-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Intelligent Systems
p-ISSN: 2165-8978 e-ISSN: 2165-8994
2011; 1(1): 32-36
doi: 10.5923/j.ajis.20110101.05
Cellular-based Population to Enhance Genetic Algorithm for Assignment Problems
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLH. R. Cheshmehgaz 1, H. Haron 1, M. R. Maybodi 2
1Faculty of Computer Science and Information Systems, Universiti Teknologi Malaysis (UTM), Skudai, Johor, 81310, Malaysia
2Soft Computing Laboratory, Computer Engineering and Information Technology Department, Amirkabir University of Technology (Tehran Polytechnic), Tehran, Iran
Correspondence to: H. R. Cheshmehgaz , Faculty of Computer Science and Information Systems, Universiti Teknologi Malaysis (UTM), Skudai, Johor, 81310, Malaysia.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
In this paper, we describe a new mechanism of cellular selection as an improved Genetic Algorithm for some optimization problems like Cellular Channel assignment, which have multi feasible/optimum solution per one case. Considering the problems and the nature of relationship among individuals in population, we use 2-dimension Cellular Automata in order to place the individuals onto its cells to make the locality and neighborhood on the Hamming distance basis. This idea as 2D Cellular Automata Hamming GA has introduced locality in Genetic Algorithms and global knowledge for their selection process on Cells of 2D Cellular Automata. The selection based on 2D Cellular Automata can ensure maintaining population diversity and fast convergence in the genetic search. The cellular selection of individuals is controlled based on the structure of cellular automata, to prevent the fast population diversity loss and improve the convergence performance during the genetic search.
Keywords: Genetic Algorithms, Cellular Automata, Optimization, Assignment Problems
Cite this paper: H. R. Cheshmehgaz , H. Haron , M. R. Maybodi , "Cellular-based Population to Enhance Genetic Algorithm for Assignment Problems", American Journal of Intelligent Systems, Vol. 1 No. 1, 2011, pp. 32-36. doi: 10.5923/j.ajis.20110101.05.
Article Outline
1. Introduction
- Genetic Algorithms (GAs) are used to solve difficult optimization problems like many NP-Hard Problems[1] in scientific and engineering areas. Resource distribution[2], management[3] and Assignment: Channel Assignment Problem[4], Graph Coloring Problem[5]; Multi-objective Optimization of Systems: 0/1 Multiple Knapsack Problem[6], Assembly Line Balancing Problem[7], etc. are considered to solve by GA. The main disadvantages of genetic algorithms are the disruption of good sub-solutions by crossover and mutation operations and undesired population diversity loss by selection operations, which constantly decreases the variety of its specimens. Population diversity should be preserved to prevent degeneration while maintaining the general trend of the evolution and some sort of selective pressure. Crossover operations are applied to produce new individuals from parents on the fitness which has been noticed by selection operation and Random mutations are applied to every new solution proposal in an attempt to slow down degeneration and introduce new characteristics to the population. Several mechanisms have been integrated with genetic algorithms in various ways to preserve the diversity of species. Reference[8], Matousek and Nolle have presented a binary GA with a modified mutation operator, which is based on the well-known Hill Climbing Algorithm (HCA) and the selection operator preserves the best individual from the GA population during the selection process while maintaining the positive characteristics of the standard tournament selection. Chen and Wang[9] have presented a selection method combining roulette selection with tournament selection is presented to reinforce the local search ability. In[10-12], some modified selection methods are proposed to increase the gain of resources, reliability and diversity; and decrease the uncertainty in the selection process.Locality, in Select operation, has been considered in some researches as one aim to increase the speed of finding a solution (feasible or optimum)[1]. In[14], the researcher has introduced the cellular automata to realize the locality and neighborhood in the population structure. Based on the structure of cellular automata, the selection of individuals is controlled to avoid the fast population diversity loss during the genetic search.Mostly, the problems which are mentioned in the beginning of this section have more than one optimum/feasible solution. Thin selection (built only on the fitness basis) would disrupt the good solutions (different good solutions) and produce not better more offspring for new population. Therefore, considering the detail of the specific problem and then using a thick selection (built on more detail bases), on hamming distance between parents and fitness bases, can improve the convergence performance during the genetic search.In this paper, we introduce the multi feasible/optimum feasible and cellular automata to evaluate the locality and neighborhood in the population structure, which is done by a mapping based on the hamming distances between individuals. The selection of individuals is controlled to avoid the fast population diversity loss during the genetic search. We apply the new ideas as improved GA, 2D Cellular Automata Hamming GA (2DCAHGA), on some well-known NP-hard Problem like graph coloring, Channel Assignment Problems and the outcome shows as simulation results.
2. Genetic Algorithms and Multi Solution Problems
2.1. Variety of Solutions
- Genetic algorithms are a general concept for solving complex optimization problems, which are based on manipulating a population of solutions by genetic operators like selection, crossover (recombination) and mutation[15]. For manipulating solutions by genetic operators, they have to be encoded in a form of so-called individual (or chromosomes) each of which consists of a sequence of genes. For example, a simple graph coloring (NP-hard) problem is shown in Figure 1, with 3 colors, there is a string of bits as matrix C that illustrates colors assigned to nodes of the graph (in each row of matrix C). In this solution (not exactly correct), color 1 is assigned to nodes “a” and “d," color 2 is assigned to node “c”; color 3 is assigned to node “b."
 | Figure 1. A Graph coloring Problem with 3 colors. |
 | Firuge 2. Two feasible/optimum solutions for problem in Figure 1. |
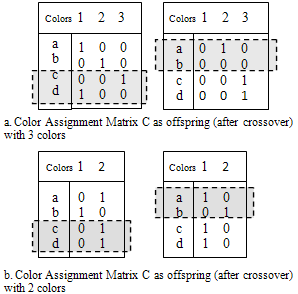 | Firuge 3. Two feasible/optimum offspring after do crossover on individuals in Figure 2. |
2.2. Hamming Distance between Binary Solutions
- Some researcher tried to modify the mechanism of selection in order to improve the GA[2-5]. In[14] Hamming distance is used for grading the difference between binary strings that have an equal number of bits. They consider a population with m individuals, and each individual includes a binary string of length l. For every pair of binary strings vi = (b1i, . . . , bli) and vj = (b1j, . . . , blj ), where b is equal to 0 or 1, the Hamming distance is defined by:
 | (1) |
 satisfies a binary ‘‘exc1usive-or” operation. To make offspring, GA selection operation selects a first according to the fitness as best (by roulette wheel selection and tournament selection techniques[15]), but to select second parent, in addition to fitness, notices the amount of hamming distance between new one and previous selected parent. Then, to make a decision to select, Modified new selections has two mechanisms: Selection-1 operation is considered for first parent and Selection-2 for the second parents. As it is following, each selection has the own mechanism but second one depend to first parent. So the value of the second parents to select can modify as follows:
satisfies a binary ‘‘exc1usive-or” operation. To make offspring, GA selection operation selects a first according to the fitness as best (by roulette wheel selection and tournament selection techniques[15]), but to select second parent, in addition to fitness, notices the amount of hamming distance between new one and previous selected parent. Then, to make a decision to select, Modified new selections has two mechanisms: Selection-1 operation is considered for first parent and Selection-2 for the second parents. As it is following, each selection has the own mechanism but second one depend to first parent. So the value of the second parents to select can modify as follows: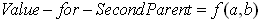 | (2) |
2.3. Comparing HGA and Classic GA
- To comparing, HGA is applied on the well-known NP-Problem in cellular mobile networks, Channel Assignment Problem (CAP)[4] that has multi feasible/optimum solution with three constraints. All three constraints are considered for the channel assignments: the co-channel constraint, the adjacent channel constraint and the co-site channel constraint. The goal of CAP is the assignment of the channel frequencies which satisfied these constraints with the lower bound number of channels (as the feasible/optimum solution). For instance, The CAP is considerate with 16 stations of BTS. The number of channels is 48, and the population size of GA is 100. The results are gathered and have been compared as is shown in Figure 4. In Figure 4.a, there are 100 runs of each algorithm with the same parameters (crossover and mutation rate =90% and 5%, population size = 100, crossover type= vertical – see Figure 2 and 3). The percentage axis in the diagram shows the number of runs that the algorithms have reached an optimum solution. Improvement of HGA in percentage of reaching an optimum solution in different iterations is sensible as compared to Classic GA (GA with no notice about Hamming Distance among individual). HGA could be mostly successful than classic GA to have a high chance to approach an optimum solution, especially in low iterations. However, most important disadvantage is a real time taken by the HGA. Both of algorithms run on Pentium 4 CPU 2.6GHz computer with 1GB RAM. As it is shown in Figure 4.b, unfortunately, the real time would be high (for 250 iterations it takes more than 6 hours). In next section, we apply 2-Dimensional Cellular Automat to reduce the real time of running HGA, and it keeps the improvement as well.
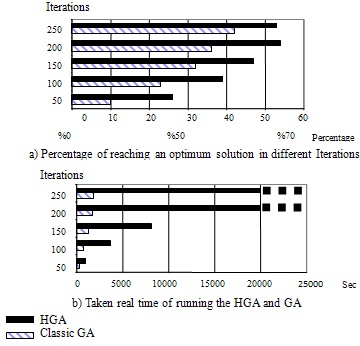 | Figure 4. Comparing HGS with GA for CA Problem (Percentage of success to reach an optimum solution / Real time). |
 | Figure 5. A part of 2DCA – C cell and its neighbors with mark #. |
3. 2 D Cellular Automata Hamming Genetic Algorithm (2DCAHGA)
3.1. Cellular Automata
- Cellular Automat (CA) is dynamical systems discrete in space, time and state variables and characterized by possession of exclusively local mechanisms of interaction. They constitute good models for the study of nonlinear complex systems. In spite of the simplicity in the definition, the set of cellular automata contains many rules with very complicated behavior.Formally, a CA is represented by the 4-tuple where:[1] Z is the finite or infinite lattice (all cells)[2] S is a finite set of cell states or values (for this article, they are individuals and their Fitness Value)[3] A is the finite neighborhood[4] f is the local transition function defined by the transition table or the rule (for this article are selection, crossover and mutation operation)The lattice is a finite or infinite discrete regular grid of cells on a finite number of dimensions. Each cell is defined by its discrete position (an integer number for each dimension) and by its discrete value. Time is also discrete. The future state of a cell (time t + 1) is a function of the present state (time t) of a finite number of cells surrounding the observed cell called the neighborhood (see Figure 5, a 2DCA).
3.2. Mapping a Population of GA onto a CA
- Before developing a 2DCAHGA, the individuals of each population are mapped onto all the cells of the cellular automaton, based on the Hamming distances.Consider a population consisting of m individuals, with binary string v. We randomly choose vi (i=1 … size of Population), to be the element C (Figure 5), then the neighborhood of C is constructed as follows. The individuals in population are sorted in ascending order of their corresponding Hamming distances to vi. Choose the first eight elements vk as the neighborhood of C, with other elements scattered outside its neighborhood, and then the whole population have been mapped onto a cellular automaton. The closest neighbors of C element are marked by # in Figure 5. They usually have smaller Hamming distance to C. This idea has introduced locality in GAs and global knowledge for their selection process.
 | Figure 6. One selection phase for cells with their own candidates. |
3.3. Steps of 2DCAHGA
- For new GA, selection operation individually does for individuals in each cell and it would have a limitation to select a mate from only cell’s neighborhoods. Each cell in CA, independently do selection and select one neighbor on the selection rules as own local transition function. This operation can be done in concurrency way too as extra advantage (in some parallel computers which can do). Each cell according to own position on CA would have some candidates to select as mate. Figure 6 illustrates one selection phase for all cells and own candidates to select (for 55 CA). The 2DCA based Hamming genetic algorithm can, in essence, be given as follows:Phase 1 (Making initial population)[1] Step 1: generate initial population. Phase 2 (Mapp-ing on 2CA)[2] Step 2: independently select an individual j from the current population. Map the selected individual j onto a cellular automaton, as described in the above subsection (previous sub section). [3] Step 3: randomly chose one filled cell of CA such that has at leas an empty neighbor, and then select individuals and map just onto empty its neighbors as described before (previous sub section).[4] Sept 4: if all cells of CA are not full, go to step 3. Phase 3 (Cellular genetic actions)[5] Step 5: independently, but they can concurrency, each cell select one of its neighbors as a mate to product a new offspring on their fitness and selection rules.[6] Step 6: in each cell, do the crossover on individual in cell and its selected neighbor, and then do a mutation then, one of the results would be kept instead of previous individual in the cell. Phase 4 (Checking to finish) [7] Step 7: if the best solution is not reached go to step 2. There are 3 most important phases to do for 2DCAHGA and at the end of cellular genetic phase, there is a new population on cells. To continue the algorithm in order to reach a better solution, the phases would be continued (phase 4).
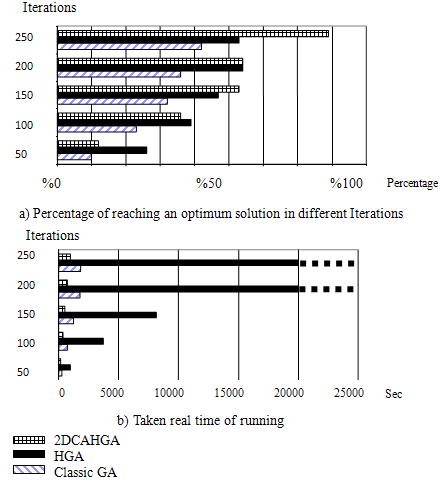 | Figure 7. Property of 2DCAHGA, HGS and Classic GA for CA Problem (Percentage of success to reach an optimum solution / Real time). |
4. Simulation Results
- The new algorithm, 2DCAHGA is applied for the same CAP has mentioned in section II. Whatever, 2DCAHGA is able to apply on many multi solution problems such 0/1 multi knapsack, graph coloring, assembly line balancing for manufacturing, placement, and, etc. as well as CAP and the results are the same. There is a noticeable improvement in the real time taken by running 2DCAGHA as compared to HGA and Classic GA in Figure 7.b. but there is not exactly specific behavior in low iterations (50 to near 150 iterations) to demonstrate that new mechanism of cellular selection would be better than the selection mechanism (in HGA) in percentage of reaching an optimum solution (see Figure 7.a). Obviously, new mechanism works well (about 90%) in high iterations of running (250 iterations) and the real time (about 1000 sec) too. Totally, the results show that the cellular selection is capable of searching feasible/optimum solutions in reasonable time and iterations.
5. Conclusions
- A two dimensional cellular automata based hamming genetic algorithm (2DCAHGA) has been developed to maintain population diversity during the genetic search, which is essential for genetic algorithms to solve the difficult multi feasible/optimum solution problems such as 0/1 multiple knapsack, channel assignment in cellular mobile network, graph coloring, assembly line balancing problem and many NP-hard problems, which have more than one feasible or optimum solution. The cellular automaton is introduced to realize the locality and neighborhood in the population structure. The selection of individuals is controlled based on the structure of cellular automata. Applications of 2CAHGA in optimization problems have shown that 2CAHGA is capable of searching for the global optimum solution of difficult nonlinear optimization problems.