-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2011; 1(1): 37-42
doi: 10.5923/j.ajis.20110101.06
Knowledge Discovery from Repository of Web Information
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLKristina Machova , Dominika Fodorová
Department of Cybernetics and Artificial Intelligence, Technical University of Košice, Košice, 04200, Slovakia
Correspondence to: Kristina Machova , Department of Cybernetics and Artificial Intelligence, Technical University of Košice, Košice, 04200, Slovakia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Paper focuses on the knowledge discovery from repository of web information and subsequent knowledge relationship discovery within the integrated data. The information repository model is described in it. The contribution introduces various approaches to knowledge relations discovery like the model creation, the exact comparison and the dynamic comparison. The implementation of the introduced approaches – WKID system – is also described. The paper contains also a comparison to similar approaches. The results of experiments with the system are described and discussed.
Keywords: Semantic Web, Integration of Information, Knowledge Discovery, Relations Discovery, WKID System
Cite this paper: Kristina Machova , Dominika Fodorová , "Knowledge Discovery from Repository of Web Information", American Journal of Intelligent Systems, Vol. 1 No. 1, 2011, pp. 37-42. doi: 10.5923/j.ajis.20110101.06.
Article Outline
1. Introduction
- The Internet is a real phenomenon of these days. In spite of massive usage of the web, it suffers from many problems. The main problems of web usage according to reference[1] are the following: high recall connected with low precision, low or even zero recall, search results being web pages and not searched information, and search results depended on a used vocabulary. Solutions of these problems need intelligent approaches to information processing in semantically enriched web[6].The most popular browsers try to solve the problem with low precision of search results using page ranking and subsequent ordering the retrieved pages according to this rank. This solution supposes that web user would read only some of the first found pages and so it is important to locate the more precise web pages on the top of the resulting page list.The second problem with low or even zero recall requires refining of web searching and understanding of user needs. A solution to this problem can be represented by semantic search according[2]. The semantic search can be an appropriate tool for making search results independent from used vocabulary. Mainly such semantic technologies as metadata (XML, RDF documents) and ontology (OWL documents) can be used for these purposes[9]. Ontology can represent the vocabulary of all words used in tags of RDF documents. Understanding of user needs in the frame of the semantic web requires also information integration according[3]. Information integration is an “ingredient” of semantic search, which would be able to recognize, that two pieces ofinformation presented in various forms have the samemeaning. This paper focuses on information integration from RDF web documents.The last problem is related with the fact that web search results are provided only in the form of web pages. People usually start searching web because of their information needs. They search for exact information instead of only web pages the information is buried somewhere within them. One attempt to cope with this problem is represented by the Wolfram Alpha system in reference[10], which formulated “answers” on web user demands in the form of selected information extracted from web pages. It has some drawbacks. For example, it is strong only in some domains (e.g. mathematics, geography and economics) and it needs the creation of large databases before. This creation means rather time consuming preparation activity.
2. Information Repository Model
- The repository model is a system, which enables data storage and subsequent access to these data using queries. These queries can be based on specialization (which object corresponds to conditions from query) as well as on generalization (which facts are valid for all objects corresponding to queries). This system uses a binary matrix for representation of attributes and their values. Some data are served from a source z from Z. Let us assume the scheme of each source is Sz = (Az , Fz), which covers at least a list of attributes Az and functional relations Fz (Az x Az) between attributes. Let these data are represented in the form of attribute – value pairs from a range of values Az x Dz, where Dz represents all values (e from E) covered by the source z. The data of this source can be represented as an instance of functional relations f from Fz using implications ei →ej between elements. These implications for each source l can be expressed using a binary matrix of the repository Φl = [Φlij] defined in equation (1):
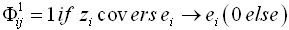 | (1) |
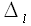 = [ δlij ] of active domains of the attributes of the source
= [ δlij ] of active domains of the attributes of the source 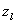 can be expressed as in equation (2):
can be expressed as in equation (2):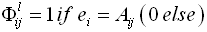 | (2) |
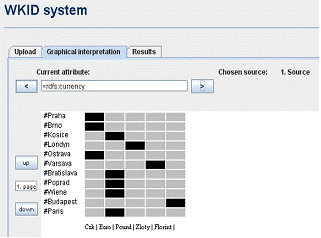 | Figure 2. The graphical interpretation of data in WKID system. |
3. Comparison to Similar Approaches
- Similar approach was used in[4], where a transposed matrix was also generated for querying the represented data. Our approach is different. No transposed matrix is used and the binary repository matrix is modified. In our approach all information got from an RDF source is downloaded in the first thick row of sub- matrixes. This representation is used because of the possibility to create effective query algorithms performing over this structure.
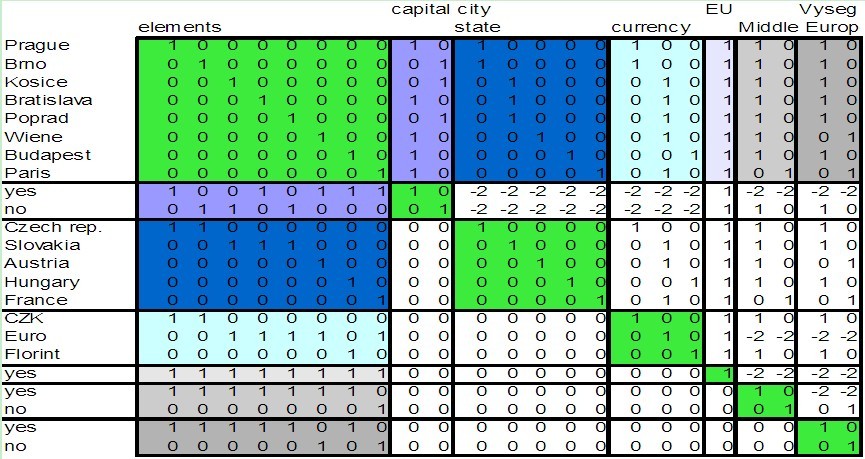 | Figure 1. A sample of binary repository matrix as a data model. |
4. Knowledge Relations Discovery
- Reference[7] introduces approaches to knowledge mining from text documents, which can be from web area. Our approach differs from it. We transform RDF documents from web into binary repository matrix and consequently discover knowledge from this matrix. The information repository model affords opportunity to process data and to discover information on different levels. At first, two basic principles have to be distinguished: local and global point of view. On the local level, various methods for knowledge extraction and discovery from one or more sources are applied. On the global level, some conclusions from local level are interpreted using several techniques responsive to a user request. On the global level, higher level methods will be used for more sources processing. The local methods of the knowledge relationship discovery on various levels of processing are implemented in the WKID system. There is if-then rules generation on the first level of processing. It is implemented within “Model creation”. On the second level of processing, method “Exact comparison” is implemented and method called “Dynamic comparison” represents processing on the third level. The menu of these methods in the WKID system can be seen in Figure 3.
 | Figure 3. Menu of methods of the WKID system. |
4.1. First Level Method
- The most elementary method is the first level method for if-then rules generation, which is used during “Model creation”. This method is able to process only one source. It is used to fill empty sub-matrixes after importing data from an actual source. These sub-matrixes (illustrated in Figure 1) represent relations between attributes related to the position. The most important part of the algorithm of the first level method is connected to if-then command. It depends on the position in matrix which is supposed to be filled. This position (matrix cell) contains information about two attributes currently being compared. If all elements (towns), which have the same value of the first attribute, are in the same group, which represents values of the second attribute, then value “1” is imported to the actual position (cell) in a selected empty sub-matrix. The value “1” is written particularly into the row with actual group position and column represents value of the first attribute. The value “0” is written to all other cells in the same row in the sub matrix. The value “-2” is written to the cell, if there is no relation. This value represents the fact that the algorithm is not able to find any relation in the process of comparing of attributes. The result of this method is generation of several if-then rules, which primary can be used like inputs for more sophisticated methods.
4.2. Second Level Method
- The second level method, called “Exact comparison”, is working still only with one information source. The inputs of this method are results from the first level processing, so another source uploading is not needed and a lot of time is saved. This method investigates dependence of two attributes by monitoring their behaviour on different starting conditions. This method is looking for the same behaviour represented by similar sub matrix created within the first level processing. Figure 4 illustrates two examples – sub-matrix selected from data model in repository matrix illustrated in Figure 1. The founded couple with the same behaviour detects relation, for example relation between Middle Europe and Vinegar deducted from sub-matrixes in Figure 4.
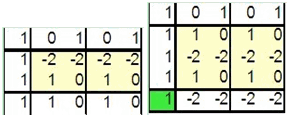 | Figure 4. Similar sub-matrixes, which were generated from data model. |
4.3. Third Level Method
- The third level method - “Dynamic comparison” uses specific groups of data from repository matrix. It distinguishes two categories: individuals and groups. The groups are created in columns from adjacent values “1” in a sub-matrix. In the process of comparison two cases can occur. At first, there is no difference in structure (values) of compared attributes and so there exist a relation between them. At second, there are some differences in the structure of compared attributes. In this case, the algorithm searches for individual value “1”, which can be connected to bigger group, as it is illustrated in Figure 5.
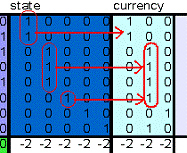 | Figure 5. Bigger group creation from given individuals in a sub matrix. |
 | Figure 6. Ordering change between seventh and eighth rows in a sub matrix. |
5. Experiments
- The designed methods were implemented within the WKID system. This system was subsequently tested. We wanted to prove in the first experiment, that our information repository model supports quick and effective information retrieval. Information retrieval was provided by the matrix and vector multiplication. The matrix played the role of an information repository and the vector represented the query used for searching relations of a particular element (attribute) to others elements in the source. The experiments with implementation were provided on a binary repository matrix, which is presented in Figure 7. This matrix represents such elements respectively attributes as: Sport, Players number, Playground, Kind, Playing area, Playing style and Tool. These attributes have the following values: Sport = {snowboarding, skiing, ice hockey, volleyball, football, basketball} Players number = {less than 4, more than 4} Playground = {snow, ice, sand, grass, hall} Kind = {winter, summer} Playing area = {cold, warm} Playing style = {with tool, without tool}Tool = {skis, board, hockey-stick, skates}.
 | Figure 7. Binary repository matrix from the sports domain. |
 | Figure 8. Data processing by the exact comparison method. |
6. Conclusions
- The novelty of this paper is in using binary matrix representation in combination with the semantic web vision and in the transforming of information from RDF documents into binary repository model. The current work obtains implementation of local level methods unable knowledge relationship discovery. Particularly, model creation and if-then rules generation, exact comparison and dynamic comparison were implemented in the WKID system. These methods were designed to process one source and generate all possible knowledge pieces from it. Deducted knowledge seems to be adequate to the real word knowledge.Our modifications of binary matrix used as a repository model, increased effectiveness of the process of relations mining from a source. Some more modifications can be implemented, for example using the binary matrix for the representation of the WKID system methods results. It can be the way how to represent meta-data from more resources. The system can be extended by an ability to discover the relations between frequently used words and so it can be used e.g. for newsgroup discussions analysis[5]. Our system enables creation of methods levels, which can be independent and they can have access to the results from various levels of sources processing (various methods). Our system also represents semantic approach to information integration because it enables synthesis and comparison of more sources from a semantic aspect. In near future, our effort will concentrate on higher level methods development and implementation and on more RDF sources processing. Also more sources formats, obvious for classical web, can be used in the WKID system in the future to enable a fluent collaboration between semantic approach and actual web. We intend to increase applicability of our system for more expansive and more complicated web domain. Maybe an idea of patterns discovery can be implemented in the WKID system. Sub-matrixes of attributes can be modified in dependence on different attributes. The structure of sub-matrixes can be simplified and can offer more unknown knowledge.
ACKNOWLEDGEMENTS
- The work presented in this paper was supported by the Slovak Grant Agency of Ministry of Education and Academy of Science of the Slovak Republic within the 1/0685/12 project ”Methods for analysis, extraction, modelling and prediction of collaborative information networks” (50%).This work is also the result of the project implementation Development of the Centre of Information and Communication Technologies for Knowledge Systems (project number: 26220120030) supported by the Research & Development Operational Program funded by the ERDF (50%).