido de manera apropiada, como por ejemplo, consultar al usuario sobre el nuevo comportamiento, refrescarle la memoria acerca de una tarea que estaba haciendo o incluso alertar a algún familiar cuando sea necesario. Se trata, por tanto, de una propuesta orientada principalmente a las personas ancianas que viven de forma autónoma en sus viviendas.
2.4. Descubrimiento de Secuencias
- El proyecto MavHome[9] presentaba una aplicación orientada a la construcción de modelos universales, representados mediante Modelos de Markov, para deducir las localizaciones o actividades futuras de los habitantes de un entorno inteligente. La información suministrada se utilizaba luego para automatizar los dispositivos y adaptarlos en el tiempo en base al algoritmo de decisión ProPHeT[10]. CASAS[11] es un proyecto realizado por el mismo grupo que el anterior, el cual implementaba un modelo capaz de adaptarse a los individuos de un entorno domótico, descubriendo sus patrones frecuentes. Entre las aportaciones más recientes de este proyecto, se encuentra un método no supervisado de reconocimiento de las actividades que se utilizan para medir la salud funcional de los usuarios[12], de forma que pueda comprobarse si mantienen su rutina o no. Por último, Aztiria et al.[13] propusieron un proceso de descubrimiento de acciones del usuario en un sistema basado en reconocimiento de voz. Este sistema permitía al individuo interactuar con los patrones para así usar su aprobación a la hora de automatizar las acciones.
2.5. Conclusiones Sobre el Trabajo Relacionado
- Después de analizar todas estas aplicaciones, parece claro que el uso de una técnica u otra está condicionado por las necesidades concretas de cada entorno, tal y como apuntaba Muller[14]. Además, estos trabajos muestran que aún no existe una propuesta global de aprendizaje. En ese sentido, dadas las fortalezas y debilidades de distintas técnicas, la combinación de las mismas parece una estrategia prometedora. De este modo, nuestro módulo de aprendizaje se basa en algunas de las técnicas anteriores, especialmente en las relativas al descubrimiento de secuencias y en los conceptos ya expuestos en un trabajo previo[2], pero introduciendo nuevos parámetros configurables para crear un sistema donde el usuario pueda guiar al entorno a actuar de una manera personalizada, al mismo tiempo que se utiliza la información adquirida para servir de apoyo en la toma de las decisiones más importantes.
3. Arquitectura del Modelo de Aprendizaje
- La capa de aprendizaje que se presenta en este artículo se enmarca dentro del proyecto IntelliDomo (http://www.intellidomo.es)[2], un sistema inteligente capaz de controlar automáticamente los dispositivos de una instalación domótica y en tiempo real mediante reglas SWRL. Su característica principal radica en la capacidad de razonamiento y de respuesta en base a los continuos cambios que se producen en una instalación domótica.Cada evento capturado por los sensores y actuadores que están distribuidos por el entorno queda registrado. Para poder gestionar todo este conocimiento, IntelliDomo está construido sobre una ontología denominada Domo OWL, cuyos conceptos están relacionados con los dispositivos del sistema y que están basados parcialmente en los expuestos en la ontología DogOnt[15]. Esta ontología, Domo OWL, ha sido modelada para estar en sincronía con los dispositivos físicos que constituyen el entorno domótico, de forma que puedan almacenarse sus valores y propiedades destacadas, tal y como se aprecia en la Fig. 1. De este modo, los componentes domóticos podrán clasificarse según sean sensores o actuadores, y dentro de este último, en electrodomésticos, dispositivos del sistema eléctrico, dispositivos del sistema de calefacción y ventilación, etc. Además, las clases de dispositivos se relacionan con las de tipos de datos, de manera que a partir de la clase de dispositivo a la que pertenezca un componente físico concreto, pueda establecerse el tipo de datos que identifique su valor: continuo (como en el caso de sensores de temperatura, de luz, etc), discreto,… El bus EIB/KNX y la red X10 son los protocolos de comunicaciones soportados para nuestra instalación.Además, la ontología trabaja junto a un conjunto de reglas SWRL preestablecidas. El usuario puede modificar dichas reglas o crear otras nuevas mediante la herramienta IntelliDomoRules y automatizar de esta forma el comportamiento del sistema. El motor de inferencias de esta herramienta, Jess[16], decide qué regla debe dispararse en cada instante conforme a las prioridades y preferencias establecidas. Dicho motor de inferencia nos va a permitir inferir nuevo conocimiento en base a los hechos representados en las reglas SWRL.También existe una base de datos domótica (QDS_DB) donde IntelliDomo actualiza los valores de estado de los dispositivos físicos en tiempo real. De este modo, IntelliDomo se encarga de transferir los cambios instantáneamente desde el nivel físico (dispositivos) al lógico (base de datos) y viceversa, manteniendo la integridad de los datos.
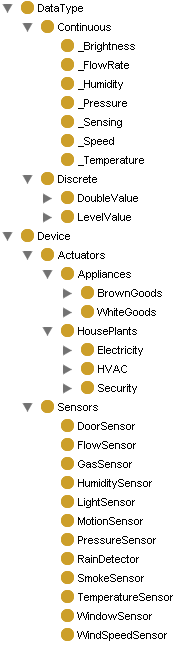 | Figura 1. Clasificación general de la ontología Domo OWL |
4. Aprendizaje Para la Toma de Decisiones
- El aprendizaje de patrones de comportamiento no es un aspecto más del sistema que puede conllevar algunas ventajas para un entorno inteligente, sino que más bien lo consideramos como una aportación esencial para formalizar la idea de que un entorno pueda actuar inteligentemente. Proporciona respaldo a entornos que se adaptan a sus usuarios de forma discreta y de manera que dichos usuarios queden liberados de la carga de programar continuamente los dispositivos domóticos. Por tanto, la habilidad para aprender hábitos de comportamiento y actuar en consecuencia es de suma importancia para implementar con éxito un entorno inteligente.
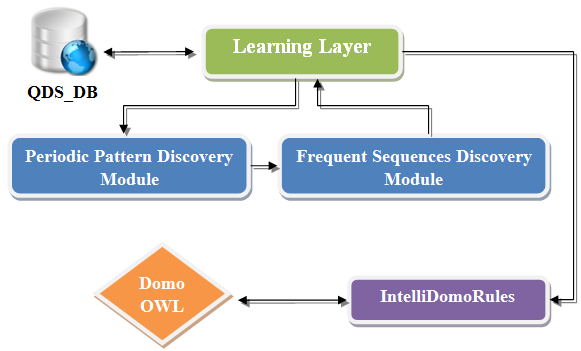 | Figura 2. Arquitectura de la capa de aprendizaje de IntelliDomo |
4.1. Primera Fase: Descubrir Patrones Periódicos
- Como ya se ha mencionado, gran parte del desarrollo de esta fase está incluida en los trabajos previos[2] y[17], por lo que en este sub-apartado se presenta un resumen de la misma para entender los nuevos cambios añadidos a partir de la siguiente etapa. Las bases del algoritmo que rige este módulo están fuertemente influenciadas por el algoritmo Apriori de Rekesh Agrawal[18]. El objetivo principal de esta primera fase consiste en detectar acciones periódicas, basadas en el razonamiento temporal, a partir de los datos de entrada. Un patrón se describe como un evento periódico, bien definido y aislado. Estas tres características se explican a continuación.Consideremos la frecuencia fi como el número de veces que una determina acción {di, si, ti} se repite en el conjunto de datos. Para poder calcularla, se debe definir un rango de acción ri =[ti-α, ti+α], donde α es una constante para ampliar o reducir el radio de búsqueda, para establecer el intervalo de tiempo a considerar en las repeticiones, ya que las acciones diarias de los usuarios no se repiten exactamente a la misma hora. De este modo, otra tupla {dj, sj, tj} se considerará una repetición de la anterior si afecta al mismo dispositivo de la misma forma (di=dj ^ si=sj) y su marca de tiempo está dentro del rango de acción (tj Є[ti-α, ti+α]).Una frecuencia de acción se considerará relevante cuando alcance un determinado umbral μ al que llamaremos soporte mínimo, y que viene dado por el tamaño del conjunto de datos de entrada. Un patrón se considerará periódico y bien definido cuando se repita frecuentemente alcanzando el soporte mínimo y con una cierta periodicidad (fi >= μ). La periodicidad representa la regularidad de ocurrencia de las acciones o actividades. El módulo de aprendizaje considera varios tipos de periodicidad: diaria, semanal, mensual,… ya que existen comportamientos diferentes dependiendo de estos tipos de temporalidad.Debido a la naturaleza errática de los humanos, diferentes tipos de actividades pueden mezclarse en el tiempo, generando ruido en los datos y provocando dificultades en la detección de patrones periódicos. Por esta razón, el algoritmo establece un nuevo valor umbral η para eliminar dicho ruido y determinar si un conjunto de acciones puede identificarse claramente como una única unidad o no. Este parámetro se denomina porcentaje de ruido. Un patrón periódico y bien definido se considera aislado cuando no excede el porcentaje de ruido en los datos. El análisis de secuencias de eventos encadenados, principal aportación de este artículo, se estudia en un nuevo proceso de minería de datos, basado en el anterior, que veremos en el siguiente sub-apartado.
4.2. Segunda Fase: Descubrir Secuencias de Acciones Frecuentes
- La segunda fase tiene como objetivo descubrir secuencias frecuentes de acciones consecutivas, y está influenciada por el algoritmo ED (Episode Discovery)[10]. En este caso, la marca de tiempo de dichas acciones ya no goza de tanta importancia como en el módulo anterior. Lo importante ahora es detectar que cada vez que una acción “A” tiene lugar, una secuencia de acciones “B”, “C”,… tendrá lugar después, tal y como se aprecia en la Fig. 3. En cuanto al descubrimiento de secuencias de acciones o actividades, no tiene sentido analizar exclusivamente el razonamiento temporal, puesto que en ese caso la frecuencia que determina si una acción puede considerarse como un hábito frecuente viene dada por repeticiones cercanas en el tiempo.
 | Figura 3. Ejemplo de patrón frecuente ABC |
4.3. Tercera Fase: Validando el Proceso de Aprendizaje
- El usuario puede rellenar los parámetros de configuración descritos arriba, así como decidir qué eventos del conjunto total de datos van a ser evaluados por el módulo. Sin embargo, por lo general el proceso de aprendizaje se ejecutará offline en intervalos regulares confirmados por el usuario. En cuanto finaliza el proceso de aprendizaje, el sistema genera automáticamente una regla SWRL para cada patrón y el usuario puede decidir cuáles de ellas se van a activar para ser procesadas por IntelliDomoRules. La transformación de estos patrones en reglas se realiza a través del parser de IntelliDomo, que se encarga de convertir las cadenas de texto generadas en la capa de aprendizaje en SWRLAtoms. Estos átomos tienen un formato predefinido, que es el siguiente: Propiedad (Instancia, Valor) y Clase (Instancia). Además, existe otro tipo especial de átomos, denominados Built-inAtoms, que permiten al usuario definir otros formatos de predicado y su interpretación. La Fig. 4 muestra un ejemplo de una actividad transformada ya en formato SWRL y de cómo son dichos átomos.
 | Figura 4. Ejemplo de actividad en formato de regla SWRL |
5. Caso de Estudio
- En esta sección se describe uno de los casos de prueba que hemos desarrollado con el fin de comprender mejor los conceptos mencionados anteriormente y entender su aplicabilidad en casos como la asistencia médica.En primer lugar, se considera el siguiente escenario para llevar a cabo el experimento: Antonio es un anciano de 60 años que vive sólo y al que le gustaría disponer de un sistema que le facilitase su vida diaria. Los días laborables se levanta poco después de que suene la alarma a las 08:00 a.m. y luego se viste. Sin embargo, los lunes, miércoles y viernes suele ir al baño unos 10 o 20 minutos después de despertarse, encendiendo previamente el calentador. Es entonces cuando aprovecha para darse una ducha, poniendo la temperatura del agua en 24 grados. Después de salir del baño, sube todas las persianas. Cuando entra en la cocina, enciende la televisión y pone en marcha la cafetera para desayunar mientras ve su programa favorito. A las 09:00 a.m., tras haber desayunado, se marcha de la casa. A las 03:00 p.m. regresa de trabajar y enciende la calefacción para mantener el ambiente acondicionado lo que resta del día. A continuación, unos 30 minutos después vuelve a la cocina para calentarse la comida y comer. Cuando termina, se retira a su habitación para descansar. Los miércoles, cuando se levanta de la siesta, se dirige al salón para encender la radio y escuchar el programa deportivo mientras lee el periódico junto a la luz de un flexo. Todos los días suele cenar en el salón para irse posteriormente a la cama sobre las 11:00 p.m.El escenario anterior es propicio para automatizar los hábitos del individuo y quitarle carga de trabajo, al mismo tiempo que la información adquirida puede ser utilizada por personal médico para corregir malos hábitos y detectar posibles casos de Alzheimer (por ejemplo, si se detectan signos de desorientación al observarse que el individuo vuelve con frecuencia a sitios de la casa donde ya ha estado). Para llevar a cabo nuestro proceso de aprendizaje, todas las acciones que lleva a cabo el usuario sobre los dispositivos ubicados en este escenario, incluida la información capturada por los distintos tipos de sensores, quedan registradas en la base de datos de IntelliDomo. Para la recogida de estos datos, se ha establecido un período de estudio de 4 meses, en el que se ha registrado toda la información que formará parte del conjunto de datos para la evaluación. Una vez que la base de datos de log está preparada con información suficiente, el individuo tiene la opción de configurar los parámetros del módulo de aprendizaje. En este caso, se ha optado por dejar los valores por defecto: soporte mínimo de un 60%, 5 minutos de rango de acción, porcentaje de ruido del 30%, y periodicidad diaria y semanal. En general, el módulo de aprendizaje se ejecutará offline en intervalos regulares (una vez al mes).Para este escenario de prueba, se ha analizado el conjunto de datos con dos versiones del aprendizaje, la del trabajo previo (sólo patrones periódicos) y la que se presenta en este artículo (patrones periódicos y secuencias de acciones). Los patrones de comportamiento generados por cada una de las versiones se muestran en la Tabla 1 y la Tabla 2, respectivamente.
|
| ||||||||||||||||||
6. Conclusiones y Trabajo Futuro
- La Inteligencia Ambiental es una de las áreas de investigación actuales que está ganando importancia en el desarrollo de entornos centrados en los usuarios. Con este trabajo se persigue descubrir las actividades periódicas y frecuentes de los humanos dentro de un entorno domótico, ya que al automatizarlas se consigue que el entorno sea receptivo hacia sus usuarios, quitándoles la carga de trabajo de las tareas repetitivas y favoreciendo la monitorización de dichas actividades, lo cual puede resultar útil en el ámbito sanitario. Hasta ahora, en los trabajos anteriores nos habíamos centrado en automatizar exclusivamente las acciones periódicas en el tiempo, sin considerar las relaciones entre los distintos eventos capturados a lo largo del día. Finalmente, con la incorporación de un nuevo módulo de aprendizaje para el descubrimiento de secuencias de acciones comunes, se ha conseguido completar y mejorar el trabajo previo como así indican las pruebas realizadas hasta el momento.Por otro lado, la combinación del análisis de contexto con el razonamiento temporal representa una técnica prometedora para comprender el comportamiento humano y permitir al entorno actuar y decidir conforme a las preferencias y prioridades de sus usuarios. La incorporación de parámetros configurables junto con el uso de ontologías y reglas de producción SWRL se ha realizado buscando la adaptación del modelo hacia una propuesta global que sea fácil de usar por los usuarios y cuyo conocimiento sea reutilizable.Actualmente estamos desarrollando módulos específicos de toma de decisiones para adaptar esta propuesta a escenarios concretos y más sustanciosos (eficiencia energética, asistencia sanitaria, seguridad,...), ya que si el entorno conoce cómo se comportan los usuarios, puede tomar decisiones que automaticen esos hábitos mientras mejoran su funcionamiento en base a diferentes aspectos.
AGRADECIMIENTOS
- Este trabajo se ha desarrollado con el apoyo y soporte de Cátedra Telefónica de la Universidad de Extremadura, FEDER, TIN 2011-27340 y Junta de Extremadura.
References
| [1] | V. Rialle, C. Ollivet, C. Guigui and C. Hervé, “What do family caregivers of alzheimer’s disease patients desire in smart home technologies? Contrasted results of a wide survey,” in Methods of Information in Medicine, vol. 47, pp. 63-69, 2008. |
| [2] | P. Valiente-Rocha, J. L. Redondo-García and A. Lozano-Tello, “Ambient intelligence system for controlling home automation instalations,” Fifth Iberian Conference on Information Systems and Technologies, pp. 1-6, June 2010. |
| [3] | M. C. Mozer, R. H. Dodier, M. Anderson, L. Vidmar, R. F. Cruickshank and D. Miller, “The neural network house: an overview,” in Current trends in connectionism, L. Niklasson and M. Boden, Eds.Erlbaum, pp. 371–380, 1995. |
| [4] | M. Chan, C. Hariton, P. Ringeard and E. Campo, “Smart house automation system for the elderly and the disabled,” IEEE International Conference on Systems, Man and Cybernetics, pp. 1586–1589, 1995. |
| [5] | H. Zheng, H. Wang and N. Black, “Human activity detection in smart home environment with self-adaptive neural networks,” IEEE International Conference on Networking, Sensing and Control, pp. 1505-1510, May 2008. |
| [6] | M. C. Mozer, “Lessons from an adaptive home,” in Smart Environments: Technology, Protocols and Applications, D. J. Cook and S. K. Das, Eds. Wiley-Interscience, pp. 273–298, 2004. |
| [7] | C. L. Gal, J. Martin, A. Lux and J. L. Crowley, “Smartoffice: design of an intelligent environment,” in IEEE Intelligent Systems, vol. 16, no 4, pp. 60-66, 2001. |
| [8] | S. Lühr, G. West and S. Venkatesh, “Recognition of emergent human behavior in a smart home: a data mining approach,” in Pervasive Mobile Computing, vol. 3, issue 2, pp. 95-116, 2007. |
| [9] | G. M. Youngblood, D. J. Cook and L. B. Holder, “Managing adaptive versatile environments,” in Pervasive and Mobile Computing, vol. 1, no 4, pp. 373-403, 2005. |
| [10] | G. M. Youngblood and D. J. Cook, “Data mining for hierarchical model creation,” in IEEE Transactions on Systems, Man and Cybernetics, Part C: Aplications and Reviews, vol. 37, no 4, pp. 561-572, July 2007. |
| [11] | P. Rashidi and D. J. Cook, “Keeping the resident in the loop: adapting the smart home to the user,” IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, vol. 39, no 5, pp. 949-959, 2009. |
| [12] | P. Rashidi, D. Cook, L. Holder, and M. Schmitter-Edgecombe, “Discovering activities to recognize and track in a smart environment,” IEEE Transactions on Knowledge and Data Engineering, vol. 23, no 4, pp. 527-539, 2011. |
| [13] | A. Aztiria, A. Izaguirre, R. Basagoiti and J. C. Augusto, “Learning about preferences and common behaviours of the user in an intelligent environment,” in Behaviour Monitoring and Interpretation –BMI- Smart Environments, Ambient Intelligence and Smart Environments book series, vol. 3, pp. 289-315, 2009. |
| [14] | M. E. Muller, “Can user models be learned at all? inherent problems in machine learning for user modelling,” in Knowledge Engineering Review, vol. 19, Cambridge University Press, pp. 61–88, 2004. |
| [15] | D. Bonino and F. Corno, “DogOnt – Ontology modelling for intelligent domotic environments,” Seventh International Semantic Web Conference, pp. 790-803, October 2008. |
| [16] | E. J. Friedman-Hill, “Jess in action: rule-based systems in java,” Manning Press, 2003. |
| [17] | V. Botón-Fernández and A. Lozano-Tello, “Learning algorithm for human activity detection in smart environments,” IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, pp. 45-48, August 2011. |
| [18] | R. Agrawal and R. Srikant, “Mining sequential patterns,” Eleventh International Conference on Data Engineering, pp. 3-14, March 1995. |