-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Computer Science and Engineering
p-ISSN: 2163-1484 e-ISSN: 2163-1492
2011; 1(1): 1-7
doi: 10.5923/j.computer.20110101.01
A Study on the Effect of Codebook and CodeVector Size on Image Retrieval Using Vector Quantization
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLB. Janet , A. V. Reddy
Dept. of CA, National Institute of Technology, Trichirappalli, 620015, India
Correspondence to: B. Janet , Dept. of CA, National Institute of Technology, Trichirappalli, 620015, India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In this paper, we study the effect of codebook size and codevector size using vector quantization (VQ) for retrieval of images, not restricted to the compressed domain. We use the image index model, to study the precision and recall values for different similarity measures. The study presents the following findings. The codebook size and codevector size are directly proportional to the precision value for a locally global codebook, but are dependent on the size of the source image for a local codebook. The Encoding Distortion similarity measure calculated from the local codebook produces the highest precision for the same recall over all other similarity measures. The Histogram Intersection using locally global codebook gives higher precision for higher codebook sizes. It is established that VQ can be used to create a single valued feature to represent the image in the image index model. This feature based on distortion measure can be effectively used for image retrieval based on the experimental results.
Keywords: Image Processing, Image Retrieval, Information Retrieval, Indexing, Vector Quantization
Cite this paper: B. Janet , A. V. Reddy , "A Study on the Effect of Codebook and CodeVector Size on Image Retrieval Using Vector Quantization", Computer Science and Engineering, Vol. 1 No. 1, 2011, pp. 1-7. doi: 10.5923/j.computer.20110101.01.
Article Outline
1. Introduction
- The image capturing devices have increased the number of images that are stored in the digital formats to such an extent that retrieval of the images has become a big problem. Content based retrieval[1] in large image databases has become the need of the hour. To facilitate the retrieval process, an index[2] of the image database is constructed that contains the similarity measure of the image to other images in the database.Many image indexing methods, to enable fast retrieval of images, have been proposed. Keywords[1] which are manually assigned or automatically assigned from tag and title or as annotations are used to index an image. The drawback with keywords is that the manual process is user dependant as different users assign different keywords for the same image. Automatic tagging depends on proper naming convention. If name is not clearly assigned then, it cannot reflect on the content of image. Another method is to assign tags for an image based on the textual content[1] close to it in the document. The text around the image will be closely associated with the content of image. But advertisements and company logos may also be considered to represent the content of the image, in this case.A second, widely researched area is based on feature vectors[1] derived from images. Histograms[3] give thecolor content of the images. Segmentation and Edge detection[1] algorithms are used to trace edges and identify or classify the shape of the images. The above mentioned techniques do not use the spatial content of the image and the storage requirement is large. Vector quantization (VQ)[4] is an efficient technique for low bit rate image compression. It is also an indexing technique where the image is represented as a set of code vectors. VQ represents the image as a codebook that reflects the intensity and spatial content of the image. The code book is a representation of the content of the image. We can use a local codebook[12, 13, 14], a global codebook[5, 6, 7], or a locally global codebook[20, 22] to represent the image. In this paper, we give a brief description of how VQ is applied to create the index structure for images using various similarity measures. The precision and recall graph is analyzed and evaluated for the various codebook sizes and for various codevector sizes, computed for the same image database. The locally global and local codebooks are used for the experiments. The distortion with the codebook or the intersection distance of the histogram is taken as a single feature to represent the image in the image index model.
2. Previous Work
- The past work on CBIR mostly represented the images by feature vectors. Color was the mostly used discriminating feature[8, 9]. Histogram is used to represent the color distribution in an image. To reduce complexity, the color space is first quantized into a fixed number of colors (bins) and images are compared by comparing their color histograms.Examples of schemes for image retrieval based on color histograms are[3, 8, 10]. An analysis of color histograms can be found in[11]. VQ based image classification and retrieval has been proposed in the past. As quantization is performed on image blocks instead of single pixels, some spatial information is implicitly included. Idris and Panchanathan[5] use VQ to index compressed images and video data. VQ is a lossy technique efficiently used for image compression to capture the content of image and maintain an acceptable quality based on the feature base. Images are initially compressed using a global VQ codebook[5, 6], then for each code vector in the codebook, a histogram of image blocks is generated (the number of blocks is taken to be the number of code vectors used in the image). Their results compare favorably to methods based on color histograms. Idris[6] used a global code book to represent a set of compressed images. The histogram of the code vectors of the image is used as an index to measure the similarity of the image to other images. Later in[5], a usage map is computed for the code vectors of a global code book. Similar images were found to have similar usage maps. It reduced the time to process a query as it is a simple XOR operation to find the similarity of an image. With the advent of digital camera, the number of images stored in a database exploded. Then, it was not possible to create a single global codebook for the entire database. Schaefer[12] proposed an algorithm that used local (or individual) codebook for each image. The code book similarity was used as a measure of the Hadusdorff distance[13] and a median Hadusdorff distance and a modified Hadusdorff distance was proposed[13]. In 2005, Daptardar and Storer[14] proposed to find the Encoding distortion distance between the images for local codebooks. Jeong and Gray[15] used minimum distortion image retrieval using Gaussian mixtures. The image with the lowest distortion was the best match. As the size of the database increased, global codebook generation was not possible. So, the local codebook was used. Later, individual codebook for each image was generated to calculate the distortion distance. Now, a locally global codebook[22] is generated using the incremental codebook generation process. This is representative of the global codebook generated already.In this paper, we analyze the precision and recall curve for various codebook sizes generated, and use the similarity measures Hadusdorff distortion, Encoding distortion and Histogram Intersection for finding precision and recall from the image index model[17].
3. Vector Quantization
- Vector Quantization[4] is used to quantize and compress the pixels of an image. An image is blocked into M, K-dimensional source vectors of pixel values. Using the LBG clustering algorithm[4], a codebook is computed as described below. Consider M to be a source vector of the images, D to be a distortion measure, N to be the number of code vectors or the codebook size, and then we can compute the codebook C and a partition space P which result in the smallest average distortion. An image is divided into blocks consisting of M source vectors called the training sequence T = {x1,x2,x3,…,xm}.This training sequence can be obtained from the large image database used for content based retrieval. M is assumed to be sufficiently large, so that all the content of the images are captured by the training sequence. Let the source vector be K-dimensional given as xm = (xm,1,x m,2,x m,3,…,x m,k), where m=1,2,…,M.Let N be the number of codevectors and let C = {c1,c2,c3,…,cn} represent the codebook. Each code vector is K–dimensional, cn = (cn,1,c n,2,c n,3,…,c n,k), n=1,2,…,N.Let Sn be the encoding region associated with code vector Cn and P be the partition of the space, then P = {S1,S2, S3,…,Sn}.If the source vector xm is in the encoding region Sn, then its approximation (denoted by Q (Xm)) is Cn
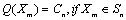 | (1) |
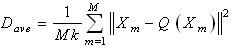 | (2) |
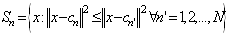 | (3) |
3.1. Similarity Measures
3.1.1. Histogram Intersection (HI)
- We can compute the histogram[15] of an image i for a locally global codebook of the entire image database. It is a N dimensional vector {Hi : i= 1,2,…,N} where Hi is the number of source vectors that fall into the encoding region of a code vector. N is the number of codevectors in the code book. The Euclidean distance[13] is calculated between two image histograms h and g as
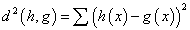 | (4) |
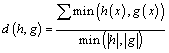 | (5) |
3.1.2. Encoding Distortion (ED)
- Schaefer[13] uses a local codebook for each image as its feature vector. To determine the image similarity based on encoding distortion distance (EDD)[13], codebooks of images are directly compared with the images as
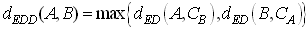 | (6) |
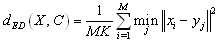 | (7) |
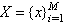 and codevectors
and codevectors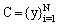 . The ED[21] is used as a measure to determine the similarity of the images.
. The ED[21] is used as a measure to determine the similarity of the images.3.1.3. Hausdorff Distortion (HD)
- Modified Hausdorff Distance[12] compares two local code books to measure their similarity. Let CA and CB be code books for the images A and B. Then Hausdorff Distance is calculated as
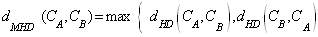 | (8) |
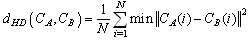 The HD[21] is used as a similarity measure to determine the similarity of the images.
The HD[21] is used as a similarity measure to determine the similarity of the images. 3.1.4. Incremental Codebook Generation
- The codebook for an image can be computed either for each image (local)[12, 13, 14] or one universal or common codebook for the entire set (global)[5, 6, 7] using the LBG VQ algorithm. The technique for finding the codebook which combines both the above mentioned techniques and generates a locally global codebook[22] is shown in figure 1.
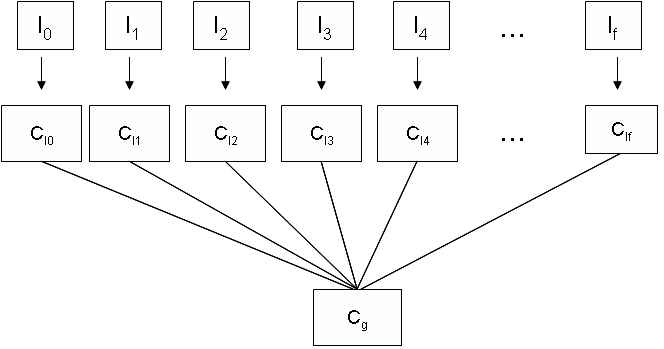 | Figure 1. Incremental Codebook Generation. |
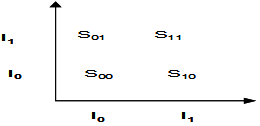 | Figure 2. Image Index Model. |
3.2. Indexing Algorithm
- Step 1: Preprocess We resize the image to 256 x 256 pixels. Then we convert it to 8 bit grayscale image.Step 2: Blocking the image We divide the image into K x K block vectors and store the image block vectors as source vector or Training sequence. For example, if K=4, then for an image, Pi is the pixel value in an image and Xi is the block vector, then T = { X1, X2, X3 …. XM }, where Xi = { Pi1, Pi2, …. PiK}. P1 P2 P3 P4 ----> P1 P2 P5 P6-------> X1P5 P6 P7 P8 ----> P3 P4 P7 P8-------> X2P9 P10 P11 P12 ----> P9 P10 P13 P14-----> X3P13 P14 P15 P16 ----> P11 P12 P15 P16----> X4Step 3: Codebook generationWe apply LBG VQ algorithm to T of each image i, to find the codebook C for each of the image in the database. C = {C1, C2 ,… ,CB} where B is the total number of images and each Ci = {Ci1, Ci2, …,CiS} where S is the codebook size used in the experiments. Cij is the codevector of the codebookThe codebook is generated to be Local, Global and Locally global. The size of the codebook is varied as 8, 16, 32, 64, 256.Step 4: Similarity measure Similarity between two images i and j is calculated using any one of the similarity measures described in section 3. It is stored as an Image Index model as shown in figure 2.
3.3. Retrieval Algorithm
- If the query by example image is in the database, then 1. Retrieve the list of similarity values from the database2. Sort the index list in ascending order3. Top K images are relevant to the query image4. Return the list.If query by example is not present in the database, then1. Repeat steps 1-4 for the image2. Add the image index list to the index3. Sort the list4. Top K images are relevant to the query5. Return the list
3.4. Index Structure
- The code books are stored as a direct index using Terrier 2.1[18] Direct Index structure. Terrier is the Terabyte Retriever version 2.1 developed by - Department of Computing Science, Information Retrieval Group. The open source version of Terrier is written in Java. Terrier was used to provide the direct index for a text database. As image was also considered for processing along with the text, terrier was also used for images to store the features as a direct index structure.Direct index for an image consist of the image identifier and the code book vectors values for that image. The Document Index stores the Image information such as the Image identifier, Image title, path and offset of the Image codebook information in the direct file. The Image index is created by calculating the similarity measure of the image i and j and is stored in the image index as Sij.
4. Experiment and Evaluation
- Terrier 2.1 is modified to implement an image direct and document index in Pentium 4 processor with 3.2 GHz and 1 GB RAM. To test the index, a sample of the database due to Wang, Li, Wiederhold[19] available on the web is used. The database consists of 1000 jpeg images which are either 256*384 or 384x256 with 100 images per class. The classes are symmetrically classified as: Africans, Beach, Architecture, Buses, Dinosaurs (graphic), Elephants, Flowers, Horses, Snow Mountains and Foods. Retrieval effectiveness is evaluated using two standard quantities: precision and recall. For a given query, let a be the number of relevant images that are retrieved, b, the number of irrelevant items, c, the number of relevant items that were not retrievedThen: Precision = fraction of the images retrieved that are relevant. = a/(a+b)Recall = fraction of the relevant images that are retrieved = a/(a+c)IR is said to be more effective if precision values are higher at the same recall values. The average precision is used to evaluate a ranked list. For ranked retrieval, the precision and recall is calculated for each rank. Then the average precision at ranks where relevant images occurred is calculated for a given recall and a precision vs recall graph is plotted. In our experiment, we use various image block size for grayscale images. The codebook size is also varied. Each image is given as a query by example, and the average precision and recall curves calculated for various similarity measures.
4.1. Code Book Size
- We now consider the codevector size of 2x2 which gives a vector length of 4 for each block. Figure 3 shows the ED measure of similarity, Precision Recall (PR) curves which show that there is increase in precision for the same recall, when the code book size is increased. Thus local codebook gives a higher precision when the codebook size is increased when using the ED Measure.
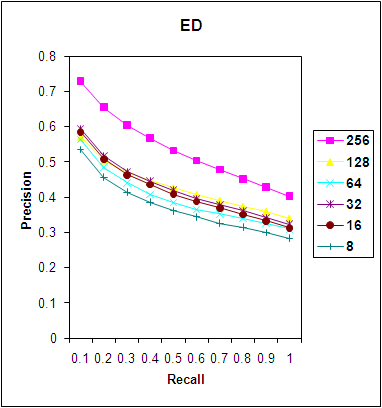 | Figure 3. PR Graph for ED Measure. |
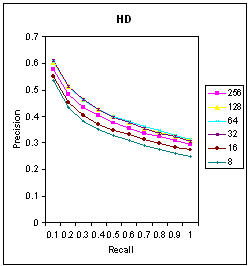 | Figure 4. PR Graph for HD Measure. |
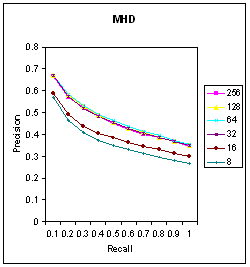 | Figure 5. PR Graph for MHD Measure. |
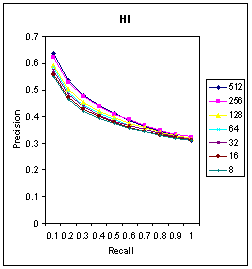 | Figure 6. PR Graph for MHD Measure. |
4.2. Code vector Size and Edge Detection
- We now also consider the code vector size of 2x2 which gives a vector length of 4 for each block. Figure 8 and 9 shows the Precision curve for the HD and HI similarity measure for code vector sizes of 4 and 16. We can conclude that the HD measure and HI measure give similar precision but in HD, a precision of 6.5 is obtained at the codebook size of 64 and in HI, at a codebook size of 256.
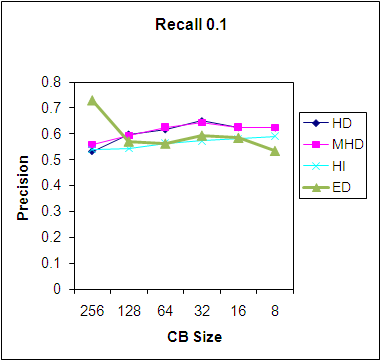 | Figure 7. Precision for various similarity measures. |
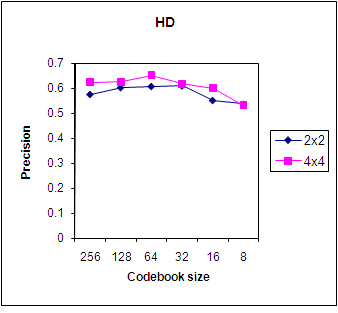 | Figure 8. Preci-sion using HD for various code vector sizes. |
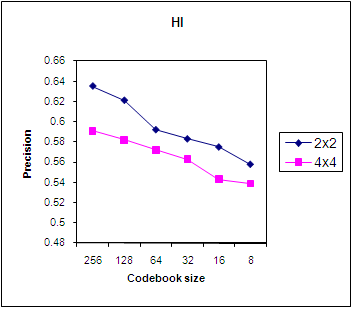 | Figure 9. Precision using HI for various code vector sizes. |
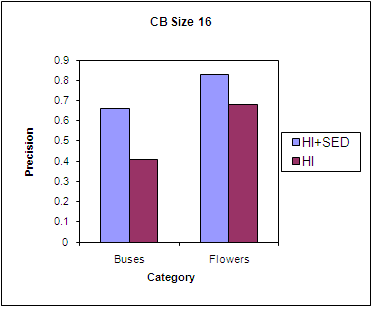 | Figure 10. Precision using HI for two categories. |
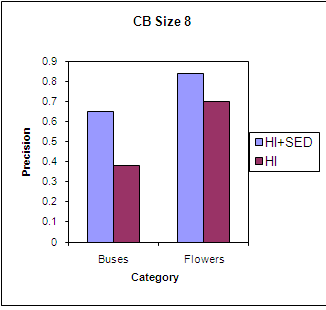 | Figure 11. Precision using HI for two categories. |
5. Conclusions
- The study on the effect of various codebook sizes and the codevector sizes concludes that the codebook size and code vector size are directly proportional to the PR value but are dependent on the size of the sample image for a local codebook. ED can be used if the precision is to be higher and HI if the recall is to be higher. Edge detection algorithm applied in the preprocessing step helps to increase the precision of images with uniform background. The ED gives the highest precision for the same recall values over all similarity measures. HI gives higher precision for larger codebook sizes. Thus, Vector quantization can be used for image retrieval where each image is represented as a single value of distortion measure.