-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2016; 6(3): 59-65
doi:10.5923/j.ajis.20160603.01

Classification with Some Artificial Neural Network Classifiers Trained a Modified Particle Swarm Optimization
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLErdinç Kolay 1, Taner Tunç 2, Erol Eğrioğlu 3
1Department of Statistics, Sinop University, Sinop, Turkey
2Department of Statistics, Ondokuz Mayıs University, Samsun, Turkey
3Department of Statistics, Giresun University, Giresun, Turkey
Correspondence to: Erol Eğrioğlu , Department of Statistics, Giresun University, Giresun, Turkey.
| Email: |  |
Copyright © 2016 Scientific & Academic Publishing. All Rights Reserved.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

In this paper, we propose a new modified particle swarm algorithm for training some neural network classifiers for the most used classification problems in literature. Researches in artificial neural network field are based on different network architectures including multilayer perceptron, single multiplicative neuron and pi-sigma neuron model. To obtain a satisfactory performance for these classifiers, one of the most important issues is network training. Evolutionary algorithms are commonly used for training neural network classifiers. Particle swarm algorithm is population based, stochastic and meta-heuristic algorithm to solve optimization problems. As all evolutionary algorithms, the particle swarm algorithm may fall into local optimum and convergence rate may incredibly decline in iterative process. To overcome these shortcomings we refer to modify the particle swarm optimization with changing position matrix for each generation at iterative process. Experimental results show that training network with the proposed modified particle swarm optimization improve the classification performance for artificial neural network classifiers.
Keywords: Neural Network Classifiers, Multilayer Perceptron, Pi-sigma Neural Network, Single Multiplicative Neuron, Particle Swarm Optimization
Cite this paper: Erdinç Kolay , Taner Tunç , Erol Eğrioğlu , Classification with Some Artificial Neural Network Classifiers Trained a Modified Particle Swarm Optimization, American Journal of Intelligent Systems, Vol. 6 No. 3, 2016, pp. 59-65. doi: 10.5923/j.ajis.20160603.01.
Article Outline
1. Introduction
- Classification problem is defined as assigning an object to one of the predefined groups. The oldest known classification method is Discriminant Analysis and this method has well enough classification performance when only the assumptions are supplied. Artificial neural networks (ANNs) are mostly used for classification problems since a development of intelligent training algorithm [1] is called back propagation algorithm (BPA). The most of studies for classification problems with ANNs until the 2000s are summarized in [2]. Multi-layer perceptron (MLP) is most well-known ANN architecture. Even though MLP trained BPA has good classification performance, BPA suffers from a number of shortcomings, like its slow rate of convergence. Therefore, researchers have attempted to increase the performance of MLP by either modified BPA [3, 4] or different training algorithms [5-7]. Pi-sigma neural network, firstly introduced by [8], is higher-order feedforward network. Here probabilistic learning rule is used for training pi-sigma network which is applied to approximation and classification problems. Moreover pi-sigma network is used for image coding in [9], time series prediction in [10] and classification problems in [10, 11].Single multiplicative neuron (SMN) model is firstly introduced by Yadav et. al. in [12] to obtain time series prediction. They used BPA for training network and the conclusions are compared with standard MLP. In [13], SMN network is trained by improved particle swarm optimization (PSO) and results are compared with BPA, standard PSO and genetic algorithm. To avoid falling into local optimum for BPA, [14] proposes improved BPA and implement to XOR and parity problems with SMN. Finally, [15] proposes using improved glow-worm swarm algorithm for training network for SMN.PSO is firstly introduced by [16]. PSO, commonly used for neural network training [13, 17-19], is a population based, stochastic and meta-heuristic algorithm. In PSO, each particle searches global optimum point in multi-dimensional search-space. In iterative process each particle changes its position according to the individual best position and all particles’ best position at history. As all evolutionary algorithms, the PSO may fall into local optimum and its convergence rate may incredibly decline in iterative process. To overcome these shortcomings, we refer to modify the PSO which is called “RPSO”.The rest of this paper is organized as follows. Section 2 reviews some artificial neural network including MLP, Pi-sigma and SMN. Section 3 reviews the standard PSO and our proposed RPSO is introduced in Sec. 4. Experiments and results are reported in Sec. 5. The paper is concluded in Sec. 6.
2. Artificial Neural Networks
2.1. Multilayer Perceptron
- MLP, the most used neuron model in ANN literature, has a usage in very large areas in science. MLP’s architecture can be shown as in Fig 1. In this study, we limit the number of hidden layer to one and only use sigmoid activation function for easy implementation and to avoid complexity. In Fig. 1 network’s weights and thresholds can be optimized with any learning algorithm. Classification by this network is defined as follows,
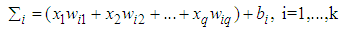 | (1) |
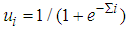 | (2) |
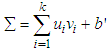 | (3) |
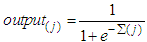 | (4) |
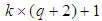 element is to be optimized for train network:
element is to be optimized for train network: 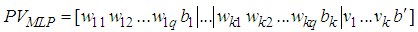 | (5) |
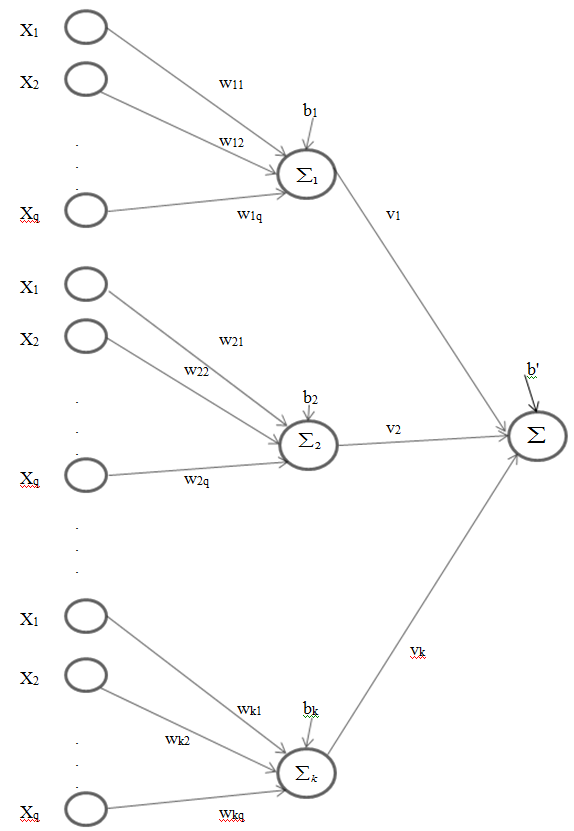 | Figure 1. Multilayer Perceptron with k units in one hidden layer |
2.2. Pi-Sigma Neural Network
- Pi-sigma neural network is higher order feedforward introduced by [8]. Pi-sigma network is similar to the MLP for their architectures which can be shown in Fig. 1 and Fig. 2. The most of important difference between two networks is to use the products of sum of k summing units for pi-sigma neural network. Outputs of the network are not affected from hidden layer thanks to fixed weights. Additionally, the lack of decision for hidden layer number may be advantage for pi-sigma neural network. To obtain output for pi-sigma network, (6) and (7) can be used. Calculations of the sums are similar to MLP in (1) and (2). Moreover, a vector of parameters including
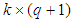 element is to be optimized given as (8):
element is to be optimized given as (8):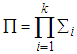 | (6) |
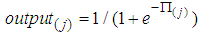 | (7) |
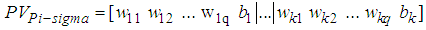 | (8) |
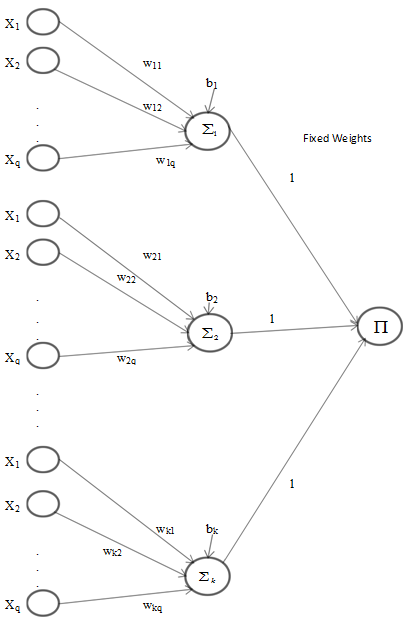 | Figure 2. Pi-Sigma Neural Network with k summing units |
2.3. Single Multiplicative Neuron Model
- SMN model is firstly used for times series prediction by [12] and better performance compared with MLP is trained BPA. SMN’s architecture is very simple and created only from one unit. This network has fewer parameters compared to others. This can be advantage in process of optimization. Fig. 3 shows SMN’s architecture. To get output, (9) and (10) are used. Lack of any restriction for implementation of this model leads the application of the network easily to any problems as classification problems. Parameters vector (11) which consists of
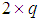 parameter is to be optimized:
parameter is to be optimized: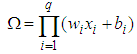 | (9) |
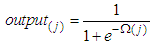 | (10) |
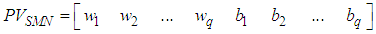 | (11) |
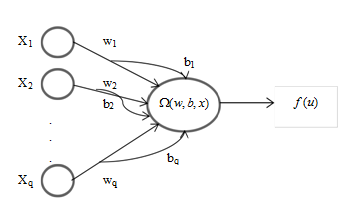 | Figure 3. Single Multiplicative Neuron Model |
3. Particle Swarm Optimization
- Population based algorithms are very popular to solve optimization problems including neural network training. The PSO is a population-based algorithm, firstly introduced by [16]. In PSO each member of population called “particle” and the entire collection of particles are called as “swarm”. This optimization technique simulates the social behaviour of swarms, such as bird flocking and fish schooling. Each particle has a random position, when the swarm initially departures for a destination. In the successive steps, each particle goes a new position by using its own previous experience (pbest) and the experience of the best positioned member of the swarm (gbest). In a d-dimensional search space, position and velocity vectors of the ith particle can be represented as Xi= (xi1, xi2,..., xid) and Vi= (vi1,vi2,...,vid) respectively. These vectors update according to equations as follows
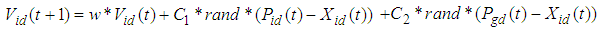 | (12) |
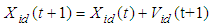 | (13) |
4. A Modified PSO
- In particle swarm optimization all particles are updated by (12) and (13). In this study, the usage of median which is a measure of central tendency is proposed, at each dimension, instead of the position of the particle which is giving the worst value of the objective function for all iterations. Also, inertia weight and constriction factors are calculated periodically as given in (14)-(16) which is referred in [27].
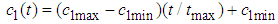 | (14) |
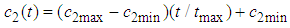 | (15) |
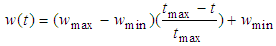 | (16) |
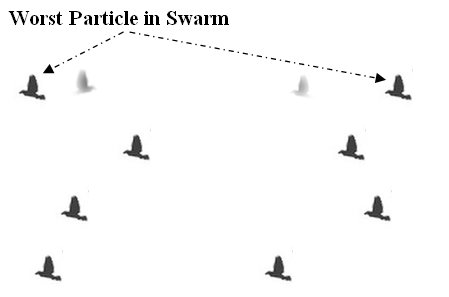 | Figure 4. Movement of Worst Particle Position in Swarm |
5. Experimental Design and Results
5.1. Experimental Design
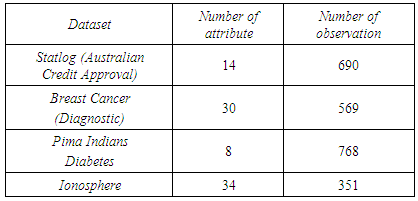
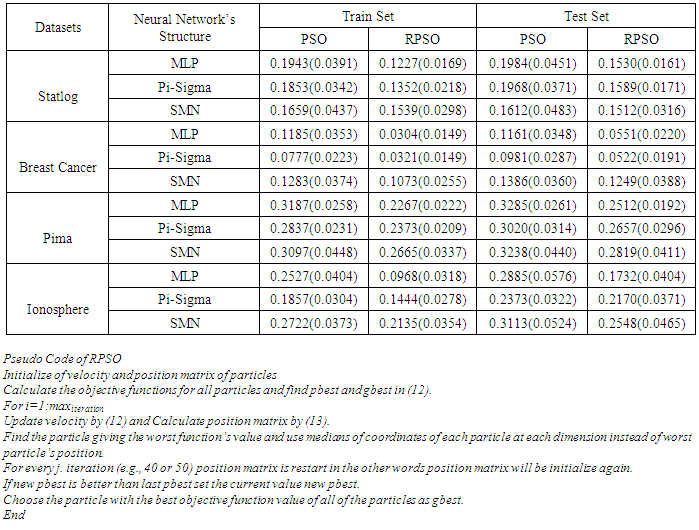
- Firstly, we first compare RPSO and the standard PSO algorithm with benchmark functions to search RPSO’s convergence rate. Table 1 consists of the most commonly used benchmark functions. In our experiment, we use these functions for comparing two algorithms. The values of the learning factor are set C1 = (1.2, 1.4995), C2 = (1.2, 1.4995). Interval of inertia weight is taken w = (0.4, 0.9) referred by [29]. Population size is 30 and the dimensions (D) for all function in Table 1 are 30 and also the maximum iteration number is 1000 for two algorithms. During the iterative process, we restart the position matrix all fortieth iteration for iterative process and run this experiment 100 times independently. Secondly, we use the most commonly used classification problems in Table 2 from UCI repository [30]. To train networks for all these classifiers, we try to optimize the parameters vector of each individual network given by (5), (8) and (11), respectively, using PSO and RPSO. MLP’s hidden layer unit k and k summing unit for pi sigma network are taken 8 and 3, respectively. Moreover, we choose randomly 50% of total sample for training data and rest of data for testing for all datasets. We run this experiment 50 times independently and investigate misclassification rate for training and testing data.
|

|
5.2. Experimental Results
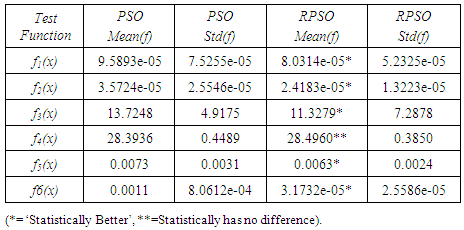
- Fig. 5 shows that the proposed RPSO converges faster than the standard PSO for five benchmark functions in Table 1 except for Rosenbrock function. We perform 100 independent runs to investigate the performance and bias of the standard PSO and RPSO. In Table 3, it is represented that the RPSO converges to the minimum values of the objective functions in Table 1 with better performance and less bias than the standard PSO. When comparing of the value of the mean for two algorithms, RPSO is statistically better with respect to Student-t distribution (Sig.<0.05).Table 4 shows the decrease in the misclassification rate for both training sample and test sample when MLP, pi-sigma and SMN classifiers are trained with RPSO. Moreover misclassification rate’s bias is less than standard PSO’s bias. Training network with RPSO increase considerably the correct classification rates for all data.This results show that RPSO is robust learning algorithm for solving optimization problems like approximation and classification problems.
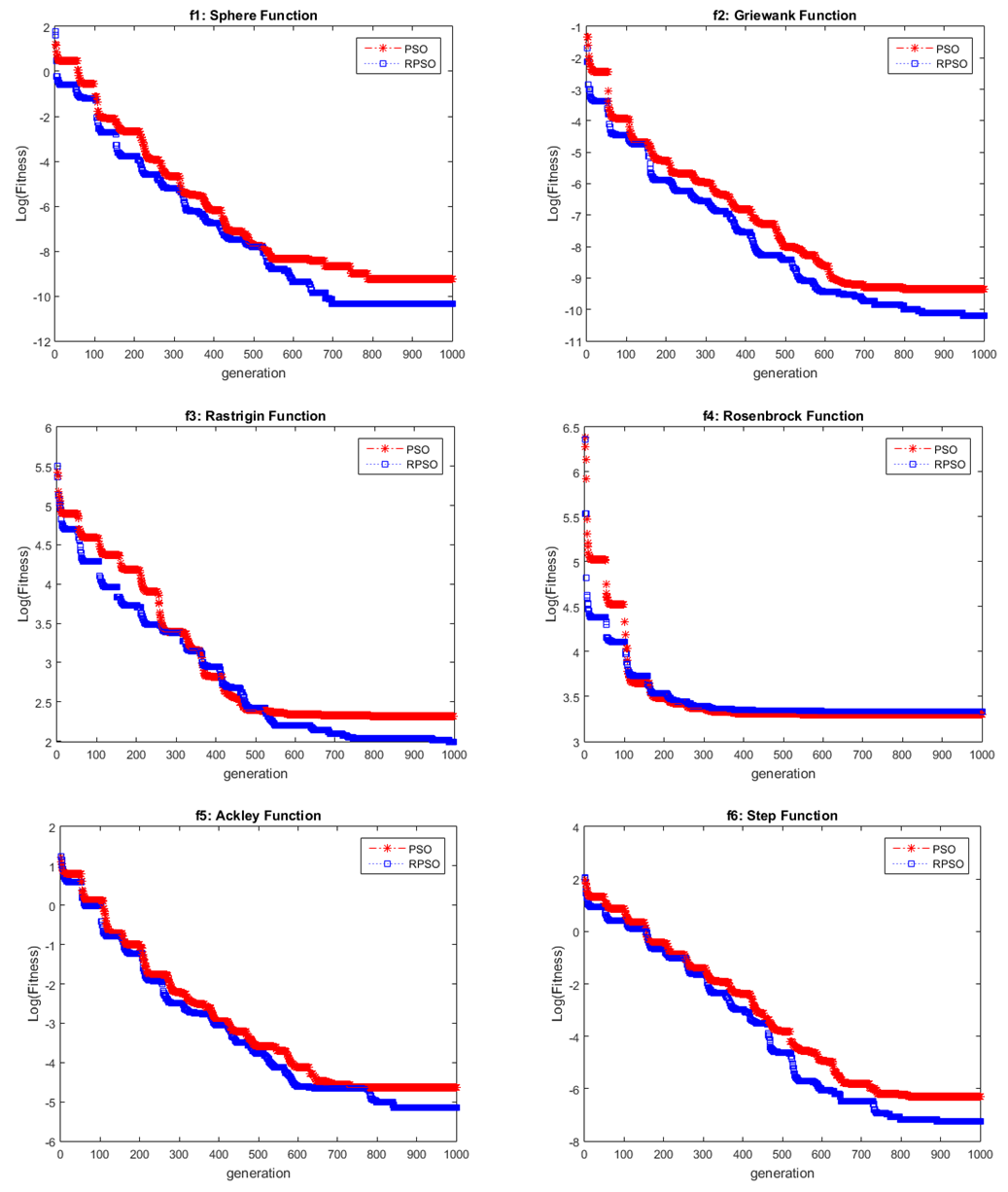 | Figure 5. Convergence Curves for the Standard PSO and RPSO |
|
|
6. Conclusions
- The performance of correct classification is characterized by the neural network’s architectures and intelligent learning algorithms. For obtaining good classification performance either various the neural network’s architecture or a modified learning algorithm can be used. To avoid falling into error researchers pay attention choosing neural network’s architectures. According to “no free lunch” theorem, which is referred by [31], the best classifier is not same for all dataset and we see this theorem’s results computationally when we analyse Table 4. From this point of view, we use three kind of neural network classifiers trained the modified particle swarm optimization to enhance the classification performance or minimise the misclassification error rate. As all evolutionary algorithms, PSO can easily fall into local optimum and speed of convergence may be reduced. To overcome this shortcoming, there are several ways to modify the PSO. To improve the PSO performance, some studies modify the parameters like inertia weights, C1 and C2 coefficients and random value etc. For this issue, we propose upgrading swarm position matrix by using median instead of the position of the particle giving the worst value of the objective function for all iterations. The results of using our modified PSO show that the proposed RPSO for performance of training neural networks is robust and better performance to estimate misclassification rates both training sample and test sample. RPSO is significantly different and has less deviation than PSO statistically (Sig<0.05). Experimental results verify this conclusion.