-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Mathematics and Statistics
p-ISSN: 2162-948X e-ISSN: 2162-8475
2013; 3(6): 346-348
doi:10.5923/j.ajms.20130306.07
The Problem of Statistical Learning Decision-Making for the Small Sample Size in Geoinformation Monitoring
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLF. A. Mkrtchyan
Department of Informatics, Institute of Radioengineering and Electronics, Russian Academy of Science, Fryazino, 141190, Russia
Correspondence to: F. A. Mkrtchyan, Department of Informatics, Institute of Radioengineering and Electronics, Russian Academy of Science, Fryazino, 141190, Russia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
The application of geoinformation monitoring means often involves statistical decision making about the presence of one or other phenomenon on a surveyed part of the Earth surface. One of the features of information acquisition conditions for such a decision is that it is impossible to obtain large statistical samples. Therefore, the development and research of optimal algorithms for distinguishing between random signals with samples of limited size under conditions of parametric a priori uncertainty is a topical problem. In the present work, a generalized adaptive learning algorithm is developed for statistical decision making concerning exponential families of distributions under conditions of a priori parametric uncertainty for small sample sizes. Numerical examples are presented. The efficiency of the optimal procedure developed is demonstrated in the case of small samples. “The reported study was partially supported by RFBR, research project No.13-07-00146”.
Keywords: Statistical Decision, Small Samples, Exponential Classes, Geoinformation Monitoring, Spottiness
Cite this paper: F. A. Mkrtchyan, The Problem of Statistical Learning Decision-Making for the Small Sample Size in Geoinformation Monitoring, American Journal of Mathematics and Statistics, Vol. 3 No. 6, 2013, pp. 346-348. doi: 10.5923/j.ajms.20130306.07.
Article Outline
1. Introduction
- The development of geoinformation monitoring systems requires a solution of some problems concerning the organization of flows of measurement data. One of important problems here is making a statistical decision about the presence of one or other phenomenon on a surveyed part of the Earth surface. One of the features of information acquisition conditions for such a decision is that it is impossible to obtain large statistical samples. Therefore, there is a need in the development and research of optimal algorithms for making statistical decisions for small-size samples under information constraints. When the number of observations is large enough, the problem is solved by the method of estimating the parameters of probability distributions, which is effective when the size of samples used for estimating the parameters indefinitely increases. Under a restricted size of samples, the decision making rule obtained by the method of estimating parameters does not satisfy the necessary optimality conditions, i.e., the constancy of the mean probability of error of the first kind and unbiasedness. In the present work, we develop an adaptive learning algorithm for statistical decision making for exponential families of distributions under conditions of a priori parametric uncertainty for small sample sizes[1, 2].
2. Statement of the Problem
- Very often, one encounters the following problem: under what class a measured random variable should be classified when a full probability description of these classes is unknown. The latter fact does not allow one to use classical results of the theory of statistical decision making. A decision can be obtained only by means of learning samples. Let ξ, η, and ζ be independent random variables and fξ(x/ω0), fη(y/ω1), and fζ(z/ω) be the distributions of probabilities ω0, ω1, ω € Ω. There are two alternatives for the parameter ω: H0: ω = ω0 and H1: ω = ω1. Errors of the first kind are given by α(φ, ω0, x*, y*) = ∫ φ(x*, y*, z*)fω0(z*)dz*and β(φ, ω0, x*, y*) = ∫[1- φ(x*, y*, z*)]fω1(z*)dz*.The optimality conditions are 1. ά = α0 (the constancy of errors of the first kind) and 2. 1 β > ά (unbiasedness). In this work, we develop a mathematical apparatus and propose a generalized adaptive procedure for solving the problem of learning to distinguish between random variables from exponential families of distributions with unknown parameters for small-size samples under information constraints. We show that available discrimination learning procedures in which first one estimates the parameters and then makes a choice between hypotheses do not satisfy the above requirements on optimal procedures. When the number of observations is large enough, the problem is solved by the method for estimating the parameters of probability distributions, which is effective when the size of samples used for estimating the parameter indefinitely increases. When the sample size is limited, the decision making rule obtained by the method of estimating parameters does not satisfy the necessary optimality conditions: the constancy of the mean probability of error of the first kind and unbiasedness.
3. Statement of the Problem
- The classical method of solving the problem is based on the sufficiently well developed theory of point estimates for unknown parameters of probability distributions. In the present problem, one obtains estimates for the parameters ω0, ω1, θ1, and θ0 from n0 observations x* = (x1, x2,………..xno) and n1 observations y* = (y1, y2,……….yn1) of the random variables ξ and η, respectively. Next, the method for constructing a decision rule is based on the Neyman--Pearson fundamental lemma: construct a likelihood relation L(z*/θ1,θ0) = [f(z1,z2,…zn/ θ1)/ f(z1,z2,…zn/ θ0)] > C(θ1,θ0) and choose a threshold C(θ1,θ0).1. θ1 > θ0 {s < t(n0/n1), s < n0/G-1n(1 - α0), 2. θ1 < θ0 { s > t(n0/n1) , s > n0/G-1n( 1- α0 ),s = x/z, t = y/z, G-1n = [1/(n-1)!] ∫ exp(-z) zn-1 dz, θ1 and θ0 are point estimates for ω1 and ω0. The domains of making a hypothesis H1 are shown in Fig. 1.
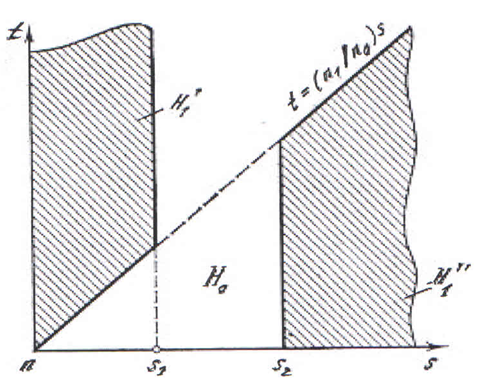 | Figure 1. Domains of making hypotheses for the classical decision rule |
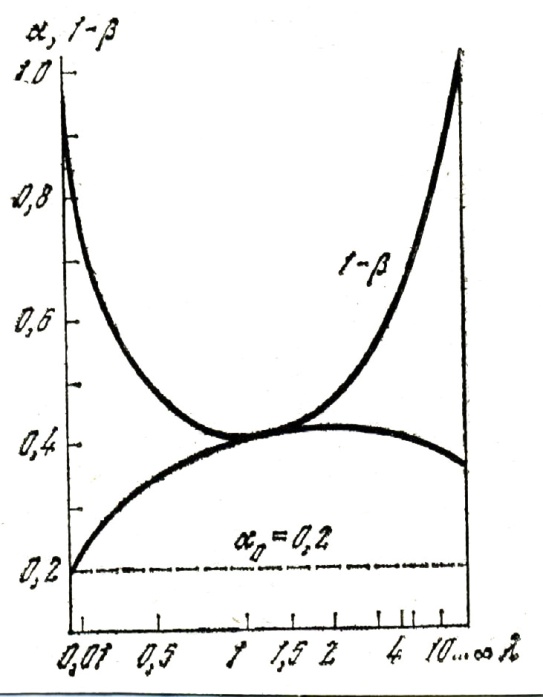 | Figure 2. Probabilities of making a correct decision and errors of the first kind |
4. Decision Rule Satisfying Necessary Optimality Conditions
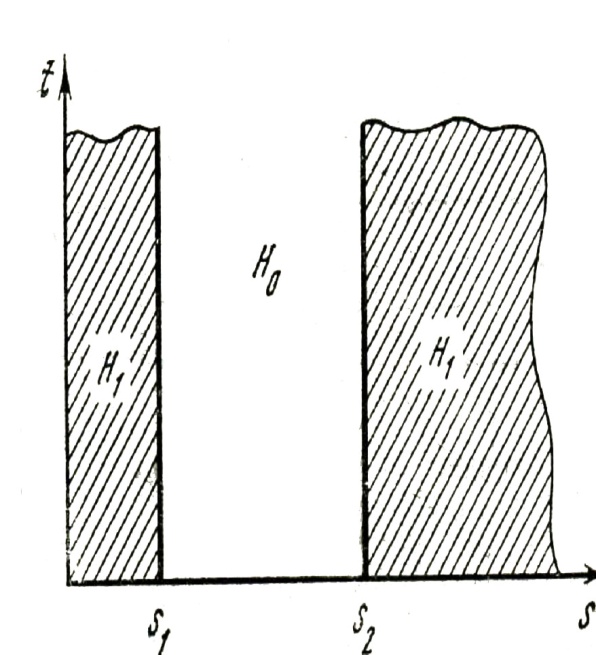 | Figure 3. Domains of making hypotheses for an optimal decision rule |
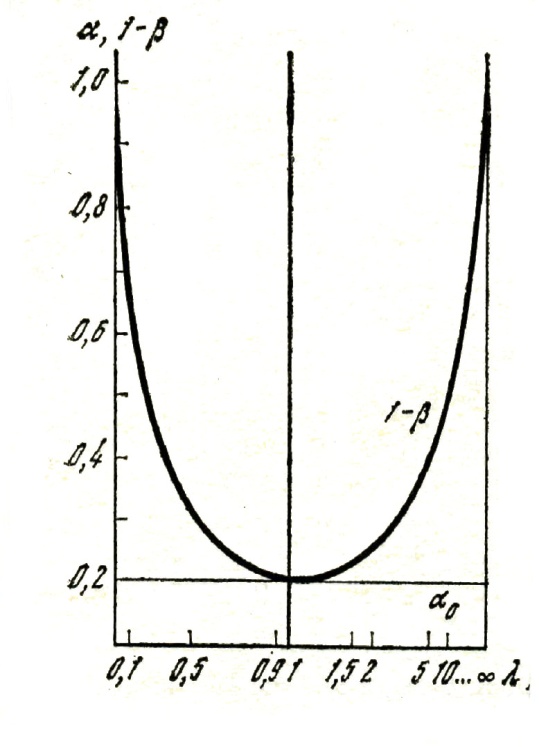 | Figure 4. Probabilities of making a correct solution and errors of the first kind |
5. Application
- The analysis of statistical characteristics of "spottiness" was carried out for three types of areas of the Pacific ocean. These statistical characteristics were obtained for the most informative thresholds. The statistical characteristics of spottiness for the same areas were chosen on the basis of the criteria of minimal value of the correlation coefficient for a joint sample of positive and negative spots. The analysis of these characteristics shows that the statistical characteristics of spottiness for regions of moderate sea roughness and storm regions coincide. The correlation coefficient ρmin attains its minimum in the case of most informative thresholds. However, for a quiet region, the situation is different[2]. Figure 5 illustrates the operation of the automated system in the mode of monitoring the surface temperature of Northern Atlantic based on data from «Kosmos-1151» (April 8-14, 1980) satellite. The system allows one to obtain temperature maps on a rather rarefied grid of satellite trajectories. The dots on the map denote areas where ship measurements were carried out. The analysis of satellite and contact measurements shows that the satellite data on the sea surface temperature are systematically understated compared with the ship measurement data, the difference being about 1.6 K on average. The root-mean-square deviation of satellite data from the ship over the entire sample data is 3.3 K. The dotted lines on the map indicate areas where the difference between the ship and satellite measurements exceeds 4 K. It is remarkable that all these areas were characterized by high cloudiness (by weather forecast data). If we disregard these areas, then the root-mean-square deviation of the satellite measurements of temperature from the ship measurements amounts to 1.4.
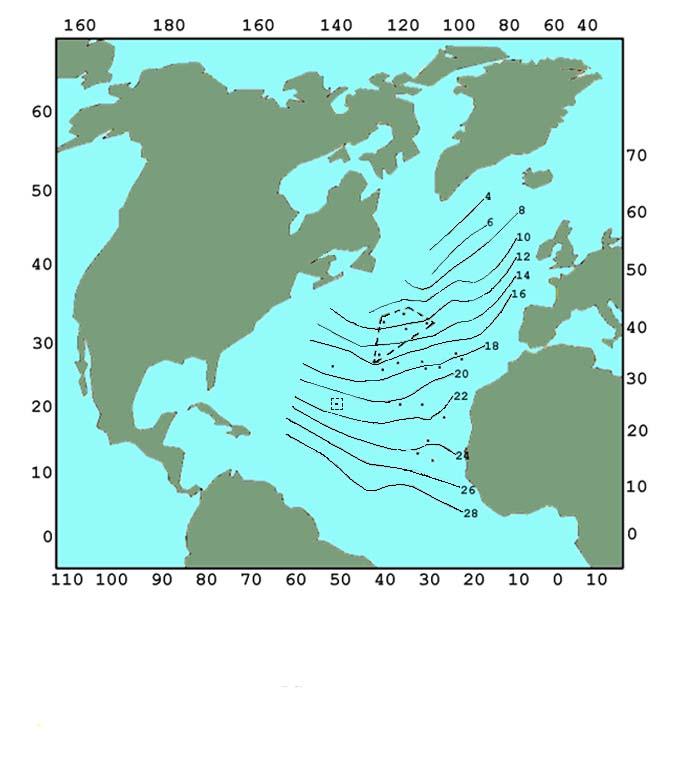 | Figure 5. Temperature map of Northern Atlantic |
6. Conclusions
- The analysis of empirical distributions of the spottiness of microwave brightness temperature has shown that, in most cases, the (l+, l-) characteristics are consistent with the exponential distribution, while the amplitude characteristics are consistent with the normal distribution. Therefore, to detect and classify phenomena on the surface of the ocean, one should apply optimal algorithms for the computer training to making statistical decisions for the aforesaid distributions.