-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2012; 2(7): 184-190
doi: 10.5923/j.ajis.20120207.05
RLIDS Based Goal Improvement in Emotional Control
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLAmin Amiri Tehrani Zade, Iman Esmaili Paeen Afrakoti, Saeed Bagheri Shuraki
Artificial Creature Lab, Department of Electrical Engineering, Sharif University of Technology, Tehran, Iran
Correspondence to: Amin Amiri Tehrani Zade, Artificial Creature Lab, Department of Electrical Engineering, Sharif University of Technology, Tehran, Iran.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In this paper, a goal improvement approach based on experiences for handling external disturbances is proposed. The suggested method uses reinforcement learning by an actor-critic mechanism in order to adapt the system to disturbance and uncertainty. Goal improvement is achieved via IDS. IDS is a powerful method in information-handling processes. It has a fast convergence and simple underlying, away from complex formulas. Temporal Difference (TD) learning is utilized in updating both Stress-Evaluator and the goal of emotional controller. As a benchmark to evaluate our method, inverted pendulum and simple submarine systems are used. Results show that the proposed method responds better to external tackling disturbances in comparison with the former fixed goal model.
Keywords: Goal, BELBIC, IDS, Fuzzy Surface, Learning
Cite this paper: Amin Amiri Tehrani Zade, Iman Esmaili Paeen Afrakoti, Saeed Bagheri Shuraki, "RLIDS Based Goal Improvement in Emotional Control", American Journal of Intelligent Systems, Vol. 2 No. 7, 2012, pp. 184-190. doi: 10.5923/j.ajis.20120207.05.
Article Outline
1. Introduction
- What is a Goal? This is the question that must be answered before going any further. The term “Goal” is defined as the cognitive representation of a desirable state which affects evaluation, emotion and behaviour. This definition has been put forward by psychology researchers[1-3]. Furthermore, a goal requires a variety of activities which enable us to reach a desirable state[4]. Goals have positivity nature which has motivation force. They also have primary reason that influence our behaviour due to their positivity natures[5]. Although Goal is defined as a desirable state which has positivity nature, the reason for which goals become positive is not clear. A goal might become positive and desirable either consciously and intentionally or subconsciously and involuntarily, e.g. repeated pairing of a given activity and the consequent reward[6]. To develop algorithms in engineering and decision making systems based on psychological and biological mechanisms is a promising area of research[7-9]. The challenging part of any psychological or biological system development is its learning necessity to adapt itself to random incidents inherent in the environment[7, 9]. Goals, as defined in engineering problems, are the performance functions that continuously evaluate the responses of environment. For instance, goals can have a critic function in critic based fuzzy controller[10], a fitness function in evolutionary algorithm[11] or they can function as an emotional cue in Brain Emotional Learning based Intelligent Controller (BELBIC)[12].Goal has a duty of directing the learning system to the desirable state. If the environment is corrupted by a variety of disturbances that cannot be predicted from the outset, adapting the parameter of learning agent is inevitable.Up to now there hasn’t been sufficient studies conducted on adapting goals in order to improve the performance of system in tackling disturbance for emotional control. Garmsiri et. Al[13] have proposed a fuzzy tuning system for parameter improvement. They used human knowledge and experience to extract fuzzy rules. Rouhani et. Al[14] have used expert knowledge to form a relationship between error and its emotional cue. In addition, a learning mechanism for attention control using sparse-super critic has been proposed in[9]. In this method, super critic sends a punishment signal sparsely in order to learn the degree of importance of each local critic assessment.As noted above, one of the critic based learning systems is BELBIC. BELBIC was first introduced in[12]. Its structure is based on Moren’s research in the field of emotional learning. Moren et Al[15] have proposed a computational model of limbic system of mammalian brain which is responsible for emotional processes. BELBIC is a model free controller with fast learning ability. Excellent performance of BELBIC in confronting disturbances has made it favourable in several control and decision making applications[12, 16-17].In model free controllers, learning may cause instability. This drawback, especially for a plant with an unstable nature, has been a challenging problem for researchers in the area of emotional control. Roshtkhari et. Al[16] cope with this problem by an imitative learning technique. Their method is based on designing imitative phases of learning to stabilize the inverted pendulum.In this paper, we introduce a new mechanism for learning and improving goal in BELBIC. In order to improve a goal, we make use of a mechanism like actor-critic. Actor-critic is a temporal difference based learning method that uses an interaction mechanism to learn proper action in a state-action space. Comprehensive details of this method can be found in[18]. The main difference of our method with other methods is that critic in our approach is an actor, and Stress- Evaluator is a critic in actor-critic structure. State-stress value planes are modeled as RLIDS in[19]. Ink drop spread (IDS) is employed as RLIDS engine. IDS is a fuzzy modeling algorithm, which expresses multi-input - single-output system as a fuzzy combination of several single-input-single-output systems[20-22]. In our algorithm, initial goal and its update rule is designed using IDS method.The paper is organized in 6 sections. In section 2 BELBIC is introduced. Section 3 is dedicated to IDS and RLIDS methods. Section 4 is devoted to our proposed method. In section 5, simulation results are demonstrated. Finally, section 6 concludes the paper.
2. BELBIC
- BELBIC is a learning controller based on the computational model of Moren’s limbic structure[15]. This structure is a simple model of the main parts in limbic system i.e., amygdale, orbitofrontal cortex, thalamus and sensory cortex which is shown in figure 1.
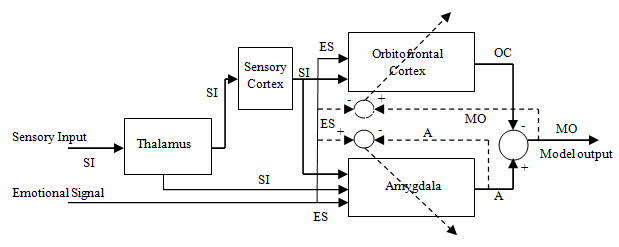 | Figure 1. simple structure of limbic system[23] |
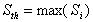 | (1) |
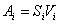 | (2) |
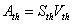 | (3) |
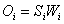 | (4) |
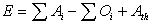 | (5) |
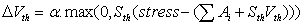 | (6) |
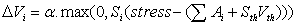 | (7) |
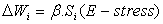 | (8) |
3. Ink Drop Spread
- Ink Drop Spread (IDS) is a fuzzy operator that has the function of information propagation in order to extract total information about the behaviour of data in the universe of discourse. In other words, IDS is a fuzzy interpolation operator. It is capable of deriving smooth curve from input data. In this method, Interpolation can be done by the use of Pyramid as a three dimensional fuzzy membership function of a data point and its neighbouring points , as shown in figure 2.
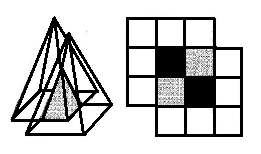 | Figure 2. pyramid membership functioning as the IDS operator and its correlation with neighbouring points |
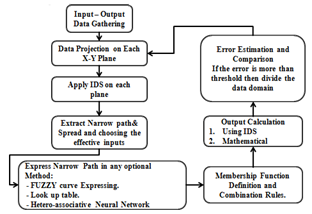 | Figure 3. flowchart of ALM Algorithm |
4. Proposed Algorithm
- As mentioned in section 1, one of the goal improvement approaches in humans is the consequence of reward experience. Reward experience refers to getting a reward for an action we do. Therefore, a mechanism that evaluates our action in each state must exist. In addition to the above statement, because our aim is to enter the mechanism of goal improvement in the area of intelligent control, we have considered two main parts in our system: Stress-Evaluator and state-stress values. Stress-Evaluator evaluates stressful actions. The state-stress evaluates the memory structure like IDS planes that memorize past experiences and their goodness according to Stress-Evaluator signals. Block diagram and flowchart of proposed controller is illustrated in figure 4 and 5.
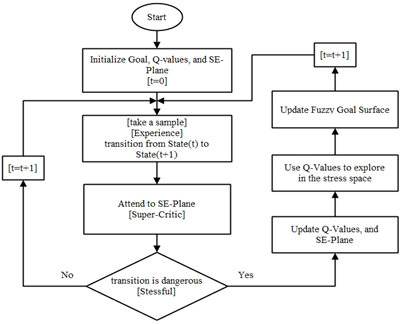 | Figure 4. flowchart of Proposed Algorithm |
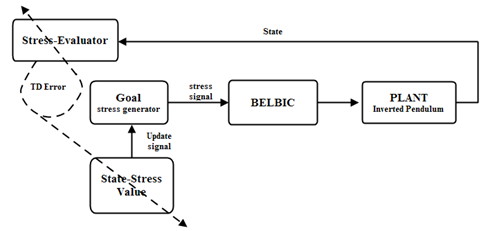 | Figure 5. block diagram of proposed learning mechanism |
4.1. Stress-Evaluator
- Stress-Evaluator is a mechanism over the critic that helps it to improve for best interaction with unknown disturbances of the environment.Stress-Evaluator in stress based critics is a metric for danger. The design of Stress-Evaluator is arbitrary for the designer and his objectives. One of the many choices that we use in this paper is Stress-Evaluator, as shown in figure 5.In the design of Stress-Evaluator, two points must be considered:● The larger the error or its derivative is, the larger the danger will be. Therefore in such situations, we must use our past experiences much more. Thus, the range of exploration is limited.● We must bear in mind that in all actions, certain amount of stress is existent; therefore our aim is to bring danger to a limited range. If error and derivative of error are lower than the threshold, this action is good and no update is needed.
4.2. State-stress value planes
- For exploration, we must save past experiences. These experiences are saved in the form of IDS planes which are inspired by active learning in human brain. In addition to experience, some extra patterns are created in accordance with the relationship among the gathered experiences.
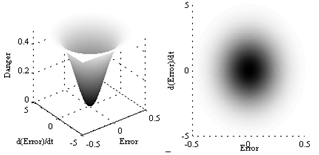 | Figure 6. Stress-Evaluator Plane |
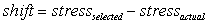 | (9) |
4.3. Learning Mechanism
- Total structure of learning is in the type of actor-critic and is based on Temporal Difference learning. The main difference is that in our approach Stress-Evaluator criticizes the action generated based on stress signal in that state. The evaluation of Stress-Evaluator is in the form of stressful action. Stress evaluation is achieved through Temporal Difference, as shown in formula (10). In this formula 𝛿 is the amount of danger in transition from state in time (t-1) to state in time (t). SE is Stress-Evaluator plane.
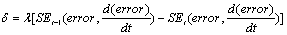 | (10) |
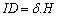 | (11) |
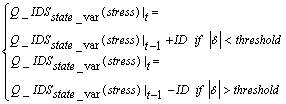 | (12) |
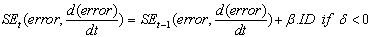 | (13) |
4.4. Goal Updating Mechanism
- The initial goal is modeled using IDS method. In this method, one IDS plane is used for each rule. Each plane is based on one variable. In our problem, we considered two variables i.e., error and derivative of error. Shifts that are obtained by state-stress value planes in formula (9) are imposed by a Gaussian function on narrow path of corresponding IDS plane of the same variable and its neighbours.
5. Results
5.1. Example1: Inverted Pendulum
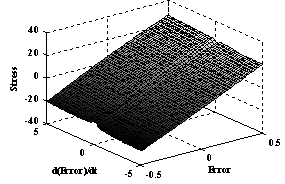 | Figure 7. Initial stress fuzzy surface (Goal) |
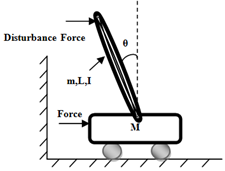 | Figure 8. illustration of Inverted Pendulum and applied disturbance force |
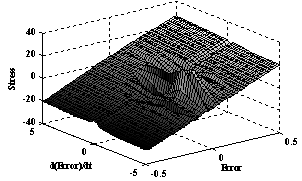 | Figure 9. Stress surface after 40 iterations of learning under applied disturbance force |
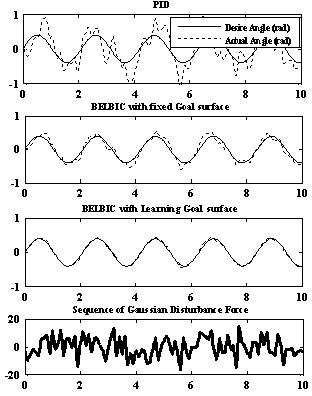 | Figure 10. result of applying disturbance on inverted pendulum after 40 iterations of learning |
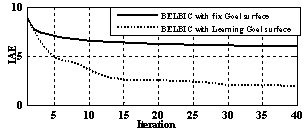 | Figure 11. Evolution of IAE in 40 iterations of learning |
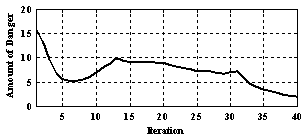 | Figure 12. Amount of danger generated from Stress-Evaluator in process of control of inverted pendulum with learning goal in 40 iterations |
|
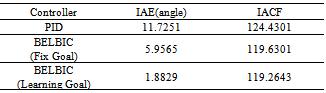
5.2. Example2: Simple Submarine System
- As another benchmark, a simple submarine system[12] is used. The transform function of this model is considered as:
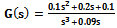 | (14) |
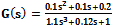 | (15) |
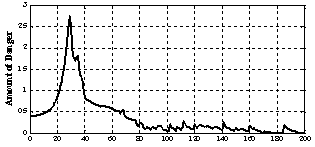 | Figure 13. Amount of danger generated from Stress-Evaluator in control process of submarine system with learning goal in 200 iterations |
|
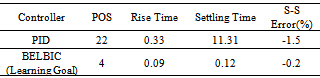
6. Conclusions
- In this paper, the main aim was to enter the mechanism of human goal improvement in the field of intelligent control. In BELBIC, controller goal is directed using the stress generated in emotional cue signal. Therefore, we used this concept as the goal and implemented the proposed mechanism in order to improve it in getting experience from the environment so after some experiences its performance improves.In order to initialize and update goal surface, IDS method is used and the structure of actor-critic is utilized for learning. Stress-Evaluator is used as the critic of stress generator fuzzy surface which represents our goal of control. Results show that our approach truly detects stressful actions and directs the goal towards increasing the performance of the overall controller.