-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2012; 2(4): 35-39
doi: 10.5923/j.ajis.20120204.01
Compressive Sensing Based Compressed Neural Network for Sound Source Localization
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLMehdi Banitalebi Dehkordi
Speech Processing Research Lab Elec. and Comp. Eng. Dept., Yazd University Yazd, Iran
Correspondence to: Mehdi Banitalebi Dehkordi , Speech Processing Research Lab Elec. and Comp. Eng. Dept., Yazd University Yazd, Iran.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Microphone arrays are today employed to specify the sound source locations in numerous real time applications such as speech processing in large rooms or acoustic echo cancellation. Signal sources may exist in the near field or far field with respect to the microphones. Current Neural Networks (NNs) based source localization approaches assume far field narrowband sources. One of the important limitations of these NN-based approaches is making balance between computational complexity and the development of NNs; an architecture that is too large or too small will affect the performance in terms of generalization and computational cost. In the previous analysis, saliency subject has been employed to determine the most suitable structure, however, it is time-consuming and the performance is not robust. In this paper, a family of new algorithms for compression of NNs is presented based on Compressive Sampling (CS) theory. The proposed framework makes it possible to find a sparse structure for NNs, and then the designed neural network is compressed by using CS. The key difference between our algorithm and the state-of-the-art techniques is that the mapping is continuously done using the most effective features; therefore, the proposed method has a fast convergence. The empirical work demonstrates that the proposed algorithm is an effective alternative to traditional methods in terms of accuracy and computational complexity.
Keywords: Compressive Sampling, Sound Source, Neural Network, Pruning, Multilayer Perceptron, Greedy Algorithms
Article Outline
1. Introduction
- Location of a sound source is an important piece of information in speech signal processing applications. In the sound source localization techniques, location of the source has to be estimated automatically by calculating the direction of the received signal[1]. Most algorithms for thesecalculations are computationally intensive and difficult for real time implementation[2]. Neural network based techniques have been proposed to overcome the computational complexity problem by exploiting their massive parallelism[3,4]. These techniques usually assume narrowband far field source signal, which is not always applicable[2].In this paper, we design a system that estimates the direction-of-arrival (DOA) (direction of received signal) for far field and near field wide band sources. The proposed system uses feature extraction followed by a neural network. Feature extraction is the process of selection of the useful data for estimation of DOA. The estimation is performed by the use CS. The neural network, which performs the pattern recognition step, computes the DOA to locate the soundsource. The important key insight is the use of the instantaneous cross-power spectrum at each pair of sensors. Instantaneous cross-power spectrum means the cross-power spectrum calculated without any averaging over realizations. This step calculates the discrete Fourier transform (DFT) of the signals at all sensors. In the compressive sampling step K coefficients of this DFT transforms are selected, and then multiplies the DFT coefficients at these selected frequencies using the complex conjugate of the coefficients in the neighboring sensors. In comparison to the other cross-power spectrum estimation techniques (which multiply each pair of DFT coefficients and average the results), we have reduced the computational complexity. After this step we have compressed the neural network that is designed with these feature vectors. We propose a family of new algorithms based on CS to achieve this. The main advantage of this framework is that these algorithms are capable of iteratively building up the sparse topology, while maintaining the training accuracy of the original larger architecture. Experimental and simulation results showed that by use of NNs and CS we can design a compressed neural network for locating the sound source with acceptable accuracy.The remainder of the paper is organized as follows. The next section presents a review of techniques for sound source localization. Section III explains feature selection and discusses the training and testing procedures of our sound source localization technique. Section IV describes traditional pruning algorithms and compressive sampling theory and section V contains the details of the new network pruning approach by describing the link between pruning NNs and CS and the introduction two definitions for different sparse matrices. Experimental results are illustrated in Section VI while VII concludes the paper.
2. Sound Source Localization
- Sound source localization is performed by the use of DOA. The assumption of far field sources remains true while the distance between source and reference microphone is larger than
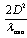 [2] fig. 1. In this equation
[2] fig. 1. In this equation 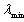 is the minimum wavelength of the source signal, and D is the microphone array length. With this condition, incoming waves are approximately planar. So, the time delay of the received signal between the reference microphone and the
is the minimum wavelength of the source signal, and D is the microphone array length. With this condition, incoming waves are approximately planar. So, the time delay of the received signal between the reference microphone and the 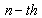 microphone would be[15]:
microphone would be[15]: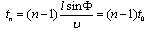 | (1) |
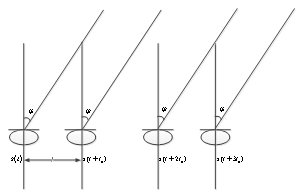 | Figure 1. Estimation of far-field source location |
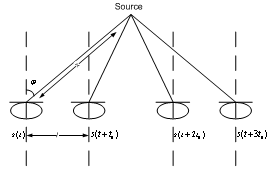 | Figure 2. Estimation of near-field source location |
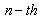 microphone would be[15] fig. 2:
microphone would be[15] fig. 2: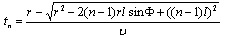 | (2) |
2. Feature Selection
- The aim of this section is to compute the feature vectors from the array data and use the MLP (Multi Layer Perceptron) approximation property to map the feature vectors to the corresponding DOA, as shown in Fig. 3[6].
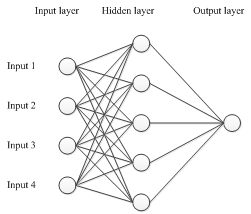 | Figure 3. Multilayer Perceptron neural network for sound source localization |
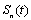 is the signal received at the
is the signal received at the 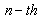 microphone and
microphone and 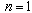 is the reference microphone
is the reference microphone 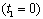 . We can write the signal at the
. We can write the signal at the 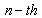 microphone in terms of the signal at the first microphone signal as follow:
microphone in terms of the signal at the first microphone signal as follow: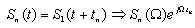 | (3) |
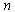 and sensor
and sensor 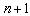 like below:
like below: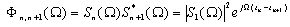 | (4) |
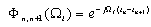 | (5) |
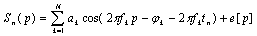 | (6) |
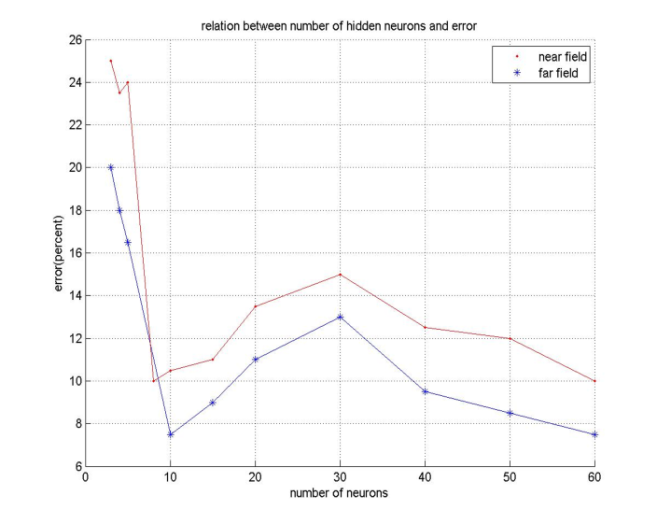 | Figure 4. Relation between number of hidden neurons and error |
3. Traditional Pruning Algorithms and CS Theory
- Generally speaking, network pruning is often casted as three sub-procedures: (i) define and quantify the saliency for each element in the network; (ii) eliminate the least significant elements; (iii) re-adjust the remaining topology. By this knowledge, the following questions may appear in mind:1) What is the best criterion to describe the saliency, or significance of elements?2) How to eliminate those unimportant elements with minimal increase in error?3) How to make the method converge as fast as possible? Methods for compressing NNs can be classified into two categories: 1) weight pruning, e.g.: Optimal Brain Damage (OBD)[10], Optimal Brain Surgeon (OBS)[4], andMagnitude-based pruning (MAG)[12]. And 2) hidden neuron pruning, e.g.: Skeletonization (SKEL)[8], non-contributing units (NC)[10] and Extended Fourier Amplitude Sensitivity Test (EFAST)[2].A new theory known as Compressed Sensing (CS) has recently emerged that can also be categorized as a type of dimensionality reduction. Like manifold learning, CS is strongly model-based (relying on sparsity in particular). This theory states that for a given degree of residual error , CS guarantees the success of recovering the given signal under some conditions from a small number of samples[14]. According to the number of measurement vectors, the CS problem can be sorted into Single-Measurement Vector (SMV) or Multiple-Measurement Vector (MMV). The SMV problem is expressed as follows. Given a measurement sample
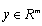 and a dictionary
and a dictionary 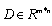 (the columns of D are referred to as the atoms), we seek a vector solution x satisfying:
(the columns of D are referred to as the atoms), we seek a vector solution x satisfying: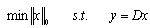 | (7) |
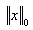 (known as l0 norm), is the number of non-zero coefficient of x.Several iterative algorithms have been proposed to solve this minimization problem (Greedy Algorithms such as Orthogonal Matching Pursuit (OMP) or Matching Pursuit (MP) and Non-convex local optimization like FOCUSS algorithm[16].
(known as l0 norm), is the number of non-zero coefficient of x.Several iterative algorithms have been proposed to solve this minimization problem (Greedy Algorithms such as Orthogonal Matching Pursuit (OMP) or Matching Pursuit (MP) and Non-convex local optimization like FOCUSS algorithm[16].5. Problem Formulation and Methodology
- Before we formulate the problem of network pruning as a compressive sampling problem we introduce some definitions[11, 10]:1. If for all columns of a matrix,
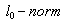 was smaller than S, then this matrix called a
was smaller than S, then this matrix called a 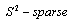 matrix.2. If the number of rows that contain nonzero elements in a matrix was smaller than S then this matrix is called a
matrix.2. If the number of rows that contain nonzero elements in a matrix was smaller than S then this matrix is called a 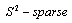 matrix.We assume that the training input patterns are stored in a matrix I, and the desired output patterns are stored in a matrix O, then the mathematical model for training of the neural network can be extracted in the form of the following expansion:
matrix.We assume that the training input patterns are stored in a matrix I, and the desired output patterns are stored in a matrix O, then the mathematical model for training of the neural network can be extracted in the form of the following expansion: | (8) |
 . When we minimize a weight matrix (w1 or w2), the behavior acts like setting, in mathematical viewpoint, the relating elements in w1 or w2 to zero. Deduction from above shows that the goal of finding the smallest number of weights in NNs within a range of accuracy can consider to be equal to finding an
. When we minimize a weight matrix (w1 or w2), the behavior acts like setting, in mathematical viewpoint, the relating elements in w1 or w2 to zero. Deduction from above shows that the goal of finding the smallest number of weights in NNs within a range of accuracy can consider to be equal to finding an  Matrix w1 or w2. So we can write problem as below:
Matrix w1 or w2. So we can write problem as below: | (9) |
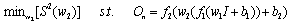 | (10) |
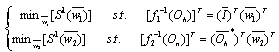 | (11) |
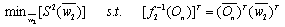 | (12) |
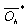 is input matrix of the hidden layer for the compressed neural network. Comparing these equations with (7) we can conclude that these minimization problems can be written as CS problems. In these CS equations
is input matrix of the hidden layer for the compressed neural network. Comparing these equations with (7) we can conclude that these minimization problems can be written as CS problems. In these CS equations 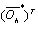 ,
, 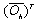 and
and 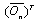 was used as the dictionary matrixes and
was used as the dictionary matrixes and 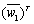 and
and 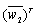 are playing the role of the signal matrix. The process of compressing NNs can be regarded as finding different sparse solutions for weight matrix
are playing the role of the signal matrix. The process of compressing NNs can be regarded as finding different sparse solutions for weight matrix 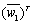 or
or 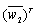 .
. 6. Results and Discussion
- As mentioned before, assuming that the received speech signals are modeled with 10 dominant frequencies, we have trained a two layer Perceptron neural network with 128 neurons in hidden layer and trained it with feature vectors that are obtained with CS from the cross-power spectrum of the received microphone signals. After computing network weights we tried to compress network with our algorithms.In order to compare our results with the previous algorithms we have use SNNS (SNNS is a simulator for NNs which is available at[19]). All of the traditional algorithms, such as Optimal Brain Damage (OBD)[16], Optimal Brain Surgeon (OBS)[17], and Magnitude-based pruning(MAG)[18], Skeletonization (SKEL)[6], non-contributing units (NC)[7] and Extended Fourier Amplitude Sensitivity Test (EFAST)[13], are available in SNNS (CSS1 is name of algorithm that uses SMV for sparse representation and CSS2 is another technique that uses MMV for sparserepresentation).Table I and II demonstrate the results of the simulations. Observing these results, in table I we compare algorithms on classification problem and in table II we compare algorithms on approximation problem. For classification problem we compare sum of hidden neurons weights in different algorithms with similar stopping rule in training neural networks. Another thing that we compared in this table was classification error and time of training epochs. In table II we compare number of hidden neurons and error inapproximation and time of training epochs, where we have stopping rule in training neural networks. With these outputs we can infer that CS algorithms are faster than other algorithms and have smaller error in compare with other algorithms. In comparison to other algorithms CSS1 is faster than CSS2 and would achieve smaller computational complexity. This means that, According to the number of Measurement vectors, the algorithm that uses single-measurement vector (SMV) is faster than another algorithm that uses multiple-measurement vector (MMV) but its achieve error is not smaller.
|
7. Conclusions
- In this paper, compressive sampling is utilized to designing NNs. Particularly, using the pursuit and greedy methods in CS, a compressing methods for NNs has been presented. The key difference between our algorithm and previous techniques is that we focus on the remaining elements of neural networks; our method has a quick convergence. The simulation results, demonstrates that our algorithm is an effective alternative to traditional methods in terms of accuracy and computational complexity. Results revealed this fact that the proposed algorithm could decrease the computational complexity while the performance is increased.
References
| [1] | R. Reed, "Pruning algorithms-a survey", IEEE Transactions on Neural Networks, vol. 4, pp. 740-747, May, 1993. |
| [2] | P. Lauret, E. Fock, T. A. Mara, "A node pruning algorithm based on a Fourier amplitude sensitivity test method", IEEE Transactions on Neural Networks, vol. 17, pp. 273-293, March, 2006. |
| [3] | B. Hassibi and D. G. Stork, "Second-order derivatives for network pruning: optimal brain surgeon," Advances in Neural Information Processing Systems, vol. 5, pp. 164-171, 1993. |
| [4] | L. Preehcit, I. Proben, A set of neural networks benchmark problems and benchmarking rules. University Karlsruher, Gerrnany, Teeh. Rep, 21/94, 2004. |
| [5] | M. Hagiwara, "Removal of hidden units and weights for back propagation networks," Proceeding IEEE International Joint Conference on Neural Network, vol. 1, pp. 351-354, Aug. 2002. |
| [6] | M. Mozer and P. Smolensky, "Skc lactonization: a technique for trimming the fat from network via relevance assessme network," Advances in Neural Information Processing Systems, vol. 1, pp. 107-115, 1991. |
| [7] | J. Sietsma and R. Dow, "Creating artificial neural networks that generalize," Neural Networks, vol. 4, no. I, pp. 67-79, 1991. |
| [8] | E. J. Candes, J. Rombcrg, T. Tao, "Robust uncertaintyprinciples: exact signal reconstruction from highly incomplete frequency information," IEEE Transactions on Information Theory, vol. 52, pp. 489-509, Jan. 2006. |
| [9] | J. Haupt, R. Nowak, "Signal reconstruction from noisy random projections," IEEE Transaction on Information Theory, vol. 52, pp. 4036-4048, Aug. 2006. |
| [10] | Y. H. Liu, S. W. Luo, A. J. Li, "Information geometry on pruning of neural network," International Conference on Machine Learning and Cybernetics, Shanghai, Aug. 2004. |
| [11] | J. Yang, A. Bouzerdoum, S. L. Phung, "A neural network pruning approach based on compressive sampling," Proceedings of International Joint Conference on Neural Networks, pp. 3428-3435, New Jersey, USA, Jun. 2009. |
| [12] | H. Rauhut, K. Sehnass, P. Vandergheynst, "Compressed sensing and redundant dictionaries," IEEE Transaction on Information Theory, vol. 54, pp. 2210-2219, May. 2008. |
| [13] | T. Xu and W. Wang, "A compressed sensing approach for underdetermined blind audio source separation with sparse representation," 2009. |
| [14] | J. Laurent, P. Yand, and P. Vandergheynst, "Compressed sensing: when sparsity meets sampling," Feb. 2010. |
| [15] | G. Arslan, F. A. Sakarya, B. L. Evans, "Speaker localization for far field and near field wideband sources using neural networks," Proc. IEEE-EURASIP Workshop on Nonlinear Signal and Image Processing, vol. 2, pp. 569-573, Antalya, Turkey, Jun. 1999. |
| [16] | Y. Le. Cun, J. S. Denker, and S. A. Solla, "Optimal brain damage," Advance Neural Information. Process. Systems, vol. 2, pp. 598-605, 1990. |
| [17] | B. Hassibi and D. G. Stork, "Second-order derivatives for network pruning: optimal brain surgeon,” Advances in Neural Information Processing Systems, vol. 5, pp. 164-171, 1993. |
| [18] | M. Hagiwara, "Removal of hidden units and weights for back propagation networks," Proc. IEEE Int. Joint Conf. Neural Network, pp. 351-354, 1993. |
| [19] | SNNS software, available athttp://www.ra.cs.unituebingen.de/SNNS |