M. A. Keyvanrad , M. M. Homayounpour
Laboratory for Intelligent Signal and Speech Processing, Amirkabir University of Technology, Tehran, Iran
Correspondence to: M. M. Homayounpour , Laboratory for Intelligent Signal and Speech Processing, Amirkabir University of Technology, Tehran, Iran.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Abstract
This paper proposes a two layer classifier fusion technique using clustering of training data from speakers of the same gender for automatic gender identification (AGI). The first layer is an acoustic classification layer for mapping MFCC and pitch acoustic feature space to score space. In this layer, a divisive clustering is proposed for dividing the speakers from each gender to some classes, where speakers in each class have similar vocal articulatory characteristics. Finally, the best structure could map 22 feature coefficients to 5 likelihood scores as new features. The second layer is a back-end classifier that receives the vectors of fused likelihood scores from the first layer. This means that the new feature coefficients are used in the second layer. GMM, SVM and MLP classifiers were evaluated in the middle and back-end layers. 96.53% gender classification accuracy was obtained on OGI multilingual corpus which is much better than the performance obtained by traditional AGI methods.
Keywords:
Gender Identification, Classifier Fusion, Clustering, GMM, SVM, MLP
Cite this paper:
M. A. Keyvanrad , M. M. Homayounpour , "Automatic Gender Identification Using Fusion of Generative and Discriminative Classifiers and Clustering of Spekaers from the Same Gender", Computer Science and Engineering, Vol. 1 No. 1, 2011, pp. 22-25. doi: 10.5923/j.computer.20110101.04.
1. Introduction
Automatic Gender Identification (AGI) is a technique to determine the user sex of a voice processing system through speech signal analysis. Automatically detecting the gender of a speaker has several advantages. In speech recognition systems, gender dependent models are more accurate than gender independent ones[1]. For example, the performance of SPHINX-II, an ASR system developed by Carnegie Mellon University, improved when gender dependent parameters were used[2]. In the context of speaker recognition, gender detection can improve the performance by limiting the search space to speakers from the same gender[1]. Also, in the context of content-based multimedia indexing, the speaker’s gender is a cue used in the annotation[1]. In addition, gender dependent speech coders are more accurate than gender independent ones[3]. Gender identification has become gradually a matter of concern in recent years. Harb and Chen (2005) used pitch and spectral features with multi layer perceptron classifier and reported 93% of classification accuracy[3]. Some other classifiers have also been used. For example Lee and Lang (2008) used SVM (Support Vector Machine)[4] and Silvosky and Nouza (2006) used G-MM[5]. In this paper, a fusion technique proposed for AGI. Scores obtained from an acoustic classification layer are fused and used as input feature vector for a back-end classification layer. In order to achieve the fusion of scores in a two class (male and female) classification task, speakers from each gender are clustered in several classes. This clustering helps to implement our fusion technique detailed in section IV and V. Different discriminative and generative classifiers are evaluated to be used in both acoustic and back-end layers. Experimental results approve the appropriateness of the proposed technique. After this short introduction, the OGI corpus will be explained in section 2. Section 3 explains three simple classifiers used in this paper, Section 4 explains the classifier fusion technique and section 5 describes AGI improvement using classifier fusion. The conducted experiments and the obtained results will be presented and discussed in section 6. Finally, section 7 concludes the paper.
2. Speech Database
The first release of Oregon Graduate Institute (OGI) Multilanguage Telephone Corpus collected by Muthusamy [6] was used in our experiments to evaluate the proposed techniques. This database consists of spontaneous factual speech utterances of ten languages uttered over telephone lines. This database contains 90 calls from each language, with a 50-20-20 division into training, development and final-test sets. All three divisions of OGI are employed in our experiments.In our experiment each gender identification test is done using long-term features obtained from each utterance. In this paper 4651, 1899, 1848 utterances are used for training, development and test respectively.
3. Simple Classifiers
In our AGI experiments three conventional classifiers including GMM, SVM and MLP are used. These classifiers are briefly introduced in the following subsections.
3.1. GMM
Given a set of feature vectors, the GMM suppose that their probability distribution function is a combination of several Gaussians (Figure 1). Therefore GMM is a compact representation for a given classification problem since the information is embedded in the Gaussian parameters. GMM are also fast in both the classification and the training processes [3].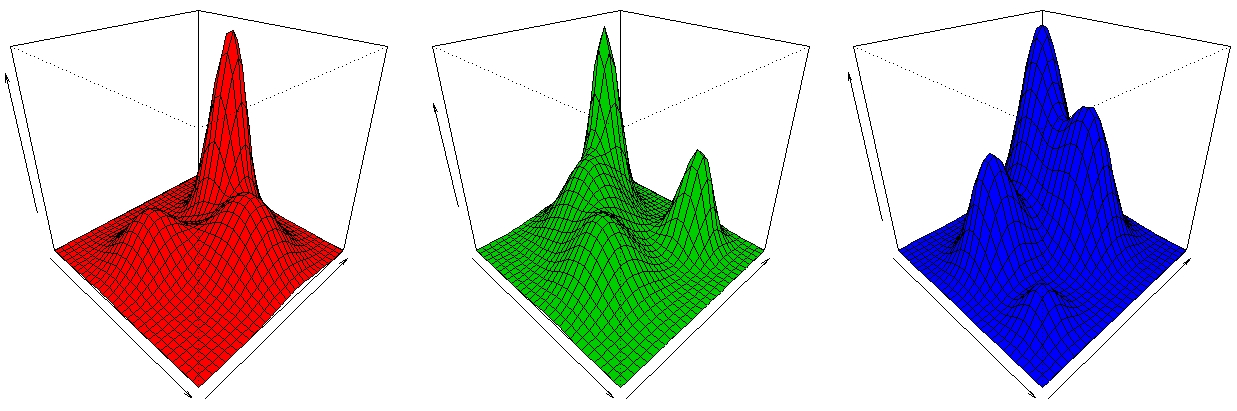 | Figure 1. Combination of several Gaussians in GMM Model. |
3.2. MLP
A Neural Network is very fast in the classification once trained; which is important for the real time applications. Moreover, a Neural Network can theoretically model complex shapes in the feature space (Figure 2). Also, the training time (or the number of epochs) can be an indicator on the complexity of the decision boundary for a given training set. Beside the classical accuracy indicator, this is another important indicator to examine the efficiency of the selected features and their suitability for a given classification problem. Finally, the compact representation of Neural Networks facilitates potential hardware implementation of the classifier[1].
3.3. SVM
The Support Vector Machine (SVM) performs a binary classification y ∈ (−1, 1) based on hyperplane separation. The separator is chosen in order to maximize the distances between the hyperplane and the closest training vectors, which are called support vectors. By the use of kernel functions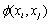 , which satisfy the Mercer condition, the SVM can be extended to non-linear boundaries (Figure 3):
, which satisfy the Mercer condition, the SVM can be extended to non-linear boundaries (Figure 3):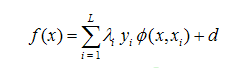 | (1) |
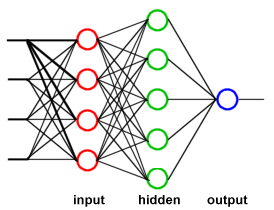 | Figure 2. Neural network structure. |
Where in Equation (1) yi are the target values and xi are the support vectors. λi have to be determined in the training process. L denotes the number of support vectors and d is a (learned) constant[1].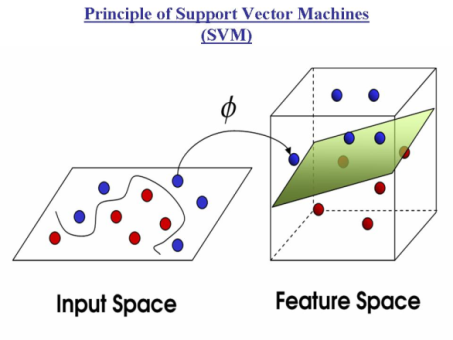 | Figure 3. Using kernel in SVM. |
4. Classifier Fusion
Classifier fusion technique is a method that employs a middle layer for extracting the scores and uses them as input feature for the back-end classifier. In the middle layer, some classifiers receive input feature vectors. These classifiers are trained using training dataset. In GMM fusion, Gaussian Mixture Models are used as classifiers. GMM fusion is one of the most popular fusion techniques that has already been used in language identification[2]. A GMM back-end classifier is deployed after the primary classification with the input vector of concatenated likelihood scores produced by middle layer classifiers (Figure 4). The back-end classifier is trained using the development dataset.In evaluation phase, the likelihood scores produced by the GMM back-end classifier (based on the inputs received from primary classification systems) are used for the final decision. The final decision is made based on the maximum likelihood score. Figure 4 depicts this process.
5. AGI Improvement Using Classifier Fusion
In AGI, we have only two classes (male and female speakers). Therefore, in order to be able to achieve more accurate middle layer, speech data from each gender is clustered and each cluster is considered as a new class. This clustering leads to forming groups of speakers, where each group (cluster) has similar speech characteristics such as vocal articulatory, segmental and supra segmental characteristics. The difference in these characteristics is due to the difference in age, accent, and speech habits. Clusters were created using the training part of OGI database. Then, a GMM model is trained for each cluster. According to the discussions in Section 3, these GMMs are used as middle layer classifiers which are used to convert feature vectors (MFCC and pitch features) to score vectors. Score vectors will then be used as input feature for the back-end GMM classifiers.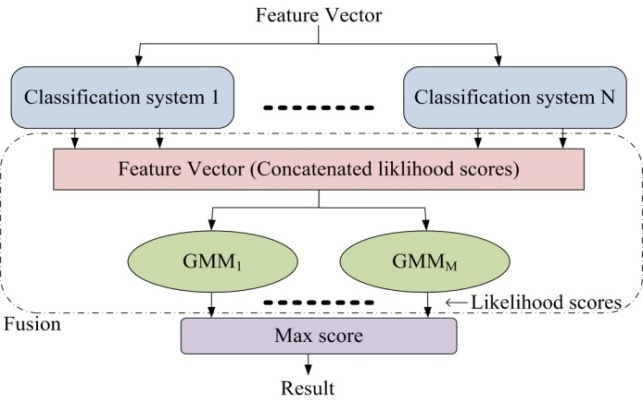 | Figure 4. GMM fusion technique (N is the number of classification systems e.g. GMM and M is the number of GMM models). |
Figure 5 illustrates GMM fusion technique for AGI. According to this figure, male training data is clustered to i clusters and female training data is clustered to j (=N-i) clusters. A GMM model is trained using data from each cluster. Two male and female GMM models are then trained as back-end classifiers in the last layer. The development part of OGI database is used for this training. To this end, the development data is feature extracted and is classified by middle layer classifiers. The obtained likelihood scores are concatenated to form the input vector for training male and female GMM back-end classifiers. We call the concatenation of classifier scores as classifier fusion.In the last step, the test part of OGI database is used to evaluate the proposed system. To do this, test speech data are feature extracted and classified by middle layer classifiers. The obtained likelihood scores are concatenated to form the input vector. These vectors are classified by male and female GMM back-end classifiers.GMM is a generative classifier which is usually used for general speech classification purposes. In order to improve the performance of the proposed system, MLP neural network as a discriminative classifier was used in place of GMM classifier in the middle layer (See Figure 6). So, both GMM and MLP were assessed as middle layer classifier to find out which one provides better scores to be used as input features for back-end classifiers.A MLP model was trained for each cluster in the middle layer. Training of a discriminative classifier for a given class needs some data from that class as relative data and data from other classes as non-relative data. Since there are N clusters in the middle layer, so N MLP models were trained (See Figure 6). 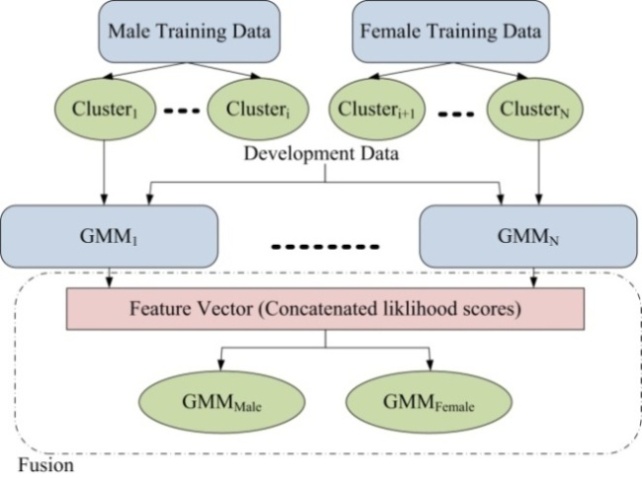 | Figure 5. Classifier fusion technique for AGI using GMM. |
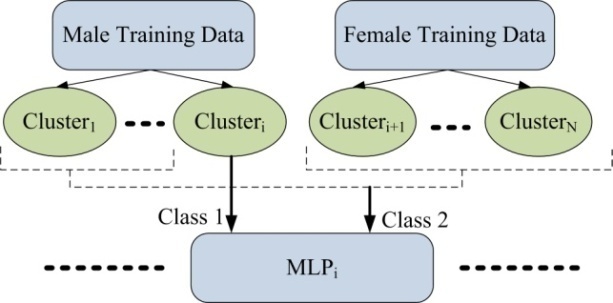 | Figure 6. Using MLP instead of GMM in the middle layer. |
To choose the best classifier in the last layer, three classifiers including MLP and SVM as discriminative classifiers and GMM as a generative classifier were also evaluated in this paper.
6. Experiments
Two features including MFCC with 21 coefficients as spectral features and pitch as a prosodic feature were used in our experiments. Higher MFCC coefficients were used since in our previous paper on feature selection, it was shown that the higher order MFCC coefficients outperform other MFCC coefficients for gender identification[3]. GMMs in the middle layer possess 64 Gaussian components. Also in SVM, RBF kernel with different values for RBF sigma value is used. In addition for large sample problem in SVM, samples are clustered to 256 clusters and their centroids are used as training data for construction of SVM models. MLP classifiers have one hidden layer and are trained using Gradient descent with momentum back propagation algorithm. The number of neurons in hidden layer is varying from 5 to 65 and the best value is used in each learning process.In the first experiment, simple gender classification (without any clustering and classifier fusion) was done using GMM, SVM and MLP classifiers. According to Table 1, gender identification performance of 92.7%, 95.17% and 93.75% were obtained using GMM, MLP and SVM, respectively. This result depicts that MLP outperforms two other classifiers for acoustic gender identification.| Table 1. AGI performance using GMM, SVM and MLP classifiers without any data clustering and classifier fusion. |
| | classifier | male performance | female performance | Average | | GMM | 95.46% | 89.94% | 92.70% | | MLP | 96.97% | 93.36% | 95.17% | | SVM | 92.81% | 94.69% | 93.75% |
|
|
Six other experiments were conducted to evaluate the proposed classifier fusion technique (see Figure 7). In each experiment, the number of clusters for males and females changed from 2 to 6 and the best results were considered. According to Figure 7, both GMM and MLP present high performances in the middle layer. Based on this figure, the best performance is obtained when the middle layer classifier is MLP. In this case, when the classifiers in the last layer are GMM, MLP and SVM, the final gender identification performance was improved from 92.70%, 95.17% and 93.75% to 95.43%, 96.53% and 95.42%, respectively. 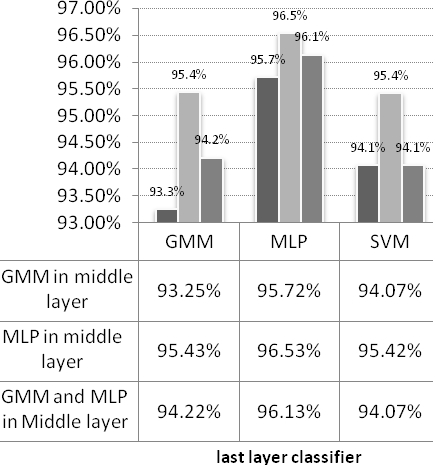 | Figure 7. Classifier fusion results using different classifiers in the middle layer and last layer. |
Using MLP in both middle and last layers leads to 96.53% accuracy which is the highest performance obtained in our experiments. Table 2 represents AGI when MLP is used in both middle and last layers with different number of clusters for each gender. According to Table 2 the best result is obtained when male and female training samples are clustered to 3 and 2 clusters respectively.| Table 2. Classifier fusion performance with different number of clusters for each gender (Columns are number of clusters for male and rows are number of cluster for female classes). |
| | | 2 | 3 | 4 | 5 | 6 | | 2 | 95.74% | 96.53% | 96.06% | 96.04% | 94.50% | | 3 | 95.30% | 95.37% | 95.56% | 95.30% | 93.42% | | 4 | 96.30% | 95.37% | 93.72% | 93.67% | 95.30% | | 5 | 95.58% | 95.24% | 94.82% | 95.01% | 94.71% | | 6 | 95.09% | 93.74% | 95.56% | 95.26% | 94.67% |
|
|
7. Conclusions
A classifier fusion approach was proposed in this paper for AGI. In this approach, the speakers of each gender are partitioned in several clusters and a GMM classifier is trained for each cluster in the acoustic level of the proposed AGI system. Each cluster may represent a group of similar speakers having similar vocal articulatory, segmental, supra segmental characteristics and speech habits. Scores from the acoustic level classifiers are fused to form input vector to back-end classifiers. Different classifiers in the middle layer (GMM or MLP or both of them) and different back-end classifiers (GMM or MLP or SVM) were evaluated. The experimental results depict that data clustering and fusing classifier scores lead to better performances for automatic gender identification compared to general techniques where no clustering and classifier fusion are done.
ACKNOWLEDGEMENTS
The authors would like to thank Iran Telecommunication Research Center (ITRC) for supporting this work under contract No. T/500/14939.
References
| [1] | H. Harb, and C. Liming, “Gender Identification using a General Audio Classifier,” in Multimedia and Expo, pp. II-733-6, 2003 |
| [2] | W. H. Abdulla, and N. K. Kasabov, “Improving Speech Recognition Performance Through Gender Separation,” in Artificial Neural Networks and Expert Systems International Conference (ANNES), Dunedin, New Zealand, pp. 218-222, 2001 |
| [3] | H. Harb, and L. Chen, “Voice-Based Gender Identification in Multimedia Applications,” Journal of Intelligent Information Systems, pp. 179-198, 2005 |
| [4] | K.-H. Lee, S.-I. Kang, D.-H. Kim et al., “A Support Vector Machine-Based Gender Identification Using Speech Signal,” IEICE Transactions on Communications, pp. 3326-3329, 2008 |
| [5] | J. Silovsky, and J. Nouza, “Speech, Speaker and Speaker's Gender Identification in Automatically Processed Broadcast Stream,” RADIOENGINEERING, pp. 42-48, 2006 |
| [6] | Y. K. Muthusamy, R. A. Cole, and B. T. Oshika, “The OGI multilanguage telephone speech corpus,” pp. 895-898, 1992 |
| [7] | T. Bocklet, A. Maier, J. G. Bauer et al., “Age and gender recognition for telephone applications based on GMM supervectors and support vector machines,” in, Institute of Electrical and Electronics Engineers Inc., Piscataway, NJ 08855-1331, United States, pp. 1605-1608, 2008 |
| [8] | Y. Bo, E. Ambikairajah, and F. Chen, “Hierarchical Language Identification Based on Automatic Language Clustering,” in Interspeech, Antwerp, Belgium, pp. 178-181, 2007 |
| [9] | M. A. Keyvanrad, and M. M. Homayounpour, “Feature Selection and Dimension Reduction for Automatic Gender Identification,” in 14th International CSI conference (CSICC2009), Tehran, Iran, pp., 2009 |
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTML