-
Paper Information
- Next Paper
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Computer Architecture
2024; 11(5): 62-65
doi:10.5923/j.ajca.20241105.02
Received: Nov. 2, 2024; Accepted: Nov. 20, 2024; Published: Nov. 22, 2024

Evaluating Message Brokers: Performance, Scalability, and Suitability for Distributed Applications
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRahul Goel
Department of Service Cloud, Bellevue, WA, USA
Correspondence to: Rahul Goel, Department of Service Cloud, Bellevue, WA, USA.
| Email: |  |
Copyright © 2024 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Message brokers play a pivotal role in enabling communication within distributed systems by facilitating reliable, asynchronous message passing between components. This paper evaluates various message broker solutions, focusing on their performance, scalability, and suitability for diverse application needs. Key metrics such as throughput, latency, fault tolerance, and scalability are analyzed to help guide selection for enterprise-level applications. Benchmarks are presented to compare the performance of popular brokers like Apache Kafka, RabbitMQ, and ActiveMQ, with practical recommendations for selecting the right broker based on specific requirements.
Keywords: Message Broker, Distributed Systems, Scalability, Throughput, Latency, Asynchronous Communication
Cite this paper: Rahul Goel, Evaluating Message Brokers: Performance, Scalability, and Suitability for Distributed Applications, American Journal of Computer Architecture, Vol. 11 No. 5, 2024, pp. 62-65. doi: 10.5923/j.ajca.20241105.02.
Article Outline
1. Introduction
- Modern distributed applications often rely on message brokers to manage asynchronous communication between microservices and decoupled components. A message broker serves as an intermediary, ensuring that messages are reliably sent, queued, and delivered across networks and system components. Selecting the right message broker is crucial for maintaining low latency, high throughput, and fault tolerance. This paper provides a comparative evaluation of prominent message brokers like Apache Kafka, RabbitMQ, and ActiveMQ, each of which offers unique advantages depending on the application's needs [1,2].
2. Key Evaluation Criteria for Message Brokers
2.1. Throughput and Latency
- Throughput and latency are fundamental metrics for evaluating message brokers, especially in high-volume applications where quick message delivery is critical. Throughput measures the number of messages that can be processed per second, while latency measures the time taken for a message to reach its destination. For example, Apache Kafka excels in high-throughput, low-latency environments, while RabbitMQ, with its focus on reliable delivery and flexible routing, may experience slightly higher latency under similar conditions [3].
2.1.1. Throughput Considerations
- High throughput is essential for applications such as event streaming, log aggregation, and real-time analytics. Kafka’s partitioned log model allows horizontal scaling across multiple brokers, achieving higher throughput compared to RabbitMQ and ActiveMQ, which typically rely on single-node configurations or clustering [4].
2.1.2. Latency Optimization
- Latency is a critical factor in applications where real-time processing is paramount. RabbitMQ offers optimized routing with its AMQP protocol, while ActiveMQ provides efficient transport with low latency for enterprise messaging. However, Kafka’s event-streaming approach generally results in slightly higher end-to-end latency compared to point-to-point brokers like RabbitMQ [5,6].
2.2. Scalability
- Scalability determines a broker’s ability to handle increased workloads by adding more nodes to the system. Apache Kafka’s architecture supports extensive horizontal scalability with its partitioned model, ideal for large-scale applications that require high availability and fault tolerance. RabbitMQ and ActiveMQ also offer clustering capabilities, but their scalability is often more limited, making them suitable for smaller deployments [7].
2.2.1. Horizontal Scaling in Kafka
- Kafka’s partitioning allows data to be distributed across nodes, enabling seamless scaling to accommodate more consumers and producers. This is especially useful in applications requiring extensive data streaming, such as log processing systems where Kafka has proven to manage large-scale data flows efficiently [8].
2.2.2. Clustering and Fault Tolerance in RabbitMQ
- RabbitMQ’s clustering model provides scalability with automatic failover, though it is best suited for applications where message ordering and reliability take precedence over raw throughput. Clustering adds complexity to RabbitMQ's deployment, making it necessary to optimize resource allocation for optimal performance [9,10].
2.3. Fault Tolerance and Reliability
- Fault tolerance is critical in distributed systems to ensure reliable message delivery even in case of node failures. Kafka uses a distributed, replicated log structure that enhances data durability and fault tolerance, supporting multi-node replication for recovery in case of broker failure. RabbitMQ, through its mirroring feature, allows queues to be mirrored across nodes to prevent data loss, while ActiveMQ provides reliability with built-in failover and recovery mechanisms [11].
2.3.1. Replication in Kafka
- Kafka's leader-follower model allows partition leaders to replicate data to follower nodes, ensuring that message logs are retained even if a leader node fails. This setup is well-suited for mission-critical systems where data durability is essential, though it incurs additional storage costs due to replication [12].
2.3.2. Queue Mirroring in RabbitMQ
- RabbitMQ supports queue mirroring, replicating queues across nodes to provide high availability. This is particularly advantageous for applications that require strong guarantees on message persistence, though mirrored queues can introduce latency if many replicas are in use [13].
2.4. Protocols and Flexibility
- Message brokers support various protocols that determine how clients interact with the broker. Protocols like AMQP (Advanced Message Queuing Protocol), MQTT (Message Queuing Telemetry Transport), and proprietary protocols have different performance profiles and support levels across brokers. RabbitMQ’s native AMQP support enables advanced routing capabilities, while Kafka’s unique protocol optimizes performance for log-based data streaming [14].
2.4.1. AMQP in RabbitMQ
- RabbitMQ’s AMQP implementation allows advanced features like topic exchange and header-based routing, providing versatility for applications with complex routing needs. This flexibility makes RabbitMQ an appealing choice for enterprise messaging and workflow automation systems [15].
2.4.2. Kafka Protocol for Stream Processing
- Kafka’s protocol is designed for efficient data streaming, focusing on minimal overhead and high throughput. It is well-suited for stream processing applications that prioritize speed and data ordering, such as log management and event sourcing [16].
3. Performance Benchmarking and Analysis
3.1. Experimental Setup and Metrics
- To compare broker performance, we conducted tests using a synthetic workload simulating an e-commerce application with multiple producers and consumers. Metrics evaluated include throughput (messages/sec), latency (mean and P99), and fault tolerance under various failure scenarios. Kafka, RabbitMQ, and ActiveMQ were deployed in a clustered environment with comparable hardware resources to ensure fairness across benchmarks [17].
3.2. Results and Discussion
- Our benchmark results demonstrate Kafka’s superiority in throughput, achieving up to 1 million messages per second in high-throughput configurations. RabbitMQ provided lower throughput but compensated with lower latency and better message reliability in high-failure scenarios. ActiveMQ displayed moderate throughput and latency, well-suited for smaller-scale applications requiring reliable, transactional message delivery [18,19].
4. Discussion
- The evaluation reveals that while Kafka is best for high-throughput streaming, RabbitMQ excels in scenarios needing strict message reliability and routing flexibility. ActiveMQ serves as a balanced option for applications with moderate throughput and reliability requirements. Selecting the right broker depends on specific application needs, with Kafka recommended for log streaming, RabbitMQ for task scheduling and inter-service communication, and ActiveMQ for transactional workflows.
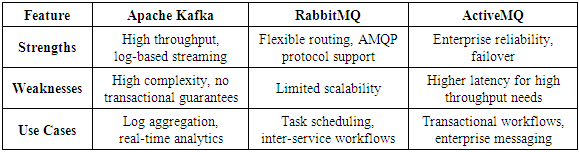
5. Comparative Analysis
- This comparison highlights the trade-offs and use-case suitability for each broker, aiding decision-making for specific application needs.
6. Best Practices for Message Brokers
6.1. Optimizing Performance
6.1.1. Use Partitioning Strategically
- For brokers like Apache Kafka, design partition keys to distribute data evenly across partitions, avoiding "hot" partitions that can cause bottlenecks.
6.1.2. Enable Compression
- Compress messages to reduce payload size, minimizing bandwidth usage and improving throughput, especially in high-traffic scenarios.
6.1.3. Leverage Batching
- Group multiple small messages into a single batch to reduce overhead and increase efficiency, particularly for systems requiring high throughput.
6.1.4. Prioritize Critical Queues
- Use priority queues for time-sensitive messages to ensure they are processed ahead of less critical ones.
6.2. Ensuring Stability
6.2.1. Deploy Redundant Configurations
- Use multi-node clusters with failover capabilities to ensure high availability. For example, replicate Kafka topics or use mirrored queues in RabbitMQ.
6.2.2. Monitor Broker Health
- Regularly track metrics like latency, throughput, and queue depth using monitoring tools like Prometheus, Grafana, or Datadog. These insights help identify and address potential issues before they impact performance.
6.2.3. Implement Circuit Breakers
- To prevent cascading failures, implement circuit breaker patterns that temporarily halt message flows to struggling consumers or producers.
6.3. Configuring Fault Tolerance
6.3.1. Use Dead-Letter Queues (DLQs)
- Set up DLQs to capture messages that cannot be processed or delivered. This allows debugging and ensures critical messages are not lost.
6.3.2. Enable Message Retention
- For brokers like Kafka, configure retention policies to store messages for a defined period, enabling recovery and replay in case of consumer failure.
6.3.3. Deploy Quorum-based Replication
- Use replication strategies that ensure data integrity and availability even if multiple nodes fail. Kafka's leader-follower replication model is an example of this approach.
7. Emerging Trends in Message Brokering
7.1. AI/ML Integration
- Message brokers are increasingly leveraging AI/ML for predictive analytics and workload optimization. By analyzing message flow patterns, AI-driven brokers can predict bottlenecks and dynamically allocate resources, enhancing system performance.
7.2. Serverless Architectures
- Serverless brokers like AWS EventBridge provide dynamic scaling and fault tolerance without requiring infrastructure management. This trend simplifies deployment and reduces operational overhead, particularly for startups and small businesses.
7.3. Enhanced Security
- Advanced encryption standards, role-based access controls, and secure protocols like TLS 1.3 are becoming standard in message brokers to address data privacy concerns in industries such as healthcare and finance.
8. Conclusions
- Message brokers are essential for maintaining asynchronous communication in distributed systems. This paper’s evaluation highlights the unique strengths of Apache Kafka, RabbitMQ, and ActiveMQ across key metrics like throughput, latency, scalability, and fault tolerance. By aligning broker selection with application requirements, developers can create robust, scalable systems optimized for their specific needs.
ACKNOWLEDGEMENTS
- This work was inspired by prior large-scale system designs that emphasized the importance of distributed systems optimization.