-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2012; 2(4): 45-52
doi: 10.5923/j.ajis.20120204.03
Neuro-PCA-Factor Analysis in Prediction of Time Series Data
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLSatyendra Nath Mandal 1, J.Pal Choudhury 1, S.R. Bhadra Chaudhuri 2
1Dept. of I.T, Kalyani Govt. Engg College, Kalyani, Nadia(W.B),India
2BESU/Dept. of ETC , Howrah ( W. B), India
Correspondence to: Satyendra Nath Mandal , Dept. of I.T, Kalyani Govt. Engg College, Kalyani, Nadia(W.B),India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Many related parameters have been considered to predict any physical problem in the world. Many of them are not significant or they are highly correlated with other parameters. But, some parameters are playing significant role in prediction of the problem. These are giving necessary and sufficient information and not correlated with the others. The output of the problem can be predicted by considering fewer significant parameters instead of all. In this paper, an effort has been made to find the significant environmental parameters in production of mustard plant using principal component and factor analysis. The environmental parameters like maximum and minimum temperature, rain fall, maximum and minimum humidity, soil moisture at different depth and sun shine have been affected the growth of mustard plant. The affect has made by all parameters are not same and more complex to predict the growth of muster plant with all parameters. The principal component and factor analysis have been used here to reduce the environmental parameters. These analyses have been used to find the significant parameters that have been greatly participated in growth of mustard plant. Finally, artificial neural network has been applied on highly significant parameters to predict the production of mustard plant at maturity.
Keywords: Physical Problem, Environmental Parameters, Principal Component Analysis and Factor Analysis, Significant Parameters, Artificial Neural Network
Article Outline
1. Introduction
- From journal study, it has been proved that the main application of principal component and factor analysis are (1) to reduce the number of variables and (2) to detect the structure in the relationship between variables, that is classify variables. Therefore, factor analysis and principal component analysis are applied as data reduction or structure detection methods. The term factor analysis was first introduced by Thrustone[6], 1931.A hands-on how-to approach can be found in Stevens(1986); more detailed technical descriptions are provided in Cooley and Lohnes (1971); Harman (1976);Kim and Muller (1978a,1978b); Lawley and Maxwell(1971) Lindeman, Merenda and Gold(1980); Morrison(1967);or Mulaik(1972). The interpretation of secondary factors in hierarchical factor analysis, as an alternative to traditional oblique rotational strategies, is explained in detail by Wherry (1984). When mining a dataset comprised of numerous variables, it is likely that subsets of variables are highly correlated with each other. Given high correlation between two or more variables it can be concluded that data that these variables are quietly redundant thus share the same driving principal in defining the outcome of the interest. The use of principal component analysis techniques [3] is well established in many fields such as pharmacology, climatology, numerous aspects of the life science, economics, ( Jolliffe, 1986,Faloutsos,Korn, Labrinidis, Kaplunuorich ,& Perkovic 1997;Preisendorfer, 1988; Shum,lkeuchi, & Reddy 1997) and even religious studies! See example Walker (2001) who has provided a very illustrative a and imaginative use of this statistical methodology.S. F. Brown, A. Branford and W. Moran[33] proposed that artificial neural networks were powerful tool for analyzing data sets where there were complicated nonlinear interactions between the measured inputs and the quantity to be predicted. F. G. Donaldson and M. Kamstra[42] investigated the use of Artificial Neural Network (ANN) to combine time series forecasts of stock market volatility from USA, Canada, Japan and UK. The authors presented techniques of combining procedures to a particular class of nonlinear combining procedure based on Artificial Neural Network (ANN). H. J. Zimmermann[34] presented the application of fuzzy linear programming approaches to the linear vector maximum problem. It showed the solutions obtained by fuzzy linear programming were always efficient solutions. In a fuzzy environment a decision could be viewed as the fuzzy objective function, which was characterized by its membership functions and the constraints. G. A. Tagliarini, J. F. Christ and E. W. Page[36] demonstrated that artificial neural networks could achieve high computation rates by employing massive number of simple processing elements of high degree of connectivity between the elements. Neural networks with feedback connections provided a computing model capable of exploiting fine-grained parallelism to solve a rich class of optimization problems. This paper presented a systematic approach to design neural networks for optimization applications. M. Laviolette, J. W. Seaman Jr, J. D. Barrett and W. H. Woodall[35] presented that fuzzy set theory had primarily been associated with control theory and with the representation of uncertainty in applications in artificial intelligence. Fuzzy methods had been proposed as alternatives to statistical methods in statistical quality control, linear regression and forecasting. M. Laviolette, J. W. Seaman Jr, J. D. Barrett and W. H. Woodall[35] and stated the difference between fuzzy and probabilistic logic and stated advantages of fuzzy logic controller. The distinction between randomness and fuzziness was based on the different types of uncertainty captured by each concept. R. G. Alamond[37] presented the comparison between fuzzy set theory and probability theory, problems with probability, certain applications in fuzzy set theory. Uncertainty meant the incident, which was not known to happen in a single experiment but could be predicted the behavior of many similar experiments. Melike Sah and Konstantin, Y.Degtiarev[28] proposed a novel improvement of forecasting approach based on using time-invariant fuzzy time series on historical enrollment of the university of Alabama. They compared the proposed method with existing fuzzy time series time-invariant model based on forecasting accuracy.Tahseen Ahmed Jilani, syed Muhammad, Agil Burney and Cemal Ardil[38] proposed a method is based on frequency density based partitioning of the historical enrollment data. They proved that the proposed method is the based method of forecasting accuracy rate for forecasting enrollments than the existing methods.Using the value of shoot length, it has been observed that artificial neural network gives better results as compared to fuzzy logic and statistical models[15]. An effort has been made using neural network based on fuzzy data on mango export quantity and revenue generated from it.[16]. The different type of research work ([19]-[27]) has been carried out using fuzzy logic and artificial neural network to forecasting rainfall, temperature and thunder strorms. They compared the proposed method with existing fuzzy time series time-invariant model based on forecasting accuracy. S.Kotsiantis, E. Koumanakos, D. Tzelepis and V. Tampakas[29] explored the effectiveness of machine learning techniques in detecting firms that issue fraudulent financial statements(FFS) and deals with the identification of factors associated to FFS. Tahseen Ahmed Jilani, Syed Muhammad, Agil Burney and Cemal Ardil[30] proposed a method is based on frequency density based partitioning of the historical enrollment data . They proved that the proposed method is the based method of forecasting accuracy rate for forecasting enrolments than the existing methods. A lots of research work also have been conducted for the prediction of several things ([19]-[30]).In this paper, an effort has been made to find the significant environment parameters which are affected the growth of mustard plant using principal component and factor analysis. The environmental parameters like maximum and minimum temperature, rain fall; maximum and minimum humidity, soil moisture at different depth and sun shine have been taken. Finally, the parameters have been reduced and only few parameters have been used to predict the growth of mustard plant. To predict the growth of the mustard plant can be measured by observing the growth of its shoot length only. As new leaves of plant may appear and old leave may fall down. The roots are going deeper to deeper inside the soil. This is the reason, the shoot length has been considered here to predict the productivity of mustard plant. At initial stage, using the reduced parameters, the shoot length of the mustard plant has been predicted by artificial neural network (ANN) . Least square method has been applied on predicted shoot length to find the shoot length at maturity. Finally, the productivity of plant has been predicted from shoot lengthy at maturity (after 95 days).This type of effort has not been used in prediction the growth of mustard plant that is the reason for ma king the effort in this paper.
2. Theoretical Illustration of Principal Component and Factor Analysis and ANN
2.1. Principal Component Analysis
- PCA ([1]–[5]) transforms the original set of variables into a smaller set of linear combination that account for most of the variance of the original set. The principal component analysis has been determined almost total variation of the data as much as possible using few factors [43]. The first principal component, PC(1), accounts the maximum of total variation in the data. PC(1) is represented by linear combination of the observed variables Xj, j=1,2,3….p – sayPC (1) = w(1)1X1 +w(1)2X2+……+w(1)pXp ,where the weights w(1)1, w(1)2, ….. w(1)p have been chosen to maximize the ratio of the variance of PC(1) to the total variation, subject to the constraint that S 1-p w2(1)=1Now, The second component, PC(2), is uncorrelated with PC(1) and represents the maximum amount from the total variation not already accounted for by PC(1). In general, the mth principal component is that weighted linear combination of the X ‘sPC(m) = w(m)1X1 +w(m)2X2+……+w(m)pXp,which has the largest variance of all linear combinations that are uncorrelated with all of the previously extracted principal components. In this way, as many as possible principal components are extracted.
2.2. Factor Analysis
- Factor analysis is used to identify underlying variables, or factors which are correlated within a set of observed variables [6]. Factor analysis has also been used in data reduction by identifying a small number of factors of the variance observed in a much larger number of variables. Assume that our X variables are related to a number of functions operating regularly. That is, X1=α11F1+ α12F2+ α13F3+ . . . . + α1mFmX2=α21F1+ α22F2+ α23F3+ . . . . + α2mFmX3=α31F1+ α32F2+ α33F3+ . . . . + α3mFm
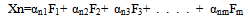 | (1) |
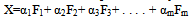 | (2) |
2.3. Artificial Neural Network (ANN)
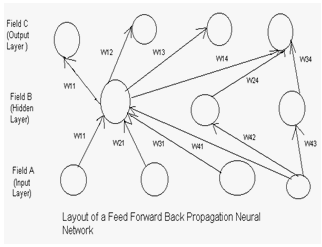
- An ANN (Artificial Neural Network) is composed of collection of interconnected neurons that are often grouped in layers. In feed forward back propagation neural network (FFBP NN) does not have feedback connections, but errors are back propagated during training. Errors in the output determine measures of hidden layer output errors, which are used as a basis for adjustment of connection weights between the input and hidden layers. Adjusting the two sets of weights between the pairs of layers and recalculating the outputs is an iterative process that is carried on until the errors fall below a tolerance level. Learning rate parameters scale the adjustments to weights. A momentum parameter can be used in scaling the adjustments from a previous iteration and adding to the adjustments in the current iteration. The layout of feed forward back propagation neural network is furnished in figure 3.
 | Figure 3. |
|
|
3. Data used in this Paper
- A statistical survey has been conducted by a group of certain agricultural scientists on different mustard plants under the supervision of Prof. Dilip De, Bidhan Chandra Krishi Viswavidyalaya West Bengal, India. The objective of the survey was to find the productivity of different mustard plant at maturity (after 95 days).The data has been collected in two stages. At first, after plantation, the reading has been taken on different parameters like shoot length, number of leaf, number of roots and root length of the plant up to 28 days. The data has been taken in some day’s interval so that the changes of parameters have been identified. Secondly, the shoot length and productivity (seed weight) at maturity (after 95 days) have been taken. The environment data like maximum and minimum temperature, rain fall; maximum and minimum humidity, soil moisture at different depth and sun shine have been collected during the year. In another paper [39], the authors have proved that the mustard plant must be planted from November to February. Now, except the shoot length, all other plant parameters cannot be measured as plant is growing. The leaves may appear and fall down and the roots are going inside the soil. So, shoot length has been used to predict the growth of mustard plant. In this paper, environmental data during initial growth(November to February) , initial shoot length of different time instances and seed weight at maturity from this survey are furnished in table 1(a), 1(b) and 1(c).
4. Method
4.1 Principal Component Analysis
- Step 1: After the plantation, the environmental parameters have been collected during the harvest period of growing stage of mustard plant is furnished table 1(a). Using Statistica 7 software package, the correlation matrix[40] of table 1(a) is furnished in table 2.Step 2: The eigen values, total variances, commulative eigen vector and percentage of contribution is furnished table 3.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
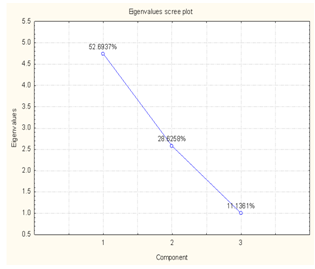 | Figure 2. Eigen Values |
|
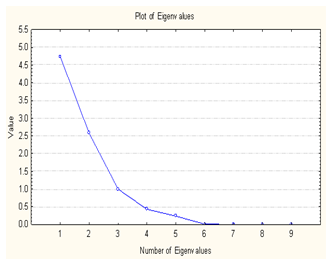 | Figure 1. Number of Eigen Values |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.2. Factor Analysis
- Step 1: The same data furnished table 1(a) has been used in factor analysis and Using Statistica 7 software package, factor loading have been calculated in factor analysis are furnished in table 7and table 8 The eigen values have been taken which are greater than 1. The factors have been taken same as number of eigen values.Step 2: In factor analysis[41], one variable is linear combination of all factors. The factor value which is greatest of all factors has been mark in the row of all variables. In each factor, it has been found the greatest value from all marks values; the corresponding variable has been taken. Using this method, the variable Min humidity has been selected in factor 1 from table 8. From the other two factors, the height loading of other two factors are -0.805376 and 0.969639, i.e., max humidity and Sun Shine.So, three variables max humidity, min humidity and sun shine have been calculated as the significant variables.
|
| ||||||||||||||||||||||||||||||||||||||||||||||
4.3. Artificial Neural Network (ANN)
- Under artificial neural network system, a feed forward back propagation neural network is used which contain three layers. One input layer, one hidden layers contain 3 neurons and one output layer contain one neuron. The values of the artificial neural network parameters are initialized by newff function which has been created develop new neural network and initial values in matlab 7 package. The momentum parameter is taken as 0.7, learning rate 0.05, initial bias of hidden layer[0.2, 0.3, and 0.5] and initial bias of output layer is[0.2].After applying PCA and Factor Analysis, the significant environmental parameters and related shoot length are furnished in table 9.
|
|
5. Result
- In this methodology, it has been proved that out of nine environmental parameters, three of them (max humidity, min humidity and sun shine) have been are played significant role for growing the mustard plant. If these three parameters are available sufficiently, the growth of mustard plant will be healthy and they will be produced huge yields. The shoot length can be predicted using ANN which furnished table 7 and linear equations. The final shoot length after 95 days is 135.88 cm and the corresponding pod yield has been predicted 2.679gm (from table 1(c)).
6. Conclusions and Future Work
- The principal component and factor analysis, same result can be produce using fewer parameters without considering all related parameters for a physical problem. The ANN used for training and testing to predict the productivity after finding the shoot length at maturity. It is a supervise learning which provide the target. This result can be cross examined using fuzzy logic, genetic algorithms in future.
ACKNOWLEDGMENTS
- The authors would like to thank to the All India Council for Technical Education (F.No-1-51/RID/CA/28/2009-10) for funding this research work.
References
| [1] | Changwon Suh, Arun Rajagopalan, Xiang Li and Krishna Rajan,” The Application of Principal Component Analysis to Materials Science Data”, Tray Ny 12180-3590 USA |
| [2] | Bernstein, I.H., Chapter 2: Some Basic Statistical Concepts. Applied Multivariate Analysis: p.2-46 |
| [3] | Bernstein , I.H., Chapter 6: Explorotory Factor Analysis. Applied Multivariate Analysis. P.157-182. |
| [4] | Shashua , A. , Intor. to Machine Learning. Lecture 9: Algebraic Representation I: PCA (scribe). 2003:p9-1-9-8. |
| [5] | Anderson, T.W., Chapter 11: Principal Components. An Introduction to Multivariate Statistical Analysis: p 451-460 |
| [6] | R.J. Rammel, “Understanding Factor Analysis “, a summary of Rummel’s Applied Factor Analysis, 1970). |
| [7] | J. Paul Choudhury, Dr. Bijan Sarkar and Prof. S. K. Mukherjee, “Some Issues in building a Fuzzy Neural Network based Framework for forecasting Engineering Manpower”, Proceedings of 34th Annual Convention of Computer Society of India, Mumbai, pp. 213-227, October -November 1999. |
| [8] | J. Paul Choudhury, Dr. Bijan Sarkar and Prof. S. K. Mukherjee, “Rule Base of a Fuzzy Expert Selection System”, Proceedings of 34th Annual Convention of Computer Society of India, Mumbai, pp. 98-104, October -November 1999. |
| [9] | J. Paul Choudhury, Dr. Bijan Sarkar and Prof. S. K. Mukherjee, “A Fuzzy Time Series based Framework in the Forecasting Engineering Manpower in comparison to Markov Modeling”, Proceedings of Seminar on Information Technology, The Institution of Engineers(India), Computer Engineering Division, West Bengal State Center, Calcutta, pp. 39-45, March 2000. |
| [10] | G. P. Bansal, A. Jain, A. K. Tiwari and P. K. Chanda, “Optimization in the operation of Process Plant through Genetic Programming”, IETE Journal of Research, vol 46, no 4, July-August 2000, pp 251-260. |
| [11] | K. K. Shukla, Neuro-genetic prediction of Software Development Effort”, Information and Software Technology 42(2000), pp 701-713. |
| [12] | S. Bandyopadhaya and U. Maulik, “An Improved Evolutionary Algorithm as Function Optimizer”, IETE Journal of Research, vol 46, no 1 and 2, pp 47-56, 2000. |
| [13] | B. Banerjee, A. Konar and S. Mukhopadhayay, “ A Neuro-GA approach for the Navigational Planning of a Mobile Robot”, Proceedings of International Conference on Communication, Computers and Devices(ICCD-2000), Department of Electronics and Electrical Engineering, Indian Institute of Technology, Kharagpur, December 2000, pp 625-628. |
| [14] | J. Paul Choudhury, Dr. Bijan Sarkar and Prof. S. K. Mukherjee, “Forecasting using Time Series Model Direct Method in comparison to Indirect Method”, Proceedings of International Conference on Communication, Computers and Devices(ICCD-2000), Department of Electronics and Electrical Engineering, Indian Institute of Technology, Kharagpur, December 2000, pp 655-658. |
| [15] | R.A. Aliev and R. R. Aliev, “Soft Computing and its applications”, World Scientific, 2002. |
| [16] | G.W.Snedecor and W.G.Cochran, “Statistical Methods”, eight edition, East Press, 1994. |
| [17] | Dr. J. Paul Choudhury, Satyendra Nath Mandal, Prof Dilip Dey, Prof. S. K. Mukherjee, Bayesian Learning versus Neural Learning : towards prediction of Pod Yield”, Proceedings of National Seminar on Recent advances on Information Technology(RAIT-2007), Department of Computer Science and Engineering, Indian School of Mines University, Dhanbad, India , pp 298-313, February 2007. |
| [18] | Dr. J. Paul Choudhury, Satyendra Nath Mandal, Prof. S. K. Mukherjee, “Shoot Length Growth Prediction of Paddy Plant using Neural Fuzzy Model“, Proceedings of National Conference on Cutting Edge Technologies in Power Conversion & Industrial Drives PCID, Department of Electrical and Electronics Engineering , Bannari Amman Institute of Technology, Sathyaamangalam, Tamilnadu, India , pp 266-270, February 2007. |
| [19] | Shyi-Ming Chen and Jeng-Ren Hwang ,” Temperature Prediction Using Fuzzy Time Series”, IEEE Transaction on Systems, Man and Cybernetics,pp263-275,Vol.30,No 2,April 2008. |
| [20] | Surajit Chattopadhyay and Monojit Chattopadhyay,”A soft computing Technique in rainfall forecasting “, proceedings of International Conference on IT,HIT, pp523-526, March 19-20,2007. |
| [21] | S. Chaudhury and S. Chatto Padhyay ,” Neuro – Computing Based Short Range Prediction of Some meteorological Parameter during Pre-monsoon Season”, Soft Computing –A fusion of Foundations Methodologies and Application ,pp349-354,2005. |
| [22] | M. Zhang and A.R. Scofield,” Artificial Neural Network Techniques for Estimating rainfall and recognizing Cloud Merger from satellite data”, International journal for Remote Sensing,16,3241-3262,1994. |
| [23] | M.J.C ,Hu, Application of ADALINE system to weather forecasting , Technical Report ,Standford Electron, 1964. |
| [24] | D.W. McCann ,” A Neural Network Short Term Forecast of Significant Thunderstroms”, Weather and Forecasting,7,525-534,doj:10.1175/1520-0434,1992. |
| [25] | D.F Cook and M.L. Wolfe, “ A back propagation Neural Network to predict the average air Temperature”, AI Applications 5,40-46,1991. |
| [26] | Mohsen Hayati and Zahra Mohebi ,” Application Artificial Neural Networks for Temperature Forecasting “ , Proceedings of WASET , pp275-279,vol 22, July 2007,ISSN 1307-6884. |
| [27] | P. Sangarun, W. Srisang, K. Jaroensutasinee and M. Jaroensutasinee ,”Cloud Forest Characteristics of Khao Nan, Thailand”, Proceedings of WASET,Vol 26, December 2007,ISSN 1307-6884. |
| [28] | Melike Sah and Konstantin, Y.Degtiarev ,” Forecasting Enrollment Model Based on First –Order Fuzzy Time Series”, Proceedings of WESET Vol I, January,2005,ISSN 1307-6884. |
| [29] | S. Kotsiantis, E. Koumanakos, D. Tzelepis and V. Tampakas ,” Forecasting Fraudulent Financial Statements using Data Mining”, International journal of Computational Intelligence,pp104-110, Vol 3 No 2. |
| [30] | Tahseen Ahmed Jilani, syed Muhammad, Agil Burney and Cemal Ardil ,” Fuzzy Metric Approach for Fuzzy Time Series Forecasting based on Frequency Density Based Partitioning”, Proceedings of WASET ,Vol 23, August 2007, ISSN 1307-6884. |
| [31] | Paras, Sanjay Mathur, Avinash Kumar and Mahesh Chandra ,” A Feature Based Neural Network Model for Weather Forecasting “,Proceedings of WASET ,Vol 23, August 2007, ISSN 1307-6884. |
| [32] | Satyendra Nath Mandal, J. Pal Choudhury, Dilip De and S. R. Bhadrachaudhuri , “ A framework for development of Suitable Method to find Shoot Length at Maturity of Mustard Plant Using Soft Computing Model” , International journal of Computer Science and Engineering Vol. 2 ,No. 3. |
| [33] | S. F. Brown, A. J. Branford, W. Moran, “On the use of Artificial Neural Networks for the analysis of Survival Data”, IEEE Transactions on Neural Networks, vol 8,no 5, Sept 1997 1071-1077. |
| [34] | H.J.Zimmermann, “Fuzzy Programming and Linear Programming with several objective functions”, Fuzzy Sets and Systems 1(1997) 45-55. |
| [35] | M. Laviolette, J.W.Seaman Jr, J. D. Barrett and W.H.Woodall, “A Probabilistic and Statistical View of Fuzzy Methods”, Technometrics, August 1995, vol 35, no 3, 249 - 261. |
| [36] | G. A. Tagliarini, J. F. Christ, E. W. Page, “Optimization using Neural Networks”, IEEE Transactions on Computers. vol 40. no 12. December ‘91 1347-1358. |
| [37] | R. G. Almond, “Discussion : Fuzzy Logic: Better Science? or Better Engineering ?”, Technometrics, August 1995, vol 37, no 3, pp 267-270. |
| [38] | Tahseen Ahmed Jilani, syed Muhammad, Agil Burney and Cemal Ardil ,” Fuzzy Metric Approach for Fuzzy Time Series Forecasting based on Frequency Density Based Partitioning”, Proceedings of World Academy Science Engineering Technology ,Vol 23, August 2007, ISSN 1307-6884.pp112-116. |
| [39] | Satyendra Nath Mandal, J.Pal Choudhury ,S.R.Bhadra Chaudhuri,Dilip De ,” A framework to Predict Suitable Period of Mustard Plant Considering Effect of Weather Parameters Using Factor and Principal Component Analysis”, International journal of “Information Technology & knowledge Management”, vol I, Issue II. |
| [40] | Alvin C Rencher & Willey Intersciences, “Methods of Multivariate Analysis”, John Wiley & Sons Inc Publication, USA. |
| [41] | Charles E. Reese and C.H. Lochmuller, “ Introduction to Factor Analysis “, Department of Chemistry , Duke University , Durham NC 27708, Copyright 1994. |
| [42] | F. G. Donaldson and M. Kamstra, “Forecast combining with Neural Networks”, Journal of Forecasting 15(1996) 49-61 |
| [43] | [43] Kai Yang, Jayant Trewn, “Multivariate Statistical Methods in Quality Management”, Mc Graw Hill, Edition: 1, Chapter 5, ISBN13: 9780071432085.pp97-157 Date of access 09.05.2012. |