-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Signal Processing
p-ISSN: 2165-9354 e-ISSN: 2165-9362
2011; 1(1): 17-23
doi:10.5923/j.ajsp.20110101.04
Exploring the Distributed Video Coding in a Quality Assessment Context
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLA. Banitalebi , H. R. Tohidypour
Digital Multimedia Lab, ECE Dept., University of British Columbia
Correspondence to: A. Banitalebi , Digital Multimedia Lab, ECE Dept., University of British Columbia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In the popular video coding trend, the encoder has the task to exploit both spatial and temporal redundancies present in the video sequence, which is a complex procedure; As a result almost all video encoders have five to ten times more complexity than their decoders. In a video compression process, one of the main tasks at the encoder side is motion estimation which is to extract the temporal correlation between frames. Distributed video coding (DVC) proposed the idea that can lead to low complexity encoders and higher complexity decoders. DVC is a new paradigm in video compression based on the information theoretic ideas of Slepian-Wolf and Wyner-Ziv theorems. Wyner-Ziv coding is naturally robust against transmission errors and can be used for joint source and channel coding. Side Information is one of the key components of the Wyner-Ziv decoder. Better side information generation will result in better functionality of Wyner-Ziv coder. In this paper we proposed a new method that can generate side information with a better quality and thus better compression. We’ve used HVS (human visual system) based image quality metrics as our quality criterion. The motion estimation we’ve used in the decoder is modified due to these metrics such that we could obtain finer side information. The motion compensation is optimized for perceptual quality metrics and leads to better side information generation compared to conventional MSE (mean squared error) or SAD (sum of absolute difference) based motion compensation currently used in the literature. Better motion compensation means better compression.
Keywords: Distributed Video Coding, Structural Similarity, Motion Compensation, Visual Information Fidelity
Cite this paper: A. Banitalebi , H. R. Tohidypour , Exploring the Distributed Video Coding in a Quality Assessment Context, American Journal of Signal Processing, Vol. 1 No. 1, 2011, pp. 17-23. doi: 10.5923/j.ajsp.20110101.04.
Article Outline
1. Introduction
- In recent years, the distributed video coding (DVC) paradigm has been under a lot of attention and the subject of extensive research. The main reason behind this fact is the applicability of this new paradigm in the widely used video uplink applications such as wireless video cameras, video conferencing using mobile devices, low-power surveillance applications, visual sensor networks, multi-view video coding and etc. These new applications require low complexity video encoders due to their intrinsic power constraint. This is in contrast to the classical video coding setting in which much of the complex task of coding is performed at the encoder using high complexity motion estimation algorithms while video can be decoded several times using rather simple decoders used for example in home devices.The first examples of DVC were developed in[3,4]. Although they were developed separately and there are some differences between them, the major trend is the same. Video frames are separated into two groups and each is en-coded using a different method. The first group of frames (main frames) is intra coded using a technology such as H.264/AVC and the second group (Wyner-Ziv frames) is encoded via the Wyner-Ziv[2] and Slepian-Wolf[1] coding paradigms. Main frames are recovered at the decoder before the WZ (Wyner-Ziv) frames and play the role of the so called side information. The Wyner-Ziv coding of video as suggested by[3] and as adopted in this paper, consists of several steps as seen in Figure. 1 the major concern of this paper is the side information generation process, referred to as “HVS-based SI generation”.
 | Figure 1. General DVC structure in transform domain. |
2. Distributed Video Coding Basics
- Distributed source coding originates in the landmark work of Slepian and Wolf[1]. This theory states that the rate needed for separate encoding of two correlated random variables
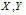 is same as the rate for their joint encoding, with arbitrarily vanishing small probability of decoding error as block size goes to infinity and provided that joint distribution,
is same as the rate for their joint encoding, with arbitrarily vanishing small probability of decoding error as block size goes to infinity and provided that joint distribution, 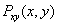 is already known at the encoder and stated formally as in (1)
is already known at the encoder and stated formally as in (1)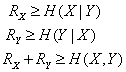 | ……(1) |
 where
where  is a Markov chain and there exists a function such as
is a Markov chain and there exists a function such as  where
where . These works were ignored for a period of almost thirty years and it was not until recently that practical implementations for WZ setting were developed. It is a well-known fact that efficient scalar quantizers and Slepian-Wolf coders can be designed to achieve performances as close to WZ bound as 1.53 dB. It was a brilliant idea to use the WZ coding structure in video coding and the introduction of DVC as done by[3],[4]. Therefore the DVC coding paradigm should use the “quantizer followed by entropy coding” structure of classic video coding but this time specialized for WZ setting. Although the quantizer can be specialized for WZ setting, usually a uniform quantizer is used and the bulk of conditional entropy coding is therefore switched to the Slepian-Wolf code. If work is preferred to be done in the transform domain, DCT transform is usually used before the quantization of data. The quantization indices are Turbo encoded and the parity bits are punctured and sent to the decoder. At the decoder, using various techniques discussed in section V, some side information is generated to be interpreted as a noisy version of the WZ frame transmitted to the decoder. The quantization indices are the result of decoding the side information for the given parity received from the encoder and finally these indices are reconstructed using a predefined reconstruction function. The details as used in the current work are given below.First, the image is divided into
. These works were ignored for a period of almost thirty years and it was not until recently that practical implementations for WZ setting were developed. It is a well-known fact that efficient scalar quantizers and Slepian-Wolf coders can be designed to achieve performances as close to WZ bound as 1.53 dB. It was a brilliant idea to use the WZ coding structure in video coding and the introduction of DVC as done by[3],[4]. Therefore the DVC coding paradigm should use the “quantizer followed by entropy coding” structure of classic video coding but this time specialized for WZ setting. Although the quantizer can be specialized for WZ setting, usually a uniform quantizer is used and the bulk of conditional entropy coding is therefore switched to the Slepian-Wolf code. If work is preferred to be done in the transform domain, DCT transform is usually used before the quantization of data. The quantization indices are Turbo encoded and the parity bits are punctured and sent to the decoder. At the decoder, using various techniques discussed in section V, some side information is generated to be interpreted as a noisy version of the WZ frame transmitted to the decoder. The quantization indices are the result of decoding the side information for the given parity received from the encoder and finally these indices are reconstructed using a predefined reconstruction function. The details as used in the current work are given below.First, the image is divided into  blocks where usually
blocks where usually . A 2D DCT transform is applied to each block and the DCT bands are separated. For each band, the coefficients of the DCT transform are fed to a uniform quantizer. The quantization indices are then extracted to their bit-planes and each bit-plane is given to the Turbo encoder successively from the highest to the lowest bit plane. The turbo encoder which plays the role of the Slepian-Wolf encoder generates the essential parity bits and sends them to the decoder. At the receiver, the Turbo decoder treats the side information as a noisy version of the original WZ bits and using the received parity bits recovers the encoded bit stream. In case of a decoding failure after pre-defined number of iterations, the decoder asks the encoder, through the feedback channel for more parity bits. The initial rate can be set to a minimum rate predefined by several methods such as offline training process or performing some simple side information estimation at the encoder which is not the object of this paper. This procedure is repeated until the bit stream is decoded successfully or a maximum number of retransmissions are reached. The decoded bit stream is then fed to the reconstruction function and reconstruction points, which correspond to pixel values, are then declared. After a WZ frame
. A 2D DCT transform is applied to each block and the DCT bands are separated. For each band, the coefficients of the DCT transform are fed to a uniform quantizer. The quantization indices are then extracted to their bit-planes and each bit-plane is given to the Turbo encoder successively from the highest to the lowest bit plane. The turbo encoder which plays the role of the Slepian-Wolf encoder generates the essential parity bits and sends them to the decoder. At the receiver, the Turbo decoder treats the side information as a noisy version of the original WZ bits and using the received parity bits recovers the encoded bit stream. In case of a decoding failure after pre-defined number of iterations, the decoder asks the encoder, through the feedback channel for more parity bits. The initial rate can be set to a minimum rate predefined by several methods such as offline training process or performing some simple side information estimation at the encoder which is not the object of this paper. This procedure is repeated until the bit stream is decoded successfully or a maximum number of retransmissions are reached. The decoded bit stream is then fed to the reconstruction function and reconstruction points, which correspond to pixel values, are then declared. After a WZ frame 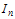 is fully decoded, it is mixed with previous and next frames, namely
is fully decoded, it is mixed with previous and next frames, namely  to preserve the order of frames.
to preserve the order of frames. 3. Perceptual Quality Metrics
- Due to its simplicity, MSE (mean square error) has been the dominant quantitative performance metric in the field of signal processing for many years. But it is shown that there is a big lack of accuracy in MSE when dealing with perceptually important signals such as speech, images and video signals. For those applications newly developed perceptual quality metrics are used.The MSE and PSNR between two 8-bit image signals x and y are defined as:
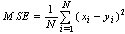 | (2) |
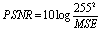 | (3) |
 | (4) |
 | (5) |
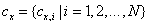 and
and 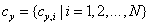 are respectively two sets of wavelet coefficients from the same spatial location in the same wavelet subbands of the two images being compared. K is a small positive constant used for stabilizing.
are respectively two sets of wavelet coefficients from the same spatial location in the same wavelet subbands of the two images being compared. K is a small positive constant used for stabilizing. 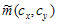 Is the SSIM index applied to the magnitude of the coefficients and
Is the SSIM index applied to the magnitude of the coefficients and  is calculated by monitoring the difference between phases of
is calculated by monitoring the difference between phases of 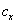 &
&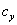 . First, CW-SSIM is calculated for each subband of the wavelet decomposition and then average of these values yields an overall CW-SSIM metric for the entire image. More details are available in[21].VIF quantifies the similarity of two images using a communication framework. It attempts to relate the signal fidelity to the amount of the information that is shared between the two signals, namely the original and the noisy or distorted version. This shared information is quantified using the concept of mutual information which is widely used in information theory. Suppose that we are to compare the quality of two signals such as two images, where one is a reference signal and the other is a noisy version. In the current motion estimation application, one signal is a block of pixels from reference frame and second is a block of pixels from next frame. Let us denote the reference signal by C and the distorted one by D. E is the perceived version of the source signal C by the neurons of the HVS or the Human Visual System and F is perceived version of D. We can write the following equations[18]:
. First, CW-SSIM is calculated for each subband of the wavelet decomposition and then average of these values yields an overall CW-SSIM metric for the entire image. More details are available in[21].VIF quantifies the similarity of two images using a communication framework. It attempts to relate the signal fidelity to the amount of the information that is shared between the two signals, namely the original and the noisy or distorted version. This shared information is quantified using the concept of mutual information which is widely used in information theory. Suppose that we are to compare the quality of two signals such as two images, where one is a reference signal and the other is a noisy version. In the current motion estimation application, one signal is a block of pixels from reference frame and second is a block of pixels from next frame. Let us denote the reference signal by C and the distorted one by D. E is the perceived version of the source signal C by the neurons of the HVS or the Human Visual System and F is perceived version of D. We can write the following equations[18]: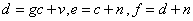 | (6) |
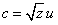 where u is a zero-mean Gaussian vector and
where u is a zero-mean Gaussian vector and 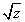 is an independent scalar random variable. According to[18] the VIF is computed by[18]:
is an independent scalar random variable. According to[18] the VIF is computed by[18]: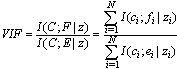 | (7) |
4. Data
- The video frames we used in the simulations are taken from famous “Foreman” and video sequence that was obtained from[27]. The formats of the frames are standard QCIF with 15 HZ frame rate. Figure. 2 show some sample frames used in the simulation. The top frames are frames
 respectively which are intra coded by the H264/AVC encoder. The bottom left frame is the WZ frame which is compressed by the Turbo encoder and finally the bottom right frame is the side information which is generated by the proposed method of this paper.
respectively which are intra coded by the H264/AVC encoder. The bottom left frame is the WZ frame which is compressed by the Turbo encoder and finally the bottom right frame is the side information which is generated by the proposed method of this paper. | Figure 2. Frame In-1 (Top Left), Frame In+1 (Top Right), Original WZ Frame or Frame In (Bottom Left) and Generated Side Information Frame using our method (Bottom Right). |
5. Method
5.1. Our New Motion Estimation
- We modified the conventional motion estimation method with the usage of SSIM (and also CW-SSIM and VIF) as the similarity criterion for block matching. SSIM works with the image structures and thus has better performance than MSE in block matching[28]. Simple full-search block based motion estimation is applied but each time the quality criterion for the computation of the similarity between reference block and target block is changed. Five metrics have been used to see the trade-offs using each of them. Search range is a block with side equal to three times bigger than the side of the original block. As we know, motion estimation is an important part of video coding. Computational complexity of the coding strongly depends on the algorithm used for motion estimation. It seems that (and simulation results confirm this fact) applying SSIM instead of MSE increases the complexity but improves the performance. There is a trade-off in selecting the similarity criterion in block matching. As we can see in results section, VIF shows the best performance but has the most complexity. CW-SSIM is better than SSIM in performance and worse in computational cost. It is again worthwhile mentioning that the complexity is not a major issue in this setting. It is assumed that the decoder has enough resources including computational power and speed to perform the decoding procedure. The main job in the DVC setting is to keep the complexity of the encoder as low as possible while keeping a relatively acceptable video quality.
5.2. SI Generation at the Decoder
- A frame interpolation algorithm is used at the decoder side to predict the side information for DVC. Consider three frames numbered
 . It is desired to obtain an estimate of frame
. It is desired to obtain an estimate of frame  from the known information namely decoded version of intra frames
from the known information namely decoded version of intra frames 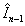 and
and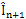 First, we employ forward motion estimation between frame
First, we employ forward motion estimation between frame and frame
and frame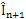 The output of this step is motion vectors for each block. A simple idea to generate SI data is to halve the motion vector for each block of the image, and then move that block from frame
The output of this step is motion vectors for each block. A simple idea to generate SI data is to halve the motion vector for each block of the image, and then move that block from frame  by this half motion vector. Another idea is to construct the frame
by this half motion vector. Another idea is to construct the frame  by subtracting the coordinate points of the corresponding block in the
by subtracting the coordinate points of the corresponding block in the 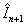 frame by the half of the motion vector. Fig. 3 demonstrates these ideas. We used the combination of these two ideas i.e. frame
frame by the half of the motion vector. Fig. 3 demonstrates these ideas. We used the combination of these two ideas i.e. frame  is built by averaging a block obtained by adding the half motion vector to the reference block of frame
is built by averaging a block obtained by adding the half motion vector to the reference block of frame 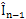 and block obtained by subtracting the half motion vector form the reference block of frame
and block obtained by subtracting the half motion vector form the reference block of frame 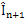 , so this is bi-directional motion compensation. If we show it symbolically, we can write:
, so this is bi-directional motion compensation. If we show it symbolically, we can write: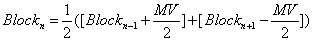 | (8) |
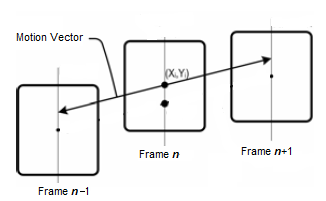 | Figure 3. Demonstration of the interpolation process. |
6. Simulations and Results
- In this section we present the simulation results for the test sequence of “Foreman”. The “Foreman” sequence consisted of 300 frames of sizeĠ. The channel between the encoder and decoder was assumed to be error-free. Each sequence was first decomposed to two groups of frames. The odd frames were intra coded using a conventional H264 encoder and the even frames were Turbo encoded and their parity bits sent to the decoder. The base Turbo encoder consisted of two convolutional encoders with the constituent encoders having the generating polynomials as
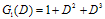 and
and and each having a feedback polynomial of
and each having a feedback polynomial of  . The interleaver size was set to 1024f and the maximum iteration number for the APP decoders was set to 15.First of all, to show the superiority of the motion estimation and side information generation process as proposed in this paper to the other currently available DVC structures, a method of comparison has been introduced in terms of bits needed for compression of the WZ frame. The comparison was performed in the pixel domain for simplicity. The frames were decomposed to their 8 bit planes each. It was assumed that no distortion other than the original quantization to 128 levels by the camera was allowed, meaning that practically Wyner-Ziv coding was reduced to Slepian-Wolf coding and no secondary quantization was allowed. The odd frames were thus encoded at rate
. The interleaver size was set to 1024f and the maximum iteration number for the APP decoders was set to 15.First of all, to show the superiority of the motion estimation and side information generation process as proposed in this paper to the other currently available DVC structures, a method of comparison has been introduced in terms of bits needed for compression of the WZ frame. The comparison was performed in the pixel domain for simplicity. The frames were decomposed to their 8 bit planes each. It was assumed that no distortion other than the original quantization to 128 levels by the camera was allowed, meaning that practically Wyner-Ziv coding was reduced to Slepian-Wolf coding and no secondary quantization was allowed. The odd frames were thus encoded at rate 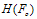 and the even frames were encoded at rate
and the even frames were encoded at rate  and
and 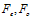 being even and odd frames bit planes respectively. As
being even and odd frames bit planes respectively. As 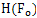 will be the same for all tested methods, we only compared
will be the same for all tested methods, we only compared  , meaning that the conditional rate of WZ frames - given that the base frames are entropy coded and are available without any further distortion at the decoder- was set as a comparison criterion. The results are given for five different methods. Each method has its own distortion measure utilized for motion compensation. Quality metrics that we used are: SAD, MSE, SSIM, CW-SSIM and VIF. Block size for motion estimation is N=16 (16×16 macro blocks). Table 1 shows the performance of the side information generation subsection with different distortion measures. The values of Tables 1 are driven from averaging over 20 frames from the video sequence. Each of these 20 averaged values corresponds to the similarity between the real frame and the frame obtained by the compression technique (with its own quality measure). This similarity is stated in various representations such as MSE, SSIM, VIF, bitplane error and
, meaning that the conditional rate of WZ frames - given that the base frames are entropy coded and are available without any further distortion at the decoder- was set as a comparison criterion. The results are given for five different methods. Each method has its own distortion measure utilized for motion compensation. Quality metrics that we used are: SAD, MSE, SSIM, CW-SSIM and VIF. Block size for motion estimation is N=16 (16×16 macro blocks). Table 1 shows the performance of the side information generation subsection with different distortion measures. The values of Tables 1 are driven from averaging over 20 frames from the video sequence. Each of these 20 averaged values corresponds to the similarity between the real frame and the frame obtained by the compression technique (with its own quality measure). This similarity is stated in various representations such as MSE, SSIM, VIF, bitplane error and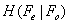 . Average bitplane error is the Hamming distance between the real frame and reconstructed frame, when each of them is considered as a sequence of bits (pixels are 8-bit binary strings and the whole sequence can be built by putting these strings in serial order). We put this parameter (errors of bit planes) to emphasize this point that usage of the HVS based metrics reduces the error in the most significant bit planes and less error in left-sided bit-planes results in better performance in lossy and lossless coding. It is noteworthy that the main parameter of comparison that shows the superiority of one method to another is
. Average bitplane error is the Hamming distance between the real frame and reconstructed frame, when each of them is considered as a sequence of bits (pixels are 8-bit binary strings and the whole sequence can be built by putting these strings in serial order). We put this parameter (errors of bit planes) to emphasize this point that usage of the HVS based metrics reduces the error in the most significant bit planes and less error in left-sided bit-planes results in better performance in lossy and lossless coding. It is noteworthy that the main parameter of comparison that shows the superiority of one method to another is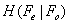 . This parameter shows the conditional rate at which the WZ frames can be encoded. It is certain that in a practical setting using the Turbo codes, this rate might not be achievable exactly and it is the average rate of a limited number of frames from limited number of sequences but the value of the proposed method in this paper will be more appreciated with a closer look at Table 1. It can be seen in Table 1 that an obvious drop in the value of conditional rate happens for the SSIM criterion. CW-SSIM sees also a drop better than SSIM and VIF meets a little bigger drop than both. As Table 1 shows we can see that VIF shows the best performance in compression quality but has the biggest computational complexity. CW-SSIM shows better performance than SSIM but it is more complex than SSIM. Regarding the computational complexity and the coding performance obtained from simulation we can conclude that SSIM can be a knee point. Compression quality is good enough while complexity is not of much concern. But VIF shows the best performance and is valuable when complexity of the decoder is not important at all and some decoding delay can also be tolerated.MSE has a little improvement over SAD but the improvement is around 0.01 bit which is not of practical importance because it might easily change for another set of data sequences. It was also seen in the simulations that usage of very large block sizes (e.g. N=32) does not help much and is practically useless. It is noteworthy that using larger block sizes for SI generation process is different from that of block size used in DCT transform if the code is applied in the transform domain. The DCT size can be chosen
. This parameter shows the conditional rate at which the WZ frames can be encoded. It is certain that in a practical setting using the Turbo codes, this rate might not be achievable exactly and it is the average rate of a limited number of frames from limited number of sequences but the value of the proposed method in this paper will be more appreciated with a closer look at Table 1. It can be seen in Table 1 that an obvious drop in the value of conditional rate happens for the SSIM criterion. CW-SSIM sees also a drop better than SSIM and VIF meets a little bigger drop than both. As Table 1 shows we can see that VIF shows the best performance in compression quality but has the biggest computational complexity. CW-SSIM shows better performance than SSIM but it is more complex than SSIM. Regarding the computational complexity and the coding performance obtained from simulation we can conclude that SSIM can be a knee point. Compression quality is good enough while complexity is not of much concern. But VIF shows the best performance and is valuable when complexity of the decoder is not important at all and some decoding delay can also be tolerated.MSE has a little improvement over SAD but the improvement is around 0.01 bit which is not of practical importance because it might easily change for another set of data sequences. It was also seen in the simulations that usage of very large block sizes (e.g. N=32) does not help much and is practically useless. It is noteworthy that using larger block sizes for SI generation process is different from that of block size used in DCT transform if the code is applied in the transform domain. The DCT size can be chosen 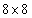 or
or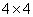 . as in the usual sense and motion estimation in the SI generation process can be done using different block sizes as used in this paper.After showing the theoretical (meaning the usage of
. as in the usual sense and motion estimation in the SI generation process can be done using different block sizes as used in this paper.After showing the theoretical (meaning the usage of 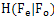 as a measure) superiority of the proposed method in terms of conditional rate and perceptual quality, the practical performance improvement by using this new method also needs to be shown. To compare the various methods, we used SSIM as a quality metric for comparison. The Rate-Quality performance is presented in Figure. 4. Also to better improve the Rate-Quality tradeoff, we used a HVS based DCT quantization table generation method in our design which we borrowed from[29]. Also, only the WZ bits have been counted for more clarity and to comply with the current standards, we used PSNR as a final comparison criterion. These figures confirm the usage of perceptual quality metrics in distributed video coding for side information generation. A gap of almost 1dB improvement is visible in Figure. 4 which can be obtained by using HVS based measures instead of MSE and SAD.
as a measure) superiority of the proposed method in terms of conditional rate and perceptual quality, the practical performance improvement by using this new method also needs to be shown. To compare the various methods, we used SSIM as a quality metric for comparison. The Rate-Quality performance is presented in Figure. 4. Also to better improve the Rate-Quality tradeoff, we used a HVS based DCT quantization table generation method in our design which we borrowed from[29]. Also, only the WZ bits have been counted for more clarity and to comply with the current standards, we used PSNR as a final comparison criterion. These figures confirm the usage of perceptual quality metrics in distributed video coding for side information generation. A gap of almost 1dB improvement is visible in Figure. 4 which can be obtained by using HVS based measures instead of MSE and SAD.
|

7. Conclusions
- In this paper we proposed a new side information generation technique for distributed video coding based on HVS based quality metrics. The new method was compared to other standard distortion measures such as MSE and SAD. It was shown via simulations that the proposed method is superior to current standard methods in the side information generation process and gains up to 1dB can be obtained. The new method has a higher complexity compared to MSE and SAD methods. This complexity can almost be ignored for DVC setting because the decoder is assumed to have abundant resources. For the cases where decoder has limited computational power, a trade-off between this gain and the complexity should be taken into account.