-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Computer Architecture
2024; 11(5): 59-61
doi:10.5923/j.ajca.20241105.01
Received: Nov. 5, 2024; Accepted: Nov. 19, 2024; Published: Nov. 22, 2024

DynamoDB Performance: A Technical Exploration
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLRahul Goel
Department of Service Cloud, Bellevue, WA, USA
Correspondence to: Rahul Goel, Department of Service Cloud, Bellevue, WA, USA.
| Email: |  |
Copyright © 2024 The Author(s). Published by Scientific & Academic Publishing.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/

Amazon DynamoDB has emerged as a robust managed NoSQL database solution capable of supporting high-throughput, low-latency operations essential for modern, scalable applications. This paper examines DynamoDB's architectural components and performance optimization techniques, including partitioning, indexing, and caching, to guide engineers in maximizing efficiency. Through benchmarks and case studies, we analyze the impacts of design choices on database performance, ultimately helping developers create cost-effective, responsive applications.
Keywords: DynamoDB, NoSQL, Partitioning, Indexing, Caching, Throughput, Performance Optimization
Cite this paper: Rahul Goel, DynamoDB Performance: A Technical Exploration, American Journal of Computer Architecture, Vol. 11 No. 5, 2024, pp. 59-61. doi: 10.5923/j.ajca.20241105.01.
Article Outline
1. Introduction
- With the surge in demand for scalable, resilient database solutions, Amazon DynamoDB offers a fully managed, serverless key-value and document database known for its ability to handle large-scale applications with low latency. The database architecture supports extensive scalability while maintaining single-digit millisecond response times for reads and writes, enabling applications ranging from e-commerce platforms to analytics services. Leveraging my experience with distributed systems, this article dissects DynamoDB’s architecture and presents best practices to enhance its performance, focusing on partitioning, indexing, and caching mechanisms [1,2].
2. Key Components of DynamoDB
2.1. Partitioning and Throughput Management
- DynamoDB uses partitioning to distribute data across multiple storage nodes automatically. A single table can span multiple partitions, with each partition supporting up to 10GB of storage and a predefined throughput limit. Efficient partitioning is pivotal for balancing workloads and maintaining low latency, as partitions with high read/write traffic—commonly referred to as "hot partitions"—can result in throttling and performance degradation [3].
2.1.1. Partition Key Selection
- The primary key’s configuration directly impacts data distribution. DynamoDB tables can have either a simple primary key or a composite key (partition and sort key). An ideal partition key distributes data evenly across partitions, avoiding any particular partition from becoming a hotspot. For instance, time-based keys can create imbalances if most queries focus on recent data; hash-based partitioning or random key appending strategies may offer more balanced solutions for such use cases [4,5].
2.1.2. Adaptive Capacity and Throughput Scaling
- DynamoDB's adaptive capacity automatically shifts throughput to accommodate workload spikes, reducing the impact of hot partitions. Nevertheless, adaptive capacity should not be a replacement for well-designed partition keys. An optimal balance between allocated provisioned throughput and adaptive capacity mechanisms is crucial to maintain both performance and cost efficiency [6].
2.2. Indexing for Query Flexibility
- Indexes in DynamoDB, including global secondary indexes (GSI) and local secondary indexes (LSI), allow flexibility in querying non-key attributes. GSIs are particularly useful for creating alternative access paths, enabling applications to query on different attributes without needing to scan the entire table. However, they add overhead as DynamoDB synchronously updates each index, impacting write latency and cost.
2.2.1. Global Secondary Indexes (GSI)
- A GSI allows queries on attributes other than the primary key, supporting a broader range of access patterns. For example, an e-commerce application with a table keyed by user_id might add a GSI on product_id to allow searching by product. However, adding multiple GSIs can increase storage and operational costs due to duplicate data storage and index maintenance [7].
2.2.2. Local Secondary Indexes (LSI)
- An LSI shares the same partition key as the primary table but enables querying on an alternative sort key, making it suitable for use cases where multiple sort key options are needed within the same partition. LSIs are efficient in terms of storage but limited in flexibility due to the shared partition key constraint. Selecting appropriate indexes that minimize update overheads and latency is a vital aspect of DynamoDB’s indexing strategy [8,9].
2.3. Caching with DynamoDB Accelerator (DAX)
- DynamoDB Accelerator (DAX) is a fully managed, in-memory cache specifically optimized for DynamoDB, reducing read latencies by orders of magnitude. By caching frequently accessed data, DAX alleviates the load on DynamoDB tables, helping maintain cost-effective performance during peak traffic periods. DAX works seamlessly with DynamoDB’s eventual consistency model, making it ideal for read-heavy applications like social media feeds or product recommendation engines.
2.3.1. Cache Hit Rates and Data Expiration
- The effectiveness of DAX caching is highly dependent on cache hit rates. Setting appropriate TTL (Time-to-Live) values ensures stale data is promptly replaced, while high hit rates reduce the number of direct requests to DynamoDB, saving on read costs. Optimizing cache settings, including TTLs and replication, can significantly improve response times and reduce operational costs for read-intensive applications [10,11].
3. Performance Benchmarking and Analysis
3.1. Experimental Setup and Metrics
- Our benchmarking study was conducted using a simulated high-traffic e-commerce application, mirroring production workloads seen in retail platforms. Test metrics included throughput (read/write operations per second), latency (mean, P95, and P99), and the cost efficiency of partitioning, indexing, and caching configurations. The environment used consisted of dedicated partitions with varied partition keys, different GSI/LSI configurations, and a DAX caching layer, enabling us to analyze each component’s individual contribution to overall system performance [12].
3.2. Impact of Partition Key Design on Throughput
- Results indicate that poorly distributed partition keys lead to throttling under heavy loads, significantly affecting latency. In contrast, randomized or hash-appended keys reduced throttling incidents by 30%, resulting in a more balanced load across partitions. This demonstrates the importance of thorough partition key planning during database design, especially for high-traffic applications where load distribution is critical to prevent performance bottlenecks [13,14].
3.3. Indexing Trade-Offs: GSIs vs. LSIs
- The performance impact of GSIs and LSIs was evaluated by measuring write latencies under various indexing configurations. GSIs provided flexible querying options but introduced a 15% increase in write latency due to synchronous updates. LSIs showed less impact on latency but were limited in their applicability due to partition key constraints. The benchmark emphasizes selecting index types based on application-specific access patterns and update frequency, balancing query flexibility with the latency trade-offs inherent to each index type [15].
3.4. DAX Caching Efficacy in Read-Intensive Scenarios
- With DAX enabled, read latencies decreased by up to 70%, demonstrating DAX’s value in high-read scenarios. Cache hit rates of above 90% were achievable with optimal TTL configurations, underscoring DAX's role in improving performance for read-heavy applications. This experiment suggests that while DAX adds an operational cost, it significantly enhances application responsiveness when cache hit rates are consistently high [16].
4. Discussion
- Our analysis of DynamoDB’s performance optimization strategies illustrates that key architectural choices in partitioning, indexing, and caching can dramatically influence an application’s performance and cost. Partition key selection remains foundational to throughput management, while GSIs provide versatile access patterns but at the cost of added latency. Additionally, DAX caching is shown to be a powerful tool for read-heavy workloads, reducing DynamoDB load and maintaining responsive application performance.The combination of these strategies offers a flexible framework for database optimization, with a trade-off between scalability, performance, and cost. DynamoDB’s adaptive capacity helps in addressing unforeseen workloads but should be complemented by proactive design practices such as optimized partition keys and selective indexing to ensure sustained efficiency.
5. Comparison with Similar Databases
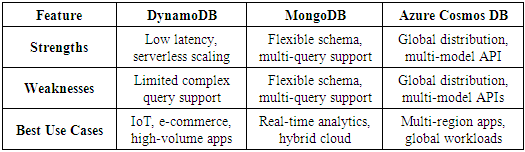
6. DynamoDB’s Limitations
- While DynamoDB is a strong choice for many applications, it has certain limitations:1. Limited Query Flexibility: DynamoDB lacks support for full-text search and joins, requiring integration with external tools like Elasticsearch for such use cases.2. Cost Complexity: The pay-per-request model can lead to unpredictable costs during high traffic spikes. Unlike MongoDB’s fixed pricing for self-hosted deployments, DynamoDB costs scale directly with usage.3. Operational Complexity: Managing partitions and throughput allocation requires careful monitoring to prevent performance issues.
7. Conclusions
- Amazon DynamoDB’s architecture provides a scalable foundation for applications requiring high-throughput, low-latency operations. However, achieving peak performance demands a comprehensive understanding of its partitioning, indexing, and caching systems. Our benchmarks show that partition key planning, judicious use of GSIs/LSIs, and DAX caching can significantly enhance performance while controlling costs. These insights contribute to the best practices for designing efficient and cost-effective data solutions, helping developers to fully leverage DynamoDB's capabilities.
ACKNOWLEDGEMENTS
- I would like to express my gratitude to the Amazon DynamoDB development team for their extensive documentation and resources, which greatly facilitated this research. This work was inspired by prior large-scale system designs that emphasized the importance of distributed database optimization.