-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2012; 2(1): 1-8
doi:10.5923/j.ajis.20120201.01
A Comparitive Survey of ANN and Hybrid HMM/ANN Architectures for Robust Speech Recognition
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLMondher Frikha, Ahmed Ben Hamida
Advanced Technologies for Medical and Signals (ATMS) Research Unit, National School of Engineering of Sfax, B.P.W, Sfax ,Tunisia
Correspondence to: Mondher Frikha, Advanced Technologies for Medical and Signals (ATMS) Research Unit, National School of Engineering of Sfax, B.P.W, Sfax ,Tunisia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
This paper proposes two hybrid connectionist structural acoustical models for robust context independent phone like and word like units for speaker-independent recognition system. Such structure combines strength of Hidden Markov Models (HMM) in modeling stochastic sequences and the non-linear classification capability of Artificial Neural Networks (ANN). Two kinds of Neural Networks (NN) are investigated: Multilayer Perceptron (MLP) and Elman Recurrent Neural Networks (RNN). The hybrid connectionist-HMM systems use discriminatively trained NN to estimate the a posteriori probability distribution among subword units given the acoustic observations. We efficiently tested the performance of the conceived systems using the TIMIT database in clean and noisy environments with two perceptually motivated features: MFCC and PLP. Finally, the robustness of the systems is evaluated by using a new preprocessing stage for denoising based on wavelet transform. A significant improvement in performance is obtained with the proposed method.
Keywords: Speech Recognition, HMM, ANN, MLP, RNN, Hybrid Sys
Cite this paper: Mondher Frikha, Ahmed Ben Hamida, A Comparitive Survey of ANN and Hybrid HMM/ANN Architectures for Robust Speech Recognition, American Journal of Intelligent Systems, Vol. 2 No. 1, 2012, pp. 1-8. doi: 10.5923/j.ajis.20120201.01.
Article Outline
1. Introduction
- Most of the current state of the art automatic speech recognition (ASR) systems are probably based on the use of a continuous density hidden Markov models (HMM) of which functionality is based on a rigorous probability theory[16],[17]. This was basically due to the efficiency with which HMM model the variation in the statistical properties of speech, both in the time and the frequency domains[15]. Also, the major advantages on the use of such models rely on their relatively fast estimation of their parameters from training data. Dynamic programming could be then used effectively to reduce computational complexity. Furthermore, their performance in terms of recognition accuracy is very high, even when computational efficiency requirements are very strict. One drawback of HMM is the various conditional independence assumptions imposed by the Markov Model. These assumptions essentially state that each speech frame is independent of its neighbours.However, over the last few years, several attempts have been undergone to evaluate the HMM deficiencies. Artificial Neural Networks (ANN) and more specifically multilayer perceptrons (MLP) appeared to be a promising alternative in this respect to replace or help HMM in the classification mode. So, a number of ANN approaches have beensuggested and used to improve the state of the art of ASR systems[20],[24]. The fundamental advantage of such approach is that it introduces a discriminative training[18]. The two main drawbacks of NN systems is their increased training computational requirements as well as their incapacity of accommodating time sequences of speech. A plethora of results indicated that NN can be trained as a probability estimator[10],[21]. This important research finding eased their integration with the HMM current state of the art recognition system technology[2]. This fact led to the possibility of unifying HMM and ANN within unifying novel models[5].In this study, we combined the advantages of the HMM and the ANN paradigms within a single hybrid system to overcome the limitations of any approach operating in isolation. The goal in this hybrid system for ASR is to take the advantage from the properties of both HMM and ANN improving its flexibility and recognition performance. An hybrid HMM/ANN recognizer that combines efficient discriminative learning capabilities of NN[5] and the superior time warping and decoding techniques associated with the HMM approach was therefore developed[1]. ANN were trained to estimate HMM emission probabilities required in HMM based only on the acoustic information in a limited number of local speech frames[26]. Those probabilities were then used by a Viterbi decoding process for recognition[8],[9]. Two kinds of ANN were investigated: Multilayer perceptrons (MLP) and recurrent neural networks (RNN), to compute posterior probabilities of classes that should be fed into the HMM decoder. The robustness of the constructed hybrid ASR system operating under noisy environments was also evaluated and a new preprocessing denoising algorithm based on wavelet transform was proposed. The remainder of this paper is organized as follows. The state of the art of speech recognition process which is composed of the acoustic analysis and classification modules is reviewed in section 2. In order to study the robustness of the constructed hybrid recognition system, a new preprocessing speech enhancement approach based on wavelet transform is described in section 3. Finally, experiments and results obtained in both clean and noisy environments are presented and discussed followed by some conclusions.
2. Speech Recognition Process
- Speech recognition systems have a wide range of applications from isolated-word recognition as in name-dialling and voice-control of machines to continuous natural speech recognition as in auto-dictation or broadcast-news transcription. Most practical speech recognition systems consist of two modules: the front end feature module and back end classification module. Figure 1 shows a general scheme of a speech recognition system.
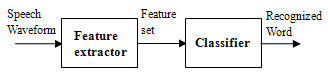 | Figure 1. General Scheme of a Speech Recognition System |
2.1. Feature Extractor
- The design of the front end feature extraction module is a relevant aspect for the performance of the speech recognizer because this module is intended to extract the discriminative information utilized by the classification module to perform recognition. Front end design has been an area of active research in the last few decades. The two front end dominant approaches in speech recognition are based on Mel frequency cepstral coefficient (MFCC)[19] and perceptual linear prediction (PLP)[11]. They are the most widely used acoustic features in current ASR systems. The steps followed in computing those features are detailed in figure 2. In the case of the speech signal, the feature extractor will first have to deal with the long-term non stationary. For this reason, the speech signal is usually cut into frames of about 10-30ms and feature extraction is performed on each piece of the waveform. Secondly, the feature extraction algorithm has to cope with the short-term redundancy so that reduced and relevant acoustic information is extracted. For this purpose, the representation of the waveform is generally swapped from the temporal domain to the frequency domain, in which the short-term temporal periodicity is represented by higher energy values at the frequency corresponding to the period. Thirdly, feature extraction should smooth out possible degradations incurred by the signal when transmitted on the communication channel. Finally, feature extraction should map the speech representation into a form which is compatible with the classification tools in the remainder of the processing chain. Some classification algorithms will, for example, require a decorrelation of the features.
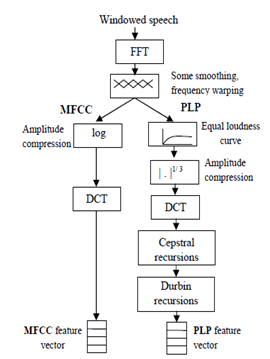 | Figure 2. Steps Followed to Compute Mel Frequency (MFCC) and Perceptual Linear Prediction (PLP) Features |
2.2. Classification Module
- We are interested in this section in three kinds of classifiers. The statistical classifier based on Hidden Markov Models constitutes actually the predominant approach in speech recognition. The connectionist models or artificial neural network (ANN) proposed in recent years as an alternative potential approach to speech recognition systems because of their impressive ability to decorrelate the input features and therefore ameliorate the interclass discrimination. The hybrid connectionist-HMM approach which combines the temporal modeling structure of HMMs with pattern classification capabilities of ANNs. We give a brief overview of these approaches in the next subsections.
2.2.1. HMM Speech Recognition
- Hidden Markov modeling of speech, assumes that speech is a piecewise stationary process. That is an utterance is modelled as a succession of discrete stationary states, with transitions. HMM are “hidden” because the state of the model, q, is not observed whereas the output of the stochastic process attached to that state is observed. This is described by a probability distribution P(x/q), where x is the acoustic evidence emitted by state q. The other set of pertinent probabilities are the instantaneous transition probabilities distribution, aij=P(qi/qj), between state i and state j. Figure 3 illustrates a simple Bakis HMM topology. Essentially, a HMM is a stochastic automaton, with a stochastic output process attached to each state. Thus, we have two concurrent processes: a Markov process modelling the temporal structure of speech and a set of state output processes modelling the instantaneous character of the speech signal. We have around 60 basic phone HMM (for English), and from these we construct word models. For any given sentence, we may write down the corresponding HMM; each state in that HMM is contributed by a constituent phone HMM.
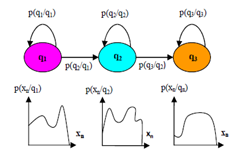 | Figure 3. A Schematic of a Three State, Left to Right HMM |
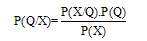 | (1) |
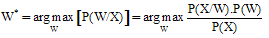 | (2) |
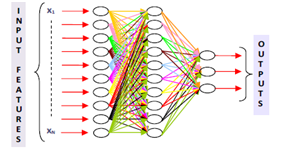 | Figure 4. Feedforward MLP Architecture with One Hidden Layer |
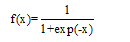 | (3) |
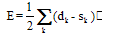 | (4) |
2.2.2. Hybrid Recognition System
- The principle aim of an artificial neural network hybrid (HMM/ANN) system is to combine the efficient discriminative learning capabilities of neural networks and the superior time warping and decoding techniques associated with the HMM approach.
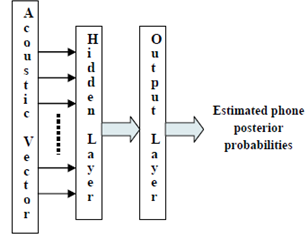 | Figure 5. Generic MLP for Posterior Probabilities Estimation |
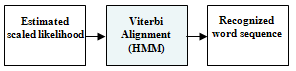 | Figure 6. Schematic Recognition Process using HMM Viterbi Dynamic Programming Search |
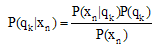 | (5) |
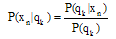 , which will be used by the Viterbi decoder, are obtained by dividing the network outputs by the prior probabilities of class qk, which are estimated by computing the relative frequency of the class qk in the training set. During the recognition P(xn) is constant.
, which will be used by the Viterbi decoder, are obtained by dividing the network outputs by the prior probabilities of class qk, which are estimated by computing the relative frequency of the class qk in the training set. During the recognition P(xn) is constant.3. Preprocessing Wavelet Denoising Stage
- We propose in this paper, a new pre-processing stage in the speech recognition system to make it robust to four types of noise. The block diagram of the proposed scheme is shown in figure 7. However, it is well known that, in Fourier based signal processing, the out of band noise can only be removed by applying a linear time invariant filtering approach. But, it cannot be removed from the portions where it overlaps the signal spectrum. The denoising technique used in the wavelet analysis is based on an entirely different idea and assumes the amplitude rather than the location of the spectrum of the signal to be different from the noise. The localising property of the wavelet is helpful in thresholding and shrinking the wavelet coefficients that helps in separating the signal from noise[4]. The denoising by wavelet is quite different from traditional filtering approaches because it is non-linear, due to a thresholding step.
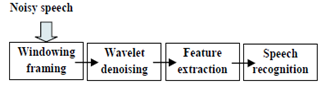 | Figure 7. Block Diagram of the Recognition System with Denoising |
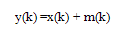 | (6) |
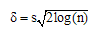 | (7) |
4. Experimental Results
4.1. Phonetic Recognition System
4.1.1. Results with Clean Speech
- The phone recognizer was trained and tested with TIMIT database[20]. All trainings were carried out using 100 phonemes of clean data. A set of 50 phonemes was used for testing. In case of tests with noisy speech, those clean test speech files were contaminated by an additive noise extracted from Noisex-92 database[3]. The temporal average is 80 ms. MLP with only one hidden layer and N output units was used to estimate the a posteriori probabilities of the classes, given the acoustic input. Each output unit of the MLP was associated to each phone (as emission probabilities of the states of the models were tied, only one output unit was needed for each model). The acoustic input to the MLP was formed by the Mel Frequency Cepstral Coeficients (MFCC) feature vectors. The number of input neurons is therefore the product of number of MFCCs and the number of acoustic vectors. Different sizes of hidden layer neurons are tested. The training procedure of the MLP was performed using the backpropagation algorithm with a sigmoidal activated function. The criterion function was the mean squared error. Our first experiment is intended to build a connectionist and hybrid recognition systems capable to recognize 4, 5, 6, 7 and 8 clean phonemes using two kinds of acoustic features (MFCC and PLP). Tables 1 and 2 summarize the obtained results in term of recognition rate (RR) respectively achieved with the MFCC and PLP features.
|
4.1.2. Results with Noisy Speech
- Four types of noises, extracted from NOISEX-92 database, have been added to the clean signal at different signal to noise ratio (SNR) levels: The performance of the phonetic recognition system, in term of recognition rate, for PLP features is depicted in figure 8.
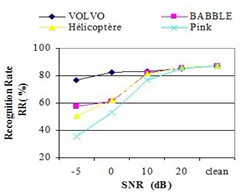 | Figure 8. Performance of Hybrid Phonetic Recognition System in an Additive Noisy Environment with PLP Features |
4.2. Isolated Word Recognition System
4.2.1. Results with Clean Speech
- The TIMIT database is phonetically transcribed using a set of 61 phones. We perform phonetic recognition on this database over a set of 39 classes that are commonly used[13]. Thus, each word in the English vocabulary could be composed by sequence of concatenating phones among the 39 phonemes. Therefore, the conceived isolated word recognition system should have a fixed input and 39 outputs which correspond to the number of output classes in the output layer of the neural network.The vocabulary set used is composed of the 10 following words: “all”, “ask”, “carry ”, “greasy”, “had”, “like”, “rag”, “she”, “that” and “wash” . The phonetic transcription of each of these words is detailed in table 3.
|
|
4.2.2. Results with Noisy Speech: Denoising with Wavelet Preprocessing Stage
- The pre-processing is based on the denoising using dicret wavelet transform and is carried out before the feature extraction phase. The recognition performance achieved by soft thresholding is evaluated and compared with a system without the proposed pre-processing. The features are based on the commonly used MFCC acoustic features. HMM based recogniser is implemented for the isolated word recognition task. Results, at SNR=-5dB, are gathered in table 5.As can be observed from figure 9, a significant improvement is obtained with the discret wavelet preprocessing stage. Although the contaminating additive noise level is very important (SNR =-5dB), a substantial average relative improvement rate in RR of 47% is obtained.
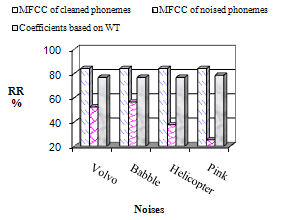 | Figure 9. Recognition Rate (RR) in % at SNR=-5dB |
5. Conclusions
- In this research, we described three acoustical modeling approaches, HMM, ANN and hybrid HMM/ANN, used in state of the art speech recognition systems. Several experiments have been carried out in order to show the effectiveness of the hybrid approach especially when compared to the connectionist one. The focus of the first experiment was to study a hybrid phone recognition system where the connectionist architecture was based on MLP with only one hidden layer. Results showed the outperformance of the hybrid system over the MLP connectionist system. However, an average relative improvement in recognition rate of 3.4% was obtained using PLP acoustic features. The second experiment was intended to recognize 10 isolated words from the TIMIT database using two kinds of connectionist models: MLP and Elman RNN in the hybrid HMM/ANN recognition system. Results showed that Elman RNN enhanced the recognition rate when compared with MLP. In fact, a relative improvement in term of recognition rate of 6.7% was obtained. Finally, we investigated the robustness of the conceived hybrid systems when tested data were contaminated by various types of additive noise at different SNR values. So, we developed a pre-processing denoising stage based on wavelet transform. Results showed an important improvement in term of RR given by such technique. However, with additive noise level SNR =-5dB, a substantial average relative improvement of 47% was obtained.
References
| [1] | A. Boubaker, M. Frikha, K. Ouni, A. Ben Hamida, 2006, “Une approche hybride neuro-markovienne pour la reconnaissance phonétique dans un milieu bruité, ” 4th Int. Conf. JTEA 06, Hammamet, Tunisia. |
| [2] | A. I. G-Moral, U. S-Urena, C. P-Moreno and F. D-Maria, 2011, “Data balancing for efficient training of hybrid ANN/HMM automatic speech recognition, ” IEEE trans. on audio, speech and lang. proc., Vol 19, No. 3, 468-481. |
| [3] | A. P. Varga et al., “The NOISEX-92 – Study on the effect of additive noise on an automatic speech recognition,” Tech. Rep., DRA Speech Research Unit, 1992. |
| [4] | D. L. Donoho, I. M. Johnston, 1995, “De-noising by soft-thresholding,” IEEE trans. Information theory, Vol. 41, No.3, 613-627. |
| [5] | E. Trentin, M. Gori, 2003, “Robust combination of neural networks and Hidden Markov Models for speech recognition,” IEEE trans. on Neural net., Vol 14 , No. 6, 1519-1531. |
| [6] | G. D. Formey, 1973, “The Viterbi Algorithm,”Proc. IEEE, (61), 7-13. |
| [7] | H. Yi, P. C. Loizou, 2004, “Speech enhancement based on wavelet thresholding the multitaper spectrum,” IEEE Trans. Speech and Audio Processing, (12), No. 1, 59-67. |
| [8] | H. Bourlard, C. J. Wellekens, 1990, “Links Between Markov Models and Multilayer Perceptrons,” IEEE Trans. on Pattern Analysis and Machine Intelligence, No. 12, 1167-1178. |
| [9] | H. Bourlard, N. Morgan , 1993, “Continuous Speech Recognition by Connectionist Statistical Methods,” IEEE Trans. on Neural Networks, (4), No. 6, 893-909. |
| [10] | H. Ketadbar and H. Bourlard, 2010, “Enhanced phone postoriors for improving speech recognition,” IEEE Trans. on audio, speech and lang. process. , Vol. 18, No. 6, 1094-1106. |
| [11] | H. Hermansky, 1990, “Perceptual linear predictive_PLP. analysis of speech,” J. Acoust. Soc. Amer., (87), No. 4, 1738–1752. |
| [12] | J. A. Bilmes, 1998, “A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixtures and hidden Markov models, ” Tech. report 97-21, univ. of Berkely, USA. |
| [13] | K. LEE and H. Hon, 1989, “Speaker-Independent Phone Recognition Using Hidden Markov Models,” IEEE Trans. on ASSP, (31), No. 11. |
| [14] | L.R. Rabiner, 1989, “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition,’’ Proc. IEEE, (77), No. 2, 257–285. |
| [15] | L. R. Rabiner and B. Juang, Fundamentals of Speech Recognition,” Prent. Hall, Engl. Cliffs, New Jersey, USA, 1993. |
| [16] | M. Frikha, “Approche Markovienne pour une reconnaissance robuste de mots isolés dans un environnement acoustique variable, ’’ PhD thesis, National School of Engineering of Sfax, Feb. 2007, Tunisia. |
| [17] | M. Frikha, A. Ben Hamida and M. Lahyani, 2011, “Hidden Markov Models (HMMs) isolated word recognizer with the optimization of acoustical analysis and modeling techniques,’’ Int. Jou. of Physical Sciences,Vol. 6(22), 5064-5074 |
| [18] | R. P. Lippmann, 1987, “An introduction to computing with neural nets,” IEEE ASSP Magazine, 4-22. |
| [19] | S.B. Davis and P. Mermelstein, 1980, “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences,” IEEE Trans. Acoust. Speech Signal Process., (28), No. 4, 357– 366. |
| [20] | S. Masmoudi, M. Frikha, A. Ben Hamida and M. Chtourou, 2010, “Efficient MLP constructive algorithm using neuron recruiting approach for isolated word recognition, ” Int. Jour. of Speech Technol., Vol. 14, No 1,1-10. |
| [21] | S. Renals, N. Morgan, H. Bourlard. M. Cohen, H. Franco, 1994, “Connectionist Probability estimators in HMM Speech Recognition ,” IEEE Trans. on Speech and Audio Process., (2), No. 1, Part II, 161-174. |
| [22] | O. Farooq, S. Datta, 2001, “Robust features for speech recognition based on admissible wavelet packet,” Electronics letters, (37), No. 5, 1554-1556. |
| [23] | O. Farooq, S. Datta, 2003, “Wavelet-based denoising for robust feature extraction for speech recognition, ” IEEE Electronics letters, (39), No. 1, 163-165. |
| [24] | P. Pujol, S. Pol, C. Nadeu, A. Hagen, H. Bourlard, 2005, “Comparison and Combination of Features in a Hybrid HMM/MLP and a HMM/GMM Speech Recognition System,” IEEE Trans. on Speech and Audio Processing, (13), No. 1, 14-22. |
| [25] | The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus (TIMIT) Training and Test Data and Speech Header Software NIST Speech Disc CD1-1.1 October 1990. |
| [26] | Z. Valsan, I. Gavat, B. Sabac, O. Cula, 2002, “Statistical and Hybrid Methods for Speech Recognition in Romanian,” Int. Journal of Speech Technology, No. 5, 259-268. |