-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2014; 4(2): 32-42
doi:10.5923/j.ajis.20140402.02
Character Recognition by Frequency Analysis and Artificial Neural Networks
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLHajji Tarik, Jaara El Miloud
Laboratoire de recherche en informatiques LRI, Faculté des sciences FSO, Oujda, 6000, Maroc (LaRI/FSO/UMP1)
Correspondence to: Hajji Tarik, Laboratoire de recherche en informatiques LRI, Faculté des sciences FSO, Oujda, 6000, Maroc (LaRI/FSO/UMP1).
| Email: |  |
Copyright © 2014 Scientific & Academic Publishing. All Rights Reserved.
This paper describes an artificial neural network (ANN)-based system that uses a word frequency database for optical character recognition (OCR) of words in Amazigh - a North African language. OCR is a widely researched field with commercial systems available for common languages like English. In this research, we will study the character recognition using a new approach based on statistical calculation and artificial neural networks. What we propose in this work is a method that will exploit the power of the semantic analysis of the language to guess all the characters in order to solve the problem of similarity of characters and reduce recognition time. The approach we propose in this study will increase the recognition rate and optimize the response time. We have already several methods based on artificial neural networks, but most of these methods don't make an exact recognition with a rate of 100%, also the response time for these methods is very important.
Keywords: Artificial Neural Networks, Database, Modeling, Probability and Statistics, Natural Language Processing, Image Processing
Cite this paper: Hajji Tarik, Jaara El Miloud, Character Recognition by Frequency Analysis and Artificial Neural Networks, American Journal of Intelligent Systems, Vol. 4 No. 2, 2014, pp. 32-42. doi: 10.5923/j.ajis.20140402.02.
Article Outline
1. Introduction
- Optical character recognition (OCR) or video-coding means computer processes for translating text images printed or typed text files. It achieves far less than the human being, who, in addition to the recognition, understands the message, stores it or starts a critical analysis in a single time. And it’s a very important topic area in the image processing science and automatic language processing. Several approaches and methods are invented to solve the problem of characters recognition, but the common problem among the majority of these approaches is response time, which is relatively important depending on the size of the instance and the recognition rate being usually lower than 100%. This work aims to find a quadratic algorithmic approach for the optimization of the temporary complexity of the Amazigh language recognition process, and also to maximize the rate of recognition of these characters facing some recognition problems. Many recognition methods have been proposed most of which is based on the treatment of individual character such as the extraction of the characteristics of each character. This type of method is very important although it does not meet 100% we need, because we still have characters not properly classified or unclassified. In the software world, we have a large collection of computer solutions in this area as: More Data, More data Fast, and GOCR. The purpose of this paper is a method that will use the power of the semantic analysis of the language to guess all the characters in order to solve the problem of similarity of characters and reduce recognition time.The Amazigh language is one of the ancient languages of the world (950 years before Christ) and is used in Africa (Algeria, Canaries, Egypt, Libya, Mali, Mauritania, Morocco, Niger, and Tunisia). Being recognized as an official language in North Africa, it is still in the early stages of computerization.
1.1. Tifinagh Alphabet
- Before the standardization of the Amazigh, the writing as well as the computer modelling was based on the Arabic alphabet or the Latin alphabet, enriched by the special characters of the International Phonetic Alphabet (IPA). Currently, the Language Planning Center (CAL) recommends the Tifinagh as the alphabet characters for the Amazigh language. From version 4.1.0 of the Unicode standard, the IRCAM characters are encoded in the range U + 2D30 to U + 2D7F. There are 55 characters defined in the standard, but there are many more characters that are not part of the Unicode standard [1]:
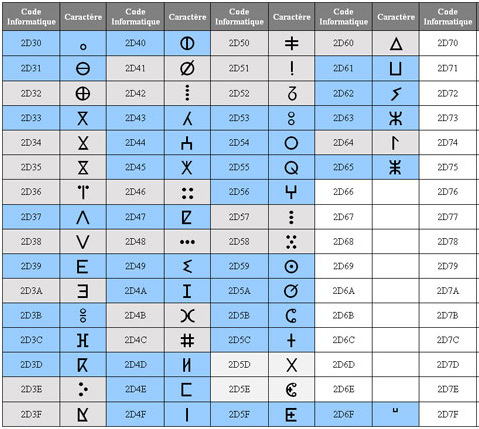 | Figure 1. Tifinagh characters |
1.2. Tamazight (state-of-the-art)
- Amazigh is an Aboriginal language of Northern Africa. This language brings together thirty dialectal varieties present from the Mediterranean to the South of Niger, and form the Canaries Islands to the western borders of Egypt. In Morocco, Amazigh is divided into three large regional varieties covering the whole mountainous regions: the Tarifite to the Northeast; Tamazight in the Middle Atlas and a party of the High Atlas; and Tachelhit in the South and Southwest. The Amazigh language and culture has experienced, through many steps, a process of standardization and integration in the new technologies of information and communication: specific encoding by extended ASCII, clean encoding in the Unicode standard, development of standards for the creation of an Amazigh keyboard and the creation of Tifinagh fonts. Since the creation of the Royal Institute of Amazigh Culture (IRCAM), the language has an institutional status allowing it to have an official spelling and clean in Unicode encoding. B.EL KESSAB and M.FAKIR have used in a work published in 2013 the ANN and the Markov model for the recognition of characters. Their approuche is tested on a database of characters Tifinagh script isolated Sizeable (900 images learning examples and 1275 test), the rate of reconnaisance found is 95.55% [2]. R.AYACHI and M.FAKIR have developed a system that uses the Fourier transform and invariant moments to extract attributes and dynamic programming and artificial neural networks for classification. The rate of reconnaissance found is in dynamic programming 92.76% and in ANN 93.27% [3]. A.Ouguengay he has a work of which he join the Tifinagh script engine Tesseract OCR Ocropus classification system. But the results are not as satisfactory [4]. K.MORO and B.KESSAB they made a contribution to the recognition of character Tifinaghe by rna and skeletonization and are obtained tau reconnisance of 92.52%. O.BENDCHAREF and N.IDRISSI they proposed the application of Riemannian geometry to the recognition of Tifinagh characters and they arrived to the rate of reconnaissance 93% [5].
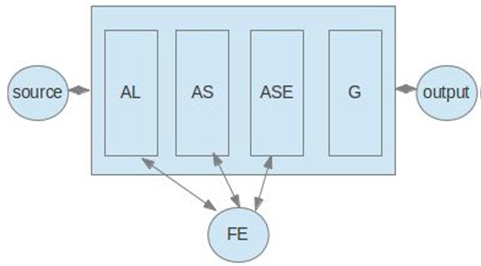
1.3. Artificial Neural Network
- The neural network is inspired by biological neural system. It is composed of several interconnected elements to solve a collection of varied problems. The brain is composed of billions of neurons and trillions of connections between them. The nerve impulse travels through the dendrites and axons, and then treated in the neurons through synapses. This results in the field of artificial neural networks in several interconnected elements or belonging to one of the three marks neurons, input, output or hidden. Neurons belonging to layer n are considered an automatic threshold. In addition, to be activated, it must receive a signal above this threshold, the output of the neuron after taking into account the weight parameters, supplying all the elements belonging to the layer n +1. As biological neural system, neural networks have the ability to learn, which makes them useful.The artificial neural networks are units of troubleshooting, capable of handling fuzzy information in parallel and come out with one or more results representing the postulated solution. The basic unit of a neural network is a non-linear combinational function called artificial neurons. An artificial neuron represents a computer simulation of a biological neuron human brain. Each artificial neuron is characterized by an information vector which is present at the input of the neuron and a non-linear mathematical operator capable of calculating an output on this vector. The following figure shows an artificial neuron [6]:
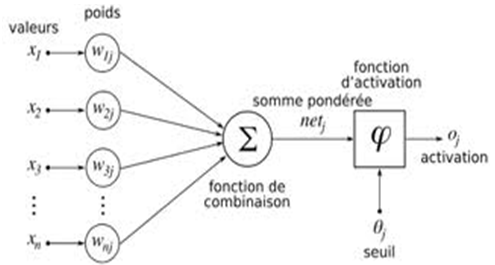 | Figure 2. Artificial neuron |
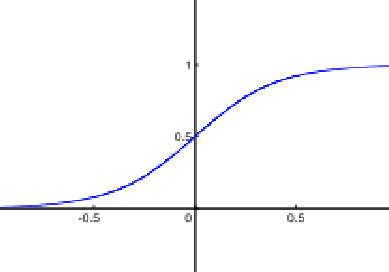 | Figure 3. Sigmoid function |
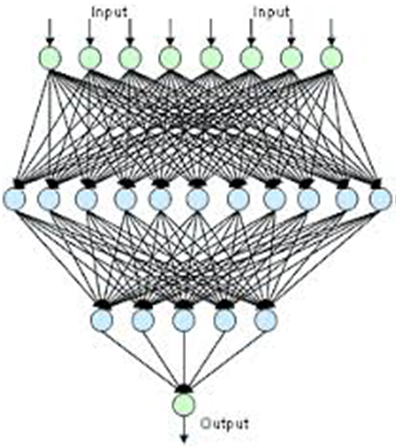 | Figure 4. Artificial neural network |
1.4. Proposed Method
- The main objective of this work is to analyze, design and implement a system that will allow character recognition of the Amazigh language using a probabilistic and statistical method based on the probabilistic calculation on text corpus of the Amazigh language through the construction of a database containing the frequency of use of each word of the Amazigh language. This database is based on a collection of corpus of the Amazigh language from several natures. The first phase of this work is the construction of the frequencies database. The second is the migration of data from the database in a method of character recognition based on neural networks. This method will allow us to reduce the number of processing operations associated with the recognition of characters; it will also allow us to maximize the rate of character recognition picture. In this work, we will also do a study to find all the morphological characteristics necessary and sufficient to represent the characters of the Amazigh language.
2. Methodology
- We have a large collection of documents of the Amazigh language; these documents are officially provided by the Royal Institute of Amazigh Culture (IRCAM) to conduct the study in real standards and to maximize the degree of accuracy of the approach.
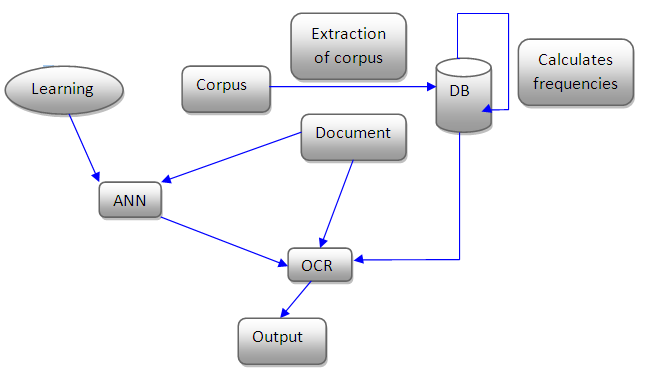 | Figure 5. Principe of the method |
2.1. Corpus of Tamazight
- The used corpus is a collection of artistic, scientific and other types of documents such as historical books, grouped in a specific context, in the aim to build a database of frequently used expressions in Tamazight. This database was recovered from the Royal Institute of Amazigh Culture (IRCAM) [11]. The majority of this corpus is not written with Amazigh characters, but they are transliterated in Arabic or Latin. For the sake of unification of the database construction and also for technical reasons, a phase of preparation and adaptation was established.
2.2. Building the Database
- The frequencies database is a computer container for storing all the information related to the corpus Tamazight. This database contains mainly tables of lexical units and their frequency of use, and another table for the corpus and their frequencies. Table of tokens is used to word recognition, while the table corpus is useful to extend the system to the global recognition corpus. The database is composed mainly by the following tables: - Table of lexical units:
 - SQL script: to create the frequencies table of Amazigh words.
- SQL script: to create the frequencies table of Amazigh words.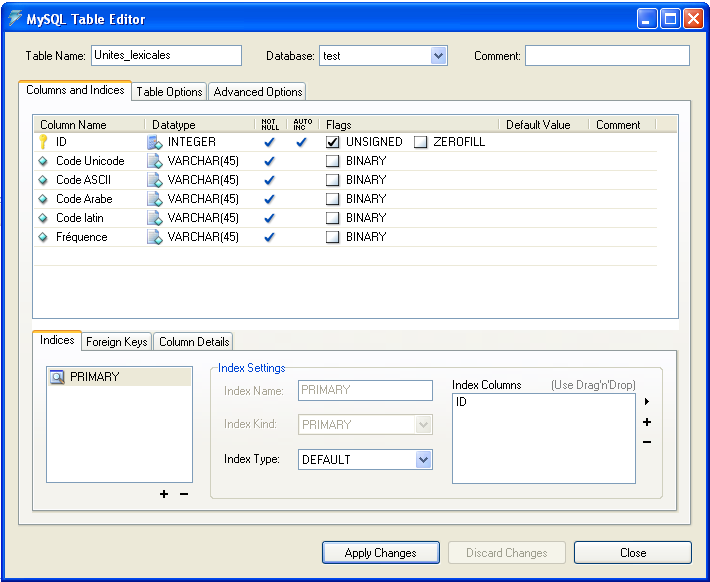 | Figure 6. Table of lexical units |
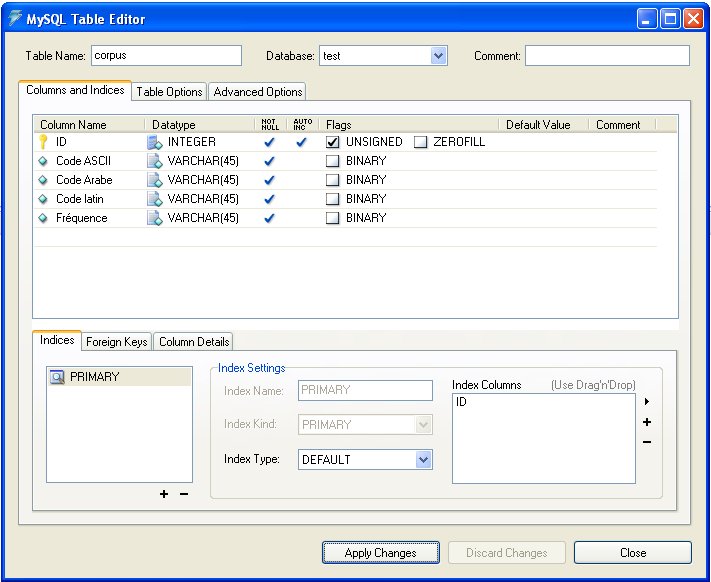 | Figure 7. Table of corpus |
 - SQL script: to create the Amazigh corpus table.The purpose of this database is to safeguard the statistical characteristics relating to corpus Tamazight and provide information engine that continuously supplies the recognition system. It should be noted that this database is constantly increasing thanks to a flexible system capable of analyzing new materials for the extraction of lexical Tamazight units and update the database.
- SQL script: to create the Amazigh corpus table.The purpose of this database is to safeguard the statistical characteristics relating to corpus Tamazight and provide information engine that continuously supplies the recognition system. It should be noted that this database is constantly increasing thanks to a flexible system capable of analyzing new materials for the extraction of lexical Tamazight units and update the database.2.3. Technical Specification of the Database
- For automatic processing of Amazigh characters in programming languages such as C language, there is no possibility to directly handling the word of Tamazight, because we do not have C compiler accepts the implementation of these characters. Therefore, we will proceed to make a transliteration of Tamazight words in other words written by Latin characters.The Royal Institute of Amazigh Culture has proposed standards for standardization of Unicode character codes IRCAM. As a result, we will use these codes to safeguard the lexical units and corpus of Tamazight in the database in order to facilitate migration in the future, and in parallel, we will also save them in formats transliterated for reasons of simplification processing all other documents and also to enjoy the power of GCC and Flex compiler for the treatment of Latin characters. This database runs on the management system MySQL database.
2.4. Calculating Frequencies Algorithm
- There is an open and ready database which save records generated by the algorithm for calculating frequencies, and has a collection of documents Tamazight PDF, doc and txt.The algorithm makes lexical analysis of each document presented to the input, then it is the recognition of a lexical unit (word or corpus) and finally launches a SQL query to the database to check whether this frequency token already exists in the database: If it already exists in the database then the frequency of use of the lexical unit (the number of occurrences and the lexical unit divided by the total number of tokens processed on all documents) one updated.If the token does not exist in the database (in the case corresponding to the first occurrence of the token) then add this into the base unit and its frequency is initialized.It is clear that the calculation algorithm is a frequency -linear algorithm based on the number of lexical items presented to the input. Since, we have for each word or phrase for each algorithm will launch a racket on the database to derive the number of occurrences which reflects clear the power of this mechanism updated in real-time data based.
2.5. Program to Build the Frequency Base
- Flex is an ideal and very powerful, tool for automatically generating lexical analyzers based on the description of lexical initiated by the definition of regular expressions. The program of construction of the base frequency is a flex program composed of three sections: 1. The definition section of macrous programming and description of lexical units and import libraries.2. The rules section UNITS lexical production and communication with the database.3. The program committee section results in the database and destroy the connection with the base. Among the main lexical units that must be delivered , we have:4. MOT: as a result of concatenation of characters ([a -zA- Z]).5. CORPUS: as a result of MOT separated by the space character (([PASSWORD] '' [PASSWORD])).Flex compiling this program will generate a lexical analyzer coded C programming language capable of supplying the database.
2.6. IRCAM Character Recognition by Artificial Neural Networks
- In this section, we will expose a method for recognizing characters IRCAM with artificial neural networks based on the extraction of the eigenvectors of the morphological characteristics of each character IRCAM.
2.7. General Description of the Process
- The objective of this method is to create an artificial neural network, with a suitable architecture, which learns to recognize characters using eigenvectors of these ones. At first, we must make a selective search on the really important and technically easy to extract and less costly in terms of the complexity characteristics to form the basis of learning artificial neural network. Then, another search to select the artificial neurons network architecture most suitable (which minimizes convergence time and maximizes the recognition rate). And finally, to accelerate the recognition process, we must seek a relationship between the weight of each feature and the activation of the neuron associated with this feature input.
2.8. Characteristics of IRCAM Characters
- Each character is IRCAM morphologically identified by several characteristics (characteristics over 80 [9]) whose potential varies between them. The following figure shows the features that we used [10]:
 | Figure 8. Characteristics of IRCAM characters |
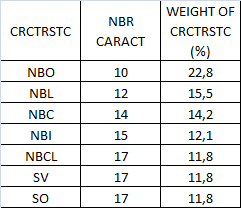 | Figure 9. Characteristics of IRCAM characters |
 | Figure 10. Characteristics of all IRCAM characters |
2.9. ANN Architecture
- A comparative study is carried out to select the most efficient architecture in terms of learning time and recognition rate of artificial neural network, this study is to instantiate multiple artificial neural networks with different architectures. The architecture is defined by a multiple of hidden layers and a number of artificial neurons in each layer.The instantiation of these neural networks is generated with a description meta-module integrated into a system of automatic generation of artificial neural networks that we have developed for this objective.
 | Figure 11. General Architecture of the automatic generator artificial neural network |
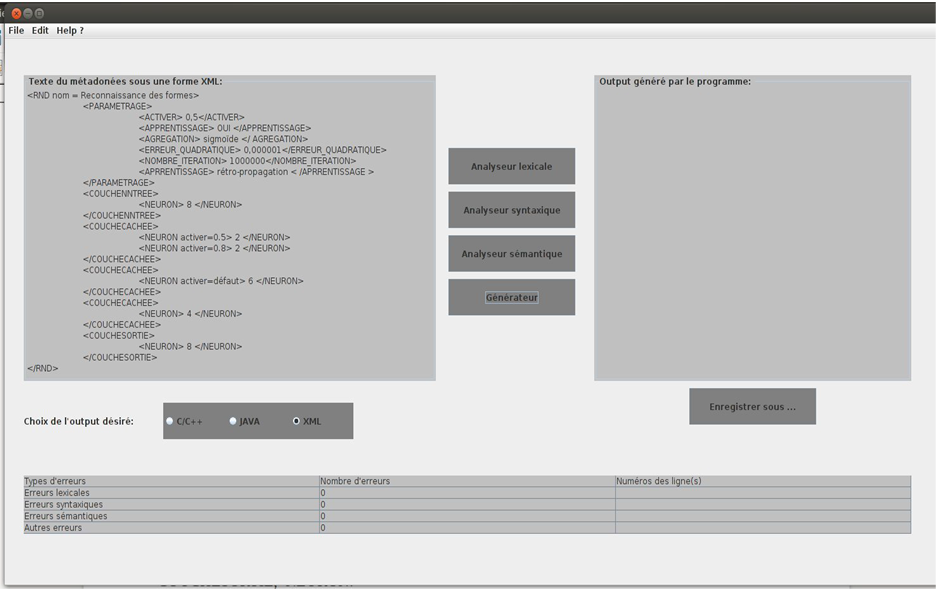 | Figure 12. Automatic generator artificial neural network |
2.10. Weight of Characteristics and Activation of Artificial Neurons
- We made the selection of morphological characteristics for use in the learning and recognition, and we selected the architecture of the ANN most suitable for the problem of IRCAM characters recognition. Finally, we noticed that these features do not have the same potential. Then we conducted another study to determine the potential of each character we have shown this problem with the following graph:
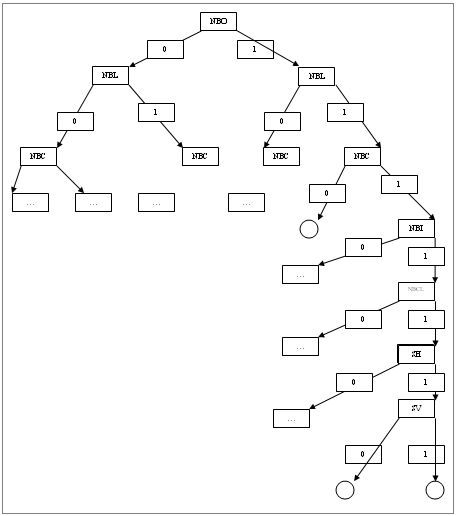 | Figure 13. Tree of recognition |
2.11. Learning Algorithm
- Step 1: Initialize the connection weights (weights are taken randomly).Step 2: Propagation entriesEntered the
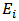 are presented to the input layer:
are presented to the input layer: 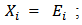 | (1) |
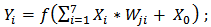 | (2) |
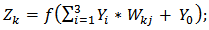 | (3) |
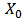 and
and 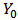 are scalar.
are scalar.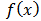 is the activation function(sigmoid):
is the activation function(sigmoid):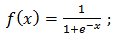 | (4) |
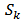 and
and 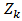 output is calculated by:
output is calculated by: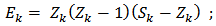 | (5) |
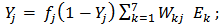 | (6) |
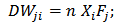 | (7) |
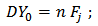 | (8) |
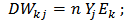 | (9) |
2.12. Partial Recognition of a Word
- The edict of this work is not to make the classic recognition of each character that makes up the word, but to do the recognition that a portion (two or three characters) of the word. The objective is to reduce the number of image processing operations on the documents. Then the database is used to derive frequency and recognize the word.a) Overall character recognitionAfter the partial recognition of a word with the use of the database frequencies and artificial neural networks, we deduce the whole other characters in the word.b) General architecture of the recognition systemThe following figure shows the relationship between the sub-programs who constitute the recognition system.
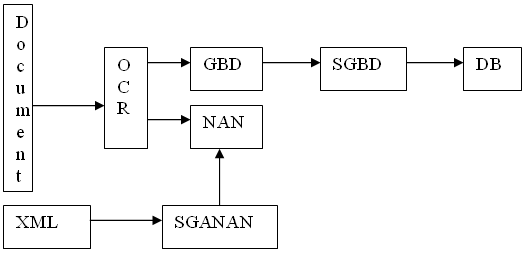 | Figure 14. General architecture of the recognition system |
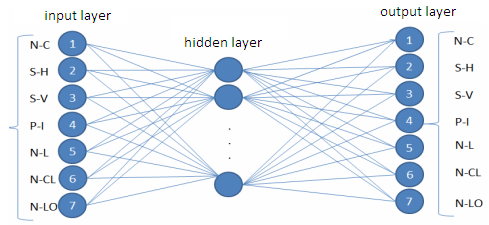 | Figure 15. OCR artificial neural network |
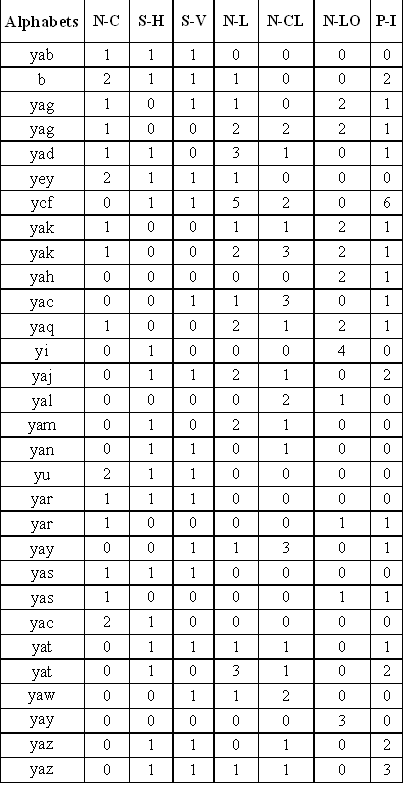
3. Results
- In this section, we will present the results we have found the test data used. As a first step, we will discuss the results of recognition using only the eigenvector characters and ANN as a classification approach, and in the following, we will show the results of using the hybrid probabilistic calculation and classification by artificial neural networks.- With artificial neural networks:
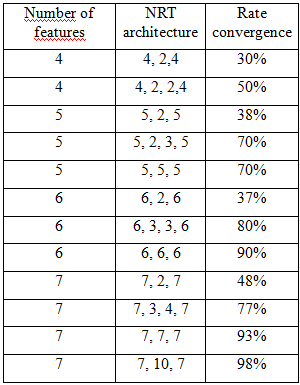 | Figure 16. Results with artificial neural networks only |
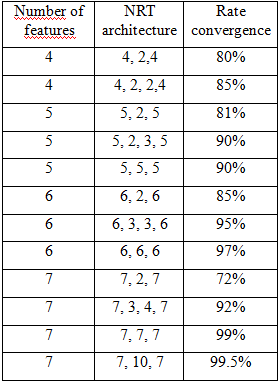 | Figure 17. Results with artificial neural networks and database frequencies |
4. Conclusions and Perspectives
- Such an approach of complete classification can't be made on the IRCAM characters, while the combination algorithms and the optimization algorithms of image processing and feature extraction remains a very open research problem in order to strengthen the classification process.In this work we presented an approach based on the probabilistic and the artificial neural networks to eliminate the problems of unclassified characters increase the recognition rate (worst classification of characters) and most importantly reduce the recognition time.Still using the same principle we can do the character recognition by a deduction of recognized corpus. We can also add a validation test corpus with a summation over the probabilities of words in the corpus.