-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2017; 7(3): 64-67
doi:10.5923/j.ajis.20170703.05

Recognition of Formatted Text using Machine Learning Technique
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRakshana J. Shetty, Nithin Kumar Heraje
Department of Computer Science & Engineering, St Joseph Engineering College, Mangaluru, India
Correspondence to: Rakshana J. Shetty, Department of Computer Science & Engineering, St Joseph Engineering College, Mangaluru, India.
| Email: |  |
Copyright © 2017 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Character recognition plays an important role in extracting the required text from a document. It is vital in many areas like banking and health services where the extraction of some of the details of the customers and patients saves the time, like extracting the bank details or the medical condition of the patients etc. Keeping this vital role of in mind this system is implemented. The main aim is to recognize the printed characters in a given input image and extracting it. It is the process in which the characters are detected and recognized from an image. Optical character recognition for the formatted English text is done. The Machine Learning technique is used where the system is initially trained for all the alphabets and numbers of the English language along with the desired output. Finally the accuracy of the system is plotted according to the output obtained.
Keywords: Machine Learning Technique, Character Recognition, Artificial Intelligence
Cite this paper: Rakshana J. Shetty, Nithin Kumar Heraje, Recognition of Formatted Text using Machine Learning Technique, American Journal of Intelligent Systems, Vol. 7 No. 3, 2017, pp. 64-67. doi: 10.5923/j.ajis.20170703.05.
Article Outline
1. Introduction
- Formatted Character Recognition (FCR) has various practical applications and is considered to be one of the most fascinating areas of pattern recognition. The interface between human and machine can be improved and it can have an immense contribution in the advancement of an automation process. The mechanism consists of converting machine printed document into text format which can be edited if required.The main purpose here is to take formatted English characters as input, process it, train the system, to recognize the pattern and produce the output which is then transferred to a text file or a doc file. The produced output can then be modified if required. The characters of English language are only recognized here but it can be further developed to recognize the characters of different languages as well.The system implemented has four different steps. Initially pre-processing is done which amplifies the image in advance to processing. Next step is segmentation which helps in locating each of the individual characters and its boundaries.Here line segmentation, word segmentation and character segmentation is performed so that individual segmentation of characters is achieved. The third step is to identify the features of the individual characters. This step is trivial as it upgrades the identification of the characters. The final step is the classification. The template matching technique is used here so that the characters can be matched accordingly so that the errors can be reduced.
2. Literature Review
- Some of the methods implemented for character recognition are discussed below.Chirag I Patel et al. implemented a method where the main objective is recognizing the characters in a given scanned document and studying the effects of changing the models of ANN. Today Neural Networks are widely preferred for Pattern Recognition chores. Different behaviours of various models of Neural Network used in OCR are discussed. Several parameters namely number of Hidden Layers, size of these Hidden Layers and epochs are considered. Multilayer Feed Forward network along with Back propagation is deployed. In the Pre processing stage some simple algorithms for segmentation of characters, normalizing of characters and De-skewing is implemented [1].Anshul Gupta et al. adapted segmentation based approach for recognition of cursive word. Initially the segmentation of cursive words into individual characters is performed. Later these words are compared with the words in the dictionary so that the meaningful word can be obtained [2].Rafael M. O. Cruz et al. performed a method where recognition is performed for each individual cursive characters. Nine different features have been extracted from the characters and the drawbacks of these features has been explained. The two features proposed are edge map and multiple zoning and these two features are further modified. Here a nine layered multilayered perceptron is used to which each individual feature is given as input. The output which is obtained from the classifier is merged with each other with the help of various rules like mean rule, sum rule etc. The accurate result is obtained is by using the edge map feature [3].M. Blumenstein et al. used techniques for segmented recognition of characters which are neural network based. Two unique features of feature extraction are explored along with two different neural networks. Back-Propagation (BP) and Radial Basis Function (RBF) network classifiers are used for comparison of directional and transition features. These are the two different features used [4].Yong Haw Tay et al. implemented the recognition based segmentation method for the identification of cursive words. A comparative study is made between two methods of recognition. For recognition the first system makes use of the amalgamation of Neural Network and Hidden Markov Model (HMM). Discrete HMM is made use in second method [5]. Radmilo M. Bozinovic et al. implemented Holistic method for recognition of cursive word. Here representation of a word is done with the help of different phases of variation like points, letter, features etc. Based on the statistical dependencies among letter and feature, generation of a vector is achieved [6].H. Bunke et al. deployed Holistic method for implementing the recognition of cursive word. Features are extracted from the skeleton of word. From the words edge information the feature vector is generated. The features include, location of edge with respect to four relative reference line [7].
3. Proposed Methodology
- The block diagram of the formatted character recognition system is shown in figure 1.
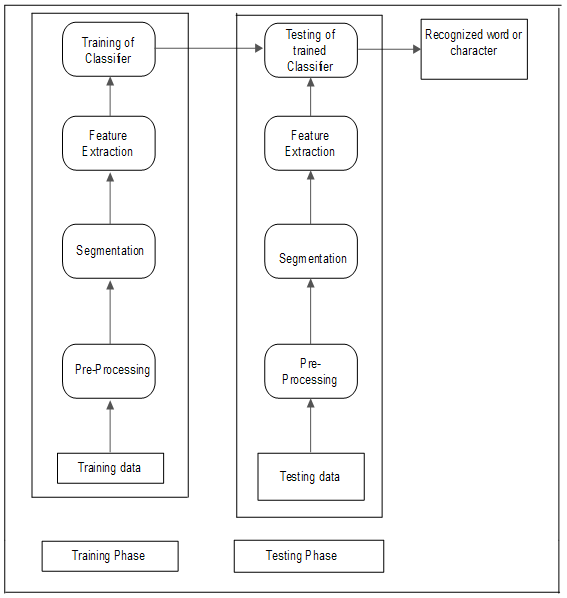 | Figure 1. Block diagram of text recognition system |
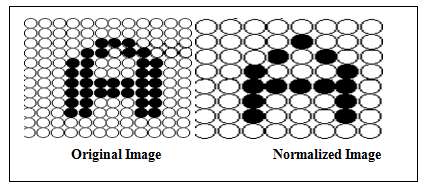 | Figure 2. Normalization example |
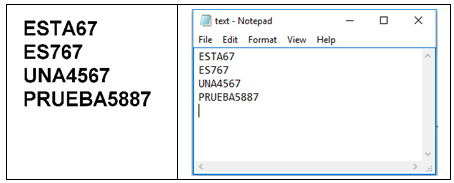 | Figure 3. Sample Output |
4. Evaluation
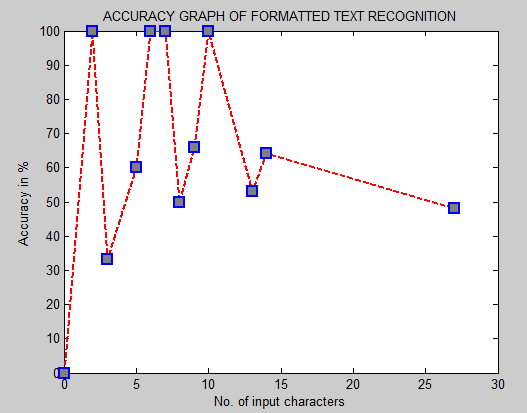 | Figure 4. Accuracy Graph |
5. Conclusions
- Character recognition is a fascinating field due to its vivid applications in different sectors like banking, healthcare etc. It has drastically reduced the human involvement. The identification of handwritten characters is lot more difficult than the formatted characters due to the variations in the human writing styles. Different methods are being deployed for this purpose but none of the methods assure to give 100% accuracy. Further improvements can be done by translating the characters of the uploaded image to characters of different languages and recognition of cursive characters and so on.