-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Geographic Information System
p-ISSN: 2163-1131 e-ISSN: 2163-114X
2014; 3(1): 23-37
doi:10.5923/j.ajgis.20140301.03
A GIS Method for Spatial Network Analysis Using Density, Angles, and Shape
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLBrian Robert Sovik
Data Transfer Solutions
Correspondence to: Brian Robert Sovik, Data Transfer Solutions.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
The identification and analysis of spatial patterns in geographic phenomena with GIS are recurrently used to improve our understanding of complex linear systems. Geographers, utility engineers, and scientists concerned with complex linear systems require methods for planning, optimization, and the health and security of such systems. This research aims to promote exploration of methods that use density, angles, and the shape of polygon areas within a GIS network for pattern identification and analysis. This research is unique because it is entirely spatial and incorporates datasets for more than one point in time. Inherently, transportation, utilities and river networks contain patterns that change over time and this research explores that gap. An additional contribution includes ideas for cognitive pattern identification through comparative and quantitative analysis.
Keywords: GIScience, Road Network Analysis, Shape Analysis
Cite this paper: Brian Robert Sovik, A GIS Method for Spatial Network Analysis Using Density, Angles, and Shape, American Journal of Geographic Information System, Vol. 3 No. 1, 2014, pp. 23-37. doi: 10.5923/j.ajgis.20140301.03.
Article Outline
1. Introduction
- Within GIScience advances, methods to explore spatial patterns in Geographic Information System (GIS) networks remain vacuous. Fischer and Curtin expose the vantage in the research of networks because it represents exceptionally complex systems[1, 2]. These complex systems, or networks, support life as we know it on Earth. Illustrations of these complex systems include transportation systems, utilities, rivers and streams. Spatial patterns sought within these complex systems are defined as; "an object, or between objects that is repeated with sufficient regularity" [3]. The objective of this research is to consider new empirically tests for a new method for spatial patterns in GIS networks.Prior advances in non-spatial network pattern research disregards important aspects for understanding geographic location[2, 4, 5]. Examples of non-spatial network pattern analysis techniques primarily rely on connectivity and topological relationships, rather than geographic properties [6, 7]. Network metrics that are used to find patterns, do not embrace the spatial dimension[8, 9]. Conversely, strategies for identifying spatial patterns in GIS networks have been explored. Many of these strategies have been empirically developed to identify patterns in road networks only[10, 11, 7, 12, 13]. The opportunity is therefore provided for research on other spatial network phenomena.Previous research also demonstrates strategies that isolate only a few pattern types. These limited pattern types are: grids[10, 7, 13], strokes[14], ring roads[15], and star patterns[14, 3]. Although these are important road network pattern identification methods, they are highly sensitive to variations in the data, are computer processing intensive, and deductively work on only one pattern type at a time[10, 7, 13, 14, 15, 3]. In a practical setting, pattern types may not be known at the time of investigation, and a more inductive approach may be beneficial.Many networks are dynamic and change over time. As examples, new roads are constructed, rivers change course, and utility systems are expanded. Research to date on network patterns consider only a single temporal representation. By considering only a single point in time, the representation of the network systems, their patterns, and our understanding how the patterns change is limited. The method presented for consideration in this research will be GIS based and inductive. The method will work regardless of the spatial networks they model, the pattern types identified, and embrace multiple time series for analysis. The proposed method is called DAS. DAS stands for the variables of features that will be used to derive a single quantitative metric for pattern detection. D, stands for density, and will measure the density of nodes within the target geographic dataset. A, stands for angles, and will measure the edge angle for features. S, stands for shape and will be a calculated value for polygons that are inherent with networks for areas enclosed by the edges. The DAS method will be tested against specific non-spatial network measures, geographic phenomena, pattern types, and human cognition. To help improve the understanding of spatial patterns in GIS networks, the DAS method will make four contributions. One, the DAS method will run in GIS and focus on the spatial aspects of networks for pattern identification. "To ignore it (spatial aspects of a network) is to miss some of these systems' (spatial networks) most interesting features"[16]. Two, DAS will be analyzed against more phenomena types than roads. Three, the DAS method be analyzed against more pattern types than the grid, stroke, ring road, or star pattern. Fourth, the DAS method will be used to analyze more than a single temporal network dataset.
2. Background
- Networks are a series of connected vertices or nodes and edges or lines. "Network data structures for geographic information science (GISci) are methods for storing network data sets in a computer in order to support a range of network analysis procedures"[1]. Curtin also points out that a network can represent a transportation or communications system, a utility service mechanism, or a computer system, to name only a few network applications" [1]. Types of networks include flow networks and pure networks. Fischer, explains flow networks will contain information on the flow of something within a network and a pure network represents any networks overall structure where the main concern are the topological relationships [17]. Additional examples of networks include computer networking, social networks, utility networks, hydrology networks, and the list goes on. Critical is the idea, that a network by definition can be used to model and analyze linear features and their relationships. The elements used to make up a network, nodes (points or junctions) and edges (lines or arcs) form the basis in GIS network models. Notably, as Curtin points out, one of the earliest GIS representations used network data structures [18]. The underlying intent of networks is, "to help us understand or predict the behaviour of these systems"[6]. The theoretical basis for networks, network models and network analysis comes from principles in mathematics, topology, and graph theory[18, 6]. Important contributions from graph theory are discuses in the next section and provides the foundation for characterizing networks, network analysis, and network patter analysis.A simple graph consists of the following objects G = (V,E). In this example, G is the graph and V is the vertices (points) and E are the edges (lines). A model such as this is often depicted in the form of a picture. Figure 1, provides an example of a simple graph where there are three vertices and three edges. As a principle, vertices do not loop back upon themselves[19]. The first noted example of problem solving using graph theory was written in 1736 by Leonhard Euler. In this seminal article he used a graph to solve the Königsber Bridge Problem. In his writings, he found a solution for using seven bridges connecting two islands to the banks and one another. The problem was to traverse each bridge once without doubling back. Interestingly, he proved using graph theory that a solution to the problem did not exist[19]. Since the time of Euler graph theory and its applications has evolved. Today, network modeling persists based on the same basic principles used by Euler, however, with the advent of computers and GIS the amount of information that can be modeled and the complexities of the systems has increased. For a more in depth review, Newman's 2003 article, "The Structure and Function of Complex Networks" is recommended[6].
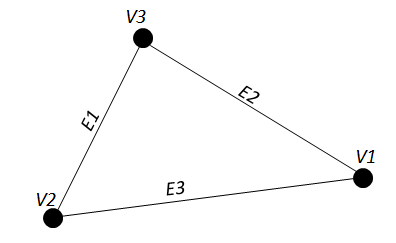 | Figure 1. A simple graph |
|

|
 | Figure 2. The Triad Representational Framework by Donna Peuquet[43] |
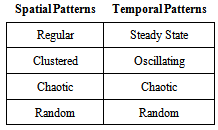
 Space and time are both continuous. This presents a challenge for GIS due to the nature of computer systems and databases[51, 43]. Regardless, for purposes of objective measurement observations of the phenomena or object must be broken down into discrete units. When selecting units, it has been found that resolution and scale must be considered [43, 52]. Discretization of phenomena are similar in some aspects with space and time yet there are some important differences. Spatially, limitations for GIS are organized in raster, vector or an extension of one of these[53]. Euclidian logic, in most cases, provides discrete grid cells or the necessary coordinate locations for features such as points, lines and polygons. Time, must also be subdivided into units. These units are often referred to as events along a continuum. What is unique about time is that it is one directional, so the idea of an absolute timeline with stored events is a viable means for storing temporal information as they relate to objects stored in GIS[54, 43]. In addition, the topological variability for time is greater with a much wider array of possible scenarios [43].If successful storage of space and time data can be accomplished the next area of active development deals with concepts of movement or patterns.[55, 45, 43]. Classifying patterns in both space and time is an important part of understanding complex phenomena, this includes the understanding of GIS networks. Consideration of temporal changes in network patterns over time in terms of not only spatial patterns, but temporal patterns would be an added benefit to GIS network analysis. The following table shows the various behaviors of objects or phenomena both spatially and temporally.
Space and time are both continuous. This presents a challenge for GIS due to the nature of computer systems and databases[51, 43]. Regardless, for purposes of objective measurement observations of the phenomena or object must be broken down into discrete units. When selecting units, it has been found that resolution and scale must be considered [43, 52]. Discretization of phenomena are similar in some aspects with space and time yet there are some important differences. Spatially, limitations for GIS are organized in raster, vector or an extension of one of these[53]. Euclidian logic, in most cases, provides discrete grid cells or the necessary coordinate locations for features such as points, lines and polygons. Time, must also be subdivided into units. These units are often referred to as events along a continuum. What is unique about time is that it is one directional, so the idea of an absolute timeline with stored events is a viable means for storing temporal information as they relate to objects stored in GIS[54, 43]. In addition, the topological variability for time is greater with a much wider array of possible scenarios [43].If successful storage of space and time data can be accomplished the next area of active development deals with concepts of movement or patterns.[55, 45, 43]. Classifying patterns in both space and time is an important part of understanding complex phenomena, this includes the understanding of GIS networks. Consideration of temporal changes in network patterns over time in terms of not only spatial patterns, but temporal patterns would be an added benefit to GIS network analysis. The following table shows the various behaviors of objects or phenomena both spatially and temporally.
|
3. Research
- Research considerations conducted by others to date have focused patterns in GIS networks. Patterns of interest include grids, ring roads, stars, and strokes as discussed by Marshall [20]. The patterns identified by Marshall have been explored through various systematic approaches to automatically have computers isolate them. These studies have been done for each pattern type in a deductive fashion. Inductive analysis based on a metric or index for repeatedly identifying these patterns is an ambitious objective. Serving as a common denominator for comparing patterns the proposed method will also look at non-spatial metrics for comparison. Additionally, a review of the detected patterns in the networks and how they change over time is an added goal. Further, this study will test the DAS method against a cognitive pattern identification survey. Ideally, this will provide new knowledge in computer and human pattern recognition. The knowledge gained in this study will determine if a new pattern detection method based on Density, Angles, and Shape can successfully isolate various patterns. Development and testing of a new method for network pattern detection expands to include these questions in depth:1.) Using simulated grid, ring road, star, and stroke patterns, can a single GIS tool provide the ability to identify these patterns reliably and repeatedly? Further, what additional patterns are detected within the targeted networks?2.) Present a study to consider geographic areas where patterns in the 2010 road centerlines and 2000 road centerline networks.3.) Present an approach for participants to identify the most prominent patterns in a series of maps showing networks, can a GIS tool identify these same patterns and quantitatively provide comparative results.
3.1. The DAS Method
- DAS is a GIS model that requires a network in GIS. DAS stands for the variables of features that will be used to derive a single quantitative metric for pattern detection. D, stands for density, and will measure the density of nodes within the target geographic dataset. A, stands for angles, and will measure the edge angle for features. S, stands for shape and will be a calculated value for polygons that are inherent with networks for areas enclosed by the edges. Further description of each variable in DAS are described below:• Density, provides how compact the location of nodes within a network. This value will be calculated for road networks using a constrained method on the network. The density measures will reside with the nodes and persist as a value from 0 to 1, where 0 is least dense and 1 is very dense.• Angles, show how the edges are oriented using angles in degrees. These values will reside with the edges and show a bearing. Values will range from 0 to 359 in the form of degrees.• Shape, will use the property of cohesiveness or compactness of polygons. In the form of an index value, the compactness score for polygons in the DAS method will range from 0 to 1. 0 will be least compact shape, while a score of 1 would be the form of a perfect circle (A circle is the most compact or cohesive shape).The baseline target patterns DAS will be calibrated with include grids, stars, circles, and strokes. Grids are regular rectangle patterns. Stars are patters that radiate from a central location. Circles or by-pass patterns typically encircle an area. Finally, strokes are longer segments where other edges feed. Strokes are sometimes described as a main road in a city. Real examples of each of these patterns are pictorially shown here:
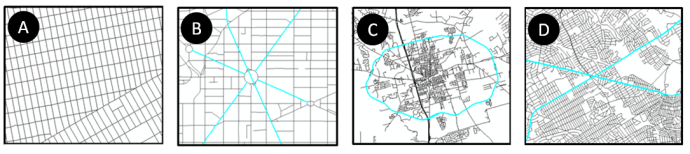 | Figure 3. Target Patterns Examples: A) Grid Pattern, B) Start Pattern, C) Circle, D) Strokes |
3.2. Technology Stack
- The DAS model should be implemented using commercial software developed by Environmental Systems Research Institute, Inc. (Esri). The version of software to be used will be 10.2. The DAS model will perform against a Geodatabase. A Geodatabase is a format for storing geographic features and data specifically created by Esri. More specifically, a network Geodatabase will be used as a starting point for managing the nodes and edges of road networks for my case study areas. Polygons will added to the Geodatabase to help identify the shapes of areas enclosed by roads. A final layer of information will be included within the Geodatabase representing patterns and DAS method metrics.
3.3. Solving DAS
- DAS should primarily be tested using three variables, density, angles and shape. Density calculation will be carried out in the Spatial Analyst Extension of ArcGIS. Consideration and testing will need to be conducted for an intersection density approach that best fits the objectives for the DAS method. Options include point density, kernel density and others. To ensure density measures are working at the scale common to road intersections for the targeted patterns. For example, if a density metric that covers too much area is used then density patterns may not be contained in results. Therefore, the density index would not be of use for pattern identification within networks. Based on the same foundation completed in Borruso's development of a Network Density Estimation[56]. The Kernel Density Estimation (KDE) will be performed.
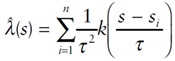 | (1) |
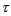 is the bandwidth"[56]. For each density measure option, a raster surface with a classification score for each cell will be produced. The class value from the raster surface will then be spatially applied back to the intersection point as an attribute. This will be done so that each node will be attributed with its own density.Angles are the second DAS metric required for the calibration of the DAS method. Angles will be computed based on the azimuth of each line using the end points. The resulting values will range between 0 to 360 degrees. Calculating the angles will be completed with the following approach:
is the bandwidth"[56]. For each density measure option, a raster surface with a classification score for each cell will be produced. The class value from the raster surface will then be spatially applied back to the intersection point as an attribute. This will be done so that each node will be attributed with its own density.Angles are the second DAS metric required for the calibration of the DAS method. Angles will be computed based on the azimuth of each line using the end points. The resulting values will range between 0 to 360 degrees. Calculating the angles will be completed with the following approach: | (2) |
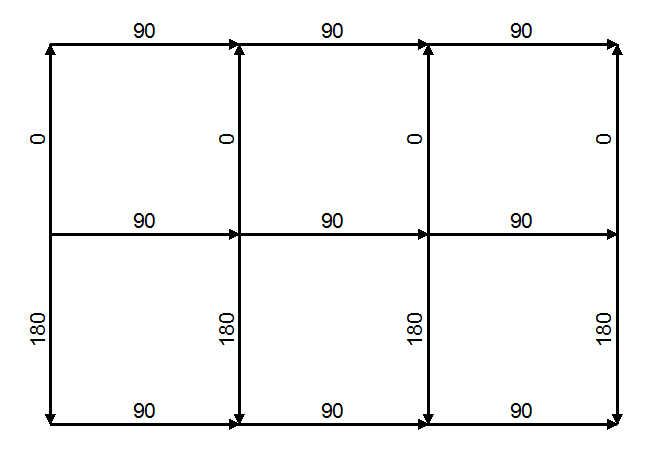 | Figure 4. A network showing with edge angles labeled |
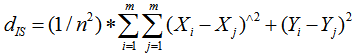 | (3) |
3.4. Pilot Study
- The simulated patterns created will be done in Euclidean space. The key importance is that each pattern will be mapped for analysis. To further check the validity of the calibration Tempe, Arizona will be included within this study. The use of a "real" city is deliberate to sample the methods of analysis against patterns that are not in the "perfect form" Additionally, through subjective observation, Tempe, Arizona offers stroke and grid patterns detectable without a GIS analysis. The following network datasets will be used to test the DAS method:1. Tempe, Arizona 2. Grid Pattern Simulation3. Star Pattern Simulation4. Ring Pattern Simulation5. Stroke Pattern Simulation6. Branch/Tree Pattern SimulationAs an example, the input will be quantified in terms of its geographic composition based on the number of features. This will be important in terms of statistical significance when comparing larger network datasets. The following table shows the feature counts for Tempe, Arizona.
|

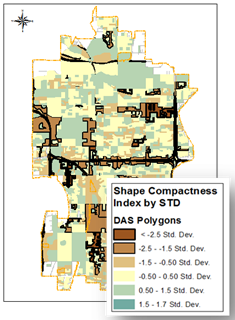 | Figure 5. Analysis Results for Tempe, Arizona |
|
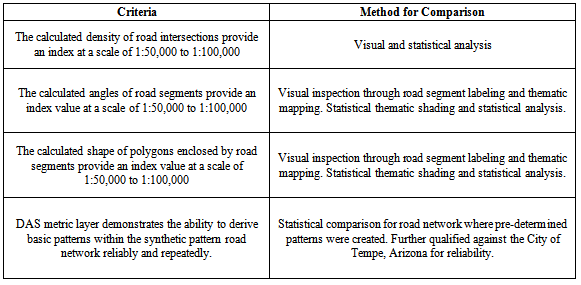
3.5. Large Urban Analysis
- To broaden the geographic scope as well as the temporal scope for the DAS model this further study put the method to the test. Locations for this case study will be the top twenty most populated 2010 Urbanized Areas found in the United States. These areas have been selected due to their large populations and the likely high quantity of road network patterns. Temporally, the DAS model will be run on the 2010 road network as well as the 2000 road network within areas delineated by the 2010 Urbanized Area Boundaries. This will provide two snapshots in time for comparative analysis. In the April 2010 US Census there were 3,592 polygons representing Urbanized Areas. These were Urbanized Areas that had a population over 50,000. 3,535 of these Urbanized Areas were located in the continental United States. The top twenty most populous will be sub selected for this case study. This selection was represents over 100 million inhabitants and 40% of the population in the United States living in Urbanized Areas. A better understanding of road network patterns (meaning more than looking at just grids or a single point in time) serves to provide new knowledge about the following Urbanized Areas and their populations as shown in the following table:
|
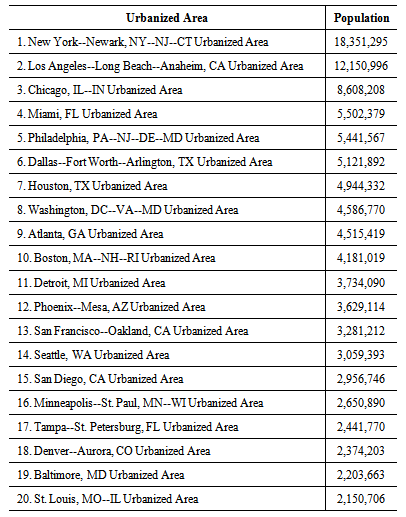
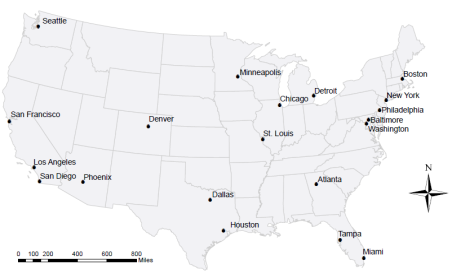 | Figure 6. Cities within the top twenty most populous Urbanized Areas in the United States (US Census Bureau - release date April, 2012) |
3.6. Required Data and Acquisition
- The data required for this study is US Census Bureau information. Decennial products will serve as a secondary source for the application of the DAS method. The US Census includes a comprehensive road centerline file by county. This data has been acquired by FTP and has been merged into road network datasets for each Urbanized Area. To ensure each Urbanized Area is fully represented a buffer of ten miles around each of the Urbanized Area was created and road centerline files were incorporated. The reason for this is to allow the DAS model to be run on the outer edges of the Urbanized Areas where Urban Geographers may gain new insight into land settlement. This is also where the comparison of the 2000 US Census road network and the 2010 US Census road network is anticipated to show space-time analysis contributions. Typical land-use or urban growth analysis is are done with remote sensing techniques or using population demographics as was conducted by Brown[190]. Alternatively, this study will provide a first GIS network based change detection method for space-time output. Road names, address ranges and road direction will not play a role in the application of DAS. Further, directional turn tables will not be required for the DAS method. Polygons, that contain road segments that do not complete the topology for enclosing an area, such as a cul-de-sac will be addressed by the tool when indexing angles for road segments and will not be included with the shape compactness index portion of the automatic processing. This is anticipated to not be an issue as these segments of road will not be important for the identification of target patterns (grid, star, ring road, and strokes).
3.7. Analysis Approach
- The data shall be analyzed by running the DAS model against each Urbanized Area road network. As the dependent variables, each urbanized area will have a number of statistical results compiled within a final DAS Polyline. The process will mirror the process conducted in the first case study, however, this will be done over a much larger area and with many more features. Three levels of investigation are anticipated. One, a visual inspection will be conducted by using thematic mapping techniques. Due to the quantitative quality of the DAS method, density, angles, and shape will be readily available for Equal Interval, Quantile, Natural Breaks, and by Standard Deviation classification methods. A second approach will be to review the DAS model results by considering a cluster score. In order to isolate certain patterns, scores will be isolated on the edges where patterns are identified. These will also be visually inspected specifically for locations where patterns are known to exist. This will take advantage of the first study's results where regular patterns were scored and will provide a likelihood score for a pattern match. Finally, the road network results will be statistically analyzed. Plotting the results of each Urbanized Area or the dependent variable against the synthetic road network or independent variable it is anticipated that the quantity of the different pattern types will be presented. This will include measures of statistical significance. Another analysis that should be carried out will be the comparison of results for 2000 and 2010 road network pattern scores from the DAS method. These results will be considered in terms of space-time pattern where results could show a regular, clustered, random or chaotic outcome. The effectiveness of this study and versatility of the DAS model will be done through statistical means. Based on the first case study, DAS metrics will serve as the baseline for "perfect scores". The study will then look at areas where a statistical relationship is present.To analyze the resulting patterns in the datasets once the DAS model is run will require statistical analysis where the dependent and independent variables will be analyzed and plotted. A comparison of the results will be conducted for a sample against the grid patterns. Additionally, alpha, gamma, and GTP analysis will be carried out for the same sample data to further test the DAS method. This will require a statistical software for analysis. As with the analysis of Tempe, Arizona, the DAS index values will reside on a polyline GIS layer. The scores will include a likelihood score for grid, star, ring road, and stroke patterns. For the processed areas, the DAS GIS method should identify road network patterns for 2010 road centerlines and 2000 road centerline in locations where change is likely to have occurred.
3.8. Human Cognition
- Another important aspect to evaluating computational pattern recognition, overlooked by many is how the computer method measures up to human analysis. A survey where participants identify the most prominent patterns in a series of maps showing road networks offer a way to check this. The objective would be to see if the DAS method quantifiably identifies patterns competitively. This means survey participants would identify a prominent pattern within a map that shows only road line work. DAS will then be run on the same geographic area. The study area locations will each be areas found in the top ten US Census most populous Urbanized Areas. The data required for this case study will already be available and analyzed. An exploratory survey with a small sample of three colleagues was conducted to assist with development and to provide a baseline for practicality. It was decided that each colleague would provide very basic information such as gender, age and the number of locations they had resided in their lifetime. Important to anonymity, each participant in an actual survey will be given an identification number that will be indexed to their name and kept in confidentiality. The reason for these questions was to ensure I would be able to identify the ten maps within their survey and could gauge qualitatively how comfortable they may be with looking at maps of locations they have never seen before. The assumption would be that individuals who had only lived in a single location may view a new map differently then someone who has moved about in their lifetime. Ten map plates were created at scales that range from 1:50,000 to 1:100,000 where census road network centerlines were the only features displayed on the maps. The area represented in each map template cover areas found within the top ten most populated urbanized areas. The road centerline files used are from the 2010 US census. Figure 7 shows samples of some of the basic map templates used in the test survey. The instructions requested that each participant highlight the "Most Prominent" pattern they see. No other instructions or prompting was provided. The results will then be compared to the same map location with the DAS method.
 | Figure 7. Sample map plates for survey instrument |
4. Results, Significance and Future Studies
- The significance of this research contributes to our body of knowledge in three ways. The first contribution is methodological. The implementation and testing of the DAS method, although an early concept, will be the first to test for pattern identification in networks using only spatial metrics for use in the GIS toolkit. Second, the DAS will provide analytical results for a number of locations using two distinct times. This will provide the inauguration of network pattern analysis that generates results worthy of future research for cause and effect based studies. Third, the research presented here will further explore cognitive aspects to human map interpretation when focusing on spatial network patterns.
 | Figure 8. Research beneficiaries |
ACKNOWLEDGEMENTS
- The author thanks members of Data Transfer Solutions, LLC for support. Special thanks to Professor Robert Balling Jr. of Arizona State University and Professor Christopher Lukinbeal of University of Arizona for moral support and encouragement.