-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2011; 1(1): 8-14
doi: 10.5923/j.computer.20110101.02
Data Warehouse Scripts Generation Through MDA Cartridge
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLL. A. Fernandes , B. H. Neto , V. Fagunde , G. Zimbrão , J. M. D. Souza , R. Salvador
Systems and Computing Engineering, Federal University of Rio de Janeiro, Rio de Janeiro, PO Box 68511 ZIP 21945-970, Brazil
Correspondence to: B. H. Neto , Systems and Computing Engineering, Federal University of Rio de Janeiro, Rio de Janeiro, PO Box 68511 ZIP 21945-970, Brazil.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Increasing market competitiveness has led entrepreneurs to require more and more information from Information Technology areas to allow for efficient decision-making. Two alternatives to solving this problem are allied in this work: use of Model Driven Architecture (MDA) and Data Warehousing (DW). This research developed and tested a MDA cartridge. It creates scripts for automatic generation and loads DW based databases on the Online Transaction Processing Model (OLTP) through a MDA tool. With the use of this approach any change in the model would be a corresponding change in the scripts without manual rework.
Keywords: Database, MDA, Data Warehouse, Data Model
Cite this paper: L. A. Fernandes , B. H. Neto , V. Fagunde , G. Zimbrão , J. M. D. Souza , R. Salvador , "Data Warehouse Scripts Generation Through MDA Cartridge", Computer Science and Engineering, Vol. 1 No. 1, 2011, pp. 8-14. doi: 10.5923/j.computer.20110101.02.
Article Outline
1. Introduction
- The problems to be solved by software engineers are, most of the time, extremely complex. Besides the understanding of the nature of the problem and establishing what the system should do, it is necessary to adapt the solution proposed to the hardware and to one or more operating systems. A lot of these tasks have been automated with reasonable results with the use of Computer-Aided Software Engineering (CASE) tools. However, constantly changing requirements, functional and non-functional, after the initial survey, can generate rework, cost increase, term issues and, most likely, dissociation between the product developed and the documentation for this product. The more advanced the development is, the highest the probability of functional changes bringing problems to various parts of the project becomes. Another aspect observed is that systems become very dependent on the platform, which they were originally created. With time, as they get older, their maintenance turns expensive, as it currently happens with legacy systems[15]. With the emergence of new technologies, many systems have again been developed on other platforms without the re-use of the previously used technology. It was observed that the areas associated with decision-making are increasing their request for software. Data warehouses provide access to data for complex analysis, knowledge discovery and decision-making, offering support to the high performance demands for data and information in an organization[4].The data warehouse project is initially driven by projections of its use, meaning the expectations of those who will use it and how they will go about it. And despite being designed to read data, it is not a static structure, and it is expected that the databases evolve and that the data warehouse schema and the component of acquisition is updated to deal with these changes[4]. That way, the construction of a data warehouse is exposed to the same changing requirement issues and platform dependence, as any other software development project. The approach to software development called MDA, adopted by the OMG (Object Management Group), makes it easier for the developer to separate the logical part of the application (linked to business) from the technology platform used in its implementation. The biggest benefit is in the increase of the abstraction level in software development, in the way the developer is left to create a specific code in some language to focus on developing of models that are specific to the domain of the application, but are independent from the platform[10]. Thus, changes in the platform do not affect existing applications and the business logic can develop independently from the technology used. This article approaches a specific area of a DW project, the extraction, transformation and data load, known as Extract Transform Load (ETL). Using the CWM (Common Warehouse Metamodel) pattern, an experiment was created for script generation that obtains data from an OLTP base (Online Transaction Processing) to load it on a DW base afterwards. This article is organized as follows: Section 2 provides a brief review of key concepts relevant to the experiencediscussed here, Section 3 presents the work related to the corresponding research area, Section 4 presents the methodology used in development of the experiment, Section 5 presents the results obtained, Section 6 considers the results obtained and Section 6 provides some conclusions and a proposal for future work.
2. Concepts: From MDA to DW
2.1. MDA
- According[9], MDA is an approach that proposes, through his architecture, the separation of system specification from details of its operating mode that is inherent to the platform used. MDA was adopted in 2001 by the OMG as a framework that uses models in software development[13]. The point of view is an abstraction technique that uses a set of architectural concepts and structural rules to focus on specific system aspects, i.e., each view point focuses on one specific aspect[13]. MDA has three points of view: independent computation, independent platform, and specific platform. Computation Independent Viewpoint (CIV) treats the fundamental logic of the system and is separated from the specification of the specific platform. Computation Independent Model (CIM) is the model used in this point-of-view which shows a business model system normally prepared by the business analyst. Platform Independent Viewpoint (PIV) deals with the system operations and omits details pertaining to the platform. The Platform Independent Model (PIM) is used in this point-of-view and models the system functions generally prepared by an architect.Platform Specific Viewpoint (PSV) treats the implementation details for a specific platform. Platform Specific Model (PSM) treats this point of view modelling the implementation on one or more platforms. Therefore, it is common that several PSMs are connected to one PIM.According to[8], the transformation of a model consists of the generation of a target model from an original model, according to a preset definition for the transformation. In the MDA, the CIM can be translated to the PIM through mapping, and the PIM can be translated to a PSM, with the PSM translated into a code belonging to a specific language.
2.2. UML
- Unified Modelling Language (UML) is a graphical language for visualization, specification, and documentation of software systems via an object-oriented paradigm. Basically, the UML allows developers to view the products of their work on pattern charts.It was adopted by the OMG as a modelling pattern. An UML model can be independent from, and specific to a platform, and in both cases the MDA development process can use the model[12].
2.2.1. UML Extension Mechanisms
- Extension mechanisms of a UML allow it to be extended and customized by adding modelling elements, properties, and semantic. This way it becomes more suitable for domain of a specific problem. There are three extended mechanisms used and defined in an UML: stereotypes, tagged values and constraints[5].According to[3] the stereotype extends the UML vocabulary, allowing the construction of a new modelling element derived from an existing element but that does not fit into the problem to be solved. The tagged value extends the properties of a modelling element, allowing the creation of new information that specifies the element at hand. And the constraint extends the semantics of the UML, allowing the inclusion of new rules and the tweaking of existing ones. In the experiment reported in this article stereotypes and tagged values were developed to meet the proposal for implementation discussed in Section 3.
2.3. OLTP & DW
- With the evolution of Information Technology and the growing use of computers, practically all medium and large businesses are using computerized systems to control their activities. Information collected daily, which is essential for the work of company management, may represent an overwhelming volume of data to analyse. Through this, a merge takes place of the need to obtain forms of manipulation, aggregation, processing and/or organization of information that enables the analysis of information for decision-making. IT areas, apart from developing systems to support and aid operating decisions (daily basis), also began to develop systems to support and aid management decisions. These systems are known as DSS (Decision Support System). There are significant differences between these two types of systems. Systems to support the operational user are also known as OLTP, being characterized for their detailed information; being transaction-oriented, they carry out real-time data modification, ensuring high availability, with significant concern on performance, and organized according to the functions or activities of the business. As DSS systems have very different characteristics from their predecessor, are organized by subject, contents, and are supported by historical information, their data is grouped or summarized and does not need to be updated in real-time; data structures are simplified to facilitate the analytical activities, and its availability is not predominant.For data storage with goals and features so different from those in use by transactional systems a need was also found to create storage areas (databases) compatible with these goals. Thus, the known transactional database (OLTP environment characteristic) was added to the database data warehouse (DSS specific environments). According to[6], data warehouse is a collection of data oriented by subject, integrated, time varying, and non-volatile, which aims at supporting decision-making processes. Considering the concepts presented above, it is possible to reach two preliminary conclusions: the first one is the existence of a need for a specific and different form of data model for this type of database, and the second one is that the data that feeds DW database that comes from OLTP databases. Dimensional modelling has emerged as a solution for data modelling in data warehouse environments.Discipline’s goal is to enable subject oriented data models development. These models are focused on aggregated data and simplified in relation to OLTP environment. This modelling comes from data relation models (developed for OLTP environments) and through successive transformations reaches the dimensional data model (specific for DW environments). This model has not only its own characteristics, but also a specific nomenclature and differs from the original model.Basic elements of a dimensional model are fact, dimension and aggregation. According to[7], dimensional model presents a much simpler structure where a central table, the fact table, is linked to various dimension tables, making the model easier to understand. Aggregation is a summary built from individual facts and aims at the access performance.Proposal development of this work begins exactly with the differences between these environments and the connection needed between them. Considering that the data from OLTP databases is exactly that which feeds the DW databases, it is expected that the information exchange between the two databases will be trivial. However, the simplification of the DW data model and the aggregation of information (from which the ‘dimensional’ expression comes) force the achievement of additional extraction and charge tasks.Metadata is one of the most important aspects of Data Warehouse[4]. There are two basic architectures for data warehouse: distributed and federated. In the distributed architecture, metadata are replicated in each distribution site, while in federated architecture, each site has its own metadata repository. In face of impossibility of a single metadata repository to implement a metamodel for organization, it is necessary to create a standard for metadata exchange between different repositories. This process is named ETL and sometimes it can become quite complex, due to many transformation tasks needed to conversion model.The proposal for this work considered two main aspects in its development: the nomenclature feature from a DW environment, and the extracting and loading task. In the case of DW, the nomenclature used to identify a dimensional entity uses the words ‘Fact’ and ‘Dimension’, whereas in an OLTP environment it uses only the word ‘entity’. Thus, it was understood that the classification should be maintained to ensure the understanding and adherence to the environment.The extraction and load task is basically achieved in two ways: through programs (often written in the database procedural language) or through sophisticated software found in the market that requires the development of specific models to accomplish this task. The creation of scripts that execute the extraction tasks (in place of manually made programmes) was the choice adopted, as it was understood that automatic generation could bring gains in development, especially in terms of the number of tables to be implemented.
2.4. CWM
- CWM is a metadata standard designed to enable the integration of data warehouse systems, intelligent e-business and business systems in heterogeneous environments, and distributed through one representation and one format of metadata swap[11]. This standard specifies metamodels for all stages of a Data Warehouse process, including the metamodel for ETL. In this metamodel (more specifically, the transformation package) elements are found that represent classes and associations commonly used for processing data in a data warehouse[14].In this paper a simplified version of this metamodel was used where the data source is a relational base and the changes are recorded only at the destination.
2.5. AndroMDA & Cartridge
- AndroMDA software was used along the development of this experiment to generate the ETL scripts. According to the site of its developers, the AndroMDA is a framework of an extensible code generator that follows the MDA paradigm. The UML models can be transformed into portable components for a given platform. The AndroMDA is extensible through its cartridges having a number of them ready for various platforms such as Struts, JSF, Spring, and Hibernate. You can still customize it, extend it, and create new cartridges, with a construction tool kit - the metacartridge[1]. The models created with the UML tool are exported, generating the XMI models. A set of templates that specify a specific code, called cartridge, is applied to the XMI models, which then generate the source code on the platform specified by the used cartridge.The templates, written in Velocity, define how the cartridge will format generated code. Velocity is a sub-project belonging to the Apache Foundation’s Jakarta Project, which consists of a language template that uses a set of classes in Java not to be handled as a language[2].
3. Works Related
- [17-25] and[26] helped to understand MDA scientific development in ETL environments. From 2009, there were tries to create code through UML models –[21] in 2009 and[23] in 2010. The other works focus process ETL, data merge to different models and multidimensional modelling.[21] and[23] show an integration with a market tool. This tool is, effectively, responsible for code generation from UML models. This paper proposes an approach, which there is no dependence on any other tool. In doing so, all code generation is complete and self-sufficient.All in all, this paper is consistent with other studies, although it has a differentiated approach: independence of market tools and unique use of UML notation – it is commonly used in the development of class models.
4. Methodology
- According to the applications architecture, generated by AndroMDA, three code layers are constructed: for presentation, for business, and for data access. The development of this work took place in the data access layer, which contains all the features of persistence and interface with the database using the Hibernate. Hibernate cartridge supplies all classes required during the development of an application using AndroMDA. The application developed can be aimed at data access (including actions for adding, modifying, and deleting in the database) or at the transformation between the database tables (in objects), and the business layer. Hibernate is responsible for transforming the rows of a relational table into objects that represent the entities for the business layer (called ‘business entities’) for the occurrence of propagation of data between the layers. Thus, it was concluded that the adjustment of this cartridge would be the most efficient way to achieve the goal of this work: the loading of data onto the DW base, containing all the information from the relational database (OLTP) through the basic extraction and load tasks. According to the conceptualization presented for dimensional models, the existence of its own nomenclature for identifying the entities in the DW database (Facts and Dimensions) was found. For this nomenclature to be maintained and, at once, not lose the concept of entity already supported by the Hibernate cartridge, the metafacades of Hibernate entities were used. The metafacades were associated to stereotypes developed especially for the extracting and loading tasks. These stereotypes are named Fact and Dimension.The methodology employed in the development used the marking of classes of persistence in the DW model with information that would allow the linking of the target DW class with the origin OLTP class. The first task was carried out to create the Fact and Dimension stereotypes to be associated respectively to the classes that represented the facts and dimensions of a DW model. Each entity type has specific characteristics; therefore the stereotypes received tagged values that could establish these characteristics, as shown below.
 | Figure 1. Sale class with the < |
4.1. Stereotype Fact
- This stereotype should be associated to the persistent class that corresponds to a table ‘fact’ in the model of the destination DW class. Figure 1 shows the association of the <
 | Figure 2. Product class with the < |
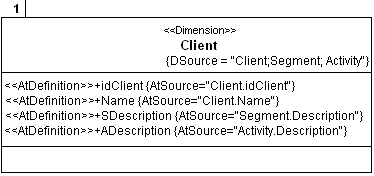 | Figure 3. Client class with the |
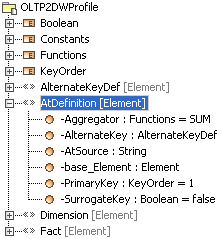
4.2. Stereotype AtDefinition
- This stereotype was designed to be applied to the attributes of persistent classes that use Fact and/or Dimension stereotypes (see Figures 1 and 2). Figure 3 shows association between stereotype <
 | Figure 4. Relationship between stereotypes and enumerators. |
4.3. Enumerators
- Apart from the stereotypes designed for the combination of persistent classes and attributes, lists were also created, with values to guarantee the fulfilment of tagged values. These lists, called enumerators, are shown below for more clarity in understanding the experiment:Functions – This enumerator contains the list of valid functions (predicted) to be used on a tagged value ‘aggregator’.Boolean – This enumerator contains boolean values indicating the completion of the tagged value SurrogateKey.KeyOrders – This enumerator contains the list of valid values for completing the tagged value PK, to indicate the order of attributes in the primary key of the entity.
4.4. Other implementations
- Several modifications were carried out, aiming at the full implementation of this experiment, in AndroMDA configuration files, that will be only briefly mentioned, as this aspect is not the focus of this article. The Cartridge.xml file had modifications made to the macrolibrary, property, and template elements. Macrolibrary was modified on the indication of the macros developed in the Velocity Template Language (VTL) language, used to write scripts. The property has been modified to include two new properties in the Hibernate cartridge. The template was modified to specify the speed files are executed in for each one of the stereotypes found in the UML model.Figure 5 shows the modelElements component that associates a stereotype to be a corresponding element in the UML model.
 | Figure 5. Piece of cartridge.xml file with a template tag and the stereotypes < |
5. Results
- The development of this work considered the script generation as oriented to a single database in order to validate the use of the methodology and practicality of the result. With it, the database spec chosen was the Oracle database and the language to generate the scripts was Oracle PL/SQL.The results obtained with the creation of the cartridge through the methodology and characteristics listed above were: First of all, the cartridge allows the generation of an SQL script containing the commands needed to create a DW database. This script is a consequence of the information described in the model. This model contains the Fact and Dimension stereotypes, which are used to define the tables to be generated. The attributes associated to the entities, with these specific stereotypes, were adapted to generate types of data recognizable to the Oracle DataBase Management System. This script gets the name of ‘schema.sql’.The second result from the execution of the cartridge is the generation of a script to load data in the DW base. This Oracle PL/SQL script gets information from the OLTP databases executes the process to extract data and then records this information in the corresponding tables on the DW base. This information is contained in the model through the references contained in the tagged values, as reported in Section 3 of this article. The resulting script gets the name of ‘model.sql’. The implementation provided in the Hibernate cartridge did not interfere in their preview activities, as the association of new stereotypes to the pre-existing ‘Entity’ stereotype. Thus, all the persistence classes generated by Hibernate in each entity of the UML model referenced to the stereotype ‘Entity’ stereotype are also generated by the marked entities with the ‘Fact’ or ‘Dimension’ stereotypes.
6. Result Analysis
- The first studies designed to assess the cartridge, as reported in the article, were to evaluate the technical feasibility of automatically generating, through the MDA approach, the scripts required to load data onto a data warehouse database.Tests were conducted with different conceptual models aimed at understanding the limits reached by the approach. It was observed that, for simple models, where there was no need for data transformation, the approach developed fully met the needs, bringing direct benefits such as:Changes (not structural) on the OLTP model were automatically corrected in the script load generated, with no need for manual intervention;Simplicity in marking the connection between the OLTP data model and the DW;Possibility of generating specific scripts for the database, using the potential of the language chosen for development (e.g., Oracle PL/SQL);In the case of more complex models, however, where the data needed to be processed and consolidated before being transferred to the data warehouse, the approach lacked supplementing. Thus, a second study is being carried out aimed at establishing a model (model extension to CWM), which may be attached to this initial approach, establishing an intermediate processing stage between the OLTP data model and the DW data model.
7. Conclusions
- With an ever-growing market, which becomes more dynamic on a daily basis, organizations need information that supports decisions to ensure its operating functionality and tactics. To make that possible, companies are increasingly investing in DSS. However, according to[16], technology investments are the efforts that use up the budget of modern organizations. Furthermore, DSS requires considerable time for implementation. The cartridge presented in this paper adds value to the organization as, with each change in the requirement as demanded by managers, the model can be automatically changed. Script generation that is quickly done, due to the integration between the OLTP and DW models. Besides that, it is possible to avoid manual rework through process ETL automatization. So, one can obtain an increase in performance and productivity, and a reduction in the costs to adapt to meet the changes, producing competitiveness for the organization. For future work, we intend to work on the evolution of the cartridge, in the way the scripts to create and load on the database are being created for other DBMSs, to see the model fully independent from the platform. Other developments would be the creation of constraints and the extent of the CWM metalanguage.