-
Paper Information
- Previous Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
American Journal of Computer Architecture
2012; 1(1): 6-11
doi: 10.5923/j.ajca.20120101.02
Double Cipher Implementation in a Ubiquitous Processor Chip
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLMasa-aki Fukase 1, Tomoaki Sato 2
1Graduate School of Science and Technology, Hirosaki University, Hirosaki, 036-8561, Japan
2Computer and Network Systems Center, Hirosaki University, Hirosaki University, Hirosaki, 036-8561, Japan
Correspondence to: Masa-aki Fukase , Graduate School of Science and Technology, Hirosaki University, Hirosaki, 036-8561, Japan.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
This paper focuses on improving the cipher strength of a particular ubiquitous processor HCgorilla. The reason why this is called the ubiquitous processor is due to its specific features for ubiquitous computing. Ubiquitous computing is really a leading edge trend of next generation information and communication technologies. One of the most promising solutions for ubiquitous computing applied to HCgorilla is exploiting not higher speed but parallelism. It has progressed the overall status of ubiquitous and processor techniques. The basic organization of HCgorilla follows multicore and multiple pipelines. These are Java compatible media pipelines (shortened to pipes hereafter) with sophisticated structures and cipher pipes. The cipher pipe implements transposition cipher called RAC (random number addressing cryptography) by using a hardware RNG (random number generators). Although RAC is excellent at software-transparency, it is not always sufficient for practical security. Since emerging ubiquitous environment requires strong security as well as high performance, it is also a crucial issue to enhance cipher strength. Thus, the improved HCgorilla in this study embeds two RNGs. These are used for double cipher, that is, the one for RAC and the other for a substitution cipher by data sealing. This approach promises strong cipher strength without any overhead for hardware cost, power dissipation, throughput, etc. Various aspects of the improved HCgorilla are evaluated.
Keywords: Ubiquitous Processor Chip, Hardware Cryptography, Double Cipher, Power Dissipation, Throughput
Article Outline
1. Introduction
- The advent of ubiquitous environment still demands power conscious strong security, high performance, high precision, and real time responsibility for processors. Thus, next generation processors for ubiquitous environment are desired to be developed. Strategy for the development of ubiquitous processors is to achieve higher throughput, stronger security, and lower power dissipation for large quantity of multimedia data[1-4]. The proliferation and standardization of ubiquitous technologies have given rise to serious concerns about security and privacy issues which are exacerbated by the fact that the majority of these technologies are resource constrained in terms of area and energy budgets[5-7]. This has led to increased interest in efficient implementations of cryptographic primitives[8].The authors have given challenges for the development of ubiquitous processors as follows. In order to satisfy the demand for data quantity and performance, the adoption of block ciphers is inevitable. Then, hardware cryptography is profitable to achieve power conscious strong security[9].With respect to this view point, a particular ubiquitous processor, HCgorilla has been really eligible[10]. The basic organization of HCgorilla follows multicore and multiple pipelines[11]. They are Java compatible media pipes and hardware cryptography embedded cipher pipes. By using a waved MFU (multifunctional unit) in the execution stage, the media pipe issues arithmetic instructions free from complicated scheduling[12]. This is a very sophisticated instruction level parallelism to achieve power conscious high performance[13]. The cipher pipe implements transposition cipher called RAC (random number addressing cryptography) by using a built-in hardware RNG.Although RAC is excellent at software-transparency, it is not always sufficient for practical security. Since emerging ubiquitous environment requires strong security as well as high performance, it is also a crucial issue to enhance cipher strength. Thus, this paper focuses on increasing the cipher strength of previous HCgorilla. In general, the cipher strength can be improved by increasing both the key length and kinds of bit operations, which can be seen in the improvement from DES (Data Encryption Standard) to AES (Advanced Encryption Standard)[14]. This is based on the general rule of deciphering a secret key cryptography that seeks an unknown key or password, assuming plaintext, cipher text, and encryption algorithms are open[15].The authors propose in this study a double cipher scheme with two RNGs[16]. The double cipher approach promises practically strong cipher strength by providing double kind of bit operations. The additional RNG is used for a substitution cipher by data sealing. Consequently, this increases the key length. Another advantage of this approach is power consciousness with high area efficiency and high throughput due to microarchitecture level hardware mechanism.Various aspects of the improved HCgorilla are studied in this paper. Metrics related to the evaluation are occupied area, power consumption, cipher strength, running time, and throughput. According to evaluation, the double cipher promises practically secure strength without any overhead. A new knowledge to be drawn from this study is to apply the temporary security of the double ciphe to ad-hoc cipher streaming without permanent network infrastructure.
2. Processor Design
- Fig. 1 shows the hardware organization of the improved version, HCgorilla.6. This has two symmetric cores. Each core is composed of two media pipes and a cipher pipe.
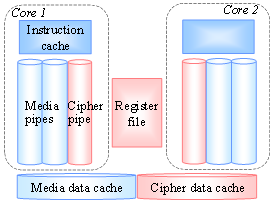 | Figure 1. Organization of HCgorilla.6 |
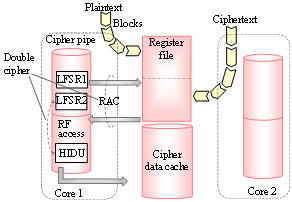 | Figure 2. Double cipher mechanism during data transfer |
2.1. Cipher Pipe
- The cryptographic defect of the previous HCgorilla originates in embodying only one hardware RNG. Transposition cipher like RAC cannot hide data structure. Thus, the HCgorilla.6’s cipher pipe is built in two RNGs. Fig. 2 illustrates the structural aspect, internal behavior, and algorithm of the cipher pipe. LFSR (linear feedback shift register) is used as RNG to achieve longer cycle with negligibly small overhead. This is because LFSR does not consume so much hardware cost, area, power consumption, running time, throughput, etc.[17]. The one of two LFSRs covers the transposition cipher of RAC and the other is used for substitution cipher. The substitution cipher is implemented by a hidable unit, HIDU.The external data of plaintext or cipher text is divided into blocks. The register file plays the role of streaming buffer. It buffers a block of external data. The transfer of the block to the register file is assumed to be DMA mode, though it is not our concern in this study.The cipher pipe executes a SIMD (single instruction stream multiple data stream) mode instruction. This occupies the cipher pipe as long as the corresponding data stream continues. The SIMD mode sequence forms double cipher streaming. RAC is carried out by making LFSR1’s output specify a register file address, synchronizing a data cache address with the current clock count, and transposing the specified register file’s content to the synchronized data cache address. Then, LFSR2 makes HIDU on data lines work for the substitution of transferred data. The resultant content stored in data cache is the double encryption of the register file’s content. Such a microarchitecture-based, software-transparent mechanism offers the protection of the whole data with negligible hardware cost and moderate performance overhead. Similarly, core 2 does double cipher decryption or encryption.
2.2. Media Pipe
- The media pipe shown in Fig. 1 is a sort of an interpreter type Java CPU[18]. The media pipe uses a waved MFU in the execution stage. This is the combination of wave-pipelining and multifunctionalization of arithmetic logic functions for media processing. Since the latency of the waved MFU is constant independently on arithmetic logic operations, the media instructions are free from scheduling[10].The waved MFU is conceived as follows. A possible way to release instruction scheduling in running processors is to merge the parallel structure of regular pipelines and to make them completely multifunctional. This surely executes every function with the same latency. However, the increase of circuit scale accompanied with the multifunctionalization elongates the critical path. This results in the degradation of clock speed. Thus, the simply merging of regular pipelines does not always promise the total enhancement of processor performance.In order to completely unify hardware units without deteriorating clock speed, wave-pipelining is really promising[19]. The wave-pipelining uses the delay of mainly combinational elements instead of using intermediate registers, while conventional pipelining uses registers to divide the circuit into shorter paths. While registers occupy large area, the wave-pipelining does not. Therefore, the wave-pipelining is more effective in view of hardware cost, power saving, speed up, and throughput degradation.Power saving of processor systems has been done by the control of supply voltage and clock. The supply voltage is sometimes scaled down[20] and sometimes gated[21]. Then, the clock is also scaled[22] and gated[23]. More sophisticated clock systems are clocks-variable[24], cycle-variable or adaptive clock[25]. However, these are accompanied with tradeoff against throughput. This in turn causes considerable overhead. Wave-pipelining is a more effective strategy for power saving at a lower level. It has been so far applied to arithmetic logics, circuit blocks, pipeline stages, etc.
3. Results and Discussion
- Basic features of the improved HCgorilla are studied. Fig. 3 illustrates a test program and internal behavior in the evaluation of HCgorilla.6’s throughputs focusing on the core 1 for the sake of simple representation. A test program is composed of the double cipher and media processing. The plaintext used in the double cipher processing is a 240×320-pixel QVGA format data.
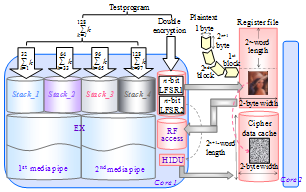 | Figure 3. A test program and internal behaviour in the evaluation of HCgorilla.6’s throughput |
3.1. Evaluation of the Double Cipher
- The HCgorilla.6’s cipher pipe is evaluated in view of cipher strength and throughput. Fig. 4 shows how to measure the double cipher strength through the experiment of rough-and-ready guess or round robin attack in a ubiquitous environment where HCgorilla built-in platforms are used. The cipher strength is the degree of enduringness against attack by a malicious third party. The attack is the third party’s irregular action to do decipher, break, or crack. This is clearly distinguished from decryption that is the right recipient’s regular process to recover the plaintext by using the given key.According to a normal scenario, the rules applied to deciphering a secret key cryptography in Fig. 4 are as follows.(a) A plaintext, cipher text, and the cipher algorithm are open to third parties.(b) A key or the initial value of RNG used in encryption is secret from third parties, though it is open to a right recipient.What is sought out in deciphering is a true key. Sometimes it is called a password. The reason why a plaintext and a cipher text are open is because they are various which in turn their quantity is beyond the protection. In addition, it is reasonable that the cipher algorithm or its specification is open because its value is usability in communication stages. This demands the spread of the algorithm in some community.
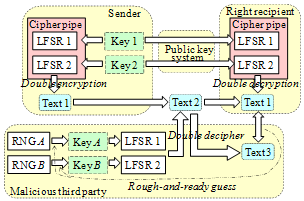 | Figure 4. Round robin attack against the secret key cryptography system including HCgorilla built-in ubiquitous platforms |
 | (1) |
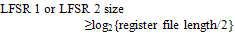 | (2) |
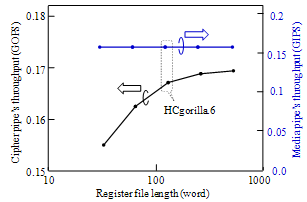 | Figure 5. Throughput vs. register file length |
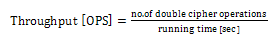 | (3) |
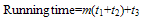 | (4) |
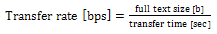 | (5) |
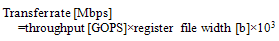 | (6) |
 | Figure 6. Media pipe’s throughput |
|
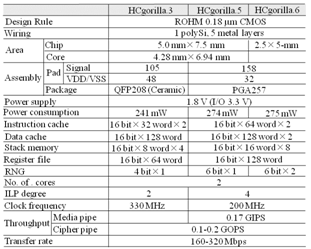
3.2. Total Evaluation of HCgorilla
- Considering (i) a secret key cryptography uses an algorithm that repeats simple operations like EXOR and shift, (ii) the algorithm is open to a third party, (iii) the cipher strength is determined by the length of a key, the point in the evaluation of the hardware implementation of a secret key cryptography is not cipher strength but hardware specifications. Table 1 summarizes chip parameters and hardware specifications of HCgorilla.6 and previous derivatives. The HCgorilla family uses the same 0.18-m CMOS standard cell technology. Clock frequency is derived from timing analysis by using a Synopsys design compiler. Power dissipation is derived from static analysis. HCgorilla.6 and HCgorilla.5 have almost the same structure except the number of built in RNG. Since RNG occupies negligibly small area, the same clock frequency is reasonable.One of the most important metrics of ubiquitous devices is power dissipation. Fig. 7 shows the register file length dependency of power dissipation and chip area. The register file length is swung similarly to Fig. 5. Power dissipation in this figure is rough approximation derived from static analysis, which summarizes the mean value of every gate. It does not take into account of switching condition. Fig. 8 shows the breakdown of HCgorilla.6’s power consumption more in detail. In addition, the effect of double cipher on power dissipation is shown by comparing HCgorilla.6 and HCgorilla.5.
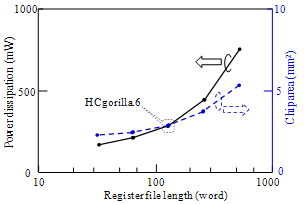 | Figure 7. Register file length dependency of power dissipation and chip area |
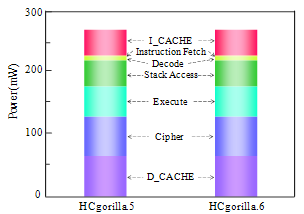 | Figure 8. The effect of double cipher on power dissipation |
3.3. Discussion
- The cost of increasing RNGs is negligible small compared with the HCgorilla.6 chip. The hardware cost of each cipher pipe is 270 cells that occupy only 0.1 mm square. The power dissipation of each cipher pipe is 30 mW from Fig. 8. Since this value is based on rough approximation, more practical value based on dynamic analysis or experimental measurement is smaller than this. Accordingly, HCgorilla.6 implemented in a 0.18-m CMOS chip is provided with hardware specifications suited to ubiquitous devices.While the cipher pipe’s transfer rate is almost enough because it is comparable to ATM’s one, the throughput in GOPS should be improved in view of CPU performance. Actually, the cipher pipe’s throughput almost saturates at 128-word length from Fig. 5. In order to enhance GOPS value, which directly affects the increase of Mbps value, running time should be decreased from (3). This is possible according to following strategies.(a) Reducing t1 and t3 by using memory buffer with faster access speed.(b) Reducing the summation of block access and transfer times, ∑(t1+t3) by increasing the register file size. Expanding the register file length leads to the increase of cipher strength. However, it needs to take into account of tradeoff between throughput and power dissipation. Increasing the register file size causes more power dissipation judging from (3). In fact, the power dissipation rapidly increases from 128-word length from Fig. 7.(c) Reducing t2 by the speed up of the cipher pipe’s clock. Increasing the number of pipeline stages is also useful for this aim.
4. Conclusions
- In order to solve the cryptographic issue of the previous versions of the ubiquitous processor, HCgorilla family, a double cipher scheme has been implemented in this study. While the double cipher is clearly stronger than the single cipher of RAC, other metrics like occupied area, power consumption, cipher strength, running time, and throughput are almost independent on the number of RNGs. The optimum buffer size of the latest version, HCgorilla.6 is 128-word length judging from throughput and power tendencies.The benefits of the improved HCgorilla.6 are very profitable from the new knowledge drawn from this study. The double cipher progressively offers the temporary protection of the whole data. The temporary security of the double cipher is really applicable for ad-hoc cipher streaming without permanent network infrastructure.Next steps of this study are as follows. Firstly, the throughput in GOPS should be improved in view of CPU performance. Secondly, the double cipher scheme should be implemented in the media pipe, though the cipher pipe and the media pipe are explicitly distinguished each other in this study. The microarchitecture level mixing of instruction scheduling free media processing with cipher processing will contribute power conscious security in ubiquitous network.
ACKNOWLEDGEMENTS
- This work is supported by Grant-in-Aid for Scientific Research (C) (21500048) from Ministry of Education, Culture, Sports, Science and Technology, Japan. In addition, this work is supported in part by VLSI Design and Education Center (VDEC), the University of Tokyo in collaboration with Synopsys, Inc. and Cadence Design Systems, Inc.