-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Signal Processing
p-ISSN: 2165-9354 e-ISSN: 2165-9362
2015; 5(1): 1-5
doi:10.5923/j.ajsp.20150501.01
Investigation of Classification Using Pitch Features for Children with Autism Spectrum Disorders and Typically Developing Children
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLYasuhiro Kakihara1, Tetsuya Takiguchi1, Yasuo Ariki1, Yasushi Nakai2, Satoshi Takada3
1Graduate School of System Informatics, Kobe University, Kobe, Japan
2Graduate School of Education, University of Miyazaki, Miyazaki, Japan
3Graduate School of Health Sciences, Kobe University, Kobe, Japan
Correspondence to: Tetsuya Takiguchi, Graduate School of System Informatics, Kobe University, Kobe, Japan.
| Email: |  |
Copyright © 2015 Scientific & Academic Publishing. All Rights Reserved.
Recently, autistic spectrum disorders (ASD) have been the focus of much research. Anautistic spectrum disorder is a congenital cerebral dysfunction, and it is a type of developmental disease that causes difficulties incommunication, perceptual, cognitive, and linguistic functions. Since the symptoms of an autistic spectrum disorder are the result of a variety of causes, a fundamental, all-encompassing medical treatment is difficult. However, for an autistic spectrum disorder, early detection and suitable education can have a significant impact on future social prognosis. In this paper, for the purpose of early-age detection of ASD, an investigation of classification using pitch features is carried out for children with autism spectrum disorders and typically developing children, where statistics (percentiles, moment, maximum, minimum, and range) for static and dynamic pitch features are used for classification. Experimental results show 1) that a section division (the head, middle, and tail sections) of an utterance provides a better accuracy, compared with no section divisions of an utterance, and 2) the section that contributed to the classification of ASD was the head section of the utterance.
Keywords: Children with autism spectrum disorders, Pitch features, Intonation
Cite this paper: Yasuhiro Kakihara, Tetsuya Takiguchi, Yasuo Ariki, Yasushi Nakai, Satoshi Takada, Investigation of Classification Using Pitch Features for Children with Autism Spectrum Disorders and Typically Developing Children, American Journal of Signal Processing, Vol. 5 No. 1, 2015, pp. 1-5. doi: 10.5923/j.ajsp.20150501.01.
Article Outline
1. Introduction
- Many speech recognition technologies have been studied for adults to date. Recently, research has been carried out for children, elderly people and people with disabilities [1, 2, 3], and research related toautistic spectrum disorders (ASD) has also been focused on. Anautistic spectrum disorder is a congenital cerebral dysfunction, and it is a type of the developmental disease that causes difficulties incommunication, perceptual, cognitive, and linguistic functions [4-6]. Children with autisticspectrum disorders are diagnosed as having less than normal social interaction and linguistic skills, and have restricted interests and a stereotypical pattern of behavior [7-9]. It is estimated that the rate of autistic disorders, such as Asperger’s syndrome [10] and nonspecific pervasive developmental disorders, is between 1% and 2% of all children [11]. Since the symptoms of an autistic spectrum disorder are the result of a variety of causes, a fundamental, all-encompassing medical treatment is difficult. However, early detection and suitable education can have a significant impact on the future social prognosis of children with such disorders. Recent research has demonstrated that early-stage support, which specializes in autistic spectrum disorders (such as Picture Exchange Communication System [12]), is effective [8]. In the field of acoustic technology, however, there has been little research focused on discriminating between children with autismspectrum disorders and typically developing children.This paper reports the results of classification experiments carried out using pitch features for children with autism spectrum disorders, where statistics (percentiles, moment, maximum, minimum, and range) for static and dynamic pitch features are calculated, and a support vector machine (SVM) is used for classification. Experimental results show that a section division (the head, middle, and tail sections) of an utterance provides a better accuracy, compared with no section divisions of an utterance, and the section that contributed to the classification of ASD was the head section of the utterance.
2. Pitch Features
- Some analyses based on pitch features of ASD have been reported [13, 14], and in this paper, the effectiveness of pitch features is investigated for classification of children with autismspectrum disorder and typically developing children.
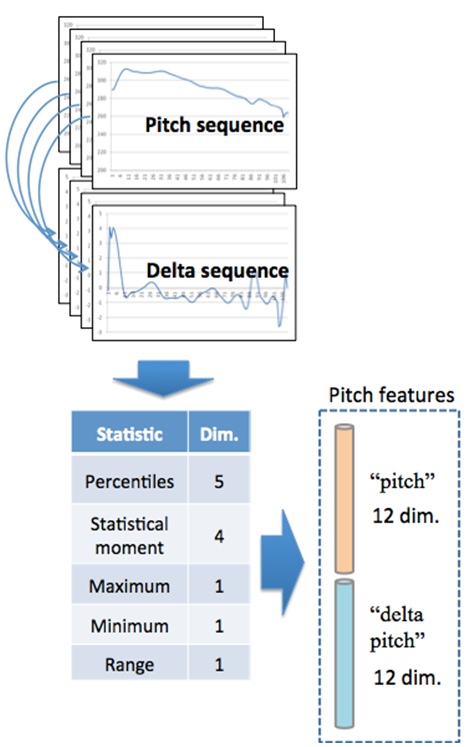 | Figure 1. Pitch features |
 ) pitchas follows:• 25th percentile,
) pitchas follows:• 25th percentile,  25th percentile• 50th percentile,
25th percentile• 50th percentile,  50th percentile• 75th percentile,
50th percentile• 75th percentile,  75th percentile• 25-50 percentile difference,
75th percentile• 25-50 percentile difference,  25-50 percentile difference• 50-75 percentile difference,
25-50 percentile difference• 50-75 percentile difference,  50-75 percentile difference• mean,
50-75 percentile difference• mean,  mean• standard deviation,
mean• standard deviation,  standard deviation• kurtosis,
standard deviation• kurtosis,  kurtosis• skewness,
kurtosis• skewness,  skewness• maximum,
skewness• maximum,  maximum• minimum,
maximum• minimum,  minimum• range (max. – min.),
minimum• range (max. – min.),  rangeThe dynamic feature is calculated using the following regression formula [16]:
rangeThe dynamic feature is calculated using the following regression formula [16]: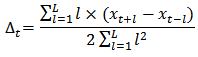 where
where 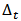 is the delta coefficient at time t calculated in terms of the corresponding static pitch features from
is the delta coefficient at time t calculated in terms of the corresponding static pitch features from 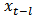 to
to 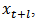
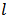 is the parameter related to time (in a delta window size), and
is the parameter related to time (in a delta window size), and 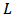 is the delta window size
is the delta window size 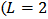 in our experiment).An example of pitch features is shown in Figure 2, where the top figure shows the 50th percentile and the minimum of static pitch and the bottom one shows the mean and the
in our experiment).An example of pitch features is shown in Figure 2, where the top figure shows the 50th percentile and the minimum of static pitch and the bottom one shows the mean and the  25th percentile.
25th percentile.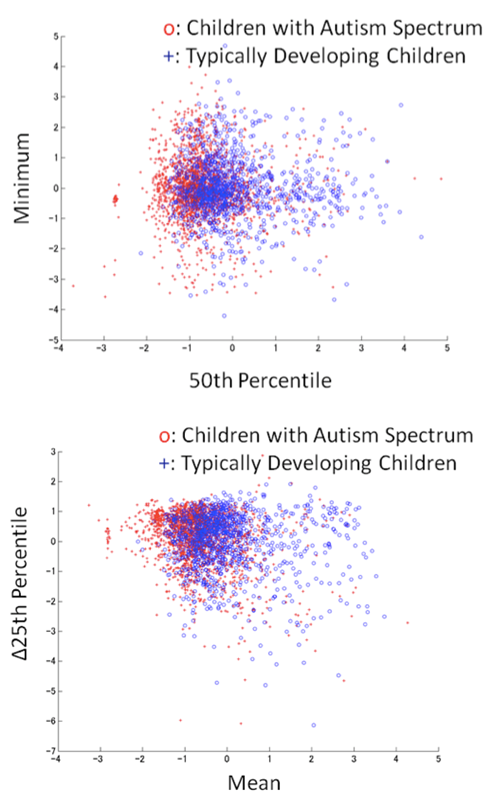 | Figure 2. An example of pitch features |
3. Speech Corpus
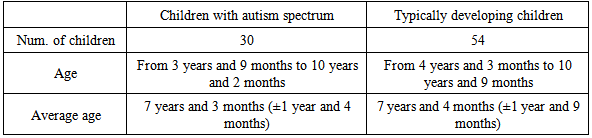
- In our experiments, we recorded the Japanese speech data of children with autismspectrum disorders and typically developing children because there is no common or commercial Japanese speech corpus of children with autism spectrum disorders [13]. The children ranged in age from kindergarteners through the fourth graders. This database consists 30 ASD children and 54 typically developing children. ASD participants were recruited from among the 4-to 9-year-old children who visited the Developmental Behavioral Pediatric Clinic of Kobe University Hospital between April and July, 2010, after approval from the Medical Ethics Committee of Kobe University Graduate School of Medicine was received. Each child uttered 50 kinds of words. Table 1 shows the condition of the Japanese speech corpus of children with autism spectrum disorders.
|
4. Experiments
- Three types of classification experiments were carried out using pitch features.
4.1. Classification Results for Section Division of Utterances
- In this subsection, as shown in Figure 3, an utterance is divided into three sections (the first (head), second (middle), and third (tail) sections), and 24th-dimension pitch features are calculated from each section.
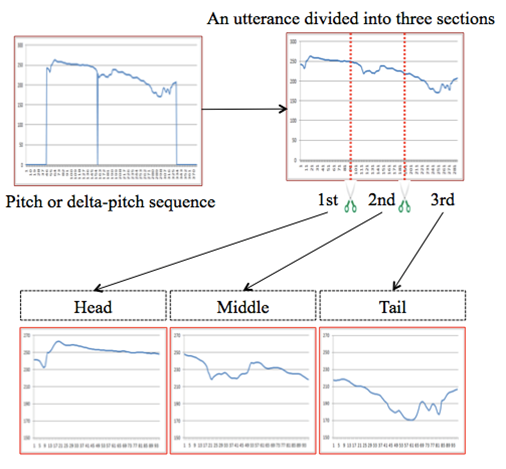 | Figure 3. Pitch interval divided into three sections |
|
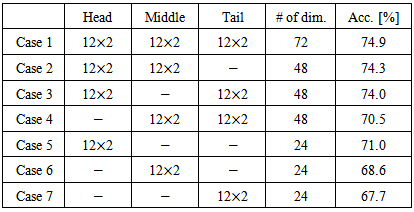
4.2. Classification Results for Each Feature
- In this subsection, each pitch feature is evaluated without section divisions. As shown in Table 3, pitch features are grouped into three categories: percentiles (5-dim. pitch features and their delta features), statistical moments (mean, standard deviation, kurtosis, skewness, and their delta features), and etc. (maximum, minimum, range, and their delta features).
|
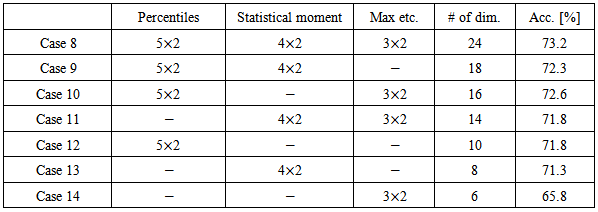
4.3. Classification Results for Each Word
- In this subsection, a SVM is trained for each word, where ten words (/ashi/ (foot), /enpitsu/ (pencil), /inu/ (dog), /kirin/ (giraffe), /megane/ (glasses), /ringo/ (apple), /sakana/ (fish), /semi/ (cicada), /terebi/ (television), /tsukue/ (desk)) are used in this experiment (/Japanese/ (English)). The experiments were carried out based on leave-one-out cross-validation, where a 24th-dimension feature vector is calculated from the pitch and delta pitch sequences for each utterance (without section divisions).Figure 4 shows classification results for each word, where the word is sorted by decreasing accuracy order. The experimental results show that the words that obtained a high accuracy are /enpitsu/, /ashi/ and so on. On the other hand, the words that had a low accuracy are /kirin/, /inu/, and so on. The difference between the highest and lowest accuracies is 9.08%. In the future research, the relationship between the word and its classification accuracy will be investigated in detail.
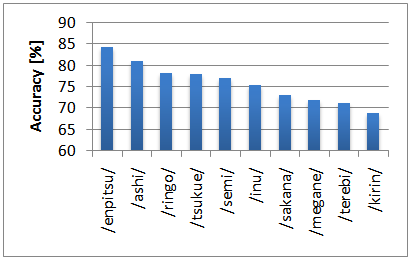 | Figure 4. Classification result for each word |
5. Conclusions
- This paper described, for the purpose of early-age detection of autistic spectrum disorders (ASD), the results of classification experiments using pitch features carried out on children with autism spectrum disorders and typically developing children, from kindergarteners through the fourth graders. In our approach, an utterance is divided into three sections (the first (head), second (middle), and third (tail) sections), and 24th-dimension pitch features are calculated from each section. The experimental results show that the head interval of the utterance greatly contributes to the classification of ASD. This may be due to a strain of the first lip movement when those with ASD begin to say a word. In the future, the relationship between the text content (the word uttered by subjects) and its classification accuracy will be investigated in detail. Also, we will perform experiments that involve increasing the amount of speech data.