-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2017; 7(3): 50-53
doi:10.5923/j.ajis.20170703.02

Hiding Personal Detail using Overlapping Slicing
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRakshatha V., Supriya Salian
Department of Computer Science and Engineering, St Joseph Engineering College, Mangalore, India
Correspondence to: Rakshatha V., Department of Computer Science and Engineering, St Joseph Engineering College, Mangalore, India.
| Email: |  |
Copyright © 2017 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Preserving the privacy while publishing the medical dataset is one of the techniques that can be implemented to preserve the privacy on the collected large scale of medical dataset. Medical data set contains the information that will include the personal identity of an individual therefore reproducing the same data to third party may gain privacy threats, which will include the personal detail of an individual. This paper proposes a data hiding technique called overlapping slicing for the better privacy preservation of the medical dataset that gets published.
Keywords: Privacy, Overlapping Slicing, Privacy Preservation Data Publication
Cite this paper: Rakshatha V., Supriya Salian, Hiding Personal Detail using Overlapping Slicing, American Journal of Intelligent Systems, Vol. 7 No. 3, 2017, pp. 50-53. doi: 10.5923/j.ajis.20170703.02.
Article Outline
1. Introduction
- Preservation on the privacy of the published medical dataset has been most significant issue. The modern era hangs on to the rules and regulations to limit to the different types of information and a bond to store and utilize the sensitive information. Contracts and agreements don’t offer assurance that personal detail will not be revealed and end with wrong hands. Particularly when medical dataset gets published. Therefore publishing such kind of medical related datasets we have to make sure that certain techniques have been applied so the privacy is maintained while publishing the medical data. So when the medical dataset is been getting published to outside world proper measures should be taken especially while dealing with the sensitive information about any individual. This activity is called privacy preserving data publishing (PPDP). PPDP provides methods and tools for publishing useful information while preserving data privacy. PPDP offers methods and tools for publishing useful information while preserving the privacy of the medical dataset. In the most basic form of privacy-preserving data publishing (PPDP), there are different forms of identifiers namely:• Explicit Identifier: These attributes contains set of attributes such as name and social security number.• Quasi Identifier: These attributes contains set of attributes such as Birth date, zip code and sex.• Sensitive Attributes: These attributes contains set of attributes such as disease and salary.Published data becomes more useful if and only if the person’s identity is preserved. In this paper we are making use of technique called overlapping slicing as it conserves the usefulness of data against privacy threats. In the information gathering stage, the data publisher will gather the required information from the record owners. Once the required medical datasets are collected from the record owners, and then that medical datasets will be released to the public or data miner called data receipt. Data miner plays an important role of performing the data mining operation on the collected medical dataset. In the current scenario shown in the figure in the information gathering stage, the data publisher collects the required medical dataset from the record owners i.e. Alice and Cathy. Once the information is gathered from record owners, data publisher will release the data to the public called the data recipient. In the figure shown below data publisher is hospital where it gathers information from patients and patient medical record history and then publish those data to the data recipient who refers to the medical center. We have to preserve the personal detail of an each individual.
1.1. Privacy-Preserving Data Publishing
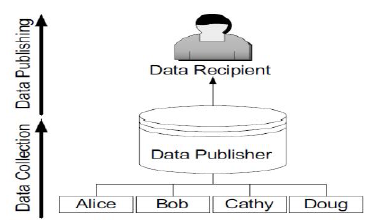 | Figure 1. Data collection and publication |
2. Literature Survey
- Privacy preserving in the field of data mining, is the area where data mining techniques are applied to protect the sensitive information from illegal user. The problem of preserving the privacy of the data that gets published had become very important in current years due to the increasing ability for storing the personal data about each individual. Numbers of techniques have been introduced like bucketization, generalization, randomization etc. In order to preserve the privacy in data mining and handling the high dimension data, generalization has drawback of preserving the information that gets lost according to the recent researches. Even bucketization method doesn’t prevent membership disclosure and at same time it is not applicable for the data that doesn’t have a clear division between the sensitive attribute and quasi attribute [1].A new method called slicing technique that partition data. Seems to be the most effective algorithm for figuring out the sliced data which follows l-diversity constraint, where we can prove that slicing prevents membership disclosure better than generalization and bucketization techniques. Compared to generalization and bucketization better utility is given by data slicing which doesn’t require clear separation between sensitive attribute and quasi attribute. Data slicing conserves better data utility than generalization and much more effective than bucketization [2].In overlapping slicing technique partitioning the data takes place vertically where highly co related attributes are grouped together so that it not reveals the information about any individuals and risk factor of identification is also reduced [3].
3. Problem Statement
- Nowadays preserving the privacy in the data publication becomes difficulty. There is always risk involved in exposing the sensitive information especially when medical datasets get published to third part or agencies. In attribute partioning the attributes which are named sensitive are grouped together in one column where the violation of the privacy takes place in generalization method and in bucketization technique there exist less co-relation between the attributes. So in order to overcome this problem a technique called overlapping slicing is used. In overlapping slicing duplication of attributes takes place un more the one column which will lead to increase the correlation among the attributes.
4. Implementation
- 1) Generalization Generalization is one of the most commonly used anonymization technique, where it replaces the quasi identifier with less specific values which are more reliable. Due to the high dimension of the medical data exists, it is likely that generalization technique will cause information loss. Generalization will be effective if and only if the records in the same bucket are very close to each other so there is always less chance of not losing the information in very large amount.2) BucketizationBucketization technique preserves the better data utility than generalization, it has some limitation. Mainly because bucketization does not prevent from revealing the personal details.as bucketization publishes the QI values in their real form, so any type adversary can find out whether an individual has any record in the published medical dataset or not. An individual can be uniquely identified by means of three attributes namely birth data, sex and zip code. This means that most of the personal detail of the individual will be revealed from the bucketized table.3) SlicingSlicing technique is used to partition the data both in vertical and horizontal manner. Vertical partition is done by grouping attributes into columns and it is purely based on the concept of correlation that exists among the attributes. The idea behind the slicing is to reduce the dimensionality of the data and preserving the data usefulness in better manner compared to generalization and bucketization. Slicing handles high dimensional data and preserves the privacy by hiding the personal detail of an individual.4) Overlapping slicingIn overlapping slicing, attributes are duplicated in more than one column. Attribute correlation exit in overlapping slicing. For example, in Table, one could choose to include the Disease attribute also in the first column. That is, the two columns are age, Sex, Disease and Zip code and Disease. This could give better data utility.
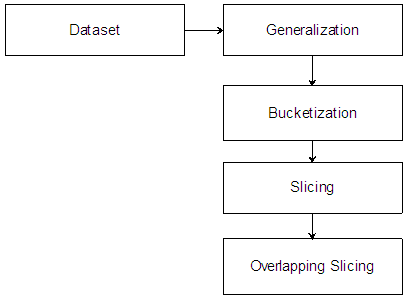 | Figure 2. Overlapping slicing architecture |
5. Results
- 1) HomepageThe concept of hiding individuals detail has been implemented and results are shown below. The proposed paper is implemented in Java technology on a Pentium-IV PC with minimum 20 GB hard-disk and 1GB RAM. The propose paper’s concepts shows efficient results and has been efficiently tested on different Datasets. The home page describe the how the individuals privacy get disclosed and patient login, admin login is there.
 | Figure 3 |
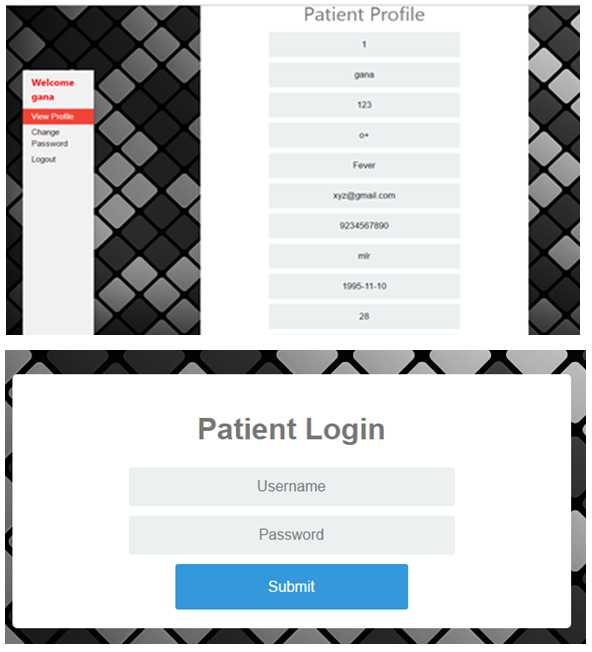 | Figure 4 |
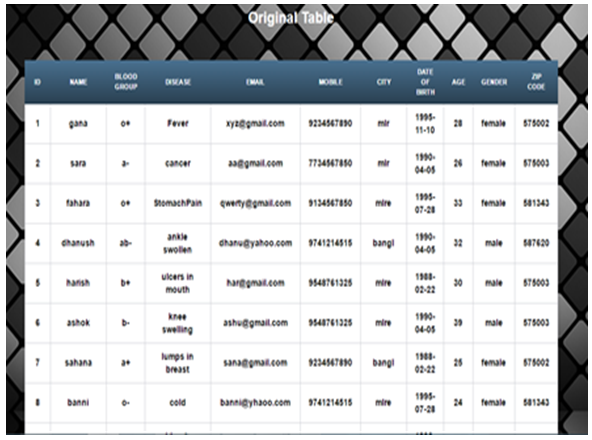 | Figure 5 |
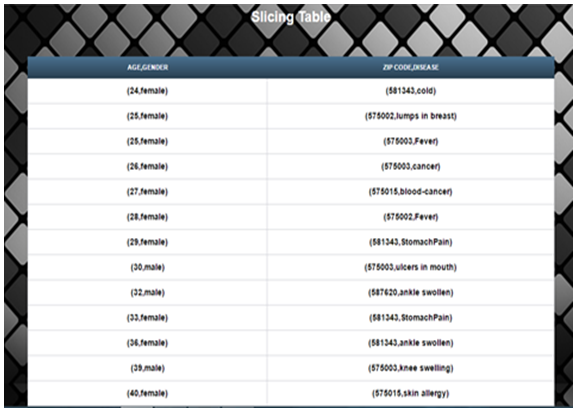 | Figure 6 |
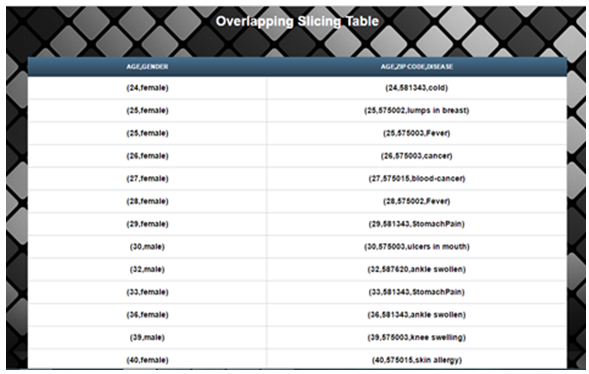 | Figure 7 |
6. Conclusions
- The drawbacks of generalization and bucketization can be reduced in Slicing and overlapping slicing technique. Overlapping slicing has the potential to hold large amount of information. In overlap-slicing, the size of data is reduced by partitioning attribute into column. It conserves the data usefulness while protecting against privacy threats. In table, each column can be referred as sub-table with a lower dimensionality. Overlapping slicing is also different from the approach of publishing multiple independent sub tables in that these sub-tables are linked by the buckets in overlap slicing. Overlap-slicing can be used without such a separation of Quasi Identifiers attribute and sensitive attribute and preserves the identity of the individual.