-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Computer Architecture
2012; 1(3): 37-50
doi: 10.5923/j.ajca.20120103.01
A Survey on Computer System Memory Management and Optimization Techniques
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTML1Department of Computer Science, University of Houston, TX 77901, Victoria
2Paradigm 5756 S. Rice Avenue, TX 77081, Houston
Correspondence to: Qi Zhu , Department of Computer Science, University of Houston, TX 77901, Victoria.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
Computer memory is central to the operation of a modern computer system; it stores data or program instructions on a temporary or permanent basis for use in a computer. However, there is an increasing gap between the speed of memory and the speed of microprocessors. In this paper, various memory management and optimization techniques are reviewed to reduce the gap, including the hardware designs of the memory organization such as memory hierarchical structure and cache design; the memory management techniques varying from replacement algorithms to optimization techniques; and virtual memory strategies from a primitive bare-machine approach to paging and segmentation strategies.
Keywords: Memory Hierarchy, Memory Organization and Management, Memory Optimization
Cite this paper: Qi Zhu , Ying Qiao , "A Survey on Computer System Memory Management and Optimization Techniques", American Journal of Computer Architecture, Vol. 1 No. 3, 2012, pp. 37-50. doi: 10.5923/j.ajca.20120103.01.
Article Outline
1. Introduction
- Computer memory system is a necessity for any modern computer system. The notation on computer memory usually refers to main memory or primary memory, which temporarily holds the data and instructions needed in process execution by the Central Processing Unit (CPU). Nowadays computer memory system is a hierarchical structure including ROM, RAM, Cache, virtual memory, a perfect memory organization is one that has unlimited space and is infinitely fast so that it does not limit the processor, which is not practically implementable such as Universal Turing Machine[100]. In reality, there is an increasing gap between the speed of memory and the speed of microprocessors[50]. In the early 1980s, the average access time of memory was about 200 ns, which was nearly the same as the clock cycle of the commonly used 4.77 MHz (210 ns) microprocessors of the same period. Three decades passed, the typical speed of a home microprocessor is 4 GHz (0.25 nanosecond), however, memory access time is just around 10 nanoseconds. Thus, the growing processor - memory performance gap becomes the primary obstacle to improve computer system performance[65].This paper surveys computer memory management strategies and various memory optimization techniques in order to improve computer system performance. In section 2, the hardware designs of the memory organization such as memory hierarchical structure and cache design are studied.Followed by the memory management techniques vary from replacement algorithms to optimization techniques in section 3; finally in section 4, virtual memory strategies from a primitive bare-machine approach to paging and segmentation strategies are reviewed.
2. Memory Architecture Designs
- In this section, we start by looking at the design of the memory organization in modern computer systems to facilitate the performance optimization.
2.1. Memory Hierarchical Structure
- Memory was just a single-level scheme for early computers. However, while computers became faster and computer programs were getting bigger, especially multiple processes that were concurrently executed under the same computer system, a single main memory that was both fast enough and large enough had not really been available. As a result, memory hierarchical structure was designed to provide with rather fast speed at low cost considering of economic and physical constraints[11, 62]. Because of the cost-performance trade-offs, the memory hierarchy of modern computers usually contains registers, cache, main memory, and virtual memory. The concept of memory hierarchy takes advantage of the principle of locality[30], which states that accessed memory words will be referenced again quickly (temporal locality) and that memory words adjacent to an accessed word will be accessed soon after the access in question (spatial locality). Loops, functions, procedures and variables used for counting and totalling all involve temporal locality, where recently referenced memory locations are likely to be referenced again in the near future. Array traversal, sequential code execution, modules, and the tendency of programmers (or compilers) to place related variable definitions near one another all involve spatial locality - they all tend to generate clustered memory references. The principle of locality is particularly applicable to memories for two reasons. First, in most technologies, smaller memories are faster than larger memories. Second, larger memories need more steps and time to decode addresses to fetch the required data.
2.2. Cache
- In modern computer systems, caches are small, high-speed, temporary storage areas to hold data duplicating original values stored in main memory which are currently in use[94], where the original data is expensive to access compared to the cost of accessing from the cache. The success of cache memories has been explained of exploiting the “principle of locality”[28, 30]. When a CPU needs a particular piece of information, it first checks whether it is in the cache. If it is, the CPU uses the information directly from the cache; if it is not, the CPU uses the information from the memory, putting a copy in the cache under the assumption that it will be needed again soon (temporal locality). Information located in cache memory is accessed in much less time compared to that located in memory. Thus, a CPU spends far less time waiting for instructions and data to be fetched and/or stored.To be cost-effective and to lookup of data efficiently, caches have limited size. Many aspects of cache design are important including the selection of the cache line size, cache fetch algorithm, placement algorithm, and replacement policy[46, 56].
2.2.1. The Cache Line
- The cache line is the fixed-size block of information transferred between the cache and the main memory; selecting the appropriate line size is crucial of the cache design[95].Small line sizes have several advantages: 1) the transmission time for moving the whole line from main memory to cache is obviously shorter than that for a long line. 2) The small line is less likely to have unneeded information, only a few extra bytes are brought in along with the actually requested information. On the other hand, large line sizes have also a number of benefits, 1) If more information in a line is actually being used, fetching it all at one time is more efficient; 2) the number of lines in the cache is smaller, so fewer logic gates and storage bits are required to keep and manage address tags and replacement status; 3) a larger line size means fewer sets in the cache, which minimizes the associative search logic.Note that the advantages above for both long and short lines become disadvantages for the other. Another criterion for selecting a line size is the effect of the line size on the miss ratio. Normally, a large line size exploits spatial locality to lower miss rates, but the miss penalty increases since the time to fetch the block has increased. In conclusion, selecting the optimum block size is a trade-off; the average value lines lie in the range of 64 to 256 bytes.
2.2.2. Placement Algorithm
- Placement algorithm determines where information is to be placed, i.e. choosing an unallocated region for a subset. In cache, mapping schemes are used to translate the main memory address into a cache location, to search the cache set, or to perform some combination of these two. The most commonly used form of placement algorithm is called set-associative mapping. It divides the cache into S sets of E lines per set. Given a memory address r(i), a mapping function f will map by f (r(i)) = s(i). When E is 1, which is known as direct mapping[22], there is only one line per set, and mapping function f is many to one, the conflict is quite high if two or more currently active lines map into the same set. When S is 1, the cache is a fully associative memory, allowing a memory block to be placed anywhere in the cache. The disadvantage of fully associative mapping is that it is slow and expensive to find a mapped block by searching all lines of the cache. An effective compromise is a combination of the above two, a trade-off between the miss rate and the miss penalty, to select the value of E in the range of 2 and 16. Studies indicate that such a range exhibits good performance at a fraction of the cost and performs almost as well as a fully associative cache[36, 91].
2.2.3. Cache Fetch Algorithm and Cache Replacement Policy
- The standard cache fetch algorithm - demand fetching - is to fetch a cache line when it is needed. If the cache is full, a cache miss means a fetch plus a replacement - to remove a line from the cache[93]. Replacement algorithms have been extensively studied for paged main memory. Even though there are some more stringent constraints for a cache memory, for example, the cache replacement algorithm must be implemented entirely in hardware and must execute very quickly, the replacement algorithms in Cache are very similar to replacement algorithms in main memory, thus we leave the discussion in section 3.Finally, some more aspects such as write through or write back policy, cache band- width, input/output, multi-cache consistency, data path, and pipelining are not mentioned in this paper but also important aspects in cache design[94].
2.3. Cache Optimization Techniques
- In this section, some cache optimization techniques are discussed to escalate the cache performance through improving hit time, increasing bandwidth, dropping miss penalty, and reducing miss rate. Compiler optimization and prefetching techniques for main memory management techniques will be discussed in next section.
2.3.1. Small and Multi-level Cache
- Cache is extremely expensive, and small cache decreases hit time but increases the miss rate[48]. Thus, many computers use multiple levels of caches to address the trade-off between cache latency and hit rate[83]. Small fast caches on chip are backed up by larger slower caches of separate memory chips. The multiple levels of caches to use could yield an overall improvement in performance[7, 73]. Some modern computers have begun to have three levels on chip cache, such as the AMD Phenom II has 6MB on chip L3 cache and Intel i7 has an 8MB on chip L3 cache[96].
2.3.2. Pipelined Cache
- Cache could be pipelined for more stages to improve the clock frequency access, which gives fast clock cycle time and high bandwidth[50]. For example, MIPS R4000 divided the cache access into three independent stages[57]. Two pipeline stages are needed to access the on-chip cache and the third one is needed to perform the tag check; the instruction tag is checked simultaneously to decode. As a result, the latency of the cache lookup and tags comparison can be dramatically decreased by pipelined cache.[71] showed that a significant performance advantage is gained by using two or three pipeline stages to fetch data from the cache for high clock rate processors.
2.3.3. Trace Cache
- A trace cache, proposed by[81], is a mechanism for increasing the instruction fetch bandwidth by storing of instructions in their dynamic order of execution rather than the static, sequential program order. Trace Cache is no longer having the problem of latency caused by generation of pointers to all of non-contiguous instruction blocks. In addition, trace cache is inherently a structure that uses repeating branch behaviour and works well for programs with repetition structures. Trace cache has the benefits to deliver multiple blocks of instructions in the same cycle without support from a compiler and modifying instruction set, also there is no need to rotate, shift basic blocks to create dynamic instruction sequence. However, the disadvantage is that a trace cache stores a lot of redundant information[10]. Pentium 4 includes trace cache to store maximally 12K decoded micro-operations, and it uses virtual addresses so no need for address translation[99]. In[78], a software trace cache is used to improve in the instruction cache hit rate and instruction fetch bandwidth; the results showed it was effectively useful for not-taken branches and long chains of sequential instructions.
2.3.4. Non-blocking Cache
- A cache miss occurs when a memory request cannot find the address in cache, which results the process stalls to degrade the system performance. In pipelined computers with out-of-order completion, the processor does not hold on a data cache miss. Multiple loads from different pipes or independent accesses can proceed in the presence of waiting misses. A non-blocking cache is employed to exploit post-miss operations by continuing to fetch during cache misses as long as dependency constraint are observed[5, 18].[32] reported non-blocking cache provided a significant performance improvement, they simulated on the SPEC92 benchmarks, and the results reduced 21% of run-time with a 64-byte, 2-way set associative cache with 32 cycle fetch latency. The Intel Pentium Pro use this technology for their L2 cache, the processor could issue up to 4 cache requests at a time[9].
2.3.5. Multibanked Caches
- Caches are often partitioned into independent banks to run in parallel so as to increase cache bandwidth and to keep up with the speed of the CPU[80]. Memory usually is split by address into the cache banks. For example, AMD Athlon 64 has 8 banks, and each cycle it can fetch two 8-byte data from different banks. However, at the same time only one access is allowed to the same bank that is single-ported, such as MIPS R10000 Superscalar Microprocessor[104].Since the mapping of addresses to banks affects the performance, the simplest mapping is called sequential interleaving to spread the block addresses sequentially across the banks.[20] also proposed vertical interleaving to divide memory banks in a cache into vertically arranged sub-banks. The result showed up to 48% reduction in maximum power density with two banks and up to 67% reduction with four banks on running Alpha binaries.
2.4. Some Real Examples
- Table 1 lists and compares parameters of the multilevel caches for some real desktop and server systems by optimizing the performance and considering the cost.
3. Memory Replacement Strategies and Some Optimization Techniques
- As one of the memory management strategies, memory replacement strategy is heavily studied for paging in virtual memory systems. Both virtual memory and paging will be discussed thoroughly in next section. In this section, we introduce the different memory replacement algorithms and also discuss some memory optimization techniques.
3.1. Replacement Strategies
- In a paged virtual memory system, when all of the page frames are occupied and a process references a non-resident page, the system should not only bring in a new memory page from auxiliary storage, but select first a victim page to be replaced by the incoming page. Pages swapped out of the main memory must be chosen carefully, otherwise it causes redundant memory reads and writes if a page is immediately requested again after it has been removed from memory, and system performance will degrade for a lot of the references of the secondary storage device.The replacement algorithms can be divided into static page replacement algorithms, dynamic page replacement algorithms, and working set algorithms.
3.1.1. Static Page Replacement Algorithms
- Static page replacement algorithms all assume that each program is allocated a fixed amount of memory when it begins to execute, and does not request further memory during its lifetime.Optimal replacement algorithm (also called OPT or MIN) replaces the page that will not be referenced again until furthest in the future or has the longest number of page requests before it is referenced[3, 77]. Use of this replacement algorithm guarantees the lowest possible page-fault rate for a fixed number of frames. However, the OPT algorithm is impractical unless you have full prior knowledge of the reference stream or a record of past behaviour that is incredibly consistent. As a result, the OPT algorithm is used mainly as a benchmark to which other algorithms can be compared.Random replacement algorithm (RAND) simply chooses the page to be removed at random, so each page in main memory has an equal likelihood of being selected for replacement without taking into consideration of the reference stream or the locality principle. A benefit of RAND is that it makes replacement decisions quickly and fairly; however, the drawback is unreliability. As commented by[33, 42], better performance can almost always be achieved by employing a different algorithm; RAND algorithm has not been used since the 1960’s.First-In-First-Out replacement algorithm (FIFO) selects the page that has been in the system the longest (or first-in) to be removed. Conceptually, it works as a limited size queue, with items being added at the tail. When the queue is full, the first page to enter is moved out of the head of the queue. Similar to RAND, FIFO blatantly ignores trends and might choose to remove a heavily referenced page. Although FIFO can be implemented with relatively low overhead using a queue, it is rarely used because it does not take advantage of locality trends[3].A modification to FIFO that makes its operation much more useful is the second-chance and clock page replacement algorithms. The only modification here is that a single bit is used to identify whether or not a page has been referenced during its time in the FIFO queue. The second-chance algorithm examines the referenced bit of the oldest page; if this bit is off, it immediately selects that page for replacement. Otherwise, it turns off the bit and moves the page to the tail of the FIFO queue. Active pages will be kept at the tail of the list and thus remain in main memory. The clock page replacement works essentially the same as the second-chance algorithm, except arranging the pages in a circular list rather than a linear list[14]. Each time a page fault occurs, a list pointer moves around the circular list like the hand of a clock. When a page’s reference bit is turned on, the pointer will turn the reference bit off and move to the next element of the list. The clock algorithm places the new arrival page in the first page it encounters with the referenced bit turned off.Least-Recently-Used replacement algorithm (LRU) relies on a process’s recent past behaviour as an indication of the near future behaviour (temporal locality). It selects the page that has been the longest time in memory without being referenced when picking a victim. Although LRU can provide better performance than FIFO, the benefit comes at the cost of system overhead[101]. For example, one implementation of LRU algorithm - a stack algorithm - contains one entry for each occupied page frame. Whenever a page is referenced, it is removed from the stack and put on the top. In this way, the most recently used page is always at the top of the stack and the least recently used page is always at the bottom. When an existing page must be replaced to make room for an incoming one, the system replaces the entry at the bottom of the stack. The substantial overhead happens because the system must update the stack every time a page is referenced. However, modifications can be made to increase performance when additional hardware resources are available[44].Least-Frequently-Used replacement algorithm (LFU) often confused with LRU, least-frequently-used (LFU) algorithm selects a page for replacement if it has not been used often in the past. This strategy is based on the intuitively appealing heuristic that a page that is not being intensively referenced is not as likely to be referenced in the future. LFU can be implemented using a counter associated with each page, and the counter is updated each time its corresponding page is referenced; however, this can incur substantial overhead. The LFU algorithm could easily select incorrect pages for replacement. For instance, the least-frequently used page could be the page brought into main memory most recently. Furthermore, it tends to respond slowly to locality changes[47]. When a program either changes its set of active pages or terminates and is replaced by a different program, the frequency count will cause pages in the new locality to be immediately replaced since their frequency is at a much lower than the pages associated with the previous program. Because the context has changed and the pages swapped out will most likely be happening again soon (the principle of locality), a period of thrashing will likely occur.
3.1.2. Dynamic Page Replacement Algorithms
- When page allocation can change, static algorithms cannot adjust to keep the performance optimized. For example, a program rapidly switches between needing relatively large and relatively small page sets or localities[4]. Furthermore, it is incredibly difficult to find the optimal page allocation since a full analysis is rarely available to a virtual memory controller.However, dynamic paging replacement algorithms could adjust and optimize available pages based on reoccurring trends. This controlling policy is also known as prefetch paging.SEQ algorithm Glass and Cao[45] proposes a new virtual memory page replacement algorithm, SEQ. Usually SEQ works like LRU replacement, however, it monitors page faults when they occur, and finds long sequences of page faults to contiguous virtual addresses. When such sequences are detected, SEQ performs a most-recently-used re- placement that mimics OPT algorithm. For applications that have sequential behaviour, SEQ has better performance when compared to LRU; for other types of applications, it performs the same as LRU. Their simulation results on Solaris 2.4 showed that for a large class of applications with clear access patterns, SEQ performs close to the optimal replacement algorithm, and it is significantly better than LRU. For other applications, SEQ algorithm performances are quite similar to LRU algorithm.Adaptive prefetching algorithm[43, 106] present a disk prefetching algorithm based on on-line measurements of disk transfer times and of inter-page fault rates to adjust the level of prefetching dynamically to optimize the system performance.In[43], the prefetching algorithm is proposed using life-time function for a single process execution model. Theoretical model is given and an analytical approach is extended to a multiprogramming environment using a queuing network model. Simulation experiments are provided to show the effective performance of the prefetching algorithm for some synthetic traces.[106] further studies this prefetching adaptive algorithm for the multiprocessing execution models and uses trace-driven simulations to evaluate the effectiveness on real workloads. The adaptive prefetching algorithm could always keep the system efficiency and maintain the system performance optimal.Early eviction LRU (EELRU)[90] introduces early eviction LRU (EELRU), which adjusts its speed of adaption on aggregating recent information to recognize the reference behaviour of a workload. The authors prove that EELRU offers strong theoretical guarantees of performance relative to the LRU algorithm: While it can be better than LRU by a large factor, on the other side, it can never be more than a factor of 3 worse than LRU.Another adaptive dynamic cache replacement algorithm extended on EELRU is proposed based on prefix caching for a multimedia servers cache system[53]. Two LRU page lists for the prefix are stored in the cache; one maintains the prefix that has been requested only once recently, while the other maintains that has been requested at least twice recently. The simulation results show that the algorithm works better than LRU by maintaining the list of recently evicted videos.ARC and CAR algorithms ARC (Adaptive Replacement Cache) algorithm is developed by IBM Almaden Research Center in IBM DS6000/DS8000 storage controllers and works better than LRU[68]. It divides the cache directory into two lists, for storing recently and frequently referenced entries. In addition, a ghost list is used for each list to keep of the history of recently evicted cache entries. ARC’s dynamic adaption exploits both the recency and the frequency features of the workload in a self-tuning way, and it provides a low-overhead alternative but outperforms LRU across a wide range of workloads and cache sizes.CAR (Clock with Adaptive Replacement) algorithm inherits virtually all advantages of ARC[2], it uses two clocks with recency and frequency referenced entries. The sizes of the recently evicted pages are adaptively determined by using a precise history mechanism. Simulations demonstrate that CAR’s performance is comparable to ARC, but substantially better than both LRU and CLOCK algorithms.
3.1.3. Working Set Algorithms
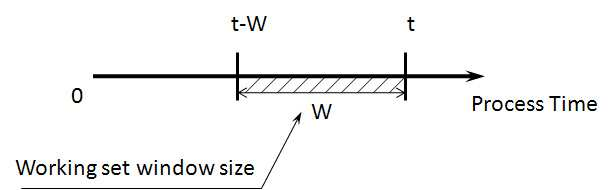
- Denning’s working set theory was developed to study what a favored subset is and how to maintain it in main memory to achieve the best performance[27, 29]. It stated that for a program to run efficiently, the system must keep the pages of program’s working set in main memory, otherwise excessive paging activity may happen to cause low processor utilization - thrashing. The working set is defined as W (t, w), where w is the process’s working set window size referenced during the process time interval t − w to current process time interval t in figure 1. A working set memory management policy tries to keep only the current working set pages in main memory to exploit the performance in the execution of that process. However, the policy is usually heuristic since it is so hard for the system to know the current working set pages in advance.
 | Figure 1. Working-set model |
3.2. Memory Optimization Techniques
3.2.1. DRAM Chip Design
- The main memory is generally made up of DRAM and has relatively large storage capacity as compared to a cache (SRAM), but it is slower, cheaper, and denser than a cache. Since the memory design needs to decrease the processor-memory gap, technologies usually are developed to have a greater bandwidth.The first innovation is a new revolutionary addressing scheme by multiplexed row and column addresses lines to cut the number of address pins in half, introduced by Robert Proebsting in Mostek MK4096 in 1975[34]. This design sent row access strobe (RAS) first and then the column access strobe (CAS), to reduce the cost and space by fitting a 4K DRAM into a 16 pin package instead of previous 22 pin package.Fast page mode is one more improvement on conventional DRAM when the row- address is held constant and data from multiple columns is read without another row access time[70]. An additional basic change is Synchronous DRAM (SDRAM), unlike the conventional DRAMs are asynchronous to the memory controller, it adds a clock signal to the DRAM interface and has a register that holds a bytes-per-request value, and returns many bytes over several cycles per request[55]. Another major innovation to increase bandwidth is DDR (double data rate) SDRAM, which doubles the data bandwidth of the bus by reading and writing data on both the rising and falling edges of the clock signal[76].The above optimization techniques exploit the high potential DRAM bandwidth with adding little cost to the system, there are many more techniques we cannot list out since of the space limitation, such as Extended Data Out (EDO) DRAM, Enhanced Synchronous (ES) DRAM, Synchronous Link (SL) DRAM, Rambus DRAMs (RDRAM), Direct Rambus (DRDRAM), Fast Cycle (FC) DRAM, etc.
3.2.2. Software Optimization
- Most of the techniques requires changing the hardware, however, pure software approach such as compiler optimization could also improve the memory performance. Code can easily be rearranged to improve temporal or spatial locality to reduce misses. For example, interchanging independent statements might reduce instruction miss rates by reducing conflict misses[85]. Another example is called branch straightening, when the compiler predicts that a branch to happen, it rearranges program code by swapping the branch target block with the block sequentially right after the branch. Branch straightening could improve spatial locality.Code and data rearrangement are mainly used on loop transformations. Loop inter-change is to exchange the order of the nested loop, making the code access the data in the order they are stored[102]. Loop fusion is a program transformation by fusing loops that access similar sets of memory locations. After fusion, the accesses are gathered together in the fused loop and can be reused easily. In[105], authors combined loop interchange and loop fusion together and applied on a collection of benchmarks, and the results indicate that their approach is highly effective and ensures better performance. When some arrays are accessed by rows and some by columns and both rows and columns are used in every loop iteration, Loop Blocking is used to create blocks instead of working on entire rows or columns to enhance reuse of local data[60].
3.2.3. Prefetching
- Demand fetching can be minimized if we can successfully predict which information will be needed and fetch it in advance - prefetching. If the system is able to make correct predications about future page uses, the process’s total runtime can be reduced[12, 92]. Prefetching strategies should be designed carefully. If a strategy requires significant re- sources or inaccurately preloads unneeded pages, it might result in worse performance than in a demand paging system. Assume that s pages are prefetched and a fraction α of these s pages is actually used (0 ≤ α ≤ 1). The question is whether the cost of the s × α saved page faults is greater or less than the cost of prepaging s × (1 − α) unnecessary pages. If α is close to 0, prefetching loses; if α is close to 1, prefetching wins.Prefetching strategies often exploit spatial locality. Furthermore, the address and size of the prefetched data are derived when considering the reference history, access pattern, and trajectory of prior memory accesses. Important criteria that determine the success of a prefetching strategy include:▪ prepaged allocation - the amount of main memory allocated to prepaging▪ the number of pages that are preloaded at once▪ the algorithm used to determine which pages are preloaded.Prefetching strategies are applied in different memory levels, such as caches[6, 75], main memory[8], and disks[43, 58, 106]. Next we discuss the categories of hardware prefetching and software prefetching.Hardware Prefetching - Both instructions and data can be prefetched. Instruction prefetch is happening normally outside the cache. Instructions following the one currently being executed are loaded into instruction stream buffer. If the requested instruction is already in the buffer, no need to fetch it again but request the next prefetch. Hardware data prefetching is used to exploit of run-time information without the need for programmer or compiler intervention. The simplest prefetching algorithm is sequential prefetching algorithm, such as one block lookahead (OBL) in HP PA7200[16]. An adaptive sequential prefetching algorithm is proposed by[23] for a dynamic k value to match k with the degree of spatial locality of the program at a particular time. Several algorithms have been developed by using special cache called reference prediction table (RPT) to monitor the processor’s referencing pattern to prefetching with arbitrary strides[1, 35]. In[19], authors found out the RPT may not be able to find an access pattern for indirect ad- dressing mode and the RPT only worked after an access pattern has been established. However, during steady loop state, the RPT could dynamically adjust its prefetching stride to achieve a good performance.Software Prefetching - Even there are some software prefetching on instructions[37], most software prefetching algorithms are working for data only, applying mostly within loops for large array calculations for both hand-coded and automated by a compiler[17, 63].[69] applied prefetching for affine array references in scientific programs, locality analysis is conducted to find the part of array references suffered from cache misses. Then loop unrolling and loop peeling to extract the cache-missing memory references are used, finally to apply prefetch instructions on the isolated cache-missing references. Jumper pointer prefetching connects non-consecutive link elements by adding additional pointers into a dynamic data structure[82]. It is effective for limited work available between successive dependent accesses. Jumper pointer prefetching can be extended to prefetch array[59], which overcomes the problem that jumper pointer prefetching is unable to prefetch the early nodes because of no pointers. To have prefetch instructions embedded in program incurring overhead, so compilers must ensure that benefits exceed the overheads.
4. Virtual Memory Management
- Processes must be executed in physical memory and each process can have limited memory space, which leads to the fundamental idea of virtual memory[88]. Gelenbe[38] also found that the number of available blocks in equilibrium is approximately fifty percent of that of blocks in use and that the fraction of storage space in use is approximately two- thirds. Virtual memory systems provide processes with the illusion that they have more memory than is built into the computer. To do this, there are two types of addresses in virtual memory system; an address used by the programmer is called the virtual address, which refers to the logical view for how a process is stored in memory. Another address used by the memory is called the physical address or real address, which refers to the physical memory address. Whenever a process accesses a virtual address, the system must translate the virtual address to a real address by using a hardware called the memory management unit (MMU). How to map virtual addresses to physical addresses is a key to implementing virtual memory systems since how mapping is done will dramatically affect the performance of the computer system. Dynamic Address Translation (DAT) is the mechanisms for converting virtual addresses to physical addresses during execution[79]. With the virtual memory, the computer can be viewed in a logical sense as an implementer of algorithms rather than in a physical sense as a device with unique characteristics.The DAT mechanism must indicate which regions of a process’s virtual address space are currently in main memory and where they are located. It is impractical for this mapping to contain entries for every address in the virtual address space, so the map- ping information must be grouped into blocks - a set of contiguous addresses in address space. The larger the average block size, the smaller the amount of mapping information. However, larger blocks can lead to internal fragmentation and can take longer to transfer between secondary storage and main memory. There are three methods: the first method -segmentation- organizes address space into different size blocks. The second method -paging- organizes memory space into fixed size blocks. The third method combines segmentation and paging approaches.
4.1. Segmentation
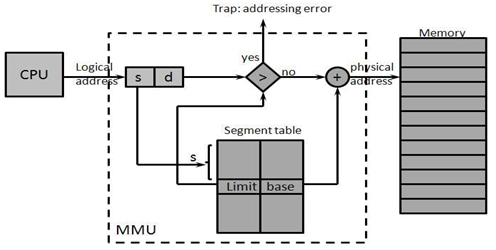
- Segmentation is a memory-management scheme that divides a program’s data and instructions into content-related or function-related blocks. Each segment consists of contiguous locations; however, the sizes of segments are various, and they are not placed adjacent to one another in main memory[25]. The advantages of segmentation are that this logical concept supports the user view of memory, and it could have arbitrary sizes (within reasonable limits). In a virtual memory segmentation system, only those segments that a program requires to execute at a certain time are maintained in main memory; the remainder of the segments reside on secondary storage. A process can execute while its current instructions and data are located in a segment that resides in main memory; otherwise, the whole segment having the instructions and data will be transferred from secondary storage as a complete unit and placed in contiguous locations in main memory.The segmented address space is regarded as a collection of named segments, each being a linear array of addresses. A virtual memory segmentation address can be referenced by an ordered pair (s, d), where s is the segment number in virtual memory in which the referenced item resides, and d is the displacement within segment s at which the referenced item is located. A segment table is used to map two-dimensional user-defined addresses into one- dimensional physical addresses. Each entry in the segment table has a segment base (a) and a segment limit (b). The segment base contains the starting physical address where the segment resides in memory, whereas the segment limit specifies the length of the segment, see the below figure.The segment table can be stored in main memory, in which each program-generated access would incur two memory references, one for the segment table and the other for the segment being referenced. A common improvement is to incorporate a small high speed associative memory into the address translate hardware. Each associative register contains a three-dimensional entry (s, a, b) and retains only the most recently used en- tries. If the associative memory contains (s, a, b) at the moment (s, d) is to be referenced, the information (a, b) is immediately available for generating the corresponding physical address; otherwise, the additional reference to the segment table is required.[87] has found that 8 to 16 associative registers are sufficient to cause programs to run at very nearly full speed.There are some more studies for segmentation,[51, 64] first implemented the address- ing schemes, and[24] further combined it into programs during execution, after that[26, 54] placed segmentation among all aspects of multi-processes computer systems. In addition,[79] combined it with dynamic storage allocation techniques and provided details for its implementations on different machines.
 | Figure 2. Segmentation Hardware |
 | Figure 3. Paging Hardware with TLB |
4.2. Paging
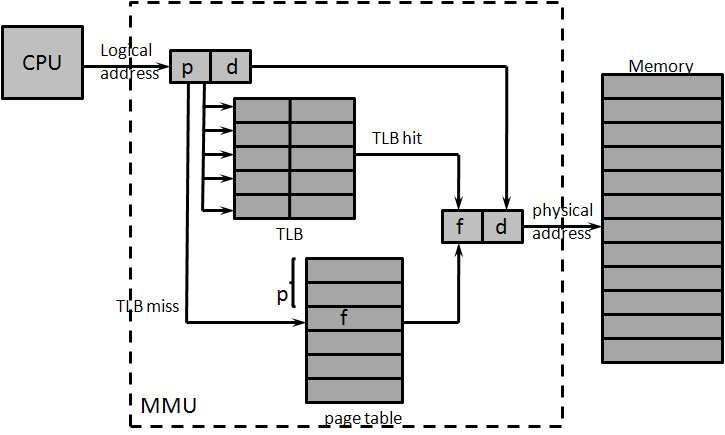
- Another method to decrease the size of mapping information is paging. Most of the memory management schemes used before (including segmentation) suffered from the significant fragmentation problem of fitting various sizes of memory chunks onto the backing store. However, paging can avoid this problem and because of its advantages over other methods, paging in its various forms is commonly used in most operating systems.Paging is implemented by breaking main memory into fixed-size blocks called frames, which are the residence for the matching size blocks of logical memory known as pages. When a process is being executed, its pages are loaded into any available memory frames from the auxiliary storage. Each page is identified by virtual address and each frame is identified by physical address, which is the location address of the first word in the frame. Similar to virtual segmentation address, a virtual memory address is an ordered two parts (p, d), where p is the page number and d is the offset within the page p. The page number p is used as an index into a page table, which contains the base address of each page in physical memory, see figure 3. Since the virtual address is a power of 2, the computation that generates the virtual address from (p, d) is trivial[25]. There is no standard page size, the page/frame size varies between 512 bytes and 16MB per page, depending on the architecture. The similar discussion about different cache line sizes can be found in section 2. Early studies, both in theoretical and in empirical, found small pages have a better performance[21, 29]. However, large page size could alleviate the high latency time of the secondary storage devices[41]. Currently, with the rapid increase of both memory and program sizes, larger page sizes have become more desirable.Paging is used by almost every computer manufacturer in at least one of products[79].Under dynamic relocation, every logical address is translated and bounded by the paging hardware to some real address. One benefit of a paged virtual memory system is that not all the pages of a process must reside in main memory at the same time: The main memory could contain only the pages that the process is currently referencing. So the page table is used to indicate whether or not a mapped page currently resides in main memory. If the page is in memory, the page table gives the value of the corresponding frame. Otherwise, the page table yields the location in secondary storage at which the referenced page is stored. When a process references a page that is not in main memory, the processor generates a page fault, which invokes the operating system to load the missing page into memory from the secondary storage. As in the implementation of segmentation, the page table can be stored in memory. Consequently, a reference to the page table requires one complete main memory cycle and a total of two memory cycles for a reference. To achieve faster speed, an associative memory - translation lookaside buffer (TLB) - to retain the most recently used page table entries can be used to achieve faster translation[49, 61]. The TLB is an integral part of today’s MMUs. Because of prohibitive cost, the TLB can hold only a small portion of most virtual address spaces. It is a challenge to pick a size to balance the cost and to have enough entries for a large percentage of reference hits in TLB.Next, we discuss some of the popular structures for the page table. Most modern computer systems support a large number of logical address spaces (232 to 264), so the page table could be excessively large and consume a significant amount of memory. For example, a 64-bit virtual address space using 4MB pages would require approximately four trillion entries! Consequently, we would not want to allocate the page table continuously in main memory. One simple solution is to divide the page table into multilevel (or hierarchical) page tables, which allow the system to store in discontiguous locations (a hierarchy) in main memory. Each level contains a table that stores pointers to one or more tables in the level below, and the last level is comprised of tables containing the page-to-frame mappings[15]. Multilevel page tables dramatically reduce memory consumption and table fragmentation. However, hierarchical page tables incur an additional memory access (or accesses) to the page mapping mechanism. A hashed page table[98] is another common approach for using address spaces larger than 32 bits. In the hash table, each entry contains a linked list of elements that hash to the same location. Each element has three fields: 1) the virtual page number; 2) the value of the mapped page frame; and 3) a pointer to the next element in the linked list. A variation of a hashed page table for 64-bit address spaces is called a clustered page table[97], which is similar to hashed page tables except that each entry in the hash table refers to several pages rather than to a single page. Thus, a single page-table entry needs to store the mappings for multiple physical frames. Clustered page tables are particularly useful in sparse address spaces. In 64-bit computer systems that contain several levels of page tables, the amount of memory consumed by mapping could be substantial. An inverted page table is proposed to be proportional to the size of physical memory, not to the size of a virtual address space. Thus, only one page table is in the system, and each entry is for each frame number of physical memory. To search through all entries of the inverted page table is inefficient; a hash table with a linked list mapping virtual addresses to an index is normally used[52, 89]. When a hash value maps an item to an occupied location, another function is applied to the hash value. The resulting value is used as the position in the table where the input is to be placed. To ensure that the item can be found when referenced, a reference pointing to this place is appended to the original hash entry. This process is repeated whenever a collision occurs. Although this approach decreases the amount of memory needed to store each page table, it increases the search time when a reference occurs. Inverted page tables are typically found in high-performance architectures, such as the Intel IA64 and the HP PA-RISC architectures.
4.3. Segmentation/Paging Combination
- Both segmentation scheme and paging scheme offer significant advantages for virtual memory organizations. However, paging does not alter the linearity of address space, the objectives that motivate segmentation; and segmentation requires that contiguous regions of various sizes be found in memory to store segments, which has been treated in the simple uniform of paging. It is possible to combine segmentation and paging together to accrue both advantages[31]. Paged segmentation was first supported in the GE 645, on which MULTICS was originally implemented[24, 72].In a segmentation/paging system, segments are arranged across multiple pages. Since not all the pages of a segment are needed in memory at once, virtual memory pages that are contiguous in virtual memory do not need to be contiguous in main memory. Usually, an ordered triple vector (s, p, d) is used to represent the virtual memory address, where s is the segment number, p is the page number within the segment s, and d is the displacement within the page p at which the item is located. Usually the information needed by the process is in main memory; however, if the segment indicates that segment s is not in main memory, a missing segment fault is generated and the operating system will locate the segment on secondary storage and load it into main memory. If the segment is in main memory, then the reference to the page table indicates the referred page is not in main memory, which initializes a page fault. Thus, the operating system gains control, locates the page on secondary storage, and loads it into main memory. When a virtual memory reference exceeds the range of the segment, a segment overflow exception is generated. As before, the segment and page tables may be stored in memory, or an associative memory may be used to speed up address formation. Finally,[40] also proposed using a finite number of page sizes to minimize the expected value of total wasted space for internal fragmentation.
5. Conclusions
- Computer memory organization has been central to the operations of the computer system since the first digital computer, the ENIAC, appeared in the early 1940s. Memory system will remain the vital part of the computers unless the conventional Von Neumann model is outdated. DRAM has been dominating the primary memory since 1971. However, the processor-memory latency gap continues to grow because the continual improvements in processor cycle speed is much faster than improvements in DRAM access latency. Many processors and memory designs, architectures, optimization techniques are developed and proposed to minimize the gap.This paper surveys computer memory management strategies and various memory optimization techniques in order to improve computer system performance. At first, the hardware designs of the memory organization such as memory hierarchical structure and cache design are studied; Memory hierarchical structure could provide with rather fast speed at low cost considering of economic and physical constraints. In addition, cache has been widely used of exploiting the principle of locality. After that, the memory management techniques vary from replacement algorithms to optimization techniques are studied. Main replacement algorithms are surveyed under the categories of static algorithms, dynamic algorithms, and working set algorithms. We also reviewed some memory optimization techniques such as DRAM chip design, software optimization, and prefetching. Finally virtual memory is studies as a technique to run extremely large processes that raise the degree of multiprogramming and increase CPU utilization.Given the constraints on the length of this paper, we have not addressed the role of memory management and optimization techniques in embedded system such as handheld devices.[66, 74] have examined data and memory optimization techniques to memory structures at different levels for embedded systems. And a survey has been conducted for techniques for optimizing memory behaviour of embedded software in[103].In the future, there is no surprise that another technology will replace DRAM in the price/performance consideration soon. For example, Magnetic RAM (MRAM) has been studied by some manufacturers. MRAM has the advantage of being non-volatile, however, how to integrate it into the memory system still face some challenges. Another choice is optical storage, which could transport the entire system memory image in a small three dimensional carrier. No matter what technology is, it should balance cost, performance, power consumption, and complexity.
References
| [1] | Baer, J.L. and Chen, T.F. (1991) An Effective On-chip Preloading Scheme to Reduce Data Access Penalty, Proceeding Supercomputing 91, Albuquerqu, NM, November, 176-186. |
| [2] | Bansal, S. and Modha, D.S. (2004) CAR: Clock with Adaptive Replacement, Proceeding of USENIX Conference on File and Storage Technologies, 187-200, San Francisco, CA. |
| [3] | Belady, L.A. (1966) A Study of Replacement Algorithms for Virtual Storage Computers, IBM Systems, 25(5), 491-503. |
| [4] | Belady, L.A. (1969) Dynamic Space Sharing in computer System, Communications of the ACM, 12(5), 282-288. |
| [5] | Belayneh, S. and Kaeli, D. (1996) A Discussion on Non-blocking/lockup-free Caches, ACM SIGARCH Computer Architecture News, 24(3), 18-25. |
| [6] | Bennett, B.T. and Franaczek, P.A. (1976) Cache Memory with Prefetching of data by Priority, IBM Tech. Disclosure Bull, 18(12), 4231-4232. |
| [7] | Bennett, B.T., Pomerene, J.H., Puzak, T.R. and Rechtschaffen (1982) R.N. Prefetching in a Multilevel Memory Hierarchy, IBM Tech. Disclosure Bull, 25(1), 88. |
| [8] | Bergey, A.L. (1978) Increased Computer Throughput by Conditioned Memory Data Prefetching, IBM Tech. Disclosure Bull, 20(10), 4103. |
| [9] | Bhandarkar, D.; Ding, J. (1997) Performance Characterization of the Pentium Pro Processor, Proceeding of High-Performance Computer Architecture, 1-5 Feb, 288-297, San Antonio, Texas, USA. |
| [10] | Black, B., Rychlik, B., and Shen, J.P. (1999) The Block-based Trace Cache, Proceeding of the 26th Annual International Symposium on Computer Architecture, 196-207. |
| [11] | Burger, D., Goodman, J.R. and Sohi, G.S. (1997) Memory Systems. The Computer Science and Engineering Handbook, 47-461. |
| [12] | Cao, P., Felten, E.W., Karlin, A.R. and Li, K. (1995) A Study of Integrated Prefetching and Caching Strategies, Proc. of ACM SIGMETRICS, 188-197. |
| [13] | Carr, W.R., Hennessy, J.L. (1981) WSClock -A Simple and Effective Algorithm for Virtual Memory Management, Proc. of the ACM SOSP, 87-95. |
| [14] | Carr, W.R. (1984) Virtual Memory Management. UMI Research Press. |
| [15] | Chang, D.C., et al (1995) Microarchitecture of HaL’s Memory Management Unit, Compcon Digest of Papers, 272-279. |
| [16] | Chan, K.K., et al. (1996) Design of the HP PA 7200 CPU, Hewlett-Packard Journal, 47(1), 25-33. |
| [17] | Chen, W.Y, Mahlke, S.A, Chang, P.P., Hwu, W.W. (1991) Data Access Microarchitectures for Superscalar Processor with Compiler-Assisted Data Prefetching, Proceeding 24th International Symposium on Microcomputing, Albuquerque, NM, November, 69-73. |
| [18] | Chen, T.; Baer, J. (1992) Reducing Memory Latency via Non-blocking and Prefetching Caches, Proceeding of ACM SIGPLAN Notice, 27(9), 51-61. |
| [19] | Chen, T.; Baer, J. (1994) A Performance Study of Software and Hardware Data Prefetching Schemes, Proceeding of the 21st Annual International Symposium on Computer Architecture, Chicago, IL, April, 223-232. |
| [20] | Cho, S. (2007) I-Cache Multi Banking and Vertical Interleaving, Proceeding of ACM Great Lakes Symposium on VLSI, March 11-13, 14-19, Stresa-Lago Maggiore, Italy. |
| [21] | Chu, W.W. and Opderbeck, H. (1974) Performance of Replacement Algorithms with Different Page Sizes, Computer, 7(11), 14-21. |
| [22] | Conti, C.J. (1969) Concepts for Buffer Storage, IEEE Computer Group News, 2(8), 9-13. |
| [23] | Dahlgren, F. and P. Stenstrom (1995) Effectiveness of Hardware-based Stride and Sequential Prefetching in Shared-memory Multiprocessors,Proc. First IEEE Sympo- sium on High- Performance Computer Architecture, Raleigh, NC, Jan. 68-77. |
| [24] | Daley, R., Dennis, J.B. (1968) Virtual Memory Processes, and sharing in Multics, Communication of the ACM, 11(5), 306-312. |
| [25] | Dennis, J.B. (1965) Segmentation and the Design of Multi-programmed Computer System, Journal of ACM, 12(4), 589-602. |
| [26] | Denning, P.J. and Van Horn, E.C. (1966) Programming Semantics for Multi-programmed Computations, Communications of the ACM, 9(3), 143-155. |
| [27] | Denning, P.J. (1968) The Working Set Model for Program Behavior, Communications of the ACM, 11(5), 323-333. |
| [28] | Denning, P.J. (1972) On Modeling Program Behavior, Proc Spring Joint Computer Conference, 40, 937-944. |
| [29] | Denning, P.J. (1980) Working Sets Past and Present, IEEE Transactions on Software Engineering, SE6(1), 64-84. |
| [30] | Denning, P.J. (2005) The Locality Principle, Communications of the ACM, 48(7), 19- 24. |
| [31] | Doran, R.W. (1976) Virtual Memory, Computer, 9(10), 27-37. |
| [32] | Farkas, K.I.; Jouppi, N.P.; Chow, P. (1994) How Useful Are Non-Blocking Loads, Stream Buffers, and Speculative Execution in Multiple issue Processors? Western Research Laboratory Research Report 94/8. |
| [33] | J. Feldman, Computer Architecture, A Designer’s Text Based on a Generic RISC Architecture, 1st edition, McGraw-Hill, 1994. |
| [34] | Foss, R.C. (2008) DRAM - A Personal View, IEEE Solid-State Circuits Newsletter, 13(1), 50-56. |
| [35] | Fu, J.W.C, Patel, J.H., and Janssens, B.L. (1992) Stride Directed Prefetching in Scalar Processors, Proceeding of 25th International Symposium on Microarchitecture, Portland, OR, December, 102-110. |
| [36] | Fukunaga, K. and Kasai, T. (1977) The Efficient Use of Buffer Storage, Proc. ACM 1977 Annual Conference, 399-403. |
| [37] | Galazin, A.B., Stupachenko, E.V., and Shlykov, S.L. (2008) A Software Instruction Prefetching Method in Architectures with Static Scheduling, Programming and Computer Software, 34(1), 49-53. |
| [38] | Gelenbe, E. (1971) The Two-Thirds Rule for Dynamic Storage Allocation Under Equilibrium, Information Processing Letters, 1(2), 59-60. |
| [39] | Gelenbe, E. (1973) The Distribution of a Program in Primary and Fast Buffer Stor- age, Communications of the ACM, 16(7), 431-434. |
| [40] | Gelenbe, E. (1973) Minimizing Wasted Space in Partitioned Segmentation, Communications of the ACM, 16(6), 343-349. |
| [41] | Gelenbe, E., Tiberio, P. and Boekhorst, J.C. (1973) Page Size in Demand-paging Systems, Acta Informatica, 3, 1-24. |
| [42] | Gelenbe, E. (1973) A Unified Approach to the Evaluation of a Class of Replacement Algorithms, IEEE Transactions on Computers, 22(6), 611-618. |
| [43] | Gelenbe, E. and Zhu, Q. (2001) Adaptive Control of Prefetching, Performance Evaluation, 46, 177-192. |
| [44] | Ghasemzadeh, H., Mazrouee,S., Moghaddam, H.G., Shojaei, H. and Kakoee, M.R. (2006) Hardware Implementation of Stack-Based Replacement Algorithms, World Academy of Science, Engineering and Technology, 16, 135-139. |
| [45] | Glass, G. and Cao, P. (1997) Adaptive page replacement based on memory reference behavior, Proc of the 1997 ACM SIGMETRICS, 25(1), 115-126. |
| [46] | Gibson, D.H. (1967) Consideration in Block-oriented Systems Design, Proc Spring Jt Computer Conf, 30, Thompson Books, 75-80. |
| [47] | Gupta, R.K. and Franklin, M.a. (1978) Working Set and Page Fault Frequency Replacement Algorithms: A Performance Comparison, IEEE Transactions on Comput- ers, C-27, 706-712. |
| [48] | Handy, J (1997) The Cache Memory Book, Morgan Kaufmann Publishers. |
| [49] | Hanlon, A.G. (1966) Content-Addressable and Associative Memory System - A Survey, IEEE Transactions on Electronic Computers, 15(4), 509-521. |
| [50] | Hennessy, J.L. and Patterson, D.A. (2007) Computer architecture: a quantitative approach, Morgan Kaufmann Publishers Inc., San Francisco, CA, 4th Edition. |
| [51] | ILiffe, J.K. (1968) Basic Machine Principles. American Elsevier, New York. |
| [52] | Jacob, B. and Mudge, t. (1998) Virtual Memory: Issues of Implementation, IEEE Computer, 31(6), 33-43. |
| [53] | Jayarekha, P.; Nair, T.R (2009) Proceeding of InterJRI Computer Science and Net- working, 1(1), Dec, 24-30. |
| [54] | Johnston, J.B. (1969) The Structure of Multiple Activity Algorithms, Proc. Third Annual Princeton Conf. 80-82. |
| [55] | Jones, F. et al., (1992) A New Era of Fast Dynamic RAMs, IEEE Spectrum, 43-49. |
| [56] | Kaplan, K.R. and Winder, R.O. (1973) Cache-based Computer Systems, IEEE Computer, 6(3), 30-36. |
| [57] | Kane, G. and Heinrich J. (1992) MIPS RISC Architecture, Prentice Hall. |
| [58] | Karedla, R., Love, J.S. and Wherry, B. (1994) Caching Strategies to Improve Disk System Performance, IEEE Computer, 27(2), 38-46. |
| [59] | Karlsson, M., Dahlgren, F., and Stenstrom, P. (2000) A Prefetching Technique for Irregular Accesses to Linked Data Structures, Proceeding of the 6th International conference on High Performance Computer Architecture, Toulouse, France, January, 206-217. |
| [60] | Lam, M.; Rothberg, E.; Wolf, M.E. (1991) The Cache Performance and Optimization of Blocked Algorithms, Proceeding of the Fourth International Conference on ASPLOSIV, Santa Clara, Apr, 63-74. |
| [61] | Linduist, A.B., Seeder, R. R. and Comeau,L.W. (1966) A Time-Sharing System Using an Associative Memory, Proceeding of the IEEE, 54, 1774-1779. |
| [62] | Lin, Y.S. and Mattson, R.L. (1972) Cost-Performance Evaluation of Memory Hierarchies, IEEE Transactions Magazine, MAG-8(3), 390-392. |
| [63] | Luk, C.K and Mowry, T.C (1996) Compiler-based Prefetching for Recursive Data Structures, Proceeding of 7th Conference on Architectural Support for Programming Languages and Operating Systems, Cambridge, MA, October, 222-233. |
| [64] | Mackenzie, F.B. (1965) Automated Secondary Storage Management, Datamation, 11, 24-28. |
| [65] | Mahapatra, N.R., and Venkatrao, B. (1999) The processor-memory bottleneck: problems and solutions, Crossroads, 5(3). |
| [66] | Mahajan, A.R. and Ali, M.S. (2007) Optimization of Memory System in Real-time Embedded Systems, Proceeding of the 11th WSEAS International Conference on Computers. 13-19. |
| [67] | Marshall, W.T. and Nute, C.T. (1979) Analytic modeling of working set like replacement algorithms, Proc. of ACM SIGMETRICS, 65-72. |
| [68] | Megiddo, N.; and Modha, D.S. (2003) ARC:A Self-tuning, Low Overhead Replacement Cache, Proceeding of 2nd USENIX conference on File and Storage Technologies, 115-130, San Franciso, CA. |
| [69] | Mowry, T. (1991) Tolerating Latency throughSoftware-controller Prefetching in Shared-memory Multiprocessors, Journal of Parallel and Distributed Computing, 12(2), 87-106. |
| [70] | Ng, Ray (1992) Fast Computer Memories, IEEE Spectrum, 36-39. |
| [71] | Olukotun, K., Mudge, T., and Brown, R. (1997) Multilevel Optimization of Piplelined Caches. IEEE Transactions on Computers, 46, 10, 1093-1102. |
| [72] | Organick, E.I. (1972) The Multics System: An Examination of Its Structure, MIT Press. |
| [73] | Ou, L., He, X.B., Kosa, M.J., and Scott, S.L. (2005) A Unified Multiple-Level Cache for High Performance Storage Systems, mascots, 13th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, 143-152. |
| [74] | Panda, P.R. et al (2001) Data and Memory Optimization Techniques for Embedded System, ACM Transactions on Design Automation of Electronic Systems, 6(2), 149-206. |
| [75] | Perkins, D.R. (1980) The Design and Management of Predictive Caches, PH.D dissertation, Univ of Calif., San Diego. |
| [76] | Peters, M. (2000) Enhanced Memory Systems, Personal Communications, September. |
| [77] | Prieve, B.G. and Fabry, R.S. (1976) VMIN - An Optimal Variable Space Page Re- placement Algorithm, Communications of the ACM, 19(5), 295-297. |
| [78] | Ramirez, A., Larriba-Pey, J.L., and Valero, M. (2005) Software Trace Cache, IEEE Transactions on Computer, 54(1), 22-35. |
| [79] | Randell, B. and Kuehner, C.J. (1968) Dynamic Storage Allocation Systems, Communications of the ACM, 297-305. |
| [80] | Rivers, J.A.; Tyson, G.S.; Dividson, E.S.; Austin, T.M. (1997) On High-Bandwidth Data Cache Design for Multi-Issue Processors, Proceeding of International Sympo- sium of Microarchitecture, Dec, 46-56. |
| [81] | Rotenerg, E., Bennett, S., and Smith, J.E. (1999) A Trace Cache Microarchitecture and Evaluation, IEEE Transactions on Computers, 48(2), 111-120. |
| [82] | Roth, A. and Sohi, G., (1999) Effective Jump-pointer Prefetching for Linked Data Structures. Proceeding of the 26th International Symposium on Computer Architecture, Atlanta, GA, May, 111-121. |
| [83] | Pas, R. (2002) Memory Hierarchy in Cache-Based Systems, Sun Microsystems. |
| [84] | Sadeh, E. (1975) An Analysis of the Performance of the Page Fault Frequency (PFF) Replacement Algorithm, Proc of the fifth ACM SOSP, 6-13. |
| [85] | Samples, A.D.; Hilfinger, P.N. (1988) Code Reorganization for Instruction Caches, University of California at Berkeley, Berkeley, CA. |
| [86] | Serhan, S.I. and Abdel-Haq, H.M. (2007) Improving Cache Memory Utilization, World Academy of Science and Technology, 26, 299-304. |
| [87] | Shemer, J.E. and Shippey, B. (1966) Statistical Analysis of Paged and Segmented Computer Systems. IEEE Trans. EC-15, 6, 855-863. |
| [88] | Shiell, J. (1986) Virtual memory, virtual Machines, Byte, 11(11), 110-121. |
| [89] | Shyu, I. (1995) Virtual Address Translation for Wide-Address Architectures, ACM SIGOPS Operating Systems Review, 29(4), 37-46. |
| [90] | Smaragdakis, Y., Kaplan, S. and Wilson, P. (2003) The EELRU Adaptive Replacement Algorithm, Performance Evaluation, 53(2), 93-123. |
| [91] | Smith, A.J. (1978) A Comparative Study of Set Associative Memory Mapping Algoirthms and Their Use for Cache and Main Memory, IEEE Trans. Softw. Eng, 4(2), 121-130, |
| [92] | Smith, A.J. (1978) Sequential Program Prefetching in Memory Hierarchies, IEEE Computer, 11(12), 7-21. |
| [93] | Smith, A.J. (1978) Bibliography on Paging And Related Topics, Operating Systems Review, 12(4), 39-56. |
| [94] | Smith, A.J. (1982) Cache Memories, Computing Surveys, 14(3), 473-530. |
| [95] | Smith, A.J. (1987) Line (block) Size Choice for CPU Cache Memories, IEEE Trans- actions on Computers, 36(9), 1063-1076. |
| [96] | Sondag, T. and Rajan, H. (2009) A Theory of Reads and Writes for Multi-level Caches. Technical Report 09-20a, Computer Science, Iowa State University. |
| [97] | Talluri, M., Hill, M.D. and Khalidi, Y.A. (1995) A New Page Table for 64-bit Address Spaces, Proc of SIGOPS, 184-200. |
| [98] | Thakkar, S.S. and Knowles, A.E. (1986) Ahigh-performance memory management scheme, IEEE Computer, 19(5), 8-22. |
| [99] | Tuck, N; Tullsen, D.M. (2003) Initial Observations of the Simultaneous Multithreading Pentium 4 Processor, Proceeding of Parallel Architectures and Compilation Tech- niques, Oct, 26-34. |
| [100] | A.M Turing (1937) On Computable Numbers, with an Application to the Entscheidungs problem, Proceedings of the London Mathematical Society, 42(2), 230-265. |
| [101] | Turner, R. and Levy, H. (1981) Segmented FIFO Page Replacement, Proc. of ACM SIGMETRICS on Measurement and Modeling of Computer System, 48-51. |
| [102] | Wolf, M.E., Lam, M. (1991) A Data Locality Optimizing Algorithm. Proceeding of the SIGPLAN conference on Programming Language Design and Implementation, Toronto, 26(6), 30-44. |
| [103] | Wolf, W, Kandemir, M. (2003) Memory System Optimization of Embedded Soft- ware. Proceeding of IEEE, Jan, 91(1), 165-182. |
| [104] | Yeager, K.C.(1996) The MIPS R10000 Superscaar Microprocessor, IEEE Micro, Apr., 16(2), 28-40, 1996. |
| [105] | Yi, Q. and Kennedy, K. (2004) Improving Memory Hierarchy Performance through Combined Loop Interchange and Multi-Level Fusion, International Journal of High Performance Computing Applications, 18(2), 237-253. |
| [106] | Zhu, Q., Gelenbe, E. and Qiao, Y (2008) Adaptive Prefetching Algorithm in Disk Controllers, Performance Evaluation, 65(5), 382-395. |