-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Mathematics and Statistics
p-ISSN: 2162-948X e-ISSN: 2162-8475
2016; 6(1): 44-56
doi:10.5923/j.ajms.20160601.05

Amarendra Distribution and Its Applications
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRama Shanker
Department of Statistics, Eritrea Institute of Technology, Asmara, Eritrea
Correspondence to: Rama Shanker , Department of Statistics, Eritrea Institute of Technology, Asmara, Eritrea.
| Email: |  |
Copyright © 2016 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

In this paper a new one parameter continuous distribution named, ‘Amarendra Distribution’ having monotonically increasing hazard rate for modeling lifetime data, has been suggested. Its first four moments about origin and moments about mean have been obtained and expressions for coefficient of variation, skewness and kurtosis have been given. Various other characteristics such as its hazard rate function, mean residual life function, stochastic ordering, mean deviations, Bonferroni and Lorenz curves have been discussed. The condition under which Amarendra distribution is over-dispersed, equi-dispersed, and under-dispersed has been given along with conditions under which Akash, Shanker, Sujatha, Lindley and exponential distributions are over-dispersed, equi-dispersed, and under-dispersed. Estimation of its parameter has been discussed using method of maximum likelihood and the method of moments. The applicability and the goodness of fit of the proposed distribution over one parameter Akash, Shanker, Sujatha, Lindley and exponential distributions have been illustrated with two real lifetime data- sets from medical science and engineering.
Keywords: Lindley distribution, Akash distribution, Shanker distribution, Sujatha distribution, Mathematical and statistical properties, Estimation of parameter, Goodness of fit
Cite this paper: Rama Shanker , Amarendra Distribution and Its Applications, American Journal of Mathematics and Statistics, Vol. 6 No. 1, 2016, pp. 44-56. doi: 10.5923/j.ajms.20160601.05.
Article Outline
1. Introduction
- The analyzing and modeling of lifetime data are crucial in almost all applied sciences including biomedical science, engineering, insurance, finance, amongst others. A number of lifetime distributions for modeling lifetime data such as Akash, Shanker, Sujatha, Lindley, exponential, gamma, lognormal, and Weibull are available in statistical literature. The Akash, Shanker, Sujatha, Lindley, exponential, and Weibull distributions are more popular than the gamma and the lognormal distributions because the survival functions of the gamma and the lognormal distributions cannot be expressed in closed forms and both require numerical integration. Akash, Shanker, Sujatha, Lindley, and exponential distributions consists of one parameter and Akash, Shanker, Sujatha, and Lindley distributions have advantage over exponential distribution that the exponential distribution has constant hazard rate whereas Akash, Shanker, Sujatha, and Lindley distributions have monotonically increasing hazard rate. Further, it has been shown by Shanker (2015 a, 2015 b, 2015 c) that the nature of Akash, Shanker, and Sujatha distributions are more flexible than Lindley and exponential distributions for modeling lifetime data.The probability density function (p.d.f.) and the cumulative distribution function (c.d.f.) of Lindley (1958) distribution are given by
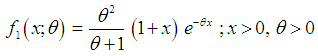 | (1.1) |
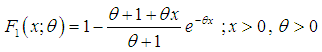 | (1.2) |
 and a gamma distribution having shape parameter 2 and a scale parameter
and a gamma distribution having shape parameter 2 and a scale parameter  with their mixing proportions
with their mixing proportions 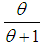 and
and 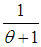 respectively. Ghitany et al (2008) have discussed various properties of this distribution and showed that in many ways (1.1) provides a better model for some applications than the exponential distribution. The Lindley distribution has been modified, extended, generalized suiting their applications in different areas of knowledge by many researchers including Hussain ( 2006), Zakerzadeh and Dolati (2009), Nadarajah et al (2011), Deniz and Ojeda (2011), Bakouch et al (2012), Shanker and Mishra (2013 a, 2013 b), Shanker and Amanuel (2013), Shanker et al (2013), Elbatal et al (2013), Ghitany et al (2013), Merovci (2013), Liyanage and Pararai (2014), Ashour and Eltehiwy (2014), Oluyede and Yang (2014), Singh et al (2014), Sharma et al (2015), Shanker et al (2015 a, 2015 b), Alkarni (2015), Pararai et al (2015), Abouammoh et al (2015) are some among others.The probability density function (p.d.f.) and the cumulative distribution function (c.d.f.) of Akash distribution introduced by Shanker (2015 a) are given by
respectively. Ghitany et al (2008) have discussed various properties of this distribution and showed that in many ways (1.1) provides a better model for some applications than the exponential distribution. The Lindley distribution has been modified, extended, generalized suiting their applications in different areas of knowledge by many researchers including Hussain ( 2006), Zakerzadeh and Dolati (2009), Nadarajah et al (2011), Deniz and Ojeda (2011), Bakouch et al (2012), Shanker and Mishra (2013 a, 2013 b), Shanker and Amanuel (2013), Shanker et al (2013), Elbatal et al (2013), Ghitany et al (2013), Merovci (2013), Liyanage and Pararai (2014), Ashour and Eltehiwy (2014), Oluyede and Yang (2014), Singh et al (2014), Sharma et al (2015), Shanker et al (2015 a, 2015 b), Alkarni (2015), Pararai et al (2015), Abouammoh et al (2015) are some among others.The probability density function (p.d.f.) and the cumulative distribution function (c.d.f.) of Akash distribution introduced by Shanker (2015 a) are given by 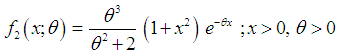 | (1.3) |
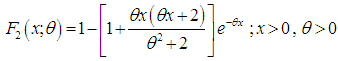 | (1.4) |
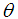 and a gamma distribution having shape parameter 3 and a scale parameter
and a gamma distribution having shape parameter 3 and a scale parameter 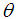 with their mixing proportions
with their mixing proportions 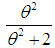 and
and 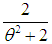 respectively. Shanker (2015 a) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability, some amongst others. Shanker (2016 a) has obtained Poisson mixture of Akash distribution named, Poisson-Akash distribution (PAD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker et al (2015 c) has detailed and critical study about modeling and analyzing lifetime data from various fields of knowledge using one parameter Akash, Lindley and exponential distributions. Further, Shanker (2016 b, 2016 c) has also obtained the size-biased and zero-truncated versions of PAD, derived their important mathematical and statistical properties, and discussed the estimation of parameter and applications for count-data-sets.The probability density function (p.d.f.) and the cumulative distribution function (c.d.f.) of Shanker distribution introduced by Shanker (2015 b) are given by
respectively. Shanker (2015 a) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability, some amongst others. Shanker (2016 a) has obtained Poisson mixture of Akash distribution named, Poisson-Akash distribution (PAD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker et al (2015 c) has detailed and critical study about modeling and analyzing lifetime data from various fields of knowledge using one parameter Akash, Lindley and exponential distributions. Further, Shanker (2016 b, 2016 c) has also obtained the size-biased and zero-truncated versions of PAD, derived their important mathematical and statistical properties, and discussed the estimation of parameter and applications for count-data-sets.The probability density function (p.d.f.) and the cumulative distribution function (c.d.f.) of Shanker distribution introduced by Shanker (2015 b) are given by 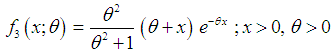 | (1.5) |
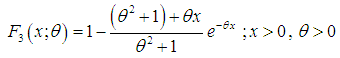 | (1.6) |
 and a gamma distribution having shape parameter 2 and a scale parameter
and a gamma distribution having shape parameter 2 and a scale parameter  with their mixing proportions
with their mixing proportions 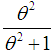 and
and 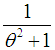 respectively. Shanker (2015 b) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability , some amongst others. Further, Shanker (2016 d) has obtained Poisson mixture of Shanker distribution named Poisson-Shanker distribution (PSD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker and Hagos (2016 a, 2016 b) have obtained the size-biased and zero-truncated versions of Poisson-Shanker distribution (PSD), derived their interesting mathematical and statistical properties, discussed the estimation of parameter and applications for count data-sets from different fields of knowledge.The probability density function (p.d.f.) and cumulative distribution function (c.d.f.) of Sujatha distribution introduced by Shanker (2015 c) are given by
respectively. Shanker (2015 b) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability , some amongst others. Further, Shanker (2016 d) has obtained Poisson mixture of Shanker distribution named Poisson-Shanker distribution (PSD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker and Hagos (2016 a, 2016 b) have obtained the size-biased and zero-truncated versions of Poisson-Shanker distribution (PSD), derived their interesting mathematical and statistical properties, discussed the estimation of parameter and applications for count data-sets from different fields of knowledge.The probability density function (p.d.f.) and cumulative distribution function (c.d.f.) of Sujatha distribution introduced by Shanker (2015 c) are given by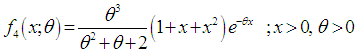 | (1.7) |
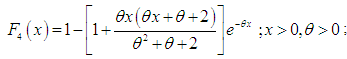 | (1.8) |
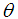 , a gamma distribution having shape parameter 2 and a scale parameter
, a gamma distribution having shape parameter 2 and a scale parameter 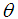 , and a gamma distribution having shape parameter 3 and a scale parameter
, and a gamma distribution having shape parameter 3 and a scale parameter 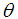 with their mixing proportions
with their mixing proportions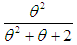 ,
, 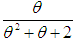 and
and 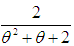 respectively. Shanker (2015 c) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability, some amongst others. Further, Shanker (2016 e) has obtained Poisson mixture of Sujatha distribution named, Poisson-Sujatha distribution (PSD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker and Hagos (2016 c, 2016 d) have obtained the size-biased and zero-truncated versions of Poisson-Sujatha distribution (PSD), derived their interesting mathematical and statistical properties, discussed the estimation of parameter and applications for count data-sets. Shanker and Hagos (2016 e) has also done an extensive study on comparative study of zero-truncated Poisson, Poisson-Lindley and Poisson-Sujatha distribution and shown that in most of the data-sets zero-truncated Poisson-Sujatha distribution gives much closer fit.Although Akash, Shanker, Sujatha, Lindley, and exponential distributions have been used to model various lifetime data from biomedical science and engineering, there are many situations where these distributions may not be suitable from applied and theoretical point of view. Therefore, to obtain a new distribution which is more flexible than the Akash, Shanker, Sujatha, Lindley and exponential distributions, we introduced a distribution by considering a four component mixture of exponential
respectively. Shanker (2015 c) has discussed its various mathematical and statistical properties including its shape, moment generating function, moments, skewness, kurtosis, hazard rate function, mean residual life function, stochastic orderings, mean deviations, distribution of order statistics, Bonferroni and Lorenz curves, Renyi entropy measure, stress-strength reliability, some amongst others. Further, Shanker (2016 e) has obtained Poisson mixture of Sujatha distribution named, Poisson-Sujatha distribution (PSD) and discussed its various mathematical and statistical properties, estimation of its parameter and applications for various count data-sets. Shanker and Hagos (2016 c, 2016 d) have obtained the size-biased and zero-truncated versions of Poisson-Sujatha distribution (PSD), derived their interesting mathematical and statistical properties, discussed the estimation of parameter and applications for count data-sets. Shanker and Hagos (2016 e) has also done an extensive study on comparative study of zero-truncated Poisson, Poisson-Lindley and Poisson-Sujatha distribution and shown that in most of the data-sets zero-truncated Poisson-Sujatha distribution gives much closer fit.Although Akash, Shanker, Sujatha, Lindley, and exponential distributions have been used to model various lifetime data from biomedical science and engineering, there are many situations where these distributions may not be suitable from applied and theoretical point of view. Therefore, to obtain a new distribution which is more flexible than the Akash, Shanker, Sujatha, Lindley and exponential distributions, we introduced a distribution by considering a four component mixture of exponential 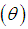 , a gamma
, a gamma 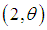 , a gamma
, a gamma 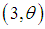 and a gamma
and a gamma  with their mixing proportions
with their mixing proportions  ,
, 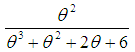 ,
, 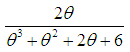 , and
, and 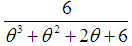 respectively. The probability density function (p.d.f.) of a new one parameter lifetime distribution can be introduced as
respectively. The probability density function (p.d.f.) of a new one parameter lifetime distribution can be introduced as 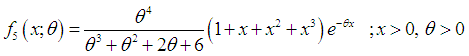 | (1.9) |
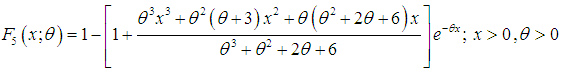 | (1.10) |
 are shown in figures 1 and 2.
are shown in figures 1 and 2.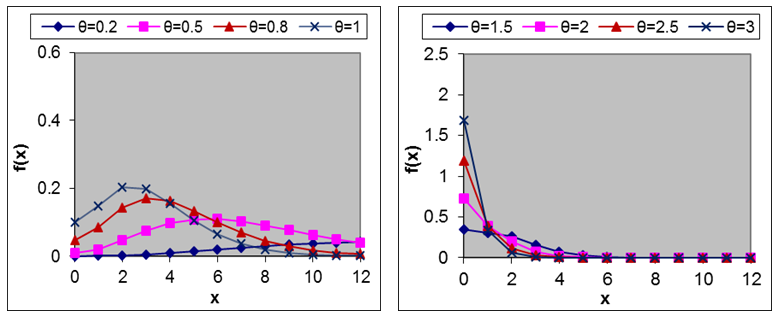 | Figure 1. Graph of the pdf of Amarendra distribution for different values of parameter θ |
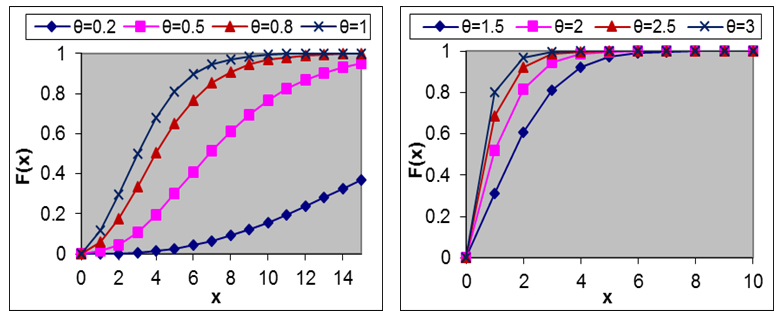 | Figure 2. Graph of the cdf of Amarendra distribution for different values of parameter θ |
2. Moment Generating Function, Moments and Related Measures
- The moment generating function of Amarendra distribution (1.9) can be obtained as
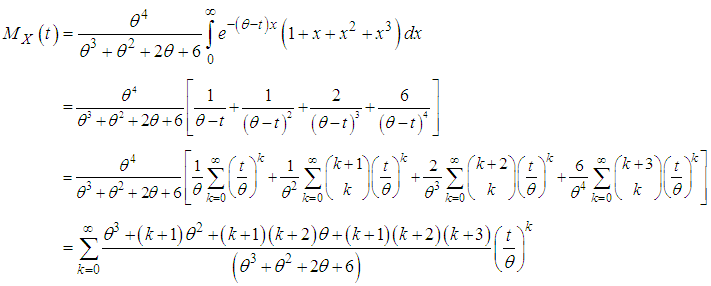 The
The 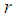 the moment about origin
the moment about origin 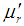 , obtained as the coefficient of
, obtained as the coefficient of 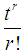 in
in 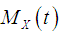 , of Amarendra distributon (1.9) has been obtained as
, of Amarendra distributon (1.9) has been obtained as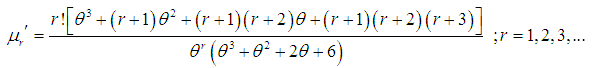 and thus the first four moments about origin are given by
and thus the first four moments about origin are given by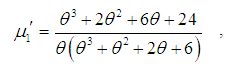
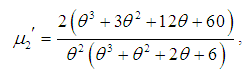
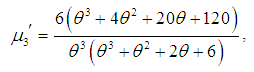
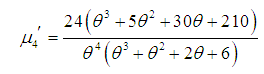 Using the relationship between moments about mean and the moments about origin, the moments about mean of the Amarendra distribution (1.9) are obtained as
Using the relationship between moments about mean and the moments about origin, the moments about mean of the Amarendra distribution (1.9) are obtained as 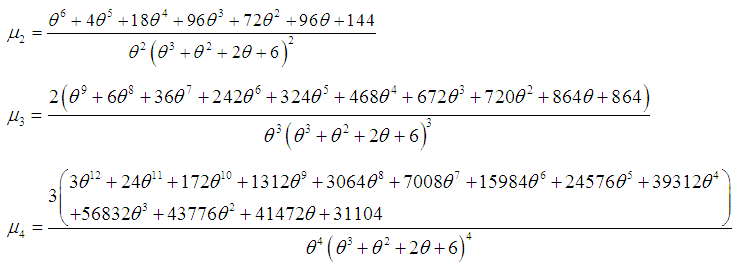 The coefficient of variation
The coefficient of variation 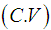 , coefficient of skewness
, coefficient of skewness 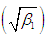 , coefficient of kurtosis
, coefficient of kurtosis 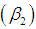 , and index of dispersion
, and index of dispersion 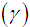 of Amarendra distribution (1.9) are thus obtained as
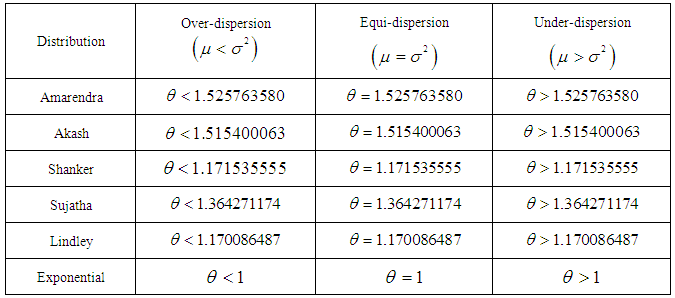
of Amarendra distribution (1.9) are thus obtained as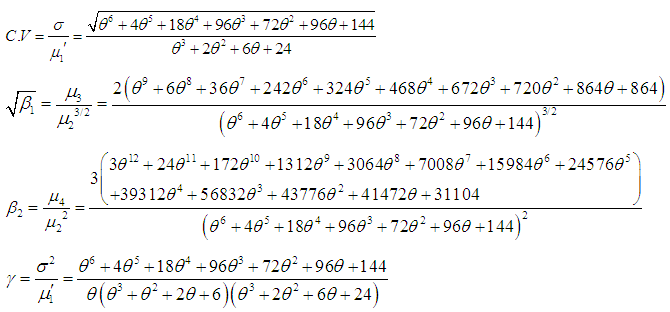 The condition under which Amarendra distribution is over-dispersed, equi-dispersed, and under-dispersed has been given along with conditions under which Akash, Shanker, Sujatha, Lindley and exponential distributions are over-dispersed, equi-dispersed, and under-dispersed in table 1.
The condition under which Amarendra distribution is over-dispersed, equi-dispersed, and under-dispersed has been given along with conditions under which Akash, Shanker, Sujatha, Lindley and exponential distributions are over-dispersed, equi-dispersed, and under-dispersed in table 1.
|
3. Mathematical and Statistical Properties
3.1. Hazard Rate Function and Mean Residual life Function
- Let
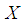 be a continuous random variable with p.d.f.
be a continuous random variable with p.d.f. 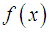 and c.d.f.
and c.d.f. 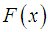 . The hazard rate function (also known as the failure rate function) and the mean residual life function of
. The hazard rate function (also known as the failure rate function) and the mean residual life function of 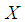 are respectively defined as
are respectively defined as 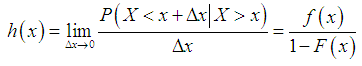 | (3.1.1) |
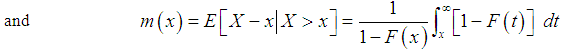 | (3.1.2) |
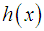 and the mean residual life function,
and the mean residual life function, 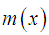 of Amarendra distribution (1.9) are thus given by
of Amarendra distribution (1.9) are thus given by 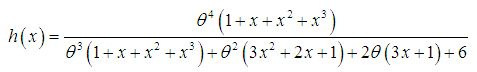 | (3.1.3) |
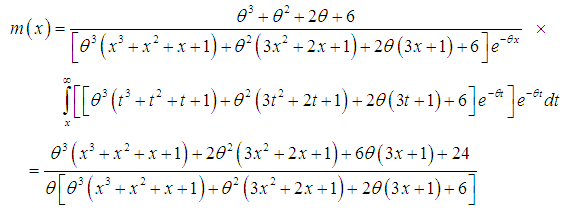 | (3.1.4) |
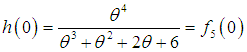 and
and 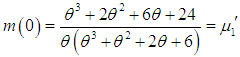 . The graphs of
. The graphs of 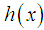 and
and 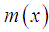 of Amarendra distribution (1.9) for different values of its parameter are shown in figures 3 and 4, respectively.
of Amarendra distribution (1.9) for different values of its parameter are shown in figures 3 and 4, respectively.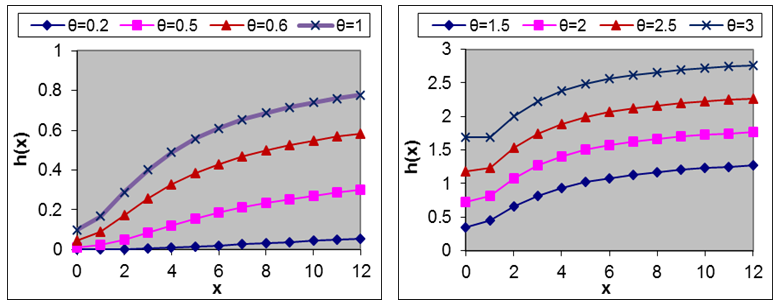 | Figure 3. Graph of hazard rate function of Amarendra distribution for different values of parameter θ |
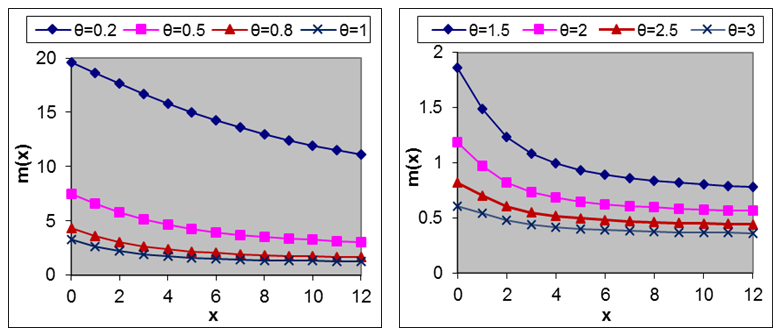 | Figure 4. Graph of mean residual life function of Amarendra distribution for different values of parameter θ |
 and
and  that
that 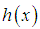 is monotonically increasing function of
is monotonically increasing function of 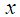 and
and 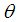 , whereas
, whereas 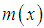 is monotonically decreasing function of
is monotonically decreasing function of  and
and 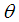 .
. 3.2. Stochastic Orderings
- Stochastic ordering of positive continuous random variables is an important tool for judging the comparative behaviour of continuous distributions. A random variable
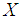 is said to be smaller than a random variable
is said to be smaller than a random variable 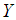 in the (i) stochastic order
in the (i) stochastic order 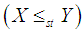 if
if 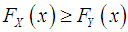 for all
for all  (ii) hazard rate order
(ii) hazard rate order 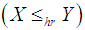 if
if 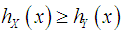 for all
for all 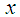 (iii) mean residual life order
(iii) mean residual life order 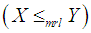 if
if 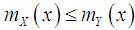 for all
for all 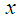 (iv) likelihood ratio order
(iv) likelihood ratio order 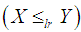 if
if 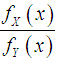 decreases in
decreases in 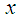 .The following results due to Shaked and Shanthikumar (1994) are well known for establishing stochastic ordering of distributions
.The following results due to Shaked and Shanthikumar (1994) are well known for establishing stochastic ordering of distributions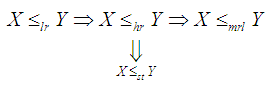 The Amarendra distribution is ordered with respect to the strongest ‘likelihood ratio’ ordering as shown in the following theorem:Theorem: Let
The Amarendra distribution is ordered with respect to the strongest ‘likelihood ratio’ ordering as shown in the following theorem:Theorem: Let  Amarendra distribution
Amarendra distribution 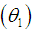 and
and  Amarendra distribution
Amarendra distribution 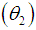 . If
. If 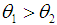 , then
, then 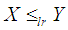 and hence
and hence 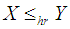 ,
, 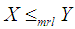 and
and 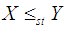 .Proof: We have
.Proof: We have 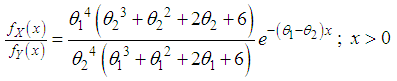 Now
Now 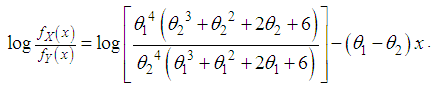 This gives
This gives 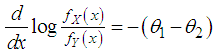 Thus for
Thus for 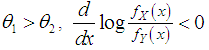 . This means that
. This means that 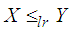 and hence
and hence 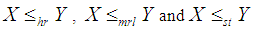 .
.3.3. Mean Deviations
- The amount of scatter in a population is evidently measured to some extent by the totality of deviations from the mean and the median. These are known as the mean deviation about the mean and the mean deviation about the median and are defined by
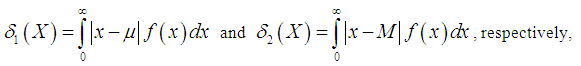
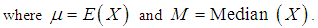 The measures,
The measures, 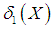 and
and 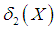 , can be calculated using the following relationships
, can be calculated using the following relationships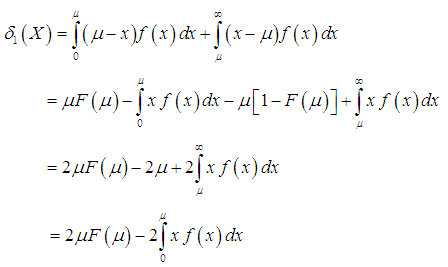 | (3.3.1) |
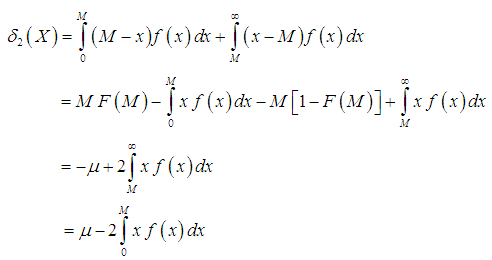 | (3.3.2) |
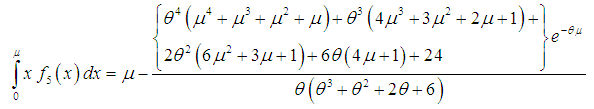 | (3.3.3) |
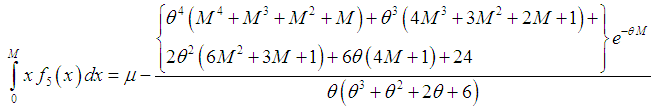 | (3.3.4) |
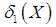 and the mean deviation about median,
and the mean deviation about median, 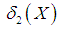 of Amarendra distribution (1.9), after some algebraic simplifications, can be obtained as
of Amarendra distribution (1.9), after some algebraic simplifications, can be obtained as | (3.3.5) |
 | (3.3.6) |
3.4. Bonferroni and Lorenz Curves
- The Bonferroni and Lorenz curves (Bonferroni, 1930) and Bonferroni and Gini indices have applications not only in economics to study income and poverty, but also in other fields like reliability, demography, insurance and medicine. The Bonferroni and Lorenz curves are defined as
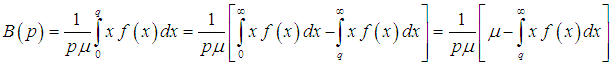 | (3.4.1) |
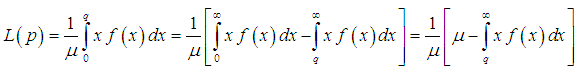 | (3.4.2) |
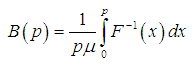 | (3.4.3) |
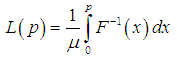 | (3.4.4) |
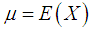 and
and 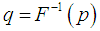 .The Bonferroni and Gini indices are thus defined as
.The Bonferroni and Gini indices are thus defined as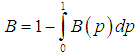 | (3.4.5) |
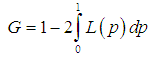 | (3.4.6) |
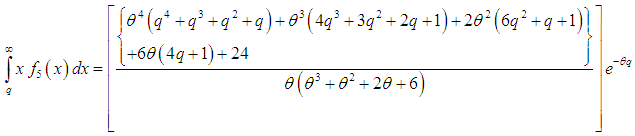 | (3.4.7) |
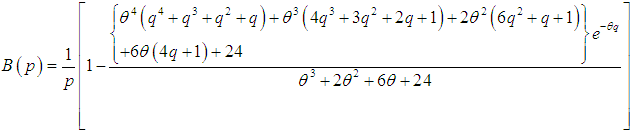 | (3.4.8) |
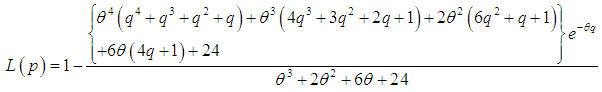 | (3.4.9) |
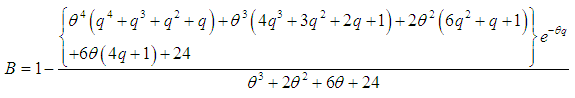 | (3.4.10) |
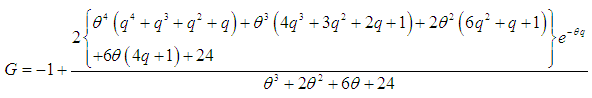 | (3.4.11) |
4. Estimation of the Parameter
4.1. Maximum Likelihood Estimation (MLE) of the Parameter
- Let
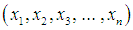 be a random sample of size
be a random sample of size 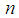 from Amarendra distribution (1.9). The likelihood function,
from Amarendra distribution (1.9). The likelihood function,  of (1.9) is given by
of (1.9) is given by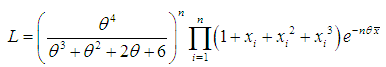 The natural log likelihood function thus obtained as
The natural log likelihood function thus obtained as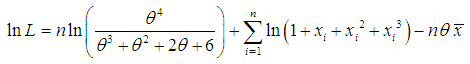 where
where 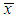 is the sample mean. Now
is the sample mean. Now 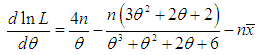 The maximum likelihood estimate,
The maximum likelihood estimate, 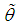 of
of 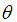 is the solution of the equation
is the solution of the equation 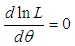 and is given by the solution of the following non linear equation
and is given by the solution of the following non linear equation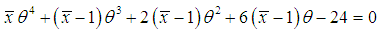 | (4.1.1) |
4.2. Method of Moment Estimation (MOME) of the Parameter
- Let
 be a random sample of size
be a random sample of size 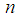 from Amarendra distribution (1.9). Equating the first population moment about origin to the corresponding sample mean
from Amarendra distribution (1.9). Equating the first population moment about origin to the corresponding sample mean 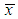 , the method of moment (MOM) estimate
, the method of moment (MOM) estimate 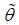 of
of 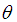 of Amarendra distribution is found as the solution of the same non-linear equation (4.1.1), confirming that the ML estimate and MOM estimate of
of Amarendra distribution is found as the solution of the same non-linear equation (4.1.1), confirming that the ML estimate and MOM estimate of 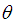 are identical.
are identical. 5. Applications and Goodness of Fit
- A number of data-sets have been fitted using Amarendra distribution to test its goodness of fit over one parameter Akash, Shanker, Sujatha, Lindley and exponential distributions. In this section, we present the fitting of Amarendra distribution to two real data -sets using maximum likelihood estimate and the goodness of fit is compared with the one parameter Akash, Shanker, Sujatha, Lindley and exponential distributions and it is clear from the fitting of these distributions that Amarendra distribution provides better fit for modeling lifetime data.
|
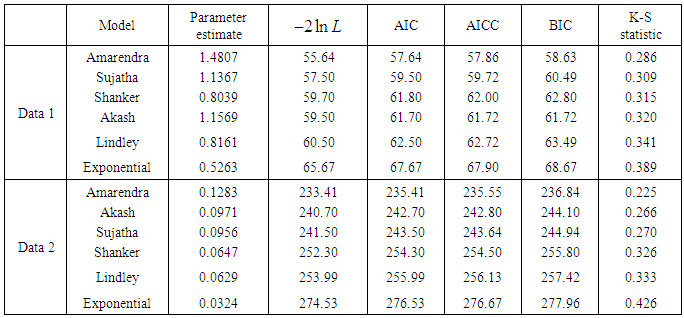
 , AIC (Akaike Information Criterion), AICC (Akaike Information Criterion Corrected), BIC (Bayesian Information Criterion), and K-S Statistics ( Kolmogorov-Smirnov Statistics) for two real data sets have been computed and presented in table 2. The formulae for computing AIC, AICC, BIC, and K-S Statistics are as follows:
, AIC (Akaike Information Criterion), AICC (Akaike Information Criterion Corrected), BIC (Bayesian Information Criterion), and K-S Statistics ( Kolmogorov-Smirnov Statistics) for two real data sets have been computed and presented in table 2. The formulae for computing AIC, AICC, BIC, and K-S Statistics are as follows: 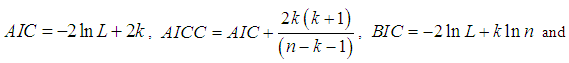
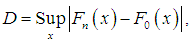 where
where 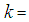 the number of parameters,
the number of parameters, 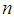 = the sample size, and
= the sample size, and 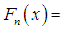 the empirical distribution function. The best distribution is the distribution which corresponds to the lower values of
the empirical distribution function. The best distribution is the distribution which corresponds to the lower values of 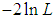 , AIC, AICC, BIC, and K-S statistics Data set 1: The first data set represents the lifetime’s data relating to relief times (in minutes) of 20 patients receiving an analgesic and reported by Gross and Clark (1975, P. 105). The data are as follows:1.1,
, AIC, AICC, BIC, and K-S statistics Data set 1: The first data set represents the lifetime’s data relating to relief times (in minutes) of 20 patients receiving an analgesic and reported by Gross and Clark (1975, P. 105). The data are as follows:1.1, 1.4,
1.4, 1.3,
1.3, 1.7,
1.7, 1.9,
1.9, 1.8,
1.8, 1.6,
1.6, 2.2,
2.2, 1.7,
1.7, 2.7,4.1,
2.7,4.1, 1.8,
1.8, 1.5,
1.5, 1.2,
1.2, 1.4,
1.4, 3.0,
3.0, 1.7,
1.7, 2.3,
2.3, 1.6,
1.6, 2.0 Data set 2: The second data set is the strength data of glass of the aircraft window reported by Fuller et al (1994):18.83,
2.0 Data set 2: The second data set is the strength data of glass of the aircraft window reported by Fuller et al (1994):18.83,  20.80,
20.80,  21.657,
21.657,  23.03,
23.03,  23.23,
23.23,  24.05,
24.05,  24.321,
24.321,  25.50, 25.52,
25.50, 25.52,  25.80,
25.80,  26.69,
26.69,  26.77,
26.77,  26.78,
26.78,  27.05,
27.05,  27.67,
27.67,  29.90, 31.11,
29.90, 31.11,  33.20,
33.20,  33.73,
33.73,  33.76,
33.76,  33.89,
33.89,  34.76,
34.76,  35.75,
35.75,  35.91, 36.98,
35.91, 36.98,  37.08,
37.08,  37.09,
37.09,  39.58,
39.58,  44.045,
44.045,  45.29,
45.29,  45.381It is obvious from above table that Amarendra distribution gives much closer fit than Akash, Shanker, Sujatha, Lindley and exponential distributions and hence it may be preferred over Akash, Shanker, Sujatha, Lindley and exponential distributions for modeling various lifetime data from medical science and engineering.
45.381It is obvious from above table that Amarendra distribution gives much closer fit than Akash, Shanker, Sujatha, Lindley and exponential distributions and hence it may be preferred over Akash, Shanker, Sujatha, Lindley and exponential distributions for modeling various lifetime data from medical science and engineering. 6. Concluding Remarks
- A new lifetime distribution named, ‘Amarendra distribution’ has been introduced to model lifetime data. Its moment generating function, moments about origin and moments about mean and expressions for skewness and kurtosis have been given. Various mathematical and statistical properties of the distribution such as its hazard rate function, mean residual life function, stochastic ordering, mean deviations, Bonferroni and Lorenz curves, have been discussed. The method of maximum likelihood and the method of moments for estimating its parameter have also been discussed. Two examples of real lifetime data- sets have been presented to show the applications and goodness of fit of Amarendra distribution over one parameter Akash, Shanker, Sujatha, Lindley and exponential distributions.NOTE: The paper is dedicated in respect of my revered teacher and supervisor Professor Amarendra Mishra, Department of Statistics, Patna University, Patna, India.
ACKNOWLEDGMENTS
- The author thanks the editor and the reviewer for their comments which led to improvement in the quality of the paper.